
系列文章目录:FPGA原理与结构(0)——目录与传送门
一、RAM概述
1、RAM基本概念
RAM:**随机存取**存储器(Random Access Memory)。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。RAM工作时可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。它与ROM的最大区别是数据的**易失性**,即一旦断电所存储的数据将随之丢失。RAM在计算机和数字系统中用来暂时暂存程序、数据和中间结果。
2、FPGA中RAM的分类
在FPGA中,当我们谈论RAM的时候,一般指的是以下两种:块RAM(BRAM,Block RAM)和分布式RAM(DRAM,Distributed RAM)。
Block RAM专用的存储资源,使用时需要把每块(36kb/18kb)作为整体使用,会产生一定的浪费,读出数据需要使用时钟,但是Tsu/Th/Tco更大Distributed RAM使用的就是CLB中的SliceM中的LUT,它会占用一定的逻辑资源,使用时位宽和深度都可以随意配置,寄存器堆进行MEM建模可以使用它。读取数据可以是纯组合逻辑也可以是时序逻辑,可能降低CLB中的其他资源利用率
分布式RAM和** BLOCK RAM**的选择遵循以下方法:
(1)小于或等于64bit容量的都用分布式实现
(2)深度在64~128之间的,若无额外的block可用DRAM。数据宽度大于16时用BRAM.
(3)DRAM有比BRAM更好的时序性能。DRAM在逻辑资源CLB中。而BRAM则在专门的存储器列中,会产生较大的布线延迟,布局也受制约。
