
一、主从复制
1.实现主从作用
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建**主从集群**,实现**读写分离**。主节点用来写的操作,从节点用来读操作,并且主节点发生写操作后,会把数据**同步**给从节点。
2.主从数据同步的原理
(1)主从全量同步
1.原理解释
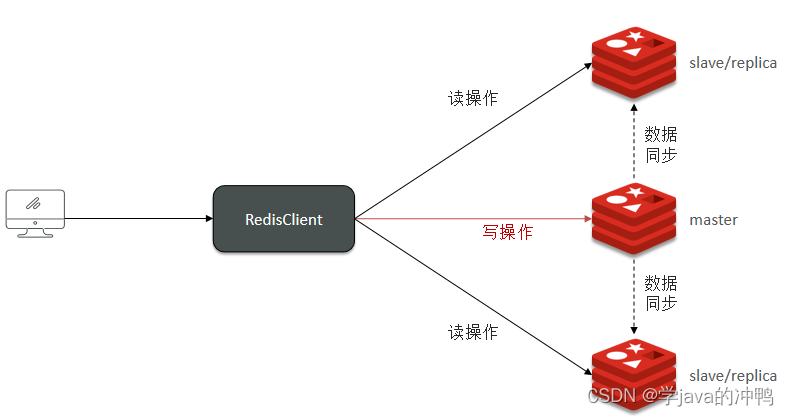
解释一下主从全量同步流程图(如下图)。**第一步**,从节点执行命令建立连接。**第二步**,向主节点请求数据同步。**第三步**,主节点判断是否是第一次同步。**第四步**,是第一次同步的话,就返回主节点的数据版本信息给从节点,从节点会保存,如果以前同步过就不用第四步这些操作了。**第五步**,主节点执行命令bgsave命令,生成RDB文件,然后发送给从节点。**第六步**,从节点会清空本地数据,加载主节点传过来的RDB文件。**第七步**,如果这时主节点有数据的修改,但是并没有同步过去,所以主节点会用repl_baklog文件记录RDB期间的所有命令,并发送给从节点。**第八步**,从节点会执行接收到的命令进行数据的同步。
第三步主节点是如何判断是不是第一次同步从节点的呢?通过**replid**来判断的。
第七步repl_baklog为什么能够同步呢?通过记录**offset**来判断的。

2.关键词的意思
**Replication Id:**简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid。
** offset:**偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
RDB可以看我以前的贴子,下方链接可以跳转:
Redis篇之数据持久化https://blog.csdn.net/weixin_53094999/article/details/136047400?spm=1001.2014.3001.5501
