
缓存的基本原理
对于前端来说,缓存主要分为浏览器缓存(比如 localStorage、sessionStorage、cookie等等)以及http缓存,也是本文主要讲述的。
当然叫法也不一样,比如客户端缓存大概包括浏览器缓存和http缓存
所谓http缓存,顾名思义,是将某一次的响应结果保存在客户端(比如浏览器)中,而后续的请求仅需要从缓存中读取即可,极大的降低了服务器的处理压力。
http缓存的原理如下:
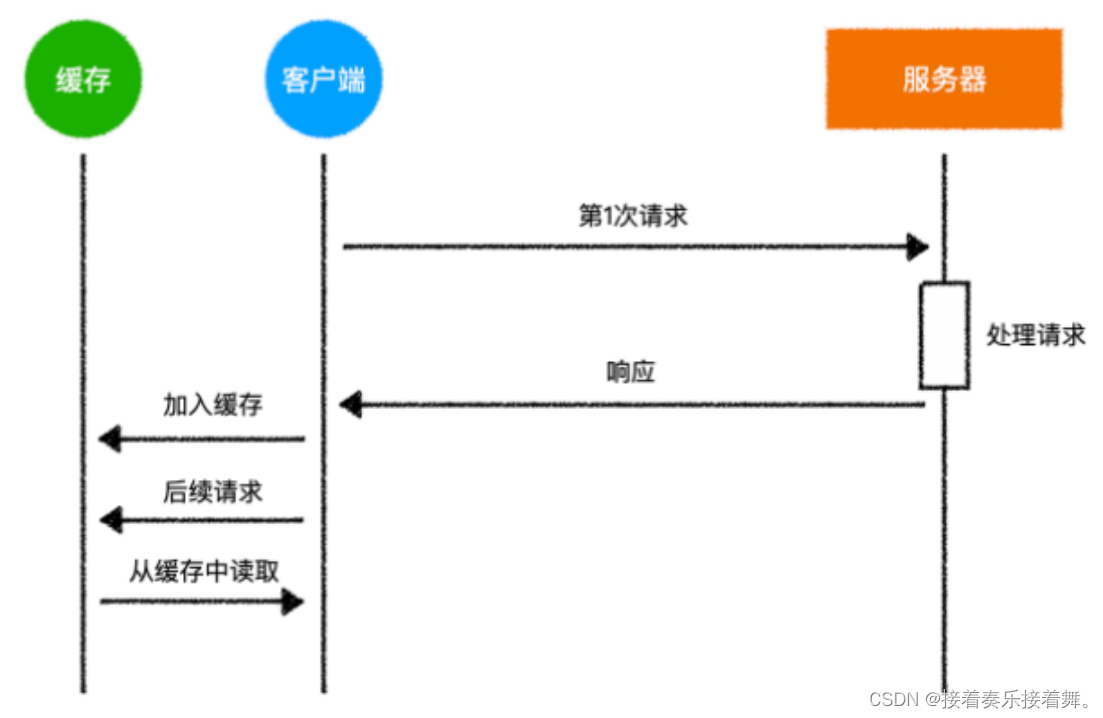
这只是一个简易的原理图,实际情况可能有差异
这里就设计到一个缓存策略的问题,这些问题包括:
- 哪些资源需要加入到缓存,哪些不需要?
- 缓存的时间是多久呢?
- 如果服务器的资源有改动,客户端如何更新缓存呢?
- 如果缓存过期了,可是服务器上的资源并没有发生变动,又该如何处理呢?
