
训练模型:
** 下载好voc数据集,并传入所需的参数即可进行训练。**

参数配置:
"""
训练:
--model deeplabv3plus_mobilenet
--gpu_id 0
--year 2012_aug
--crop_val
--lr 0.01
--crop_size 513
--batch_size 4
--output_stride 16
测试:
--model deeplabv3plus_mobilenet
--gpu_id 0 --year 2012_aug
--crop_val
--lr 0.01
--crop_size 513
--batch_size 16
--output_stride 16
--ckpt checkpoints/best_deeplabv3plus_mobilenet_voc_os16.pth
--test_only
--save_val_results
"""
1.数据预处理部分
deeplab v3+默认使用voc数据集和cityspace数据集,图片预处理部分仅仅读取图片和对应的标签,同时对图片进行随机翻转、随机裁剪等常见图片预处理方式。
def get_dataset(opts):
""" Dataset And Augmentation
"""
if opts.dataset == 'voc':
train_transform = et.ExtCompose([
#et.ExtResize(size=opts.crop_size),
et.ExtRandomScale((0.5, 2.0)),
et.ExtRandomCrop(size=(opts.crop_size, opts.crop_size), pad_if_needed=True),
et.ExtRandomHorizontalFlip(), # 以给定的概率水平翻转给定的图像
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
if opts.crop_val:
val_transform = et.ExtCompose([
et.ExtResize(opts.crop_size),
et.ExtCenterCrop(opts.crop_size),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
else:
val_transform = et.ExtCompose([
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# 读取数据
train_dst = VOCSegmentation(root=opts.data_root, year=opts.year,
image_set='train', download=opts.download, transform=train_transform)
val_dst = VOCSegmentation(root=opts.data_root, year=opts.year,
image_set='val', download=False, transform=val_transform)
if opts.dataset == 'cityscapes':
train_transform = et.ExtCompose([
#et.ExtResize( 512 ),
et.ExtRandomCrop(size=(opts.crop_size, opts.crop_size)),
et.ExtColorJitter( brightness=0.5, contrast=0.5, saturation=0.5 ),
et.ExtRandomHorizontalFlip(),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
val_transform = et.ExtCompose([
#et.ExtResize( 512 ),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
train_dst = Cityscapes(root=opts.data_root,
split='train', transform=train_transform)
val_dst = Cityscapes(root=opts.data_root,
split='val', transform=val_transform)
return train_dst, val_dst
2.网络结构:
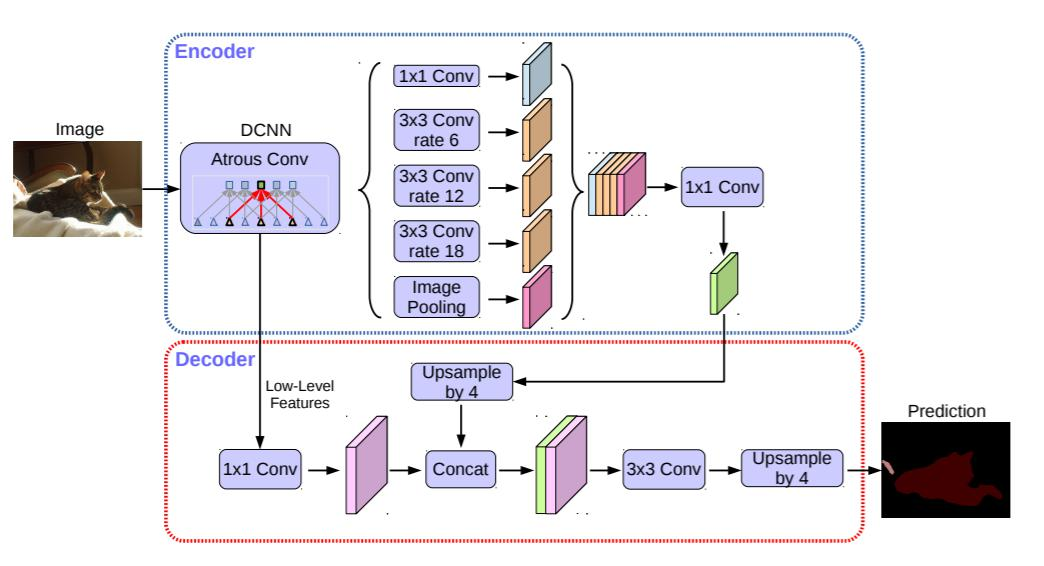
Ecoder部分
使用resnet作为网络的ecoder部分,resnet作为图像分类模型,将图像下采样了32倍,特征图信息损失比较大,尤其是目标分割而言,无法再下采样32倍的特征图中恢复细节信息,因此,resnet的最后三层,将根据需要的特征图的大小,将下采样换为空洞卷积。输出layer4经过ASPP层的结果(下采样16倍或者8倍),同时也输出layer1的结果。
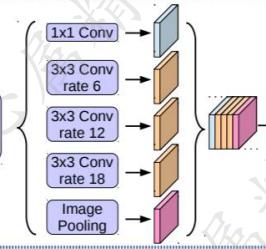
** ASPP层:**
** ** 如图所示,ASPP由不同空洞率的空洞卷积组成。以实现不同感受野的特征信息融合。此外,还有一个细节是空洞卷积的padding=空洞率,以保证输入输出特征图大小不改变。
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
modules = [
nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
]
super(ASPPConv, self).__init__(*modules)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(ASPPPooling, self).__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
def forward(self, x):
size = x.shape[-2:]
x = super(ASPPPooling, self).forward(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
def forward(self, x):
res = []
for conv in self.convs:
#print(conv(x).shape)
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
Decoder部分
Layer4的输出首先会经过ASPP模块,然后经过1*1的卷积调整通道数至256,然后上采样至layer1输出结果的大小,将layer1的输出结果的通道数经过1*1的卷积调整至48,将这两个结果进行拼接。经过3*3的卷积后,再经过1*1的卷积对输出进行预测。
代码如下:
class DeepLabHeadV3Plus(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHeadV3Plus, self).__init__()
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
#print(feature.shape)
low_level_feature = self.project( feature['low_level'] )#return_layers = {'layer4': 'out', 'layer1': 'low_level'}
#print(low_level_feature.shape)
output_feature = self.aspp(feature['out'])
#print(output_feature.shape)
output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
#print(output_feature.shape)
return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
dcoder的输出的特征图还是下采样4倍的结果,最终的输出需要继续进行双线性插值,调整到原特征图大小,最终代码如下:
class _SimpleSegmentationModel(nn.Module):
def __init__(self, backbone, classifier):
super(_SimpleSegmentationModel, self).__init__()
self.backbone = backbone
self.classifier = classifier
def forward(self, x):
input_shape = x.shape[-2:]
features = self.backbone(x)
x = self.classifier(features)
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
return x
本文转载自: https://blog.csdn.net/qq_52053775/article/details/127086195
版权归原作者 樱花的浪漫 所有, 如有侵权,请联系我们删除。
版权归原作者 樱花的浪漫 所有, 如有侵权,请联系我们删除。