
博主介绍:✌全网粉丝6W+,csdn特邀作者、博客专家、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于大数据技术领域和毕业项目实战✌
🍅文末获取项目联系🍅
基于Hadoop的2019年11月至2020年2月宁波天气数据分析
2019—2020 学年第二学期《分布式系统原理与技术》期末大作业评分表评价内容评价标准占比得分课程期末作业文档内容规范文章结构严谨,逻辑性强,表达层次清晰,语言准确,文字流畅,内容翔实。30分布式集群搭建Hadoop 集群搭建成功,可在浏览器查看其启动情况。MAVEN、IDEA 等软件安装与配置合理。20分布式计算生成 Mapreduce 的 Jar 包,可在虚拟机的主节点或本地计算机上进行分布式计算。20大数据采集使用数据爬虫采集的数据至少 100 条10运行的流畅性整个分布式计算过程,运行时没有产生什么逻辑错误或系统错误。10格式符合各项格式规范要求,且达到规定篇幅要求。10总分教师评语教师签名:2020 年 6 月 日
目 录
1 分布式集群搭建
1.1Hadoop集群搭建与配置
1.1.1Hadoop简介
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。它的目的是从单一的服务器扩展到成千上万的机器,将集群部署在多台机器,每个机器提供本地计算和存储。Hadoop 框架最核心的设计是 HDFS 和 MapReduce。
Hadoop 为在多个节点集群上处理数据提供了有效的框架,可以在多台机器上运行,提供数据的并行处理。Hadoop 可以处理海量数据量;可以处理繁多的数据类型,包括文本、网页、语音、图片、视频等;可以进行数据分析,提取有价值信息;处理速度快、时效高。Hadoop 有开源、分布式处理、可靠性和高容错性、可扩展性、费用低、数据本地化、传统数据处理系统等特点。
Hadoop 的核心组件有:Common、HDFS、MapReduce 等。其中,HDFS 为分布式文件系统,是 Hadoop 的主要存储系统,由主节点 Namenode 和从节点 Datanode 组成;MapReduce 是一种编程模型,主要用于海量数据的
图 1.1 Hadoop 生态系统
1.1.2Hadoop集群搭建
(1) 准备工作
- 安装包
⚫ CentOS-6.10
⚫ Java
⚫ Hadoop
图 1.2 CentOS-6.10
图 1.3 Java 安装包
图 1.4 Hadoop 安装包
- 软件
⚫
Vmware 15
图 1.5 Vmware 15 界面
Vmware 用于虚拟机的安装和运行等操作。
⚫ Xshell
图 1.6 Xshell 界面
Xshell 是 Windows 的 SSH 客户端,可以跟虚拟机进行远程连接。
⚫
WinSCP
图 1.7 WinSCP 界面
WinSCP 用于传输 Windows 和虚拟机上的文件。
⚫ Notepad++
图 1.8 Notepad++界面Notepad++用于修改虚拟中的文件。
(2) 新建虚拟机
在已经安装好的 Vmware 中新建虚拟机,安装 CentOS-6.10。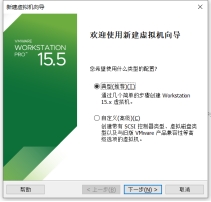
图 1.9 新建虚拟机
图 1.10 虚拟机安装完成界面
(3) 建立主节点
- 以 root 用户登录 namenode,更改 namenode 的主机名
图 1.11 更改 namenode 的主机名
关闭防火墙

图 1.12 关闭防火墙关闭主机防火墙
图 1.13 关闭主机防火墙