(2)主从增量同步
增量同步触发的时机:**slave重启或后期数据变化。**
** 主要就是先判断replid,然后把获取repl_baklog中的offset**后的数据,发送给从节点执行。
二、哨兵模式
1.为什么要使用哨兵
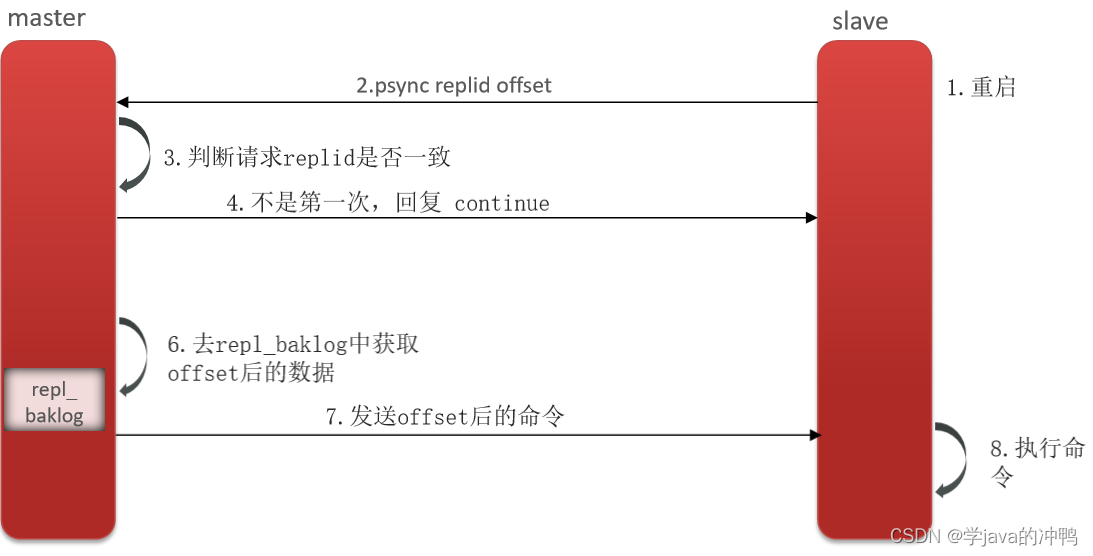
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。
2.哨兵的结构和作用
** 监控:**Sentinel 会不断检查您的master和slave是否按预期工作.
**自动故障恢复:**如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主。
**通知:**Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端。

3.服务状态监控
(1)心跳机制
Sentinel基于**心跳机制**监测服务状态,每隔1秒向集群的每个实例发送ping命令:
**主观下线:**如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
**客观下线:**若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
(2) 哨兵选主
**哨兵选主规则:**
首先判断主与从节点断开时间长短,如超过指定值就排该从节点。
然后判断从节点的slave-priority值,越小优先级越高。
**如果slave-prority一样,则判断slave节点的offset值,越大优先级越高。**
最后是判断slave节点的运行id大小,越小优先级越高。
4.脑裂问题
(1)概念
脑裂问题:当一个集群内部的节点间由于网络故障、硬件故障或其他原因导致部分节点无法与其他节点正常通信时,集群可能会分裂成两个或多个独立运行的部分,每个部分都认为自己是整个集群的有效子集,并继续提供服务。会导致数据的不一致。
(2)如何解决
redis中有两个配置参数:
min-replicas-to-write 1 表示最少的salve节点为1个
min-replicas-max-lag 5 表示数据复制和同步的延迟不能超过5秒
三、分片集群
1.为什么要使用分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
1. 海量**数据存储**问题。
2. **高并发写**的问题。
使用分片集群可以解决上述问题,**分片集群特征**:
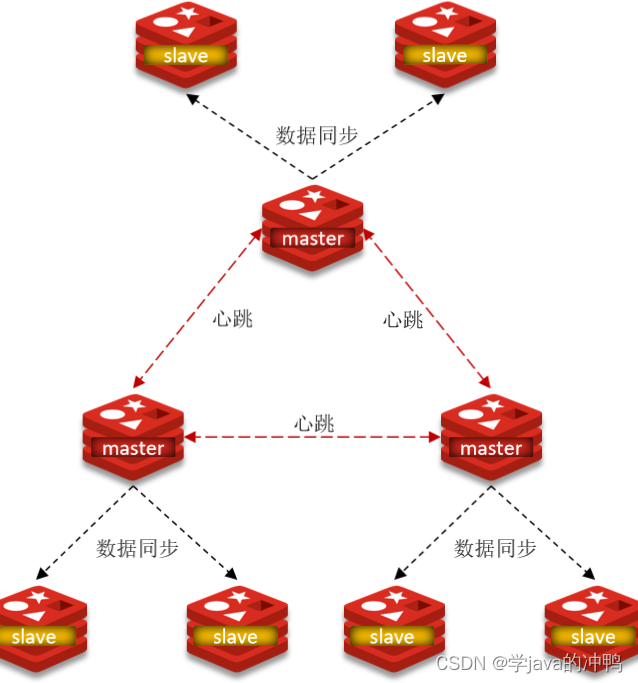
1. 集群中有多个master,每个master保存不同数据。
2. 每个master都可以有多个slave节点。
3. master之间通过ping监测彼此健康状态。
4. 客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
2.数据读写怎么完成呢
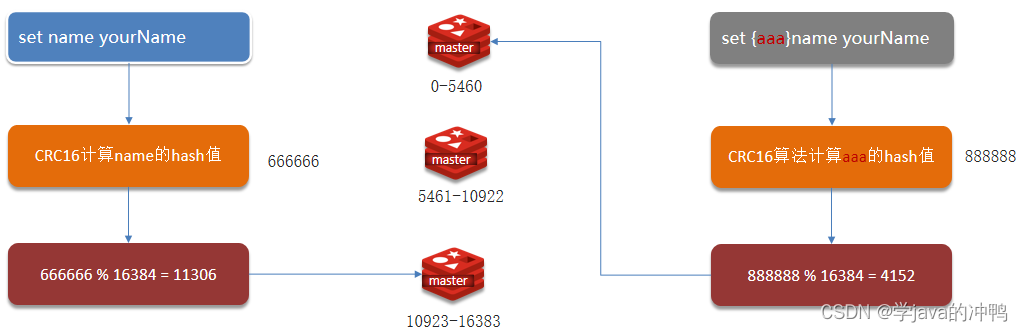
Redis 分片集群引入了**哈希槽**的概念,Redis 集群有 **16384 **个哈希槽,每个 key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
左边是根据key来计算hash值,然后进行对哪个节点的读写操作。
右边是通过自定义的{aaa}有效部分来计算hash值,然后读写固定的节点。
四、有关面试的问题
1.主从复制
面试官:Redis集群有哪些方案, 知道嘛 ?
