
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
**🚀对毕设有任何疑问都可以问学长哦!**
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于实时车流的智能交通灯系统
设计思路
一、课题背景与意义
智能交通系统在现代城市中起着至关重要的作用,能够提高交通效率、减少交通拥堵和事故发生率。而交通灯作为交通系统的核心组成部分,对交通流量的控制和调度起着重要作用。传统的定时交通灯无法适应实时交通流量的变化,导致车辆等待时间长、交通效率低下。基于实时车流的智能交通灯系统通过结合深度学习和计算机视觉技术,能够实时感知交通流量并根据实际情况进行智能调度,提高交通效率,减少交通拥堵和碰撞事故的发生。
二、算法理论原理
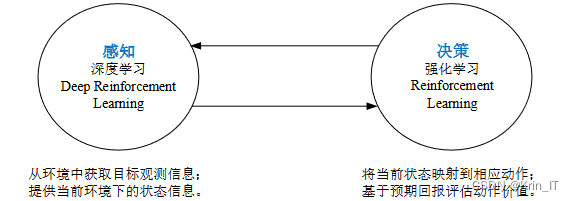
2.1 深度学习
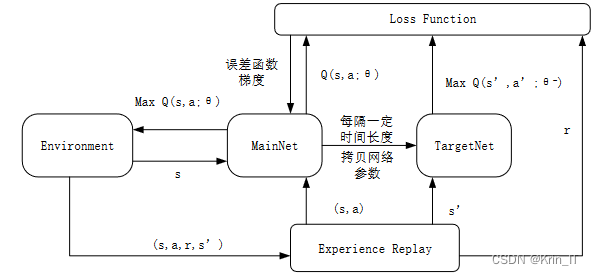
深度强化学习实质是将深度学习与强化学习两者相结合。深度学习基于神经网络,因此具有较好的感知能力,但是在决策能力方面有欠缺,而强化学习具有较好的决策能力。DQN是一种深度强化学习算法,结合了深度学习和Q-learning的思想,用于解决连续状态和动作空间较大的强化学习问题。DQN的核心思想是使用神经网络来近似Q值函数,以替代传统Q-learning中的Q表格。
DQN算法的基本思路和实现步骤:
- 定义深度神经网络模型:首先,定义一个深度神经网络(如卷积神经网络)作为Q值函数的近似器。该网络将状态作为输入,输出每个动作的Q值估计。
- 初始化经验回放缓冲区:创建一个经验回放缓冲区,用于存储智能体与环境的交互经验。每个经验包括当前状态、执行的动作、奖励、下一个状态以及一个表示是否为终止状态的标志。
- 采样并执行动作:根据当前状态和Q值函数选择一个动作。可以使用epsilon-greedy策略,以一定的概率选择最优动作,以一定的概率探索其他动作。执行选择的动作,并观察环境返回的下一个状态和奖励。
- 存储经验:将当前状态、执行的动作、奖励、下一个状态和终止状态标志存储到经验回放缓冲区中。
- 从经验回放缓冲区中随机采样:从经验回放缓冲区中随机采样一批经验,用于训练神经网络。
- 计算目标Q值:根据DQN的目标函数,使用当前的Q值网络和目标Q值网络计算目标Q值。
- 更新Q值网络:使用梯度下降法更新Q值网络的参数,使得预测的Q值与目标Q值尽可能接近。
- 更新目标Q值网络:定期更新目标Q值网络,将当前Q值网络的参数复制到目标Q值网络中。
- 重复步骤3至步骤8:不断地与环境交互、存储经验、训练神经网络,直到达到预定的停止条件(如达到最大训练步数或达到收敛条件)。
2.2 YOLOv5算法
车辆控制算法利用车辆内部传感器采集车辆的位置和行驶速度等信息,并通过人机交互界面提供给驾驶员。同时,车辆也将信息整理上传给雾层,并接收来自雾层的信息。通过与雾层的信息交互,车辆可以获得全面的交通信息,帮助驾驶员安全高效地驾驶车辆。基于收集到的数据,车辆可以进行简单的决策,例如根据道路状况判断是否能够在有效绿灯时间内通过路口。驾驶员接收到这些信息后,可以有意识地调整车辆的速度,避免抢红灯等危险行为,降低交通事故的可能性。如果系统判断车辆能够在有效绿灯时间内通过路口,驾驶员可以加速或保持现有速度,确保车辆顺利通过路口,提高道路的车辆吞吐量。
利用DQN算法可以对路口各相位的绿灯时长进行进一步优化。由于其他相位的道路可能仍有车辆排队等待,因此在计算绿灯时长时需要考虑一定范围内仍在移动的车辆。数据收集完成后,系统可以获取相应的交通状态。本研究将路口各道路靠近停止线的255m道路的车辆分布作为状态。每隔7.5m划分一小格,根据实时车流量信息,对应的道路车辆位置矩阵进行标记,有车则记为1,无车则记为0。如果车头和车尾分别在相邻的两个格中,认为车头所在的格记为1,车尾所在格记为0。从停止线开始向后,如果有一格为0,则从该0格开始向后找到第一个为1的格,即为该车道中第一辆没有排队的车辆。

