
推荐一套企业级开源充电桩平台:完整代码包含多租户、硬件模拟器、多运营商、多小程序,汽车 电动自行车、云快充协议;——(慧哥)慧知开源充电桩平台;https://liwenhui.blog.csdn.net/article/details/134773779?spm=1001.2014.3001.5502
1.引言
,一直做后台开发,从程序员一路做到[架构师海量服务之道贯彻始终。
所以就从海量服务之道说起,聊聊在腾讯如何做系统设计。
1.1.海量服务之道
腾讯早期业务的高速发展,催生了一种独特的技术哲学,名为"胖子的柔道"。
"胖子的柔道"在腾讯内部被称为海量服务之道,这象征着以柔和和灵活的方式处理复杂的系统问题。而这个理念具体体现在腾讯的海量服务之道中,则由2个价值技术观和7个技术手段,4个意识组成。技术价值观是总体思想,意识是一些原则,技术手段是实现技术价值观的手段或者方法。
海量服务之道,在腾讯根深蒂固,所有后台答辩基本上都是按照上面这个框架来。
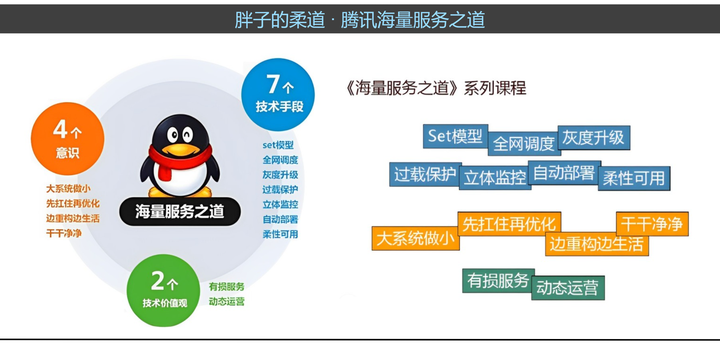
以下这些技术手段共同构成了海量服务之道的实施框架,旨在确保服务在面对海量用户请求和复杂场景时能够保持稳定和高效:
- Set模型:通过将服务划分为不同的集合,实现服务的模块化和可扩展性。
- 立体监控:从多个维度对系统进行实时监控,及时发现并解决问题。
- 自动部署:通过自动化工具实现服务的快速部署和更新,减少人工干预和错误。
- 全网调度:根据网络状况和用户请求的分布情况,动态调整服务资源的分配和调度策略。
- 柔性可用:在部分服务出现故障时,通过降级、容错等机制保证整体服务的可用性。
- 灰度升级:通过逐步将新版本服务推送给部分用户,实现平滑过渡和风险控制。
- 过载保护:在系统负载过高时,通过限流、熔断等机制保护核心服务不受影响。
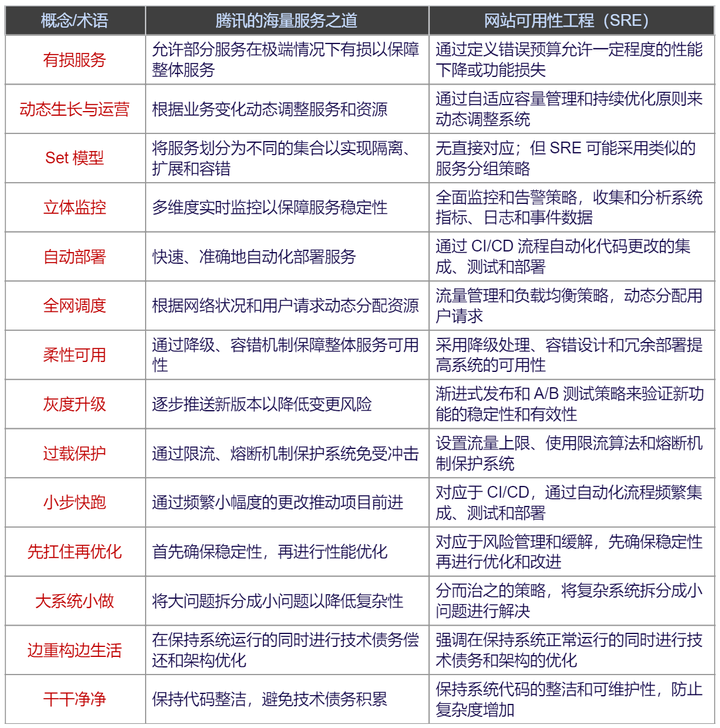
现在我们知道,海量服务之道其实就是业界的SRE方法论,尽管在当时海量服务之道出现的时候还没有SRE。
网站可用性工程(SRE,即Site Reliability Engineering)是一种针对网站和系统的工程化方法,旨在提高系统的可用性、稳定性和效率。SRE团队通常负责确保服务的高可用性、减少故障、优化性能,并与开发团队紧密合作,共同设计和改进系统架构。
用SRE的术语重新表述腾讯的海量服务之道,可以有如下的对应关系:
1.2.技术潮流的演变
软件工程,一路向前,势头不减。
从海量服务之道演进到SRE(网站可靠性工程),再到DevOps,再到CI/CD(持续集成/持续部署),再到当下的平台工程,在扬弃中不断发展,有变也有不变。
变的是:
技术与工具:随着技术的不断发展和创新,软件工程中使用的具体技术和工具在不断变化。海量服务之道可能强调分布式系统的管理和扩展,而SRE则更加注重可靠性和效率。DevOps引入了跨职能团队的协作和自动化工具,CI/CD则进一步强调了持续集成和持续部署的实践。平台工程则专注于提供开发者自助服务和内部平台的优化。
流程与方法论:随着软件工程实践的演进,开发、测试和部署的流程也在不断变化。从传统的瀑布模型到敏捷开发,再到DevOps的持续交付,软件开发的流程变得越来越灵活和快速。同时,方法论也从关注单个系统的可靠性,发展到关注整个组织的效率和创新能力。
组织结构与文化:随着软件工程实践的演变,组织结构也在不断变化。传统的垂直组织结构逐渐被跨职能的、扁平化的团队所取代。此外,组织文化也从命令与控制转变为更加开放、协作和创新的氛围。