(4)DRAM可以是纯组合逻辑,即给出地址马上出数据,也可以加上register变成有时钟的RAM。而BRAM一定是有时钟的。
二、DRAM详解
1、FPGA资源
在FPGA中,CLB是实现逻辑功能的基本单元,一个CLB由2个slice组成,slice可以分成以下的两类:SliceM(Memory)和SliceL(Logic)。这两种slice的区别在于它们的LUT不同。
SLICEM(M:Memory):其内部的LUT可以读也可以写,可以实现移位寄存器和64bit的DRAM等存储功能,还可以实现基本的查找表逻辑。
SLICEL(L:Logic): 其内部的LUT只可以读,只能实现基本的查找表逻辑。
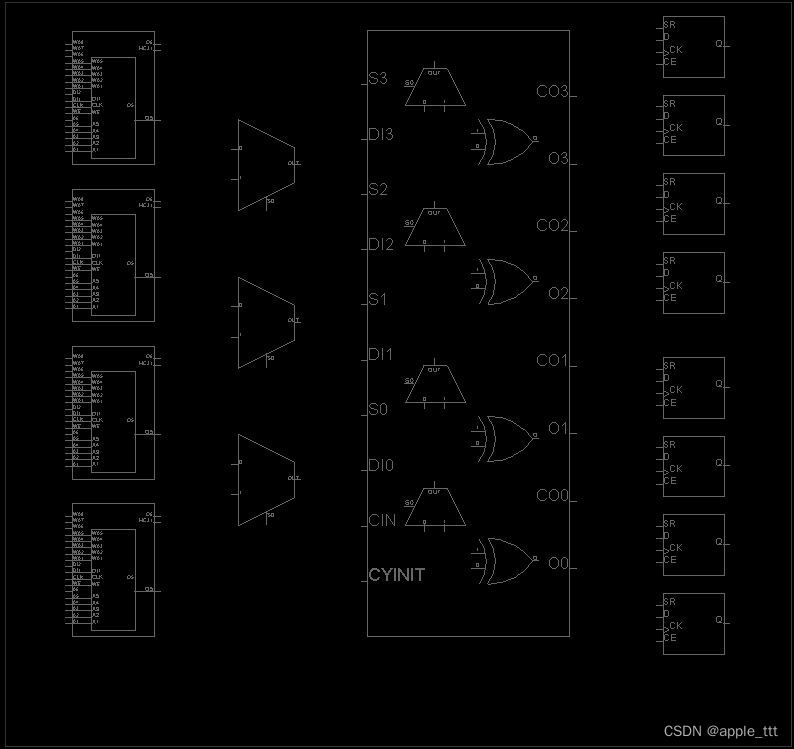
下图为SLICEM的视图展示:
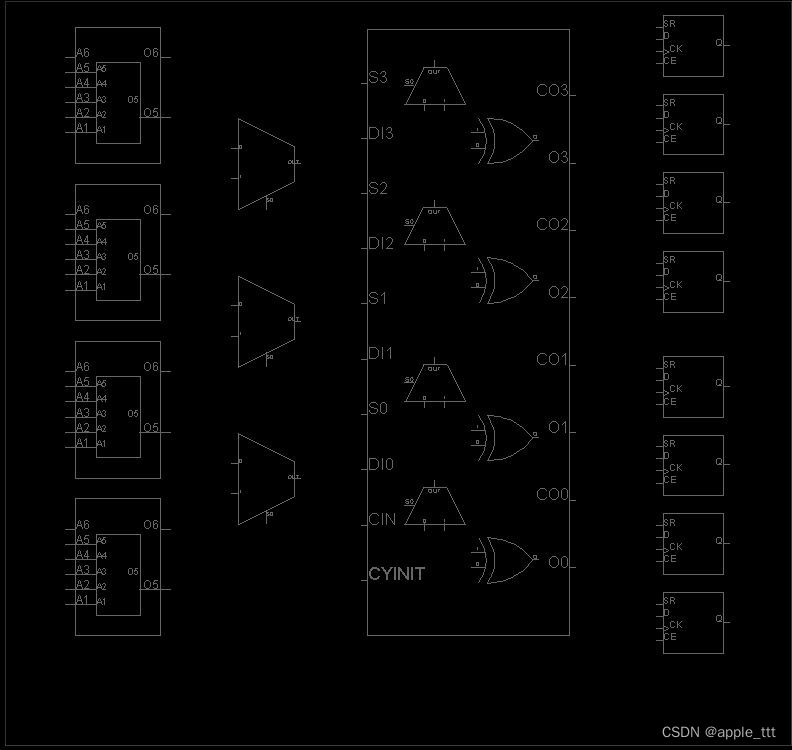
下图为SLICEL的视图展示:
可以看到从视图上明显的区别就在于两者的LUT有所不同,我们对两者的LUT进一步放大进行观察:
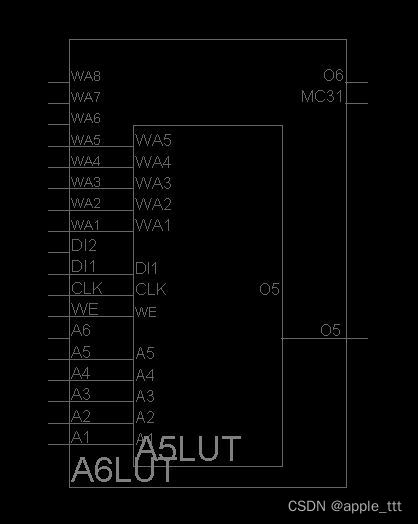
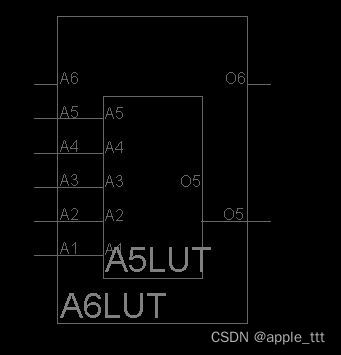
左侧是SliceM对应的LUT视图,右侧为SliceL对应的LUT视图。
接下来我们将两种LUT的结构进行对比:
相同点:都具有地址输入线(A1-A6),两个输出口(O5-O6)。
不同点:SLICEM的LUT6具有写地址输入线(WA1-WA8),写数据端(DI1 DI2),写使能端(WE),而SLICEL的LUT6没有。
