
我们坐在阳光下,我们转眼间长大,Yolo系列都到V8了,来看看怎么个事。目标检测不能没有Yolo,就像西方不能没有耶路撒冷。这个万能的目标检测框架圈粉无数,经典的三段式改进也是改造出很多论文,可惜我念书时的研究方向不是纯粹的目标检测,所以在做研究的时候没有用到过,但是同学用到的多啊,彼此交流也大概能知道Yolo的架构,这次决定好好学一学这个绝版Yolo。
先来看看它的自我介绍:
Ultralytics YOLOv8是由Ultralytics开发的YOLO物体检测和图像分割模型的最新版本。YOLOv8是一个尖端的、最先进的(SOTA)模型,它建立在以前YOLO版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。
YOLOv8的一个主要特点是其可扩展性。它被设计成一个框架,支持所有以前的YOLO版本,使其很容易在不同的版本之间切换,并比较其性能。这使得YOLOv8成为那些想利用最新的YOLO技术,同时又能使用他们现有的YOLO模型的用户的理想选择。
除了其可扩展性,YOLOv8还包括其他一些创新,使其成为广泛的物体检测和图像分割任务的吸引人的选择。这些创新包括一个新的骨干网络、一个新的无锚检测头和一个新的损失函数。YOLOv8的效率也很高,可以在各种硬件平台上运行,从CPU到GPU。
我来总结一下吧。第一:可以目标检测、图像分割,是最强的Yolo。第二:做成了框架,可以和前几个版本的Yolo做对比,这个做过科研的都知道咋回事了。第三:框架里有新的细节,创新的骨干、无锚检测头、新损失,效率更高,不过以我的经验来讲,快就要牺牲精度,除非真的有针对性提取信息的创新。
一、安装使用
1.1 安装
YoloV8有两种下载方法:pip、git
pip:
pip install ultralytics
** or**
git:
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e '.[dev]'
不过我建议直接去github网址下载,这样快一些,下载完成后进入到ultralytics目录下pip install 需要的库:
执行:
pip install -r requirements.txt -i https://pypi.douban.com/simple/
我加了豆瓣镜像会快一些,别忘了切换到自己的环境下去做这些事,不然白忙活。
1.2 数据处理
下载自己的数据集,比如测试用的coco8:
