
欠采样方法总结
从数据样本层面解决样本不平衡的方法,欠采样就是从多数类中删除样本
随机欠采样
从多数类别样本中随机选取一些剔除掉。使多数类别样本数目和少数类别样本数目相当,组成新的数据集。
缺点:可能会导致丢弃含有重要信息的样本。
Edited Nearest Neighbours (ENN)
对于多数类的一个样本,其最近邻的样本大部分或者全部样本不属于其类别则剔除。(考虑了数据的分布信息)
Tomek Links
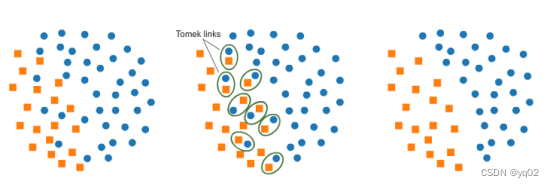
原理:如果有两个不同类别的样本A、B,A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link。Tomek link的方法就是,将组成Tomek link的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉。
EasyEnsemble
(1) 从多数类中有放回的随机采样n次,每次选取与少数类数目相近的样本个数,从而得到n个样本集合记作 ;
(2) 将(1)中得到的n个集合分别与少数类样本合并组成新的数据集去训练模型,可以得到n个模型;
(3) 将这些模型组成成集成学习系统,系统输出为n个模型的平均值。
BalanceCascade
BalanceCascade算法基于Adaboost,将Adaboost作为基分类器,核心思路如下:
(1) 在每一轮训练时都使用与少数类样本数目相当的多数类样本,训练出一个Adaboost基分类器;
(2) 然后使用该分类器对全体多数类进行预测,通过控制分类阈值来控制假正例率,将所有判断正确的样本删除。
(3) 最后,进入下一轮迭代中,继续降低多数类数量。
原型选择和原型生成
- NearMiss-1: 在多数样本中选择出与少数样本最近的K个样本的平均距离最小的样本。计算每个多样本与每个负样本的距离;得出每个多数样本与负样本距离最近K个负样本,计算K个平均距离,即每个多数样本都有这个平均距离,按照这个平均距离排序,选择出平均距离最近的样本。
- NearMiss-2: 在多数样本中选择出与少数样本最远的K个样本的平均距离最小的样本。计算每个多样本与每个负样本的距离;得出每个多数样本与负样本距离最远K个负样本,计算K个平均距离,即每个多数样本都有这个平均距离,按照这个平均距离排序,选择出平均距离最近的样本。
- NearMiss-3: 对于每个少数类别样本,选择离它近的K个多数类别样本。
- 基于K-Means聚类欠采样: sklearn中的用法:直接使用聚类类别的聚类质心作为样本,不一定是原始样本。另一种方法是将多数类别数据进行聚类,假如K个类别,然后选取每个类别中距离聚类质心最近的n个样本,这样就可以得到n*K个样本。
本文转载自: https://blog.csdn.net/weixin_43978588/article/details/127647754
版权归原作者 yq02 所有, 如有侵权,请联系我们删除。
版权归原作者 yq02 所有, 如有侵权,请联系我们删除。