不变的是:
对质量的追求:无论软件工程实践如何变化,对质量的追求始终是不变的。无论是海量服务之道、SRE、DevOps、CI/CD还是平台工程,都强调通过各种手段提高软件的质量和可靠性。
持续改进:持续改进是软件工程实践的核心原则之一,也是不变的维度之一。无论采用何种技术和流程,都需要不断地进行反思、测量和改进,以适应不断变化的需求和环境。

对于每种技术潮流,不多赘述,简评如下:
海量服务之道,基于腾讯的工程实践总结出来的一套方法论,重在理念阐述,缺乏逻辑严谨性。
SRE(网站可靠性工程),由谷歌提出,强调通过错误预算、服务级别目标(SLO)、服务级别协议(SLA)等手段来量化和管理系统的可靠性。此外,自动化运维、故障排查、性能优化等技术也是SRE阶段的关键。
DevOps强调开发人员与运维人员之间的紧密合作,通过自动化部署、持续监控、快速反馈等技术手段,加速软件的交付周期并提高质量。此外,DevOps还倡导文化变革,推动组织形成更加敏捷和协作的工作环境。
CI/CD则是一种敏捷方法,强调通过自动化的构建、测试和部署流程,确保代码的快速迭代和高质量交付。技术要点包括版本控制、自动化测试框架、持续集成工具、部署策略等,以实现代码从提交到生产的无缝集成和快速部署。
平台工程则是gartner总结的十大技术趋势之一,这是一种新的工程方法,旨在创建可扩展、可重用和模块化的技术平台,以支持多个应用程序或产品。平台工程有助于提高效率、降低成本,并促进创新。
时间来到2023年,Gartner提出了平台工程。可以看出,平台工程的基本概念,基本上也是一种哲学式的总结,历史似乎又回到了起点,从哲学卷到科学,科学卷不动的时候又回到哲学。平台工程就是另一种形式的海量服务之道。

1.3.分布式计算理论
海量服务之道,抑或是SRE/Devops/CICD/平台工程,本质上都是一种工程实践的总结,背后的基础都是分布式计算理论。
分布式计算理论是一种研究和实现并行处理大型计算任务的理论,它通过任务划分、任务调度、通信协议、数据一致性和容错处理等技术手段,提高了计算效率和系统的可扩展性。
分布式计算理论是计算机科学的分支之一,其体系庞大。在实际工作在,有一些技术点被反复用到,笔者择其要点,总结出"系统大设计"框架:
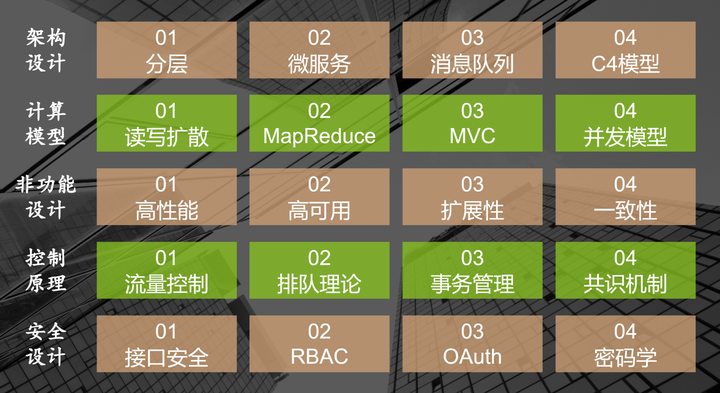
为了方便沟通和呈现,这个"系统大设计"框架被设计成5维度x4要点的矩阵,以下是每个技术要点的简单介绍。
1. 架构设计
- 分层:将系统按功能或责任划分为多个层次,每层只与相邻层通信。这有助于模块化、解耦和复用。
- 微服务:将应用拆分成一系列小型服务,每个服务独立部署、升级。提高了系统的可伸缩性和可维护性。
- 消息队列:异步通信方式,允许独立的服务或组件通过队列发送和接收消息,实现解耦和流量削峰。
- C4模型:一种系统架构描述方法,强调从上下文到容器、组件和代码的层次化描述。
2. 计算模型
- 读写扩散:数据副本分布在多个节点,读写操作可在任意副本上进行,通过同步机制保持数据一致。
- MapReduce:一种编程模型,用于大规模数据集的并行处理。通过Map和Reduce两个函数简化分布式计算。
- MVC:模型-视图-控制器模式,将应用的逻辑、数据和展示分离,提高代码的可维护性和复用性。
- 并发模型:描述如何在多核或多处理器环境中管理并行执行的线程或进程,确保数据一致性和性能。
3. 非功能设计
