
链接在这(需要科学上网)
Vicuna-13B: Best Free ChatGPT Alternative According to GPT-4 🤯 | Tutorial (GPU)
有人在B站转了人家的视频
ChatGPT:在你的本地电脑上运行Vicuna-13B 🤯|教程 (GPU)
下面就是部署的步骤,其中有一步需要科学上网
下载docker镜像
docker pull nvidia/cuda:11.7.0-cudnn8-devel-ubuntu18.04
因为他这个模型就认cuda:11.7版本,所以我用了人家官方模型。
运行docker镜像
docker run -it --name $容器的名字 --gpus all -p 3000:3000 $镜像的名字:镜像的版本号
进去之后试下
nvidia-smi
如果可以打印出GPU的情况,那就继续。
更新软件来源,初始化
apt-get update
apt-get upgrade
apt-getinstallwget -y
apt-getinstallgit -y
更新一些用到的命令
装miniconda3
wget https://mirrors.ustc.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
sha256sum Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
source ~/.bashrc
下载miniconda,在容器里走个conda环境管理,省时省力
启动python环境
conda create -n vinuca python=3.9
conda activate vinuca
这里名字打错了,但我也不想改了
搭载模型
git clone https://github.com/thisserand/FastChat.git
cd FastChat
pip3 installfschat==0.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install -e . (科学上网)
就
pip3 install -e .
这一句需要科学上网,因为有一步是
pip install git+https://huggingface...
,找了半天没找到不科学上网的方法。
mkdir repositories
cd repositories
git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py install
到这都蛮顺利的
cd../..
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g
然后download-model.py这一句怎么也过不去,需要改下他的原码,vim进去,照下面这样子改就行。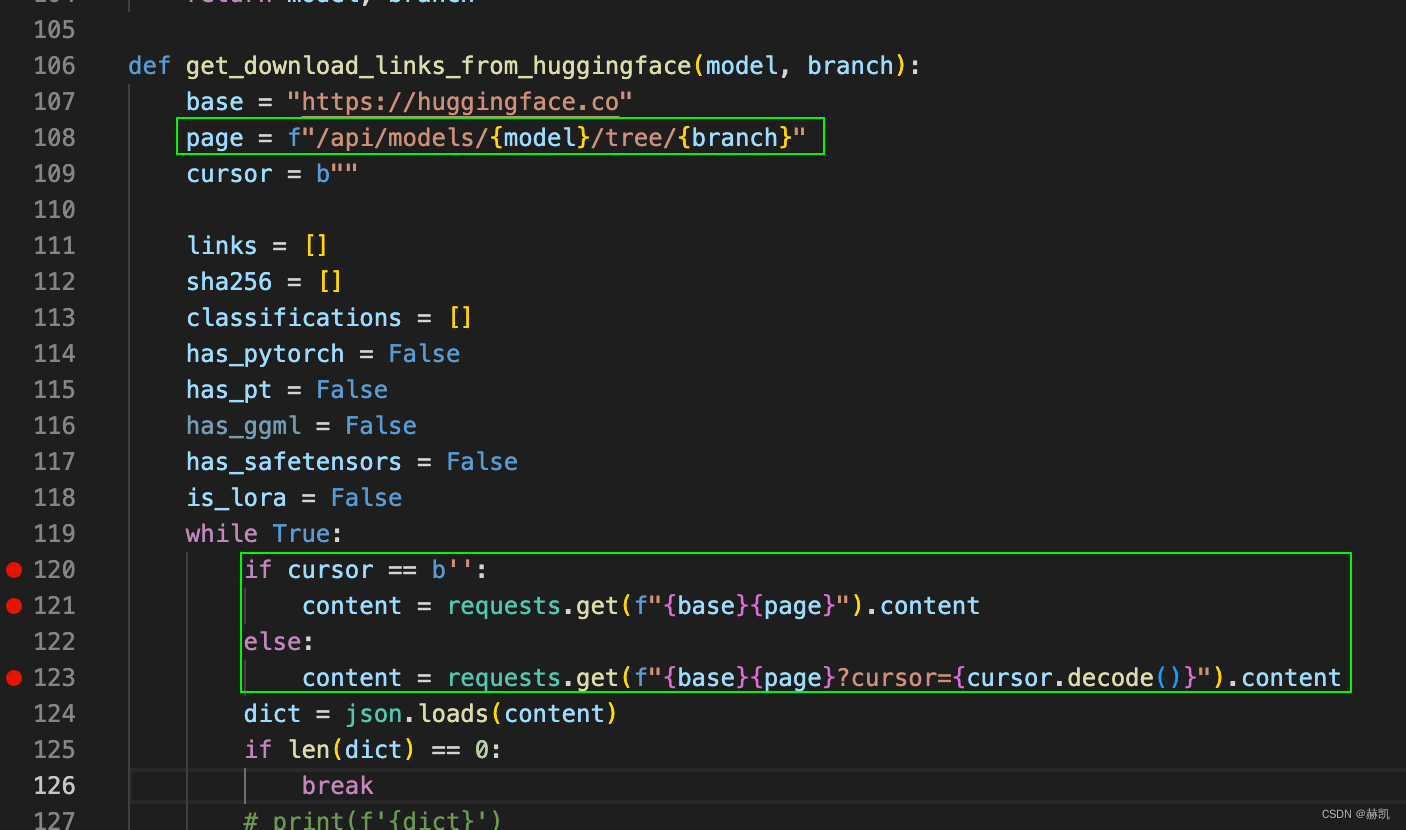
改完之后再执行就可以了
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g
使用
这个命令是走终端聊天,你一句,电脑一句,蛮有意思,我觉得不如chatglm6B。
python -m fastchat.serve.cli --model-name anon8231489123/vicuna-13b-GPTQ-4bit-128g --wbits 4 --groupsize 128
我做好的包
docker pull hekaii/vicuna:v2
进去,激活环境,cd Fast开头文件夹,输入命令就可以了
就酱
标签:
人工智能
本文转载自: https://blog.csdn.net/u010095372/article/details/130376651
版权归原作者 赫凯 所有, 如有侵权,请联系我们删除。
版权归原作者 赫凯 所有, 如有侵权,请联系我们删除。