这是由于以上的不同,才使得SliceL的LUT只具有存储数据的能力,只能作为ROM使用,而SliceM的LUT还具备了数据写入的功能,可以作为DRAM或移位寄存器使用。
2、DRAM的配置形式
在一个SliceM中具有4个6-LUT,其资源可以被被配置成一种同步RAM资源,也就是我们一直在说的DRAM。我们知道一个6-LUT的大小为64bit,所以DRAM的可配置情况如下:
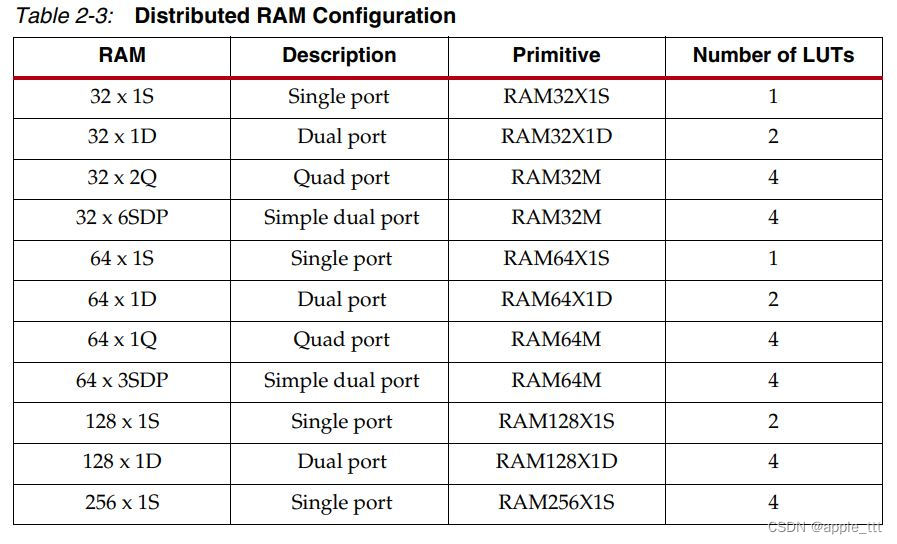
RAM描述原语使用的资源32 x 1S单端口RAM32X1S1个LUT32 x 1D双端口RAM32X1D2个LUT32 x 2Q四端口RAM32M4个LUT32 x 6SDP简单双端口RAM32M4个LUT64 x 1S单端口RAM64X1S1个LUT64 x 1D双端口RAM64X1D2个LUT64 x 1Q四端口RAM64M4个LUT64 x 3SDP简单双端口RAM64M4个LUT128 x 1S单端口RAM128X1S2个LUT6+1个MUX128 x 1D双端口RAM128X1D4个LUT6+2个MUX256 x 1S单端口RAM256X1S4个LUT6+3个MUX
其中第一列的缩写展开含义如下: 深度 x 位宽+类型 ,例如256 x 1S表示的就是深度为256,位宽为1的单端口DRAM。
缩写含义如下:
S:Single-Port 单端口
D:Dual-Port 双端口
Q:Quad-Port 四端口
SDP:Simple Dual-Port 简单双端口
2.1 Single-Port(单端口)
同步写,异步读(可选同步读,加一个寄存器),读写公用相同的地址总线。