- …
要回答这些问题,就必须要清楚
http
中关于缓存的协议
理解了http的缓存协议,自然就能回答上面的问题了。
来自服务器的缓存指令
当客户端发出一个
get
请求到服务器,服务器可能有以下的内心活动:「你请求的这个资源,我很少会改动它,干脆你把它缓存起来吧,以后就不要来烦我了」
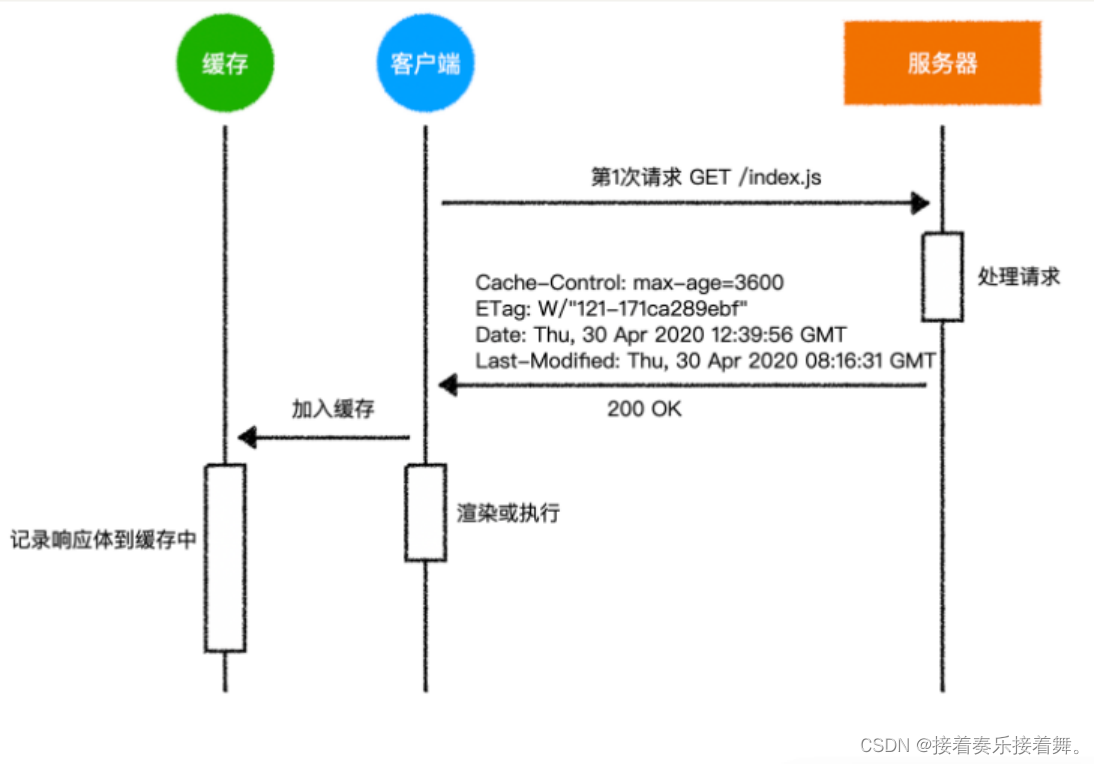
为了表达这个美好的愿望,服务器在响应头中加入了以下内容:
Cache-Control: max-age=3600
ETag: W/"121-171ca289ebf"
Date: Thu, 30 Apr 2020 12:39:56 GMT
Last-Modified: Thu, 30 Apr 2020 08:16:31 GMT
这个响应头表达了下面的信息:
Cache-Control: max-age=3600,我希望你把这个资源缓存起来,缓存时间是3600秒(1小时)ETag: W/"121-171ca289ebf",这个资源的编号是W/"121-171ca289ebf"Date: Thu, 30 Apr 2020 12:39:56 GMT,我给你响应这个资源的服务器时间是格林威治时间2020-04-30 12:39:56Last-Modified: Thu, 30 Apr 2020 08:16:31 GMT,这个资源的上一次修改时间是格林威治时间2020-04-30 08:16:31
这个美好的缓存愿望,就这样通过响应头传递给客户端了
如果客户端是其他应用程序,可能并不会理会服务器的愿望,也就是说,可能根本不会缓存任何东西。
但是凑巧客户端是一个浏览器,它和服务器一直以来都是相亲相爱的小伙伴,当它看到服务器的这个响应头表达的美好愿望后,立即忙起来:
- 浏览器把这次请求得到的响应体缓存到本地文件中
- 浏览器标记这次请求的请求方法和请求路径
- 浏览器标记这次缓存的时间是3600秒
- 浏览器记录服务器的响应时间是格林威治时间
2020-04-30 12:39:56 - 浏览器记录服务器给予的资源编号
W/"121-171ca289ebf" - 浏览器记录资源的上一次修改时间是格林威治时间
2020-04-30 08:16:31
这一次的记录非常重要,它为以后浏览器要不要去请求服务器提供了各种依据。
来自客户端的缓存指令
当客户端收拾好行李,准备再次请求
GET /index.js
时,它突然想起了一件事:我需要的东西在不在缓存里呢?
