
前言
今天今天又来了一个冷门脚本!读取txt文件中的数据转换成csv文件。
比如下面文件开始有规律分布着需要提取的数据,从第三行开始提取,并且对数据进行处理,最后进行输出。
代码
说明:
- 以下代码不仅仅是提取数据,还包含处理的步骤,处理的方式不进行公开,
from utils.feature_process import FeatureProcess是我自定义的库; plot_flag可以将一个文件夹中的处理后的数据进行显示,设为False就不进行绘图啦。- 在main中先设置源文件,再设置存储位置。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from utils.feature_process import FeatureProcess # 自定义的特征处理函数
plot_flag =Trueclasstxt2csv:def__init__(self, source_dir, save_dir):
self.source_dir = source_dir
self.save_dir = save_dir
defprocess(self):
txt_data = os.listdir(self.source_dir)for one_data in txt_data:
self.csv_date = pd.DataFrame(columns=['frames','wratio','cvalue','kangle'])
self.arr_data = np.zeros((1,4))
self.feature_process = FeatureProcess()withopen(os.path.join(self.source_dir, one_data),'r')as f:# 读取每个文件夹的数据
lines = f.readlines()for line in lines:
num = line.split(',')iflen(num)<=1:continue# 处理数据
frame = num[0]
bounding_box = num[2:]
feature_list = self.feature_process.feature_extraction([240,320], bounding_box)# 存储数据
self.arr_data[0][0]= frame
self.arr_data[0][1]= feature_list[0]
self.arr_data[0][2]= feature_list[1]
self.arr_data[0][3]= feature_list[2]# 追加方式填充上数据
one_row_data = pd.DataFrame(self.arr_data, columns=['frames','wratio','cvalue','kangle'])
self.csv_date = self.csv_date.append(one_row_data, ignore_index=True)
self.csv_date.to_csv(os.path.join(self.save_dir, one_date.split('.')[0]+'.csv'), index=False)if plot_flag:# 拿起画板
fig = plt.figure()# 在画板上贴上画纸
ax1 = fig.add_subplot(111)# 画图显示 True显示,False不显示
ax1.scatter(self.csv_date['frames'], self.csv_date['cvalue'])
plt.show()if __name__ =='__main__':# 读取源文件
tc = txt2csv(r'./annotation_files','.')# 进行转化和存储
tc.process()
文件目录结构
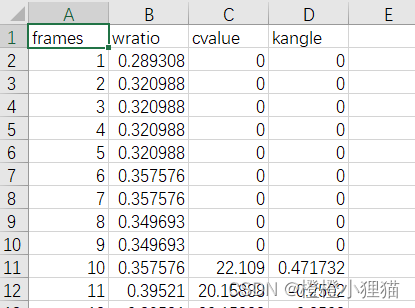
简单展示一下csv中的结果
本文转载自: https://blog.csdn.net/weixin_42442319/article/details/128473447
版权归原作者 橙橙小狸猫 所有, 如有侵权,请联系我们删除。
版权归原作者 橙橙小狸猫 所有, 如有侵权,请联系我们删除。