- 高性能:关注系统的响应时间、吞吐量和资源利用率,通过优化算法、数据结构和硬件资源来提高性能。
- 高可用:设计冗余组件和故障转移机制,确保系统在部分组件故障时仍能提供服务。
- 扩展性:系统能够容易地增加资源以应对增长的需求,包括垂直扩展(增强单个节点能力)和水平扩展(增加节点数量)。
- 一致性:在分布式环境中保持数据的一致性,确保所有节点在给定时间看到相同的数据视图。
4. 控制原理
- 流量控制:管理进入和离开网络的流量,防止拥塞和过载,确保服务质量。
- 排队理论:研究系统中等待线或队列的行为,用于预测和优化系统性能。
- 事务管理:确保一系列操作要么全部成功,要么全部失败,保持数据的一致性和完整性。
- 共识机制:在分布式系统中达成一致决策的过程,如Paxos、Raft等算法。
5. 安全设计
- 接口安全:保护系统接口免受未经授权的访问和攻击,如使用HTTPS、API密钥等。
- RBAC(基于角色的访问控制):根据用户的角色分配访问权限,简化权限管理。
- OAuth:开放授权标准,允许用户授权第三方应用访问其账户信息,无需共享密码。
- 密码学:使用加密算法保护数据的机密性、完整性和真实性,如AES、RSA等。
1.4.系统设计与复杂度
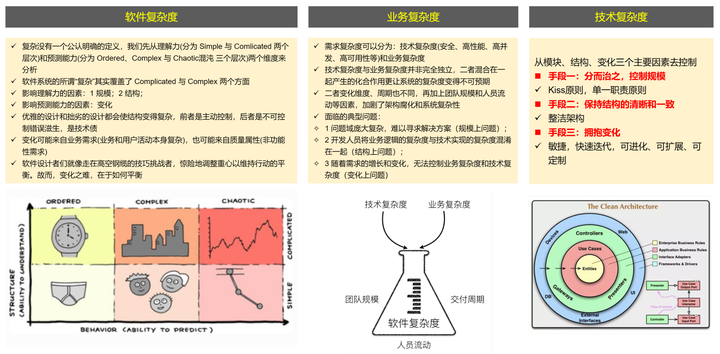
软件是复杂度,系统是复杂的,"系统大设计"首先瞄准复杂度。
最近看了一本书《软件设计:从专业到卓越》,作者张刚将复杂度视为一个根本挑战,由于:
- 软件充满了信息。每一行代码都是信息,任何一行代码不正确功能就不正确。
- 不可见。在外部无法直观感知设计质量。
- 容易变更。软件是"软"的,它本身就是为了"变更"而存在的。
- 没有必然规律。不同于客观物理规律,软件的需求是服务于现实业务的,而现实业务没有那么强的规律性。
早在1986年发表一篇关于软件工程的经典论文,《没有银弹:软件工程的本质性与附属性工作》(No Silver Bullet—Essence and Accidents of Software Engineering),论文作者brooks把失控的、复杂的软件项目比作中世纪的狼人,只有银弹才能杀死它。但是由于软件开发的本质复杂性,使得真正的银弹并不存在。
在软件开发领域,大体上可以将复杂度分为三类:软件本身固有的复杂度,业务逻辑带来的复杂度,以及技术复杂度。
- 软件本身固有的复杂度:软件是现实世界的模型,需处理多变情况、异常和边界条件,导致内在复杂性。各部分间存在复杂的相互作用和依赖关系,难以理解和预测,且随系统演化易变混乱。这种固有复杂度是软件开发的根本挑战。
- 业务逻辑带来的复杂度:软件需实现特定业务规则和流程,不同领域逻辑各异,可能极为复杂。如金融领域的交易规则、风险管理,医疗领域的病人信息和诊断流程。这些业务逻辑直接增加了软件开发的难度和成本。
- 技术复杂度:实现软件功能需应对技术挑战,如选择开发语言、框架、工具,设计算法和数据结构,处理并发性、安全性和性能优化等。新技术如云计算、大数据、人工智能带来新挑战和机遇,同时也增加了技术复杂度。
2.架构设计

应对复杂度,架构设计是抓手之一。
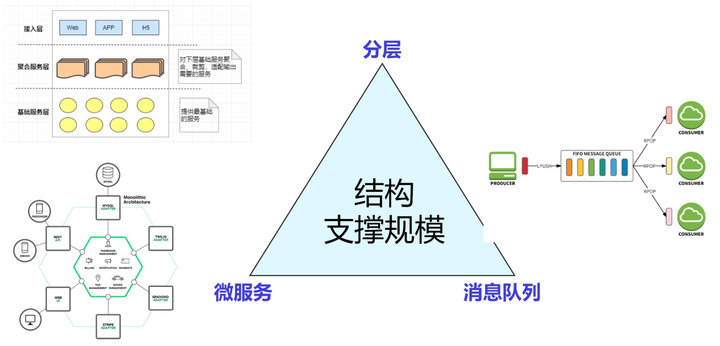
一个系统可以很复杂,但基线架构应该很简单,四梁八柱撑起整个大厦。常用的基线架构有分层、微服务、消息队列和C4模型。
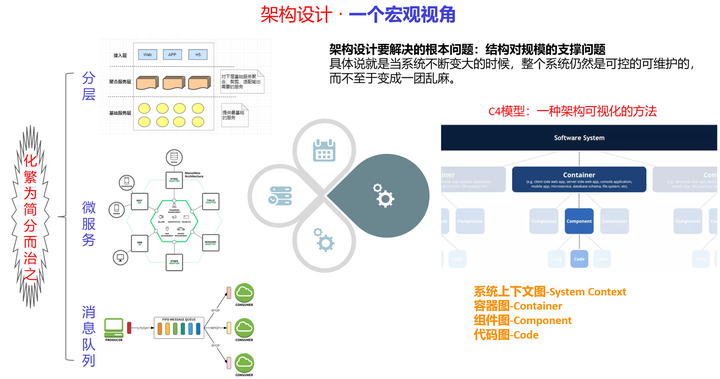
架构设计要解决的根本问题是什么?