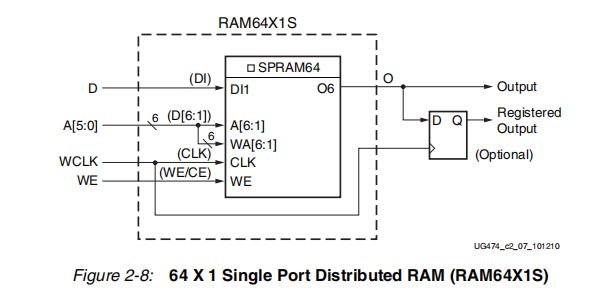
图中D为输入的数据,WCLK为同步时钟,WE为使能信号,A[5:0]为地址总线(读写共用),输出端可选是否使用寄存器实现同步读。
2.2 Dual-Port(双端口)
一个端口用于同步写,异步读(可选同步读,加一个寄存器);另一个端口用于异步读(可选同步读,加一个寄存器)。
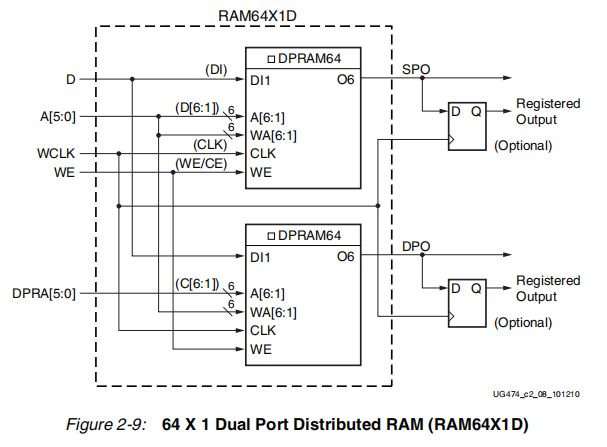
一个端口(A[5:0]为地址输入)可同步写,异步读。另一个端口(DPRA[5:0]为输入地址)只能异步读。两个LUT6中存放着相同的数据,其实上面的LUT6就是一个单端DRAM,它的输出(SPO)取决于输入地址A[5:0]。下面的LUT6的不同之处就是它的输入端口A[6:1]连的是DRPA[5:0],因此它的输出取决于地址DPRA[5:0]。
2.3 Quad-Port(四端口)
一个端口用于同步写,异步读(可选同步读,加一个寄存器);剩下3个端口用于异步读(可选同步读,加一个寄存器)。
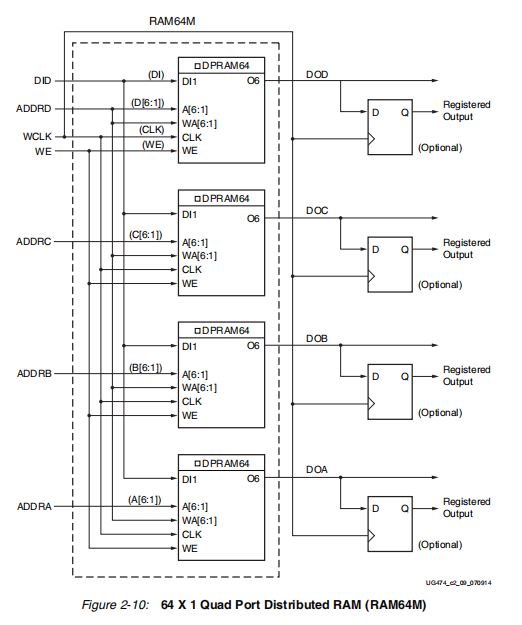
一个端口(ADDRD为地址输入)可同步写,异步读。另外三个端口(ADDRA,ADDRB,ADDRC为输入地址)只能异步读。结构与双端口DRAM相似,4个LUT所存放着着相同的数据,只不过每个端口都可以单独读不同地址的内容。
2.4 Simple Dual-Port(简单双端口)
一个端口用于同步写(不能输出数据,即不能进行读),另一个端口用于异步读(可配置成同步读,加一个寄存器)。
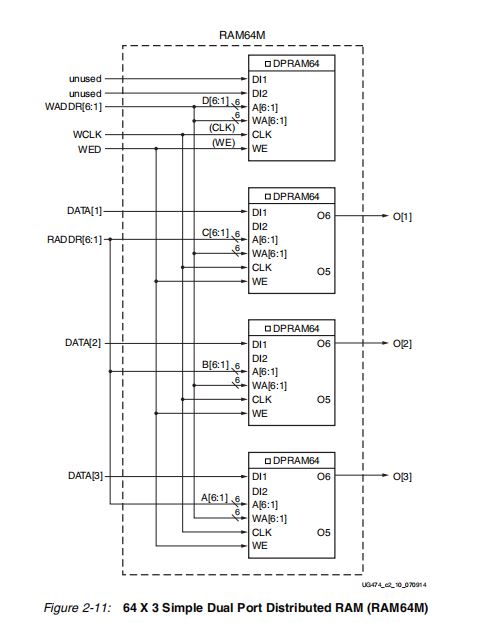