- 查看主机和虚拟机的 IP 地址
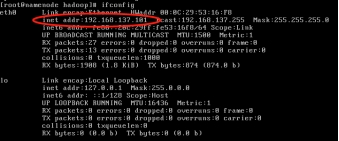
图 1.14 虚拟机 IP 地址

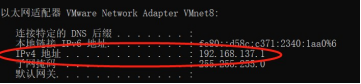
图 1.15 VMnet8 在主机上产生的 IP 地址
测试主机和虚拟机网络的连通性
图 1.16 主机连通虚拟网
图 1.17 虚拟网连通主机SSH 连接
打开 Xshell,新建 Session,选择 SSH 协议。连接成功后,可在主机中控制虚拟机。
图 1.18 SSH 连接
- SFTP 连接
打开 WinSCP,文件协议选择 SFTP。连接成功后,可以实现主机与虚拟机的文件互传。
图 1.19 WinSCP 连接
图 1.20 传输 Hadoop 和 JDK 安装包
(4) 建立从节点
新建虚拟机 datanode1,重复建立主节点的 1-5 步后,关闭虚拟机。对 datanode1 进行完整克隆,并将克隆虚拟机名称改为 namenode2。
图 1.21 克隆虚拟机
完成克隆后,使用 Xshell 建立两台新建虚拟机的连接,并建立免密 SSH 互访。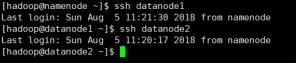
图 1.22 namenode 测试连通性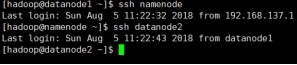
图 1.23 datanode1 测试连通性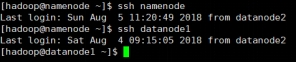
图 1.24 datanode2 测试连通性
(5) 安装 Hadoop
- 安装 JDK
将之前通过 WinSCP 传入 namenode 的 JDK 压缩包解压到 opt 目录中,并修改文件名为 jdk。
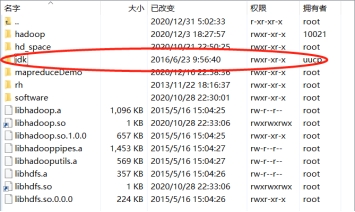
图 1.25 JDK 压缩包解压至 opt 文件夹中
配置 JDK 环境,编辑/etc/profile 文件,并加载使其立即生效。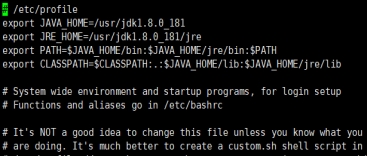
图 1.26 配置 JDK 环境变量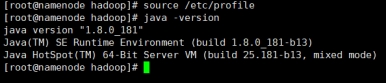
图 1.27 测试 JDK 是否正常工作
- 安装 Hadoop
⚫ 在 hadoop-env.sh 中配置 java 环境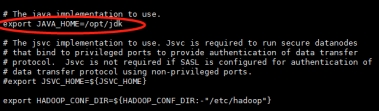
图 1.28 hadoop-env.sh 中配置 java 环境
⚫ 在 yarn-env.sh 中配置 java 环境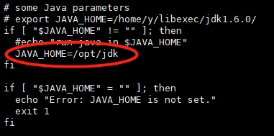
图 1.29 yarn-env.sh 中配置 java 环境
⚫ 配置 slave 节点
图 1.30 slave 节点
⚫ 使用 Notepad++软件配置 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
文件
图 1.31 namenode 文件修改
(6) 建立分布式集群
- 从节点上安装 JDK 和 Hadoop
- 启动 Hadoop

输入start-all.sh 命令启动hadoop 的各个监护进程;输入stop-all.sh 可以关闭hadoop 的各个监护进程。输入 jps 命令查看 hadoop 是否配置和启动成功。
图 1.32 查看 namenode、datanode1、datanode2 的 hadoop 配置和启动状态