https://ultralytics.com/assets/coco8.zip
在yolov8目录下直接创建datasets文件夹,将coco8解压在下面就能使用,自己的数据集同样的格式就可以:
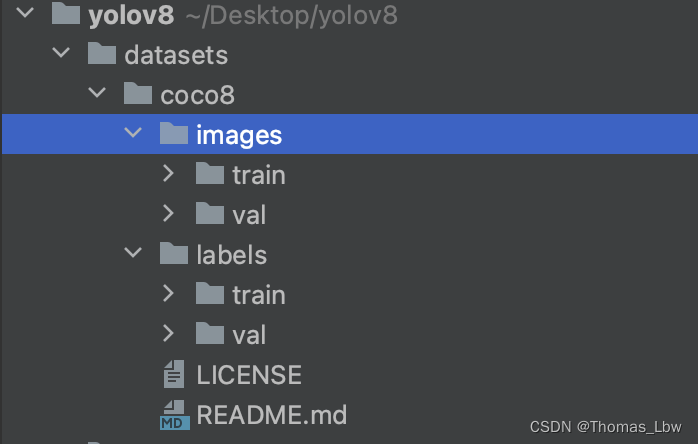
其实这种加载文件的细节在dataloader中,修改dataloader中的:v5loader.py,另外可以在v5augmentations.py中加入自己想要的数据增强方法,在里面通过设置概率p来控制数据增强的轻度大小。

二、Tasks(使用不同方式训练)
1.1 Detection
老版Yolo做的都是Detection,也就是传统的目标检测。两个目标:定位位置,识别类别。这两个目标对应着两个检测头,如果我没记错的话,这里并没有最新的YoloV8论文。
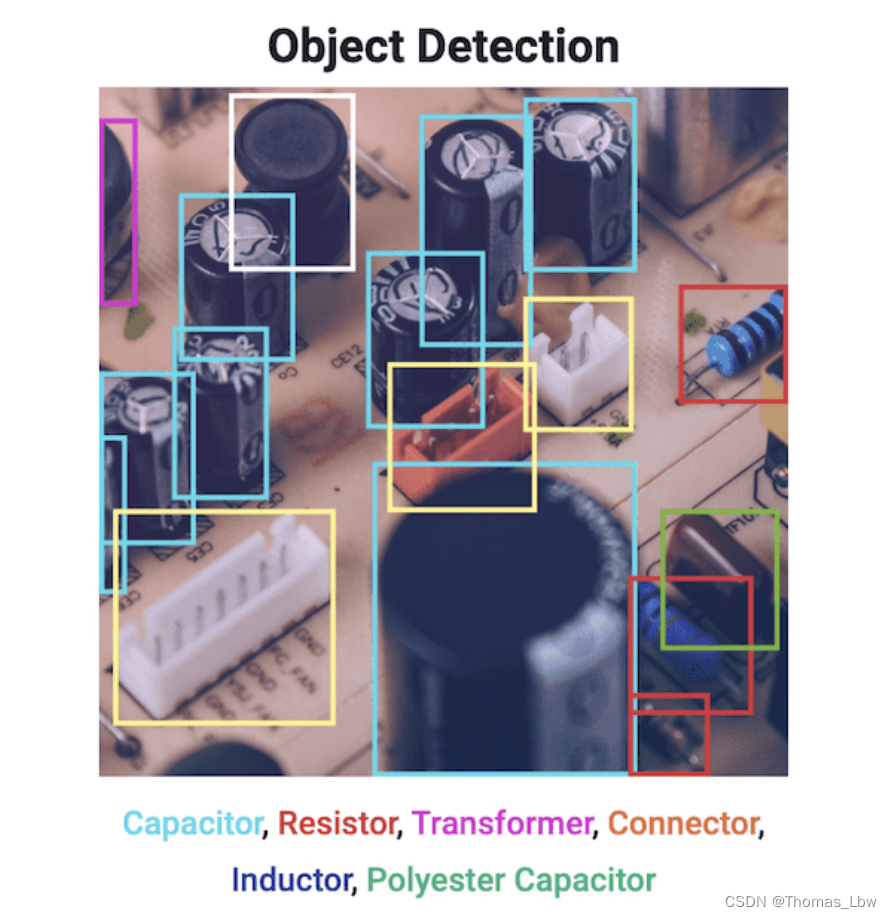
当你需要识别场景中感兴趣的物体,但又不需要知道物体的确切位置或其确切形状时,物体检测Detection方法是一个不错的选择。另外,YoloV8仍然将模型的结构定义在了yaml配置文件里。
tips:YOLOv8检测模型没有后缀,是 YOLOv8的默认模型,即 yolov8n.pt,预先在 COCO 上进行了训练。
1.1.1 Train
训练有两种方式:
一种是新建了py文件导入模型,另一种是命令启动。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640)
yolo task=detect mode=train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
我莫名觉得前者更好一点,哈哈哈哈。
具体参数如何配置以及配置后的影响请看下面链接:
Configuration - Ultralytics YOLOv8 Docs
1.1.2 Val
仍是两种方式:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
results = model.val() # no arguments needed, dataset and settings remembered
yolo task=detect mode=val model=yolov8n.pt # val official model