在DQN算法中,将状态作为输入,根据策略决定选择Q值最大的动作执行,或者随机选择行为执行。每次只能选择一个动作,可以增加绿灯时间、减少绿灯时间或保持绿灯时间。在奖励方面,考虑到某个相位拥有通行权的同时意味着其他相位对应的车道处于红灯阶段,需要车辆停车等待。在获得进一步精确的绿灯时间分配后,需要判断绿灯时长是否合理并进行微调。长时间保持某个相位的绿灯可能导致其他相位的车辆等待时间过长,从而导致车辆平均等待时间增加,造成道路拥堵。
相关代码示例:
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95 # discount rate
self.epsilon = 1.0 # exploration rate
self.epsilon_decay = 0.995
self.epsilon_min = 0.01
self.learning_rate = 0.001
self.model = self._build_model()
def _build_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target = (reward + self.gamma *
np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己去实地拍摄并制作一个全新的数据集。我选择了不同的交通场景,包括城市道路、高速公路、十字路口等,以及各种交通流量情况。通过现场拍摄,我能够捕捉到真实的场景和多样的交通环境,包括车辆数量、车辆类型和车辆行为等。这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为基于实时车流的智能交通灯系统的研究提供有力的支持,并为交通领域的发展做出积极贡献。

为了增加数据集的多样性和数量,我使用了数据增强技术对自制的数据集进行扩充。这包括图像旋转、镜像、缩放、平移等操作,以生成更多样的交通场景样本。通过数据扩充,我能够提高模型的鲁棒性和泛化能力,使其能够更好地适应不同的交通环境和情况。此外,我还利用合成数据的方法,在现有数据的基础上生成了一些虚拟的交通场景,以增加数据集的规模。这些数据扩充的方法使得我的数据集更加完备和全面,为基于实时车流的智能交通灯系统的研究提供了更可靠的基础。
# 加载原始图像
image = Image.open('original_image.jpg')
# 定义数据扩充的变换操作
data_augmentation = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5), # 水平翻转
transforms.RandomVerticalFlip(p=0.5), # 垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 调整亮度、对比度、饱和度和色调
transforms.RandomRotation(degrees=(-30, 30)), # 随机旋转
transforms.RandomCrop(size=(224, 224)), # 随机裁剪
transforms.ToTensor() # 转换为张量
])
# 扩充数据
augmented_data = []
for _ in range(10): # 扩充10个样本
augmented_image = data_augmentation(image)
augmented_data.append(augmented_image)
# 将扩充后的数据转换为NumPy数组
augmented_data = np.stack(augmented_data)
3.2 实验环境搭建