- 业务功能的不断增长,系统的扩展能力不受影响
- 系统的维护成本不会随业务功能的扩展而线性增长
- 系统规模的增长不会导致模块耦合度的提高
2.1.分层
分层是一种化繁为简的方法。
通过把一个复杂系统分解为多个层次,每层解决一个问题,各层之间保持简单统一的接口,这样整个系统就呈现出一种简单可控的结构特征。我们也可以将分层用于呈现一个复杂系统,让整个系统更容易被人理解。
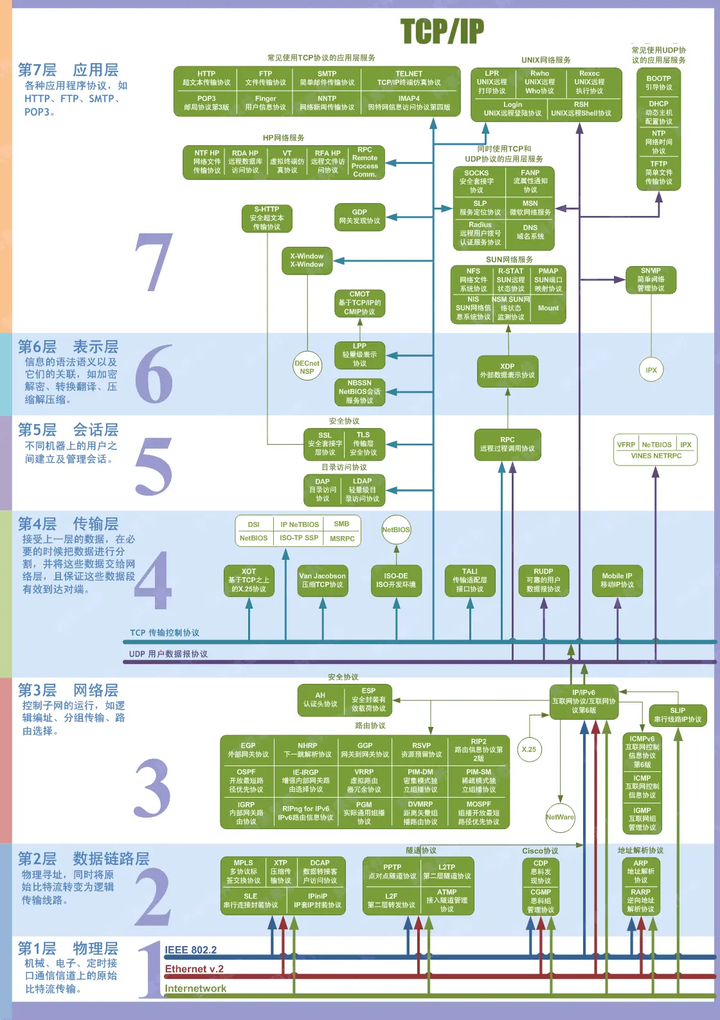
最经典的分层架构当属TCP/IP的七层架构,下面这个图多看看,面试的时候经常会拿来提问。
下面是一个典型的架构图参考框架,注意其上中下分层与左右结构,都是典型的架构图画法,加上适当的颜色区分,看起来很美观。
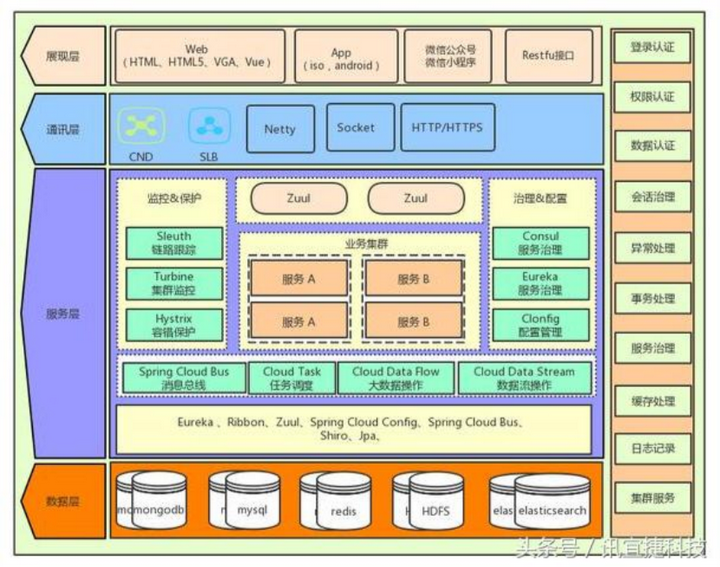
2.2.微服务
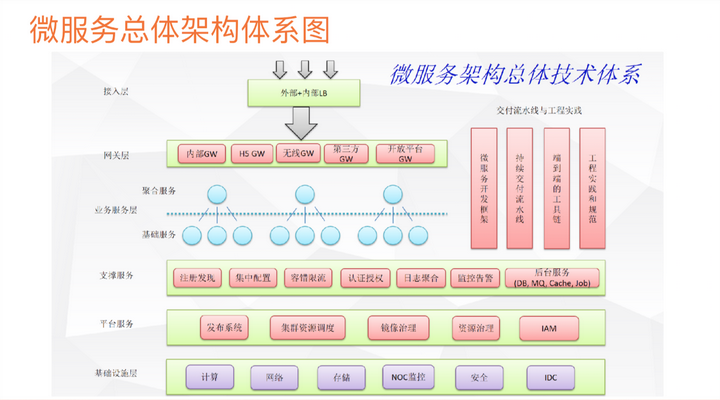
微服务架构则进一步将系统拆分为一系列小型的服务,每个服务独立部署、升级和扩展,提高了系统的灵活性和可伸缩性。
下面是一个微服务的抽象框架:
将上面的抽象框架,用一个具体的例子实例化以后有:
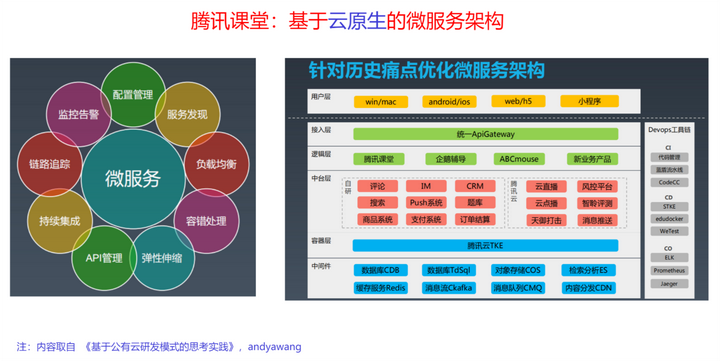
参考:微服务写的最全的一篇文章
2.3.消息队列
消息队列则用于解耦系统组件之间的通信,使得系统能够异步地处理消息和请求,提高了系统的响应性和可靠性。

腾讯早期自研了中转系统,业界现在一般都用开源的消息队列,Kafka是其中最常用的,其他包括RabbitMQ、ActiveMQ、RocketMQ和Pulsar等。这些消息队列各有特点,例如RabbitMQ在吞吐量方面稍逊于Kafka和RocketMQ,但由于其基于Erlang开发,并发能力很强,性能极好,延时很低,达到微秒级,因此也是常用的选择之一。而Kafka则由于其高吞吐量、可扩展性、容错能力等特点,在大数据领域的实时计算、日志采集等场景中得到广泛应用。
2.4.C4模型
C4模型则是一种可视化的架构设计方法,它通过将系统划分为不同的层次和组件,并以图表的方式展示出来,帮助开发者更好地理解和描述系统的结构和行为。
C4模型:
- 上下文图-System Context
- 容器图-Container
- 组件图-Component
- 代码图-Code
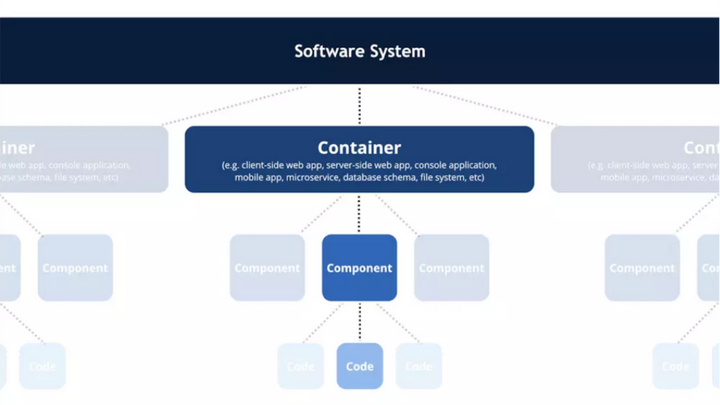
C4模型有个专门的网站介绍:
The C4 model is… 一组分层抽象、一组分层抽象、与表示法无关、与工具无关
- A set of hierarchical abstractions (software systems, containers, components, and code).