- 登录查看
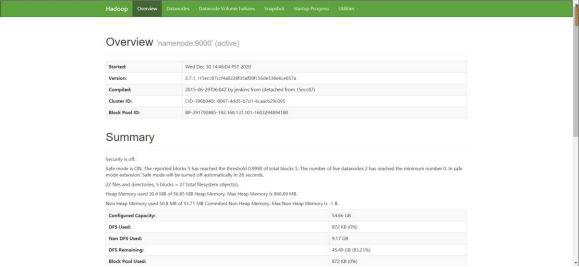
图 1.33 hadoop 启动成功界面可以用本地浏览器打开 50070,则代表 hadoop 安装成功。
1.2Maven安装与配置
1.2.1Maven简介
Maven 是用于项目管理和构建的工具,它可以对项目进行快速简单的构建。因为使用IDEA 或 Eclips 对项目进行构建,步骤比较零散,不好操作。为了让项目管理和构建更加简便,本文使用 Maven 对项目进行管理和构建。在 Maven 中,Ant 是专门的项目构建工具,配置需要明确源码包、class 文件和资源文件的位置。
1.2.2Maven工程的创建
(1) 下载 Maven(本文选择 Maven-3.3.3 版本)
图 1.34 Maven 目录
(2) 配置 Maven 的环境变量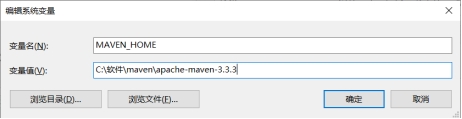
图 1.35 Maven 环境变量的配置
(3) 启动并查看 Maven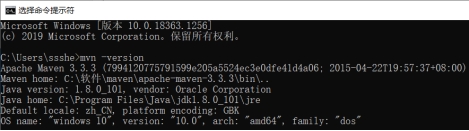
图 1.36 cmd 中查看 Maven 是否安装成功
(4) 下载 IntelliJ IDEA,并在 IDEA 中安装 Maven
图 1.34 IntelliJ IDEA 界面
- 在“设置”的 Maven 目录下设置 Maven home 的路径
图 1.35 设置 maven home 的路径
- 配置 Settings.xml 文件的本地仓库和镜像
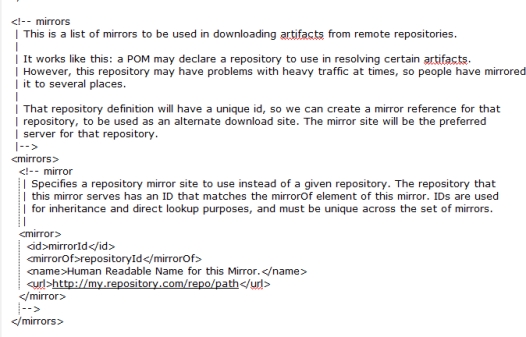
图 1.36 Settings.xml 镜像配置
(5) 新建 Maven 工程
新建 Maven 项目
图 1.37 新建 Maven 项目导入第三方库
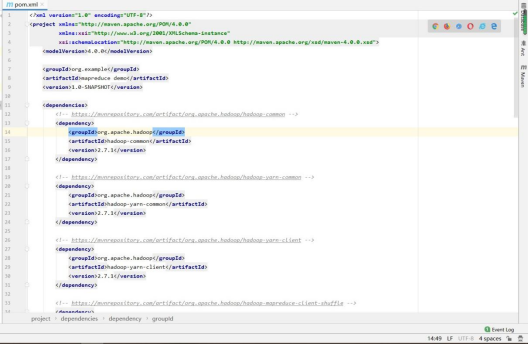
图 1.38 在 pom.xml 文件中导入第三方库自动下载 jar 包
jar 包下载成功后,Maven 工程即可使用。
1.3windows搭建hadoop开发环境
1.3.1在windows上搭建hadoop开发环境的原因
上文中已经创建好了 Maven 工程,本文在使用分布式计算框架 MapReduce 编程时,需要将 Java 工程打包,提交到 Yarn 上才可以在 hadoop 虚拟环境中运行。当 MapReduce 修改之后,Java 工程需要构建、打包,再次提交到 Yarn 上运行,步骤比较繁琐。



图 1.39 MapReduce 作业运行机制
因此为了简化这个过程,需要在 windows 上搭建 hadoop 开发环境,使程序可以直接在本地运行。
1.3.2windows搭建hadoop开发环境
(1) 下载 Hadoop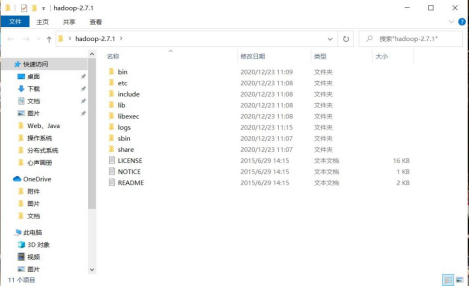
图 1.40 windows 上下载 hadoop-2.7.1 压缩包并解压
(2) 下载 winutils
图 1.41 windows 上下载 winutils 对应的 hadoop-2.7.1 版本
将 winutils 中的 winutils.exe 和 hadoop.dll 复制到 hadoop-2.7.1\bin 目录下:
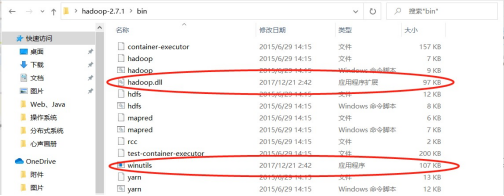
图 1.42 添加文件
(3) 配置环境变量
在 windows 中配置 HADOOP_HOME,完成 hadoop 开发环境在 windows 上的搭建。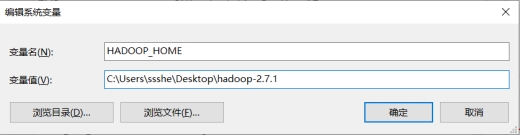