一个端口(WADDR为地址输入地址)只可同步写,另一端口(RADDR为地址输入)只能异步读。在64x3简单双端口DRAM中,3个数据输入口DATA[3:1]并行输入,3个数据输出口O[3:1]并行输出。
2.5 更大深度
以上我们举的所有的例子,所使用的DRAM的深度都没有超过64,而我们知道DRAM还可以实现深度为128,256的RAM,在这种情况下还需要使用到MUX资源。我们以最复杂的256 X 1 Single Port Distributed RAM (RAM256X1S)为例:
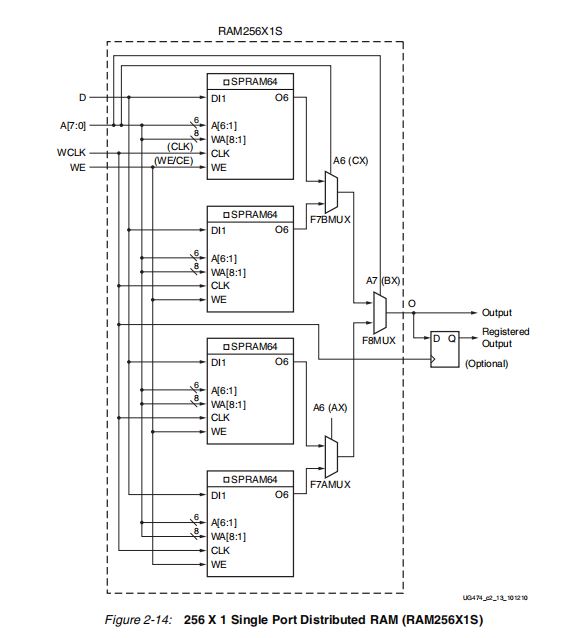
这是单个SLICEM可以实现的最大深度,使用到2个MUX7,1个MUX8 。
3、DRAM数据流
** 同步写操作**:同步写是带有使能信号的单时钟沿操作。当写使能信号(WE)为高时,输入数据(D)被写入地址(Address)对应的存储空间。
**异步读操作**:当单端口时,输出由地址A决定,当双端口时,上面一个LUT(对应既可读又可写的)的输出SPO由地址A决定,下面一个LUT(只可读)的输出DPO由地址DPRA决定。每次地址变化,延迟访问LUT的时间后输出该地址的内存数据值。这个操作是异步的,可以独立于时钟信号(也可以配置成同步)。
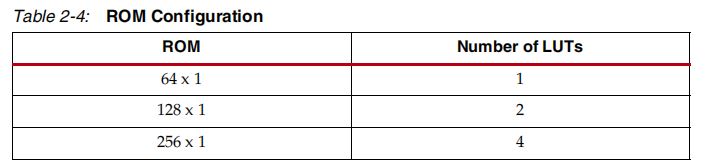
4、ROM
每个SLICEM和SLICEL都可以配置成ROM,不要认为SLICEM就不能被配置成ROM。
三、设计实现
要在我们的设计中合理自如地使用DRAM,我们就需要了解DRAM在vivado中的各种使用形式。
1、vivado推断
