
这篇论文介绍一下亚马逊开源的automl框架 – autogluon,只需要几行代码就可以轻松实现数据预处理、模型融合、择优参数以及模型选择等。autoGluon除了处理表格数据外,还可以处理图像和文本等多模态数据,最重要的是,你费尽心力调得参数可能比不上autoGluon的几行代码的模型性能。
paper:AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
autogluon文档:https://auto.gluon.ai/
autogluon代码:https://github.com/awslabs/autogluon
先看下autoGluon在表格数据上的使用姿势:
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
predictor = TabularPredictor(label='class').fit(train_data, time_limit=120)# Fit models for 120s
leaderboard = predictor.leaderboard(test_data)
预测结果如下图: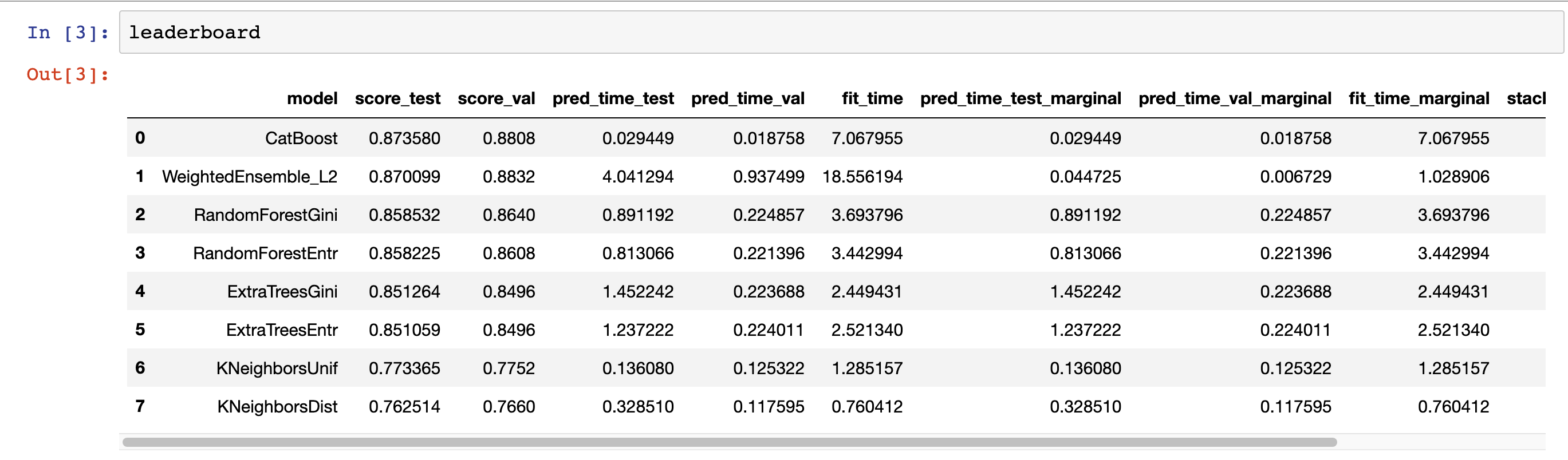
autoGluon还可以用来预测涉及图像和文本的任务,工具包:autogluon.multimodal,如下示例:
from autogluon.multimodal import MultiModalPredictor
from datasets import load_dataset
train_data = load_dataset("glue",'mrpc')['train'].to_pandas().drop('idx', axis=1)
test_data = load_dataset("glue",'mrpc')['validation'].to_pandas().drop('idx', axis=1)
predictor = MultiModalPredictor(label='label').fit(train_data)
predictions = predictor.predict(test_data)
score = predictor.evaluate(test_data)
下面以kaggle上泰坦尼克号人员幸存预测比赛为例,来测试下autoGluon框架的性能:
kaggle比赛链接
训练数据:train.csv
测试数据:test.csv
# import packagefrom autogluon.tabular import TabularDataset, TabularPredictor
# train model
train_data = TabularDataset('train.csv')id, label ='PassengerId','Survived'
predictor = TabularPredictor(label= label).fit(train_data.drop(columns=[id]))# prediction
test_data = TabularDataset('test.csv')
preds = predictor.predict(test_data.drop(columns=[id]))# 提交结果写到本地
submission = pd.DataFrame({id:test_data[id], label:preds})
submission.to_csv('submission.csv', index=False)
预测结果超过了90%的队伍,并且只用了几行代码,效果还是不错的!
本文转载自: https://blog.csdn.net/qq_32275289/article/details/126744484
版权归原作者 NLP_wendi 所有, 如有侵权,请联系我们删除。
版权归原作者 NLP_wendi 所有, 如有侵权,请联系我们删除。