研究采用Python进行VISSIM的二次开发,Python是一种简洁易懂的脚本语言,相对于C++等编程语言而言更加容易上手。Python拥有丰富的库函数,便于实现各种算法和模型优化,如深度学习、遗传算法和神经网络等。此外,Python还具有强大的数据挖掘和绘图能力。随着机器学习和深度学习等算法研究的发展,Python已经引起研究人员的广泛关注。
3.3 实验及结果分析
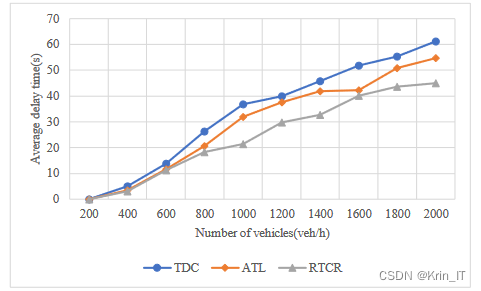
对于ATL控制方法,与RTCR控制方法相比,在车流量较小时它们的性能差异不大。当车流量为1200veh/h时,ATL和TDC的效果几乎相同,这是因为此时主干道和非主干道的车流量差异不大。但当车流量达到1300veh/h左右时,ATL控制的性能开始逐渐接近定时控制。在车辆排队长度这个性能指标上,RTCR是三种控制方法中表现最好的。尽管在后期随着车流量增加,车辆排队长度也有所增加,但RTCR控制的延迟更为靠后,并且在车流量为2000veh/h时,车辆排队长度仍然比其他两种方法小。这是因为RTCR控制根据车辆排队长度和平均等待时间等信息计算相位顺序和绿灯时长,而其他两种控制方法的相位顺序固定,无法根据车辆排队长度调节绿灯时间,因此相较于其他两种控制方式,RTCR能够降低车辆的平均排队长度。总体上看,RTCR控制方法在平均车辆排队长度这个性能指标上表现最好。
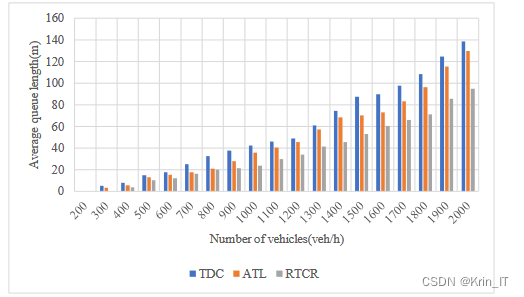
对于车辆的平均延误时间,可以观察到三种控制方法中,TDC控制方法的性能最差。随着车流量的增加,TDC的车辆平均延误时间迅速增加。ATL控制方法在车流量较小的情况下表现良好,特别是在主干道和非主干道车流量差异较大时,性能优势更为明显。然而,随着车流量继续增大,主干道和非主干道车流量差异缩小,ATL的性能逐步接近TDC。RTCR是三种方法中性能最好的,它的车辆平均延误时间最小,并且随着车流量的增加,车辆平均延误时间的增长速度最慢。这是因为在决定相位顺序时,RTCR考虑了车辆的平均等待时间因素,从而降低了车辆的平均延误时间。
相关代码示例:
import random
def get_traffic_volume():
# 模拟获取道路实时车流量的函数
return random.randint(0, 200) # 随机生成一个车流量值
def calculate_phase_duration(volume):
# 根据实时车流量计算相位时长的函数
if volume < 100:
return 30 # 低车流量时,设置较短的相位时长
else:
return 60 # 高车流量时,设置较长的相位时长
def control_traffic_lights():
while True:
volume = get_traffic_volume() # 获取道路实时车流量
duration = calculate_phase_duration(volume) # 根据车流量计算相位时长
# 控制交通灯相位时长
# 这里省略具体的交通灯控制代码,可以根据具体情况使用相应的API或控制硬件
print("Current traffic volume:", volume)
print("Phase duration:", duration)
print("Traffic lights controlled.")
# 延时一段时间后进行下一次控制
# 这里省略延时代码,可以使用time.sleep()函数等进行延时
# 主函数,启动交通灯控制
if __name__ == '__main__':
control_traffic_lights()
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/136009758
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。