候选人:在Redis中提供的集群方案总共有三种:主从复制、哨兵模式、Redis分片集群。
面试官:那你来介绍一下主从同步。
候选人:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中。
面试官:能说一下,主从同步数据的流程。
候选人:主从同步分为了两个阶段,一个是全量同步,一个是增量同步。
全量同步是指从节点第一次与主节点建立连接的时候使用全量同步,流程是这样的:
第一:从节点请求主节点同步数据,其中从节点会携带自己的replication id和offset偏移量。
第二:主节点判断是否是第一次请求,主要判断的依据就是,主节点与从节点是否是同一个replication id,如果不是,就说明是第一次同步,那主节点就会把自己的replication id和offset发送给从节点,让从节点与主节点的信息保持一致。
第三:在同时主节点会执行bgsave,生成rdb文件后,发送给从节点去执行,从节点先把自己的数据清空,然后执行主节点发送过来的rdb文件,这样就保持了一致。
当然,如果在rdb生成执行期间,依然有请求到了主节点,而主节点会以命令的方式记录到缓冲区,缓冲区是一个日志文件,最后把这个日志文件发送给从节点,这样就能保证主节点与从节点完全一致了,后期再同步数据的时候,都是依赖于这个日志文件,这个就是全量同步。
增量同步指的是,当从节点服务重启之后,数据就不一致了,所以这个时候,从节点会请求主节点同步数据,主节点还是判断不是第一次请求,不是第一次就获取从节点的offset值,然后主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步。
2.哨兵模式
面试官:怎么保证Redis的高并发高可用。
候选人:首先可以搭建主从集群,再加上使用redis中的哨兵模式,哨兵模式可以实现主从集群的自动故障恢复,里面就包含了对主从服务的监控、自动故障恢复、通知;如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主;同时Sentinel也充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端,所以一般项目都会采用哨兵的模式来保证redis的高并发高可用。
面试官:你们使用redis是单点还是集群,哪种集群。
候选人:我们当时使用的是主从(1主1从)加哨兵。一般单节点不超过10G内存,如果Redis内存不足则可以给不同服务分配独立的Redis主从节点。尽量不做分片集群。因为集群维护起来比较麻烦,并且集群之间的心跳检测和数据通信会消耗大量的网络带宽,也没有办法使用lua脚本和事务
面试官:redis集群脑裂,该怎么解决呢?
候选人:这个在项目很少见,不过脑裂的问题是这样的,我们现在用的是redis的哨兵模式集群的
有的时候由于网络等原因可能会出现脑裂的情况,就是说,由于redis master节点和redis salve节点和sentinel处于不同的网络分区,使得sentinel没有能够心跳感知到master,所以通过选举的方式提升了一个salve为master,这样就存在了两个master,就像大脑分裂了一样,这样会导致客户端还在old master那里写入数据,新节点无法同步数据,当网络恢复后,sentinel会将old master降为salve,这时再从新master同步数据,这会导致old master中的大量数据丢失。
关于解决的话,我记得在redis的配置中可以设置:第一可以设置最少的salve节点个数,比如设置至少要有一个从节点才能同步数据,第二个可以设置主从数据复制和同步的延迟时间,达不到要求就拒绝请求,就可以避免大量的数据丢失。
3.分片集群
面试官:redis的分片集群有什么作用。
候选人:分片集群主要解决的是,海量数据存储的问题,集群中有多个master,每个master保存不同数据,并且还可以给每个master设置多个slave节点,就可以继续增大集群的高并发能力。同时每个master之间通过ping监测彼此健康状态,就类似于哨兵模式了。当客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
面试官:Redis分片集群中数据是怎么存储和读取的?
候选人:在redis集群中是这样的,Redis 集群引入了哈希槽的概念,有 16384 个哈希槽,集群中每个主节点绑定了一定范围的哈希槽范围, key通过 CRC16 校验后对 16384 取模来决定放置哪个槽,通过槽找到对应的节点进行存储。取值的逻辑是一样的。
版权归原作者 学java的冲鸭 所有, 如有侵权,请联系我们删除。