
大家在日常的工作和学习过程中,都少不了与PDF文件打交道,很多的小伙伴都面临着将PDF文件中的文字、图片和表格数据提取出来的问题。能够对PDF文件中的文字、表格等数据进行编辑,网上现存的PDF提取的软件都需要付费操作!
小编今天就利用百行的python程序,来提取PDF文件中的文字、图片和表格数据。一起来看看吧。
01.程序执行效果
python库版本介绍
本次程序涉及到多个python第三方库与python3的内置库,而且不同的python库版本对于程序的兼容性不一致,因此我们首先来介绍一下使用到的python第三方库版本。
- PySimpleGUI 4.38.0
- pdfminer3k 1.3.4
- pdfplumber 0.5.27
- fitz 0.0.1.dev2
- pandas 1.1.3
02.程序讲解
看过视频之后,接下来就进行程序的展示,程序的展示主要分为以下的四个方面,分别是:
- PDF提取文字
- PDF提取图片
- PDF提取表格
- 交互界面的制作
03.PDF提取文字
PDF中文字是只允许我们进行只读,但是无法进行更改,所以我们要做的就是提取PDF中的文字信息,然后将提取到的文字写入到word文件当中,让我们能够进行后续的改写。对于文字的提取,我们利用的是pdfminer函数库,其程序如下图所示:
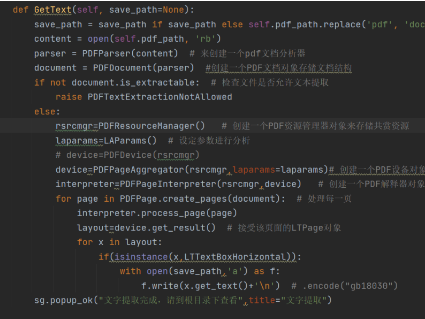
程序首先创建了PDFParser对象来进行PDF文档的分析,PDFDocument对象来将资源对象处理成我们需要的格式,PDFResourceManager对象用来保存共享数据内容;
而PDFPageInterpreter则是用来处理页面的内容。程序中通过for循环来针对PDF文件中的每一页内容进行处理,对于每一页的内容,通过layout来存储页面解析出来的各种对象;
包括文本,图片等信息。但是小编发现,对于图片的提取,pdfminer的效果很不好,所以后面针对于图片的提取;
小编采用的fitz库进行单独的处理,取得很好的图片提取效果。这里,我们先来看一下对于文本的处理结果。

我们的pdf是一个两页的pdf文档,我们只让程序去提取第一页的文本,从上图可以看出,程序完整的提取出第一页的文本,没有任何的错误。
04.PDF提取图片
对于文字的提取处理完毕后,接下来我们就来看一下如何提取pdf中的图片,并将其保存到本地。对于图片的提取,程序如下图所示:

上述的程序中,利用fitz库来提取PDF文档中的对象,然后通过字符串匹配来判断对象是不是图片类型,如果不是的话,我们直接进行跳过即可。如果判断对象是图片类型的话,我们边可以通过创建PixMap对象来提取图片,并保存到我们指定的路径下即可。结果如下图所示:
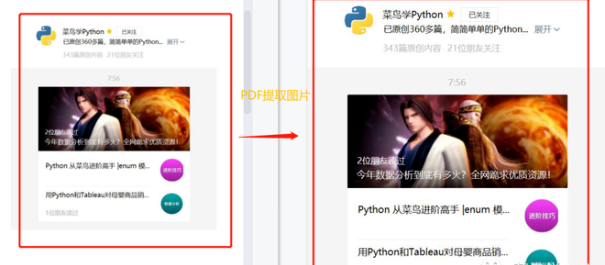
上图可以看出,程序正确的将图片进行了提取,从而达到了我们的图片提取的目的,可以在短短的几秒内完成pdf文档的所有图片的提取。
05.PDF提取表格
对于PDF中表格的提取,利用的是pdfplumber库,程序如下图所示:

程序中,通过pdfplumber库读取PDF文件,针对于文件中的每一页,提取表格数据,然后通过pandas将表格数据保存到根目录下的tables文件夹中,结果如下图所示。
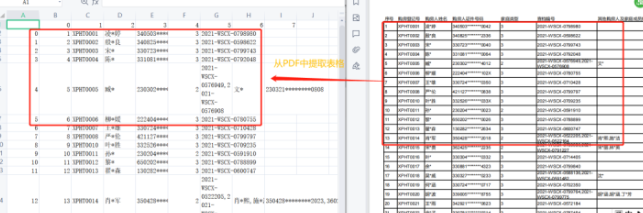
通过结果的展示,可以看出,对于PDF中的表格数据,程序能够做到较为准确的提取。
06.交互界面的制作
交互界面的制作,程序利用的是PySimpleGUI库进行处理,其部分程序如下图所示。
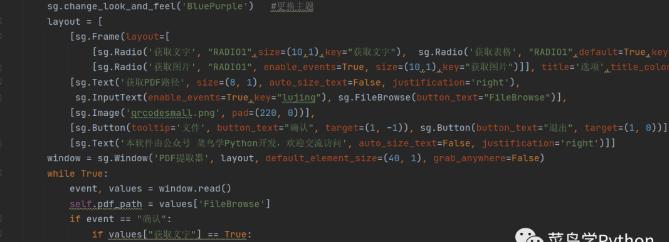
PySimpleGUI库集合了tkinter,wxpython、PyQt等GUI库的优势,其最重要的特点是用简单少量的代码就可以制作出精美的界面。程序执行的可视化界面如下图所示。
07.软件打包
为了方便大家的使用,小编将程序打包为exe文件,需要注意的是,为了减少大家对于exe文件执行时的报错,需要在win10(64bit)的环境下进行运行。大家可以下载exe文件,直接进行pdf文件内容的提取。
如何获取源码:
①3000多本Python电子书有 ②Python开发环境安装教程有 ③Python400集自学视频有 ④软件开发常用词汇有 ⑤Python学习路线图有 ⑥项目源码案例分享有 如果你用得到的话可以直接拿走,在我的QQ技术交流群里群号:754370353(纯技术交流和资源共享,广告勿入)以自助拿走 点击这里 领取
版权归原作者 Python是世界上最好的语言 所有, 如有侵权,请联系我们删除。