- A set of hierarchical diagrams (system context, containers, components, and code).
- Notation independent.
- Tooling independent.

注意,诚如C4官方所言,C4模型是一种架构可视化方法,而不是一种架构设计方法。
笔者试图将C4模型发展为一种大项目开发方法:

参考:可视化架构设计------C4介绍
3.计算模型

3.1.读扩散与写扩散
读扩散与写扩散,信息流系统常用的两种架构。
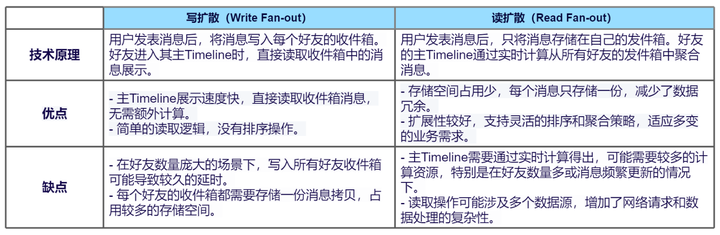
- 读扩散(Read Fan-out)
读扩散的架构重点在于简化数据的写入过程,而将复杂性放在读取端。在这种架构中,当有新的数据产生时,它会被写入到一个中心化的存储位置或每个会话的Timeline中。接收端(如用户或客户端应用)负责从这个存储位置拉取新的数据。这种方法的优点在于写入操作相对简单且高效,因为数据只需要被写入一次。
然而,读扩散的缺点在于读取操作可能变得复杂和低效。因为接收端需要对每个数据源或会话进行单独的拉取操作,这可能导致大量的读取请求和数据处理。此外,如果某些会话没有新数据,这些拉取操作可能会产生无效的网络流量和计算开销。
- 写扩散(Write Fan-out)
与读扩散相反,写扩散的架构将复杂性放在写入端,而简化读取过程。在这种架构中,当有新数据产生时,它不仅被写入到中心化的存储位置,还会被主动推送到所有相关的接收端或它们的同步Timeline中。这样,接收端在需要读取数据时,只需要从自己的同步Timeline中读取即可,无需进行额外的拉取操作。
写扩散的优点在于读取操作非常高效,因为数据已经预先被推送到接收端。此外,由于读取操作是本地的,它还可以减少网络流量和延迟。然而,写扩散的缺点在于写入操作可能变得复杂和低效。因为每次有新数据时,系统都需要确定哪些接收端需要这份数据,并进行相应的推送操作。这可能会增加写入延迟和计算开销,特别是在有大量接收端或数据需要跨多个网络或数据中心进行同步的情况下。
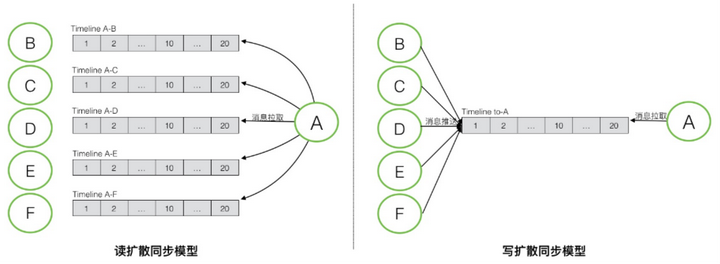
对比两种架构的技术要点:

将上面的抽象框架实例化一下,可以得出微博基于写扩散与读扩散的架构:
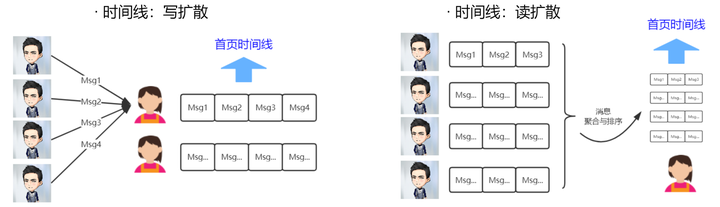
对两种架构做一简单对比:
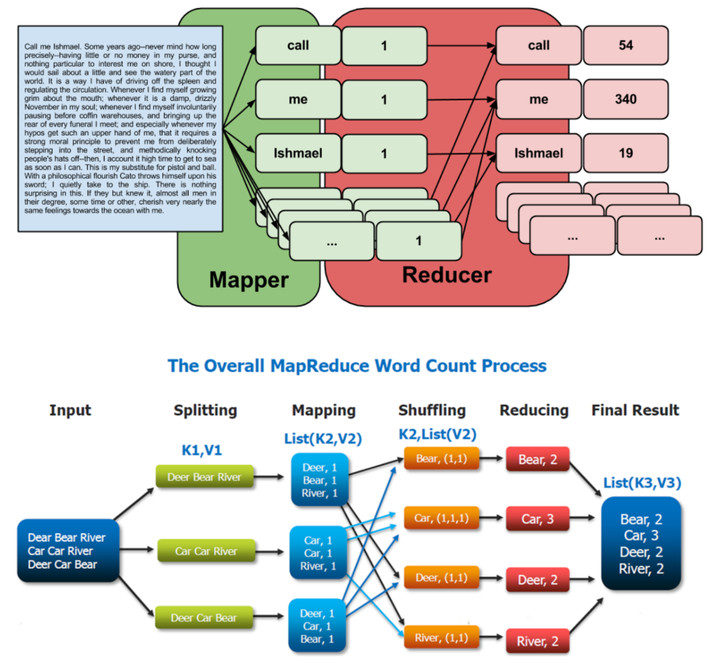
3.2.MapReduce
MapReduce作为一种分布式计算模型,在大数据处理领域具有广泛的应用。它的核心思想是将复杂的、大规模的数据处理任务分解为若干个简单的子任务,然后并行处理这些子任务,从而提高数据处理的速度和效率。
MapReduce的基本原理可以分为两个主要阶段:Map阶段和Reduce阶段。
- Map阶段:在这一阶段,框架将输入数据分割成若干个数据块,然后分配给多个Map任务并行处理。每个Map任务读取一个数据块,并根据预定义的逻辑(如正则表达式、字符串匹配等)将其转换为一系列的键值对(key-value pair)。这些键值对将作为中间结果输出,并根据键的值进行分区和排序,以便后续的Reduce任务处理。