推断指的是设计者通过编写符合EDA工具属性的RTL代码,由EDA工具(这里指vivado)自行对于需要使用的硬件资源进行判断,从而完成合理的综合。
由于现在EDA工具的发展已经相对成熟,所以在大部分时候推断都能给出让人满意的结果,这也是对于设计者的解放,一定程度上来说,就算设计者完全不知道FPGA的底层结构,EDA工具也能通过推断对于设计者的设计进行优化。
使用推断的好处有:(1)设计者无需再去例化RAM原语(2)节约时间(3)保持HDL代码的可升级性和便捷性。
1.1 推断使用BRAM还是DRAM?
对于这两种类型地RAM来说,写操作都是同步的,区分他们地最本质地区别在于他们的读操作:DRAM可以实现异步读,BRAM只能进行同步读。

vivado综合时推断使用DRAM还是BRAM地标准如下:
(1)用户设计地HDL代码风格
(2)用户是否对使用类型进行了强制限定 ram_style 。
这里的ram_style会直接强制vivado在综合时使用BRAM还是DRAM,它可以被设置成 *block *或 ***distributed ***两种情况。我们举个例子来帮助大家了解如何使用:
//DRAM
(* ram_style = "distributed" *) reg [data_size-1:0] myram [2**addr_size-1:0];
//BRAM
(* ram_style = "block" *) reg [data_size-1:0] myram [2**addr_size-1:0];
(3) BRAM资源的可用性,如果所选的FPGA中的BRAM资源已经耗尽了,那么就不得不使用DRAM了。
1.2 RAM推断能力