yolo task=detect mode=val model=path/to/best.pt # val custom model
1.1.3 Predict
展示效果:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
1.1.4 Export(导出)
导出这个简直太棒了,有开发框架果然还是方便啊。不然都得自己写。以导出onnx格式为例:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom trained
# Export the model
model.export(format="onnx")
看下面这个表格,不要太方便:
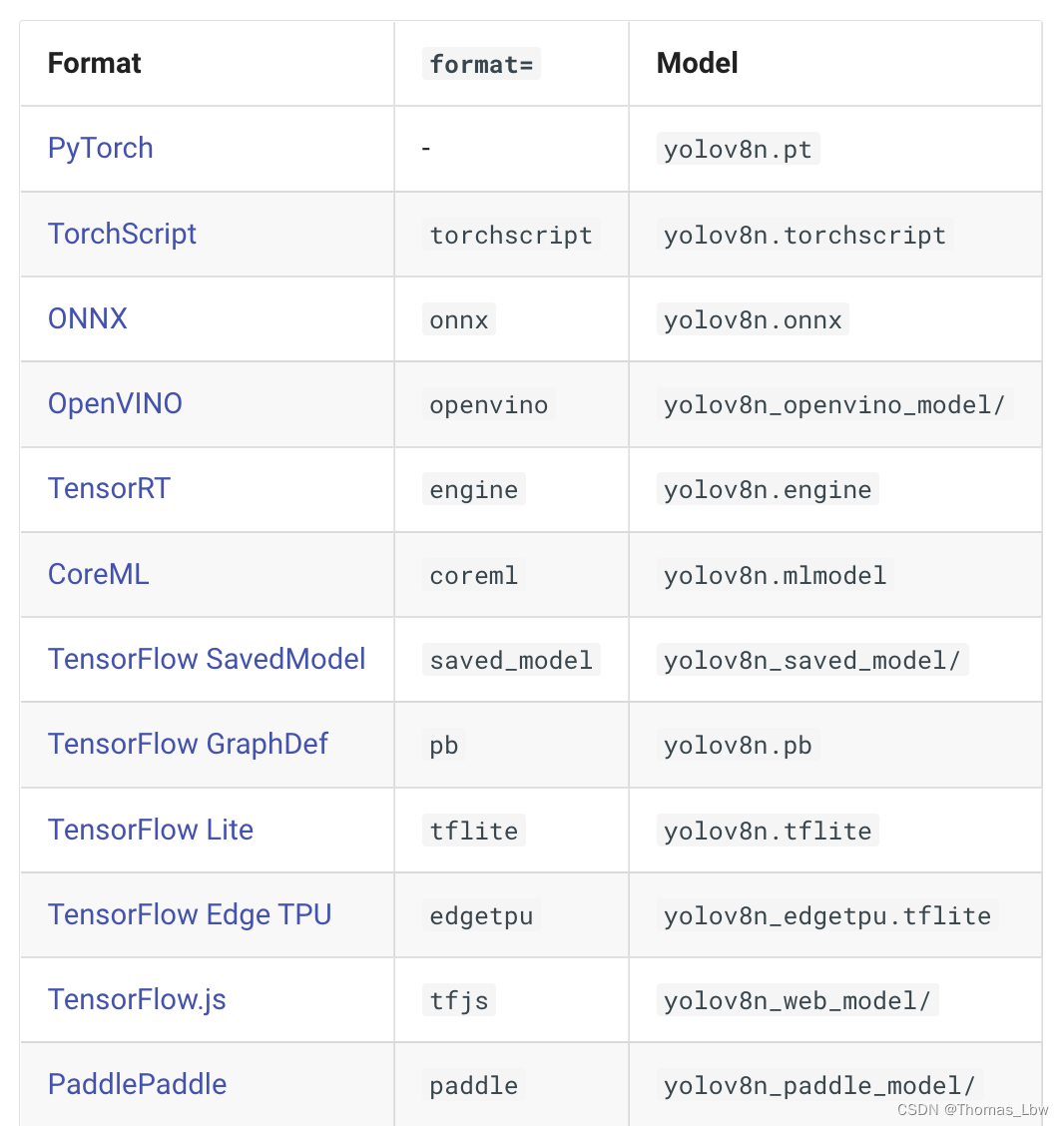
1.2 Segmentation
实例分割比目标检测分割更进一步,它涉及识别图像中的单个对象,并将它们与图像的其余部分分割开来。一般来说做实力分割好的网络都是U型,著名的UNet就是如此,因为需要判断每个像素点,所以使用全卷积神经网络,速度也慢很多。Yolo这种轻量的网络做Segmentation应该不如专业的Seger强,希望我被打脸。

训练方式类似Detection,不做过多介绍。
1.3 Classification
图像分类器的输出是一个单类标签和一个置信度评分。当您只需要知道图像属于哪个类,而不需要知道该类的对象位于何处或它们的确切形状时,图像分类非常有用。
Classidication是传统的机器学习项目了,一般的卷积神经网络后置一个全联接层在minist数据集上就可以达到98%的准确率,所以对于yoloV8这根本不是问题,问题是谁用这个做calssification啊,难道是我肤浅了?

那么至此,基本的介绍就到这。
二、网络结构
关于网络结构可以参考YoloV5,都是定义在ymal里的参数,然后通过参数去调用模块,这块对模块自定义者完全不友好:
yolov5模型配置yaml文件详解_yolov5 yaml_LaLaLaLaXFF的博客-CSDN博客
值得注意:Head不仅指检测头,还有关于图像融合的部分比如FPN、PAN等等,不过FPN、PAN也是通过小的组件实现的,所以完全可以通过配置参数组合自己想要的融合机制,也就是FPN的样子。
三、总结
总之,YoloV8仍然是在YoloV5基础上做改进,下一篇看看如何玩转yaml定义的网络结构,实现自己的创新点。
版权归原作者 Thomas_Lbw 所有, 如有侵权,请联系我们删除。