图 1.43 Hadoop 环境变量配置
(4) 查看 Hadoop 是否安装成功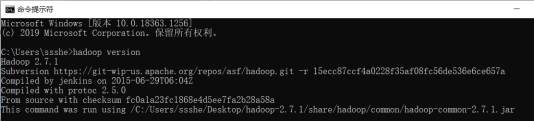
图 1.44 Hadoop 开发环境安装成功
2 2019 年 11 月至 2020 年 2 月宁波天气数据准备
2.1数据选取
由于自 2020 年 11 月以来,宁波气温时高时低。因此本文选取 2019 年 11 月-2020 年 2 月
的天气数据,进行统计分析,再与 2020 年 11 月-2021 年 1 月的天气数据进行比较,得出最终的数据分析。
2.2网页结构分析
本文使用的数据来自天气+(http://lishi.tianqi.com),其中宁波 2019 年 11 月-2020 年 2 月的天气链接如下表所示:
表 2.1 宁波 2019 年 11 月-2020 年 2 月天气数据链接
时间链接2019 年 11 月http://lishi.tianqi.com/ningbo/201911.html2019 年 12 月http://lishi.tianqi.com/ningbo/201912.html2020 年 1 月http://lishi.tianqi.com/ningbo/202001.html2020 年 2 月http://lishi.tianqi.com/ningbo/202002.html
为准确爬取天气网上宁波 2019 年 11 月-2020 年 2 月的天气数据,需要先对网页结构进行
分析。本文先打开 2019 年 11 月的天气页面,如下图所示: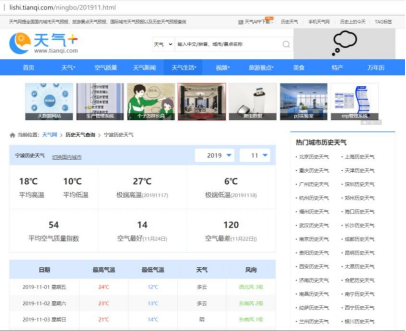
图 2.1 2019 年 11 月宁波天气页面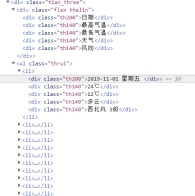
根据网页,本文需要爬取的数据为以“日期、最高气温、最低气温、天气、风向”为表头的整张表。为的到这一部分的网页结构,本文通过浏览器打开“开发者调试工具(F12)”,通过 Elements 获取该表的结构如下所示:
图 2.2 2019 年 11 月宁波天气主体表格网页结构根据该网页信息,可以获取本文需要提取数据的大体结构:
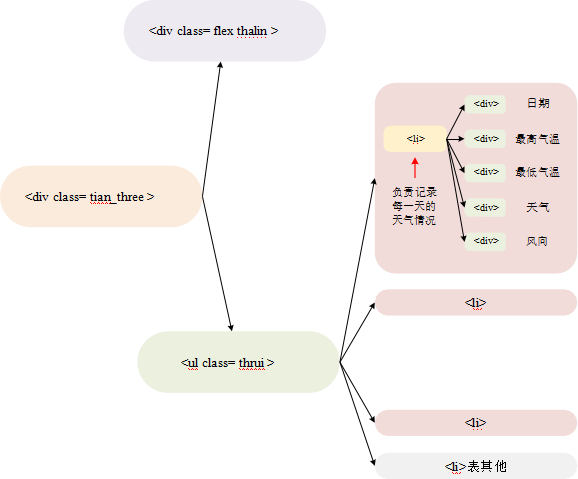
图 2.3 网页天气历史数据大体结构
2.3爬取数据
通过 2.2,本文对 2019 年 11 月数据所在位置的网页进行了大体的结构分析,再通过查看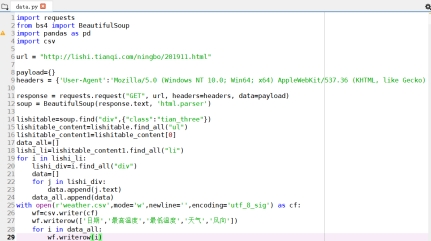
2019 年 12 月-2020 年 2 月的数据,发现网页结构并没有改变,主体都是一致的。因此,本文使用 python 先对 2019 年 11 月的天气数据进行爬取,代码如下所示(具体代码放在附录中):
图 2.4 2019 年 11 月天气数据爬取代码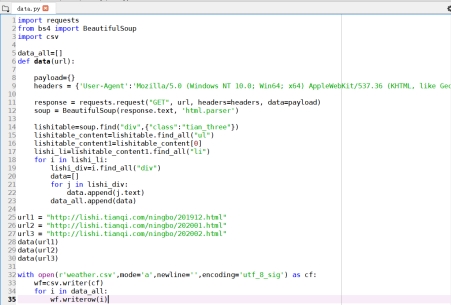
爬取好的数据放入 weather.csv 文件中,接下来对 2019 年 12 月-2020 年 2 月的数据进行爬取,也加入至 weather.csv 文件中,代码如下所示:
图 2.5 2019 年 12 月-2020 年 2 月天气数据爬取代码
最终共得到 119 条数据。
3 2019 年 11 月至 2020 年 2 月宁波天气数据分析
略
4 附录
略
版权归原作者 Maynor996 所有, 如有侵权,请联系我们删除。