- Reduce阶段:在Map任务完成后,框架将所有具有相同键的中间结果合并成一个列表,并分配给相应的Reduce任务。Reduce任务对这些列表进行进一步的处理和合并,生成最终的结果。这一阶段通常涉及对中间结果的聚合、过滤或转换等操作。
通过并发执行Map和Reduce任务,MapReduce能够充分利用分布式系统的计算资源,加快数据处理的速度。同时,由于其简单的编程接口和自动的任务调度机制,MapReduce也降低了开发大规模数据处理应用的复杂性。
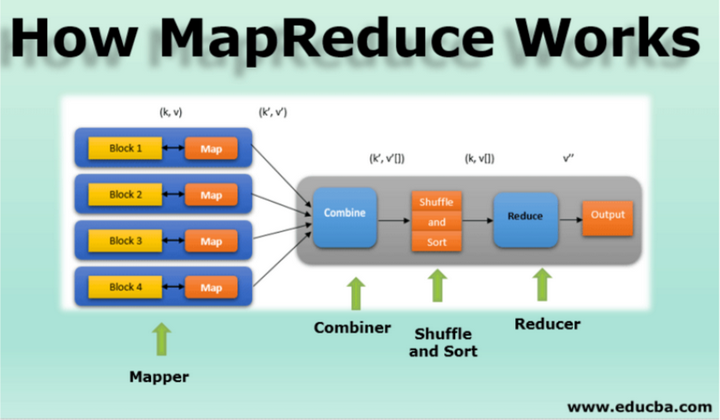
下面是一个利用MapReduce统计单词频率的例子,可以通过这个例子来简单地理解MapReduce的基本原理,实际场景要复杂的多,通常会涉及大规模的分布式集群。
下面是一个较复杂的例子,用RxGo构造MapReduce。RxGo是一个Golang编程库。

github地址:RxGo
3.3.并发模型
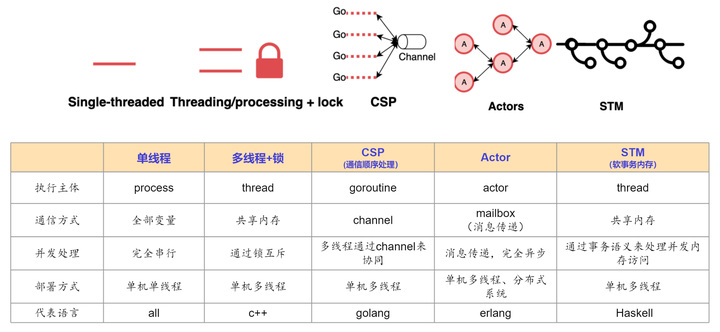
在并发编程中,常用的并发模型有以下几种:
- 单线程模型,以其简单直接的方式,适用于那些无需并行处理的轻量级任务,但在多核处理器时代,其性能局限性也显而易见。
- 多线程+锁模型引入了并行处理的能力,通过锁机制来确保资源访问的安全性,然而这也带来了编程复杂性和潜在的死锁风险。
- CSP模型则通过消息传递实现并发进程间的协同工作,特别适合分布式系统,但可能需要更多的编程抽象。
- Actors模型进一步强化了封装性,每个Actor都是独立的计算实体,通过异步消息通信,非常适合构建高并发和分布式的应用,尽管消息传递的开销不可忽视。
- STM模型将并发操作视为事务,简化了锁的管理,但在高性能或实时性要求下,事务的冲突和回滚可能成为性能瓶颈。
当前Golang语言是一门发展非常迅速的语言,其语言级的并发能力非常强大,而其背后的并发模型就是CSP。
Tony Hoare,因为"对程序设计语言的定义和设计方面的基础性贡献"在1980年获得图灵奖。26岁时发明快速排序算法(Quick Sort)。1978年发表经典论文《Communicating Sequential Processes 》。
《Communicating Sequential Processes》(顺序通信进程,简称CSP)为并发计算提供了一种新的理论框架和编程模型。该论文的主要内容可以概括为以下几个方面:
- 并发系统的描述:CSP 提出了一种基于消息传递的并发模型,用于描述和分析由一系列独立但又可通信的顺序进程(sequential processes)组成的系统。这些进程通过通道(channels)进行通信,通道是进程之间传递消息的媒介。
- 语法和语义:CSP 定义了进程的语法和语义。语法层面,进程由一系列顺序执行的语句组成,这些语句包括输入、输出、选择和循环等。语义层面,CSP 采用了一种基于迹(traces)的模型来描述进程的行为,迹记录了进程在执行过程中可能的事件序列。
- 通信原语:CSP 强调了输入和输出作为并发编程中被忽视的原语的重要性。它提供了两种基本的通信原语:发送(output)和接收(input)。通过这些原语,进程可以同步或异步地交换信息。
- 并发组合:CSP 允许通过特定的并发组合操作符(如并行组合、选择、隐藏和重命名等)将简单的进程组合成复杂的并发系统。这些操作符提供了丰富的表达能力,使得CSP 能够描述各种复杂的并发模式。