此时,客户端会到缓存中去寻找是否有缓存的资源
寻找的过程如下:
- 缓存中是否有匹配的请求方法和路径?
- 如果有,该缓存资源是否还有效呢?
以上两个验证会导致浏览器产生不同的行为


要验证是否有匹配的缓存非常简单,只需要验证当前的请求方法
GET
和当前的请求路径
/index.js
是否有对应的缓存存在即可
如果没有,就直接请求服务器,就和第一次请求服务器时一样,这种情况没有什么好讨论的
关键在于验证缓存是否有效
如何验证呢?
非常简单,就是把
max-age + Date
,得到一个过期时间,看看这个过期时间是否大于当前时间,如果是,则表示缓存还没有过期,仍然有效,如果不是,则表示缓存失效。
缓存有效
当浏览器发现缓存有效时,完全不会请求服务器,直接使用缓存即可得到结果
此时,如果你断开网络,会发现资源仍然可用
这种情况会极大的降低服务器压力,但当服务器更改了资源后,浏览器是不知道的,只要缓存有效,它就会直接使用缓存
缓存无效
当浏览器发现缓存已经过期,它并不会简单的把缓存删除,而是抱着一丝希望,想问问服务器,我这个缓存还能继续使用吗?
于是,浏览器向服务器发出了一个带缓存的请求
所谓带缓存的请求,无非就是加入了以下的请求头:
If-Modified-Since: Thu, 30 Apr 2020 08:16:31 GMT
If-None-Match: W/"121-171ca289ebf"
它们表达了下面的信息:
If-Modified-Since: Thu, 30 Apr 2020 08:16:31 GMT,亲,你曾经告诉我,这个资源的上一次修改时间是格林威治时间2020-04-30 08:16:31,请问这个资源在这个时间之后有发生变动吗?If-None-Match: W/"121-171ca289ebf",亲,你曾经告诉我,这个资源的编号是W/"121-171ca289ebf,请问这个资源的编号发生变动了吗?
其实,这两个问题可以合并为一个问题:快说!资源到底变了没有!
之所以要发两个信息,是为了兼容不同的服务器,因为有些服务器只认
If-Modified-Since
,有些服务器只认
If-None-Match
,有些服务器两个都认
目前的很多服务器,只要发现
If-None-Match存在,就不会去看``If-Modified-Since`
If-Modified-Since是
http1.0版本的规范,
If-None-Match是
http1.1的规范
此时,问题又抛给了服务器,接下来,就是服务器的表演时间了
服务器可能会产生两个情况:
- 缓存已经失效
- 缓存仍然有效
如果是第一种情况——缓存已经失效,那么非常简单,服务器再次给予一个正常的响应(响应码
200
带响应体),同时可以附带上新的缓存指令,这就回到了上一节——来自服务器的缓存指令
这样一来,客户端就会重新缓存新的内容
但如果服务器觉得缓存仍然有效,它可以通过一种极其简单的方式告诉客户端:
- 响应码为