vivado毕竟还只是一个EDA工具,是工具就有其能力范围。vivado综合时对于RAM的推断能做到:(1)支持任何大小和数据宽度。Vivado综合系统会将内存描述映射到一个或几个RAM原语(2)支持单端口,简单双端口,真双端口 (DRAM支持的4端口模式就不能通过推断的方式实现)(3)最多支持两个写端口 (4)多个读端口。
1.3 DRAM的推断案例
这里给出了位宽16,深度64的双端口DRAM的官方示例:
// Dual-Port RAM with Asynchronous Read (Distributed RAM)
//
// File: HDL_Coding_Techniques/rams/rams_09.v
//
module v_rams_09 (clk, we, a, dpra, di, spo, dpo);
input clk; //时钟信号
input we; //写使能
input [5:0] a; //地址信号(读写共用)
input [5:0] dpra; //读地址信号
input [15:0] di; //输入数据
output [15:0] spo; //地址a对应的spo数据输出
output [15:0] dpo; //地址dpo对应的dpo数据输出
reg[15:0] ram [63:0]; //RAM定义,深度64,位宽16
always @(posedge clk) begin
if (we)
ram[a] <= di;
end
assign spo = ram[a]; //异步读
assign dpo = ram[dpra]; //异步读
endmodule
查看对应的综合结果:
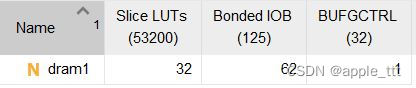
可以看到使用的确实是LUT资源,与我们的预期是一致的。
2、原语
使用原语直接进行模块例化,这是最接近底层的实现方式,但是缺点就是需要设计者对底层由充分的了解,并且实现起来相对复杂,代码冗长可读性差,可维护性差,一般只做了解,不推荐大家进行使用,具体的模块结构可以参考《 **ug953-vivado-7series-libraries **》,原语例化的示例可以参照vivado的Language Templates 。
3、IP核
使用IP核开发的方式大家应该并不陌生,Xilinx在这里也提供了DRAM的官方IP核。

在充分了解了DRAM对一个的底层结构后,这个IP核的配置也非常简单。
在这个界面我们设置DRAM的深度,位宽,模式。
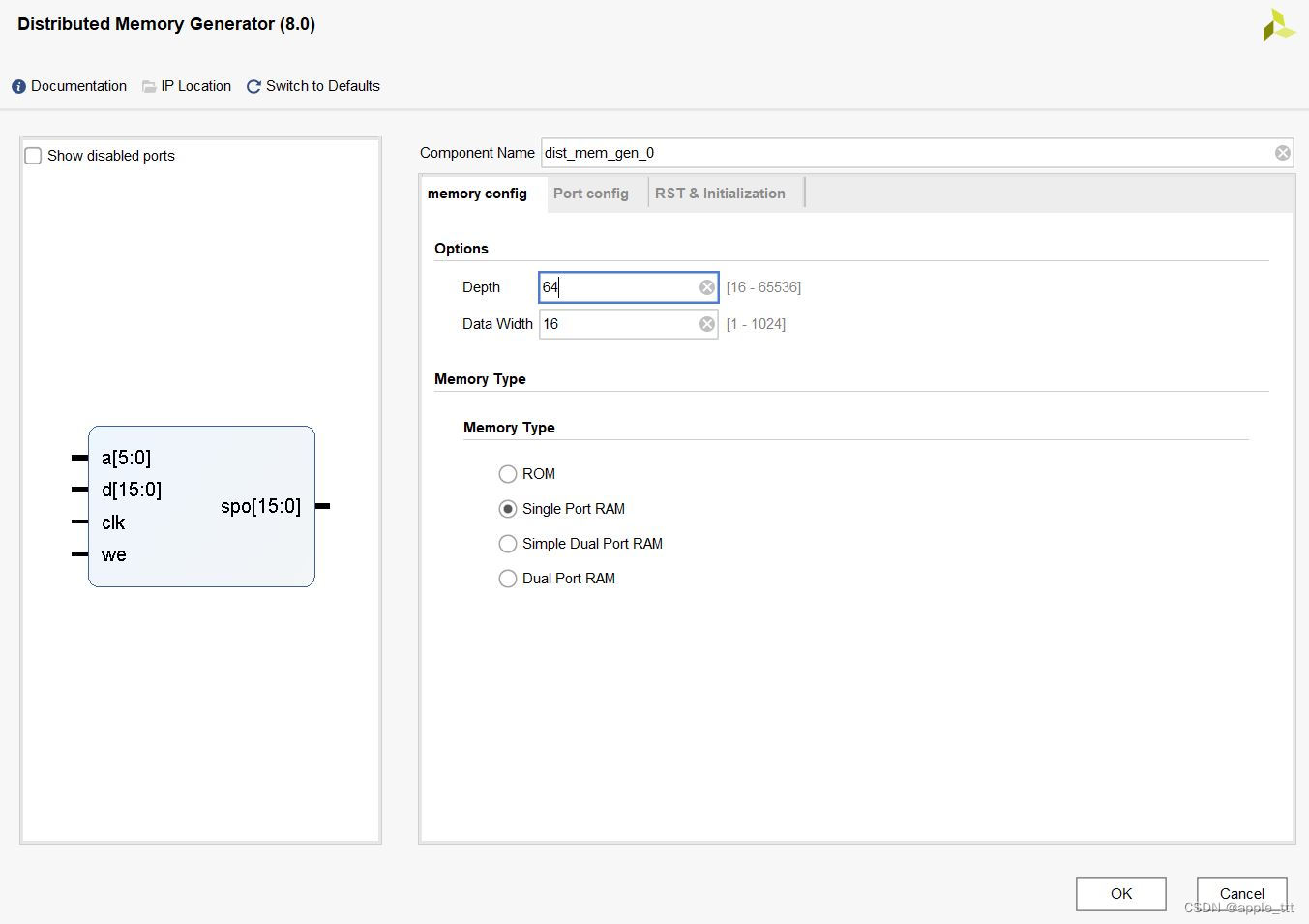
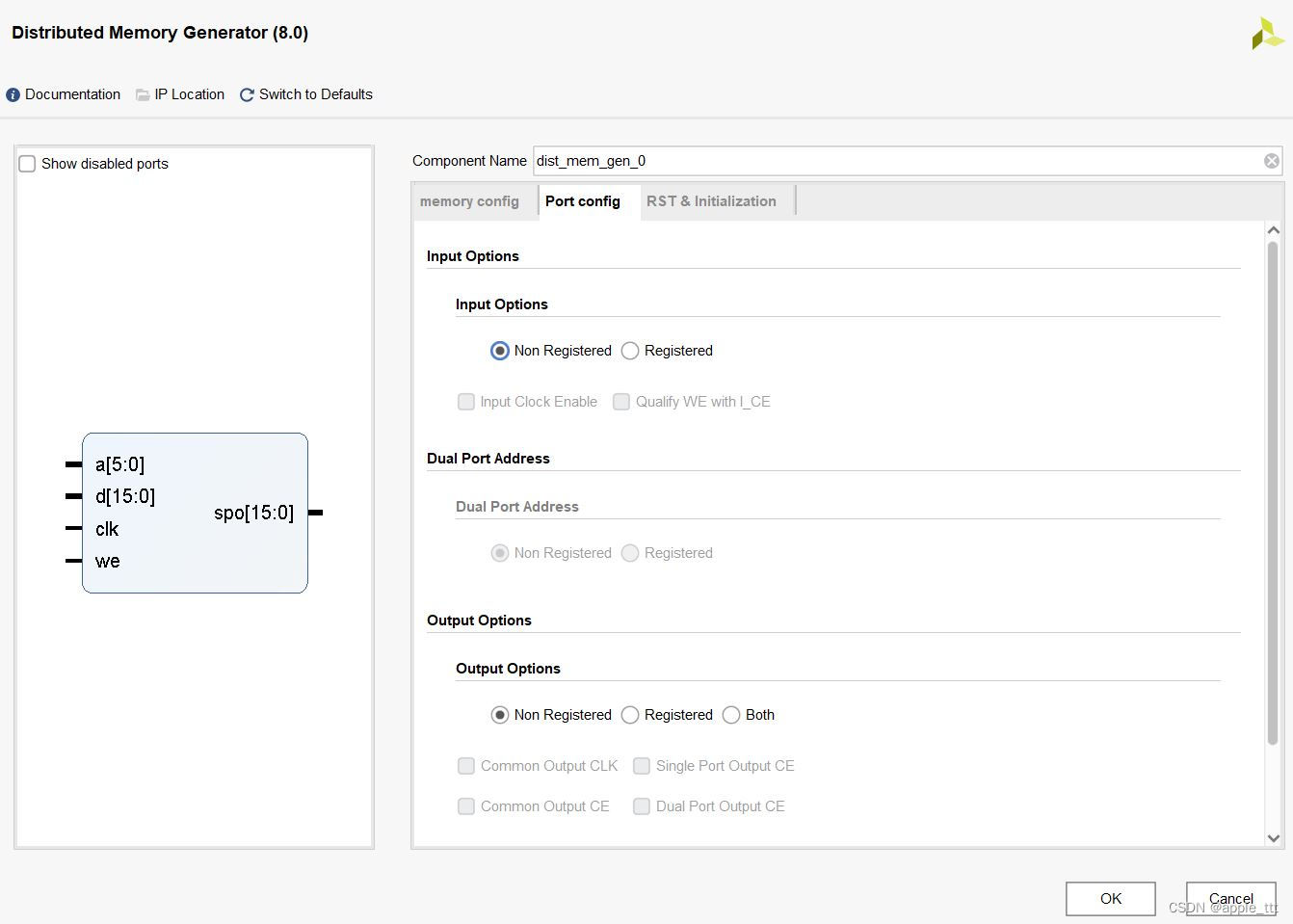
这个界面我们设置输入输出端口是否需要寄存器,一般来说都不需要,如果读操作想要实现同步读可以设置输出端口有寄存器。
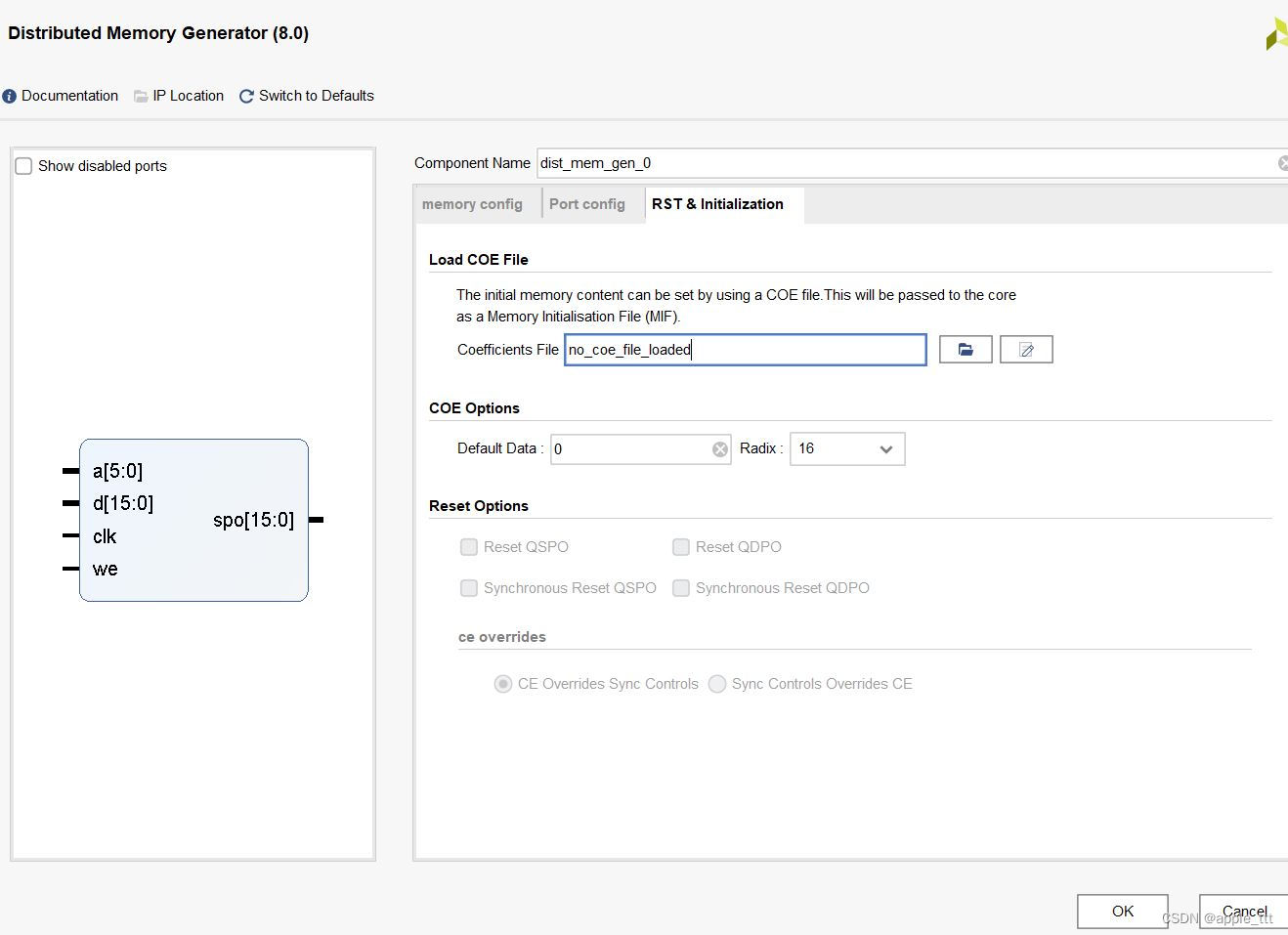
最后我们设置RAM的初值和复位后的情况。
四、小结
到这里,我们的DRAM部分就结束了,在设计时推荐大家还是规范自己的代码风格,由vivado自行推断是否使用DRAM,其实对于一个设计来说,如果选择的芯片的资源足够,一般情况下,我们完全不需要关注是否去使用DRAM,但是当资源不足或者时序上必须进行调整,我们有时候就不得不去使用到DRAM。
版权归原作者 apple_ttt 所有, 如有侵权,请联系我们删除。