- 死锁和活锁:CSP 论文中讨论了并发系统中常见的死锁和活锁问题,并提供了相应的解决方案。通过合适的进程设计和组合,可以避免或检测这些并发问题。
CSP 论文的发表对并发计算领域产生了深远的影响。它不仅为并发系统的设计和分析提供了一种新的理论框架,还启发了许多后来的并发编程语言和模型的发展,例如Go语言中的goroutine和channel就是受到CSP启发的并发模型。

下面是两个基于CSP的工程案例:
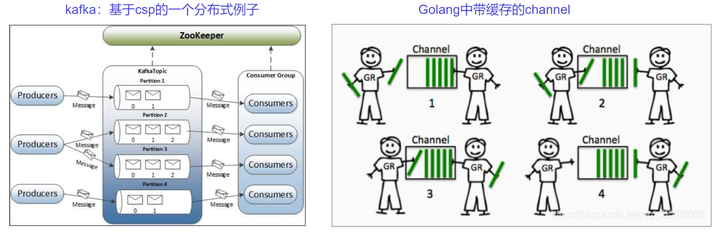
Erlang中的Actor模型和Haskell中的STM模型,笔者不熟悉。
3.4.MVC
MVC(Model-View-Controller)本身是一种设计模式,但也可以看做一种方法论,作为方法论的MVC,提供了一种对显示逻辑、控制逻辑、数据逻辑进行分离与整合的方法,可以看做是一种对计算进行组织的方法。
- 模型(Model):代表应用程序的数据和业务逻辑。它负责处理数据的存取和管理,以及与数据库或其他数据源进行交互。模型通常是与应用的状态和行为相关的代码,它不应该包含任何与用户界面相关的逻辑。
- 视图(View):负责展示模型中的数据给用户。视图是用户界面的组成部分,它可以是图形用户界面(GUI)、命令行界面(CLI)或任何其他类型的用户界面。视图不应该包含任何业务逻辑,它只关心如何显示数据给用户。
- 控制器(Controller):作为模型和视图之间的中介,控制器负责接收用户的输入,并根据这些输入调用相应的模型和视图来完成任务。控制器处理用户的请求,并根据需要更新模型和视图的状态。
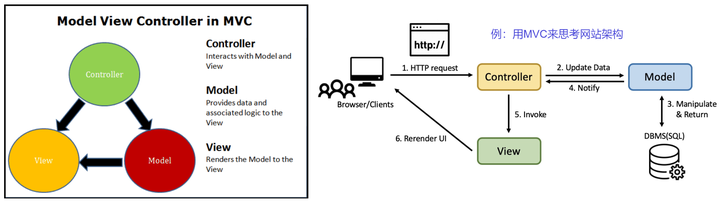
通过将显示逻辑放在视图中,控制逻辑放在控制器中,以及数据逻辑放在模型中,MVC 确保了各个组件之间的松耦合。这种分离使得开发者可以独立地修改、更新和测试每个组件,而不影响其他组件。此外,MVC 还支持代码的复用,因为模型和视图可以被多个控制器共享。
4.DFX设计

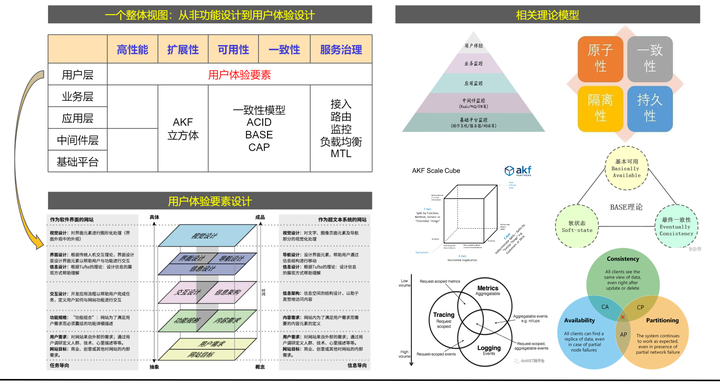
DFX(Design For X)是一种设计和开发方法,旨在确保产品在特定领域或条件下具有所需的非功能性特性。这里的"X"可以代表各种不同的因素,如制造(Manufacturability)、测试(Testability)、可靠性(Reliability)、可用性(Usability)等。在软件开发和系统设计领域,DFX通常是指非功能设计,这通常涉及高性能、高可用、扩展性、一致性以及服务治理等方面。
- 高性能:高性能设计旨在确保系统或应用程序能够快速、有效地处理任务。这包括优化算法、减少资源消耗、提高吞吐量以及降低延迟等方面的考虑。
- 高可用:高可用性意味着系统或服务能够在正常操作和故障情况下持续提供服务。这通常涉及冗余设计、故障转移、容错机制以及监控和恢复策略。
- 扩展性:扩展性设计允许系统或软件在需求增长时能够容易地增加资源或处理能力。这包括水平扩展(增加更多实例)和垂直扩展(增强单个实例的能力)。
- 一致性:在分布式系统中,一致性指的是所有节点在给定时间点上对某个数据项的状态达成共识。这通常涉及使用各种一致性协议来确保数据的完整性和准确性。
- 服务治理:服务治理是一套用于管理和控制服务的策略和实践。这包括服务发现、负载均衡、流量管理、安全性、版本控制以及服务的监控和诊断。