304 Not Modified - 无响应体
- 响应头带上新的缓存指令,见上一节——来自服务器的缓存指令
这样一来,就相当于告诉客户端:「你的缓存资源仍然可用,我给你一个新的缓存时间,你那边更新一下就可以了」
于是,客户端就继续happy的使用缓存了
这样一来,可以最大程度的减少网络传输,因为如果资源还有效,服务器就不会传输消息体
它们完整的交互过程如下:

细节
上面描述了客户端缓存的基本概念和过程
但其中仍然有不少细节值得我们注意
Cache-Control
在上述的讲解中,
Cache-Control
是服务器向客户端响应的一个消息头,它提供了一个
max-age
用于指定缓存时间。
实际上,
Cache-Control
还可以设置下面一个或多个值:
public:指示服务器资源是公开的。比如有一个页面资源,所有人看到的都是一样的。这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用。本着「我告知,你随意」的原则,http协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己。private:指示服务器资源是私有的。比如有一个页面资源,每个用户看到的都不一样。这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用。本着「我告知,你随意」的原则,http协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己。no-cache:告知客户端,你可以缓存这个资源,但是不要直接使用它。当你缓存之后,后续的每一次请求都需要附带缓存指令,让服务器告诉你这个资源有没有过期。见:「来自客户端的缓存指令 - 缓存无效」no-store:告知客户端,不要对这个资源做任何的缓存,之后的每一次请求都按照正常的普通请求进行。若设置了这个值,浏览器将不会对该资源做出任何的缓存处理。max-age:不再赘述
比如,
Cache-Control: public, max-age=3600
表示这是一个公开资源,请缓存1个小时。
Expire
在
http1.0
版本中,是通过
Expire
响应头来指定过期时间点的,例如:
Expire: Thu, 30 Apr 2020 23:38:38 GMT
到了
http1.1
版本,已更改为通过
Cache-Control
的
max-age
来记录了。
记录缓存时的有效期
浏览器会按照服务器响应头的要求,自动记录缓存到本地文件,并设置各种相关信息
在这些信息中,有效期尤为关键,它决定了这个缓存可以使用多久
浏览器会根据服务器不同的响应情况,设置不同的有效期
具体的有效期设置,按照下面的流程进行:

例如,当
max-age
设置为0时,缓存立即过期
虽然立即过期,但缓存仍然被记录下来,后续的请求通过缓存指令发送到服务器,来确认资源是否被更改。
因此,
Cache-Control: max-age=0
类似于
Cache-Control: no-cache
Pragma
这是
http1.0
版本的消息头
当该消息头出现在请求中时,是向服务器表达:不要考虑任何缓存,给我一个正常的结果。
在
http1.1
版本中,可以在请求头中加入
Cache-Control: no-cache
实现同样的含义。
是的,
Cache-Control可以出现在请求头中
在
Chrome
浏览器中调试时,如果勾选了
Disable cache
,则发送的请求中会附带该信息

Vary
有的时候,是否有缓存,不仅仅是判断请求方法和请求路径是否匹配,可能还要判断头部信息是否匹配。
此时,就可以使用
Vary
字段来指定要区分的消息头
比如,当使用
GET /personal.html
请求服务器时,请求头中
cookie
的值不一样,得到的页面也不一样
如果还按照之前的做法,仅仅匹配请求方法和请求路径,如果
cookie
变动,你可能得到的仍然是之前的页面。
正确的做法如下:

使用版本号或hash
如果你是一个前端工程师,使用过
vue
或其他基于
webpack
搭建的工程
你会发现打包的结果中很多文件名类似于这样:
app.68297cd8.css
文件的中间部分使用了
hash
值
这样做的好处是,可以让客户端大胆的、长时间的缓存该文件,减轻服务器的压力
当文件改动后,它的文件
hash
值也会随之而变,比如变成了
app.446fccb8.css
这样一来,客户端要请求新的文件时,就会发现路径从
/app.68297cd8.css
变成了
app.446fccb8.css
,由于之前的缓存路径无法匹配到,因此就会发送新的请求来获取新资源了。
以上是现代流行的做法。
而在古老的年代,还没有构建工具出现时,人们使用的办法是在资源路径后面加入版本号来获取新版本的文件
比如,页面中引入了一个css资源
app.css
,它可能的引入方式是:
<linkhref="/app.css?v=1.0.0">
这样一来,缓存的路径是
/app.css?v=1.0.0
当服务器的版本发生变化时,可以给予新的版本号,让html中的路径发生变动
<linkhref="/app.css?v=1.0.1">
由于新的路径无法命中缓存,于是浏览器就会发送新的普通请求来获取这个资源
总结
最后,通过客户端和服务器两位大佬的视角,来总结一下以上内容
服务器视角
服务器无法知道客户端到底有没有像浏览器那样缓存文件,它只管根据请求的情况来决定如何响应
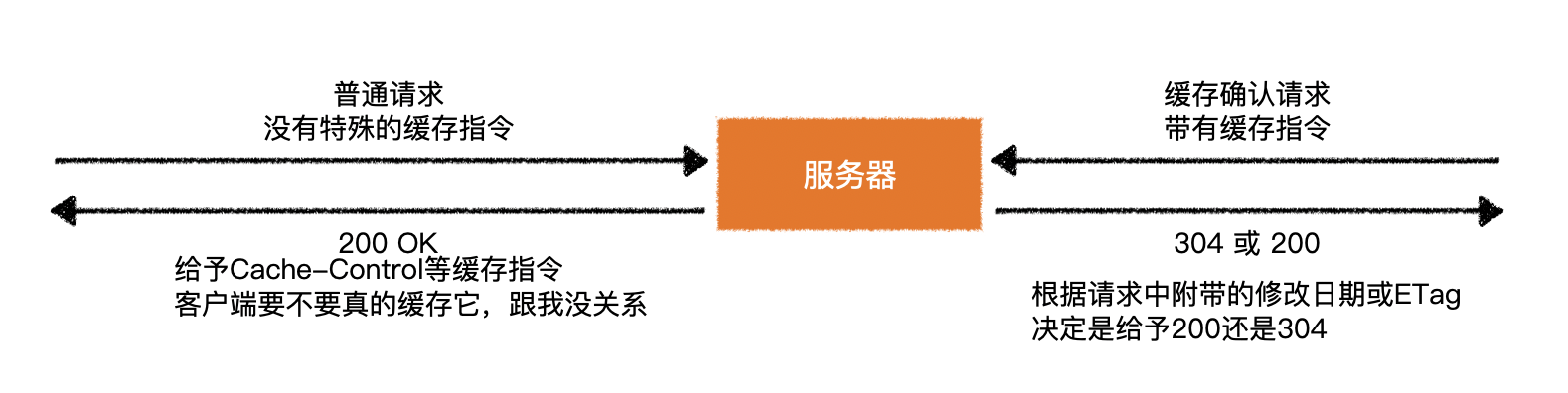
很多后端语言搭建的服务器都会自带自己的默认缓存规则,当然也支持不同程度的修改
浏览器视角
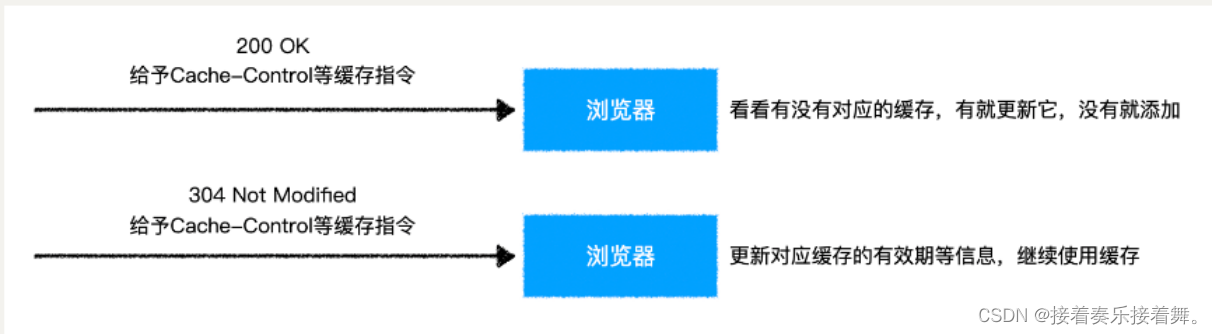
浏览器在发出请求时会判断要不要使用缓存

当收到服务器响应时,会自动根据缓存指令进行处理
版权归原作者 接着奏乐接着舞。 所有, 如有侵权,请联系我们删除。