在DFX的框架下,架构师和开发者需要在早期阶段就考虑这些非功能需求,并确保它们在整个产品生命周期中得到满足。通过在设计阶段就考虑这些因素,可以显著降低后期修改和优化的成本,同时提高最终产品的质量和用户体验。
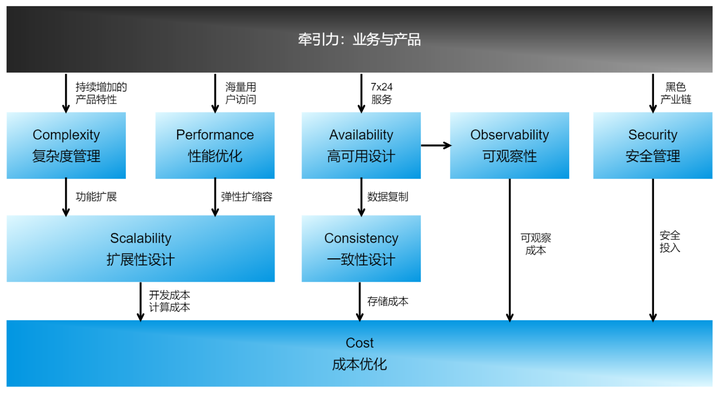
对于互联网业务而言,丰富的产品特性和海量用户是基本的驱动力。由此而催生出DFX的各个维度,例如复杂度管理、高性能、高可用,可观察、安全性,扩展性、一致性等,所有这些维度的提升,都要求提高成本。产品功能特性的不断增加导致了需要做复杂度管理,而海量海量用户则需要系统具备高性能的处理能力。功能扩展和性能弹性扩容导致了需要做扩展性设计。服务7x24小时不间断运行,要求系统具备高可靠性,高可靠性通常要求数据复制,数据复制又会导致一致性。高性能高可靠通常要求都要求可观察。黑色产业链是业务必须要面对的安全压力。
以下是笔者梳理的,用于互联网业务的DFX设计,共8个维度:
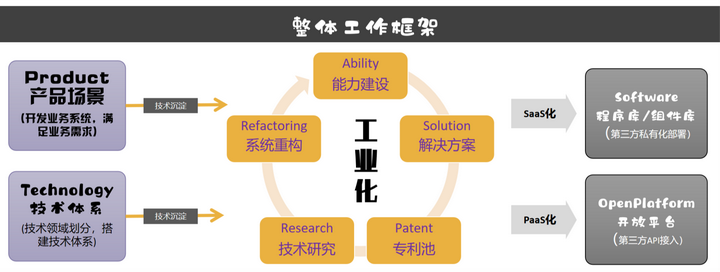
腾讯在2018年发起了一个930战略(2018.9.30为发起时间),要求全公司所有业务3年内全部上云。930战略分解到腾讯视频后,变成一个自上而下的被称之为"腾讯视频工业化"的战略,笔者当时在腾讯视频负责一个叫"一起看"的业务,上层战略投射到一起看业务后,即"一起看工业化建设"项目。下面是笔者整理的一页材料。

当时为了方便工作,统一团队思想,笔者制作了一个工作框架,阐明工业化战略How的问题。
接下来挑几个维度做简单介绍。
4.1.高性能
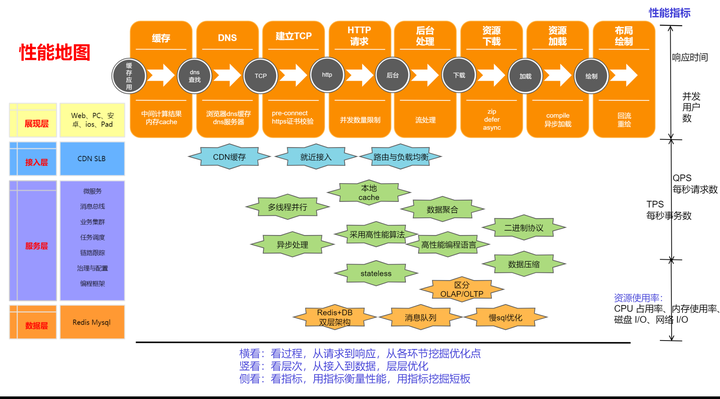
通常,我们可以可以从以下三个维度来理解高性能的设计。
横看:看过程,从请求到响应,从各环节挖掘优化点
- 请求处理流程:分析从用户发起请求到系统响应请求的整个流程。这包括网络传输、请求解析、业务逻辑处理、数据访问和响应生成等环节。
- 瓶颈识别:在每个环节中识别可能的性能瓶颈。例如,网络延迟、请求解析开销、数据库查询效率等。
- 优化策略:针对识别出的瓶颈,制定相应的优化策略。这可能包括缓存优化、并发控制、负载均衡、数据库索引优化等。
竖看:看层次,从接入到数据,层层优化
- 应用架构层次:审视应用的整体架构,从前端接入层到后端服务层,再到数据存储层。
- 分层优化:在每个层次上考虑性能优化。例如,在接入层可以通过CDN加速和SSL卸载来提升性能;在服务层可以通过服务拆分和微服务化来提升可扩展性和并发处理能力;在数据层可以通过读写分离、分库分表和数据缓存来提升数据访问性能。
- 跨层优化:考虑跨层次的性能优化策略。例如,前后端之间的接口优化、服务层和数据层之间的数据交互优化等。
侧看:看指标,用指标衡量性能,用指标挖掘短板
- 性能指标:定义和收集关键性能指标,如响应时间、吞吐量、并发用户数、失败率等。
- 性能监控与分析:建立性能监控系统,实时监控和分析性能指标的变化趋势。这有助于及时发现性能问题和定位瓶颈。
- 识别瓶颈点并改进:通过性能指标的分析,识别出系统的性能瓶颈,并制定相应的改进策略。这可能包括硬件升级、系统配置优化、代码重构等。
通常我们面对的任务是,如何提高系统性能,常用的优化措施分为三类,第一类是接入层的优化,第二类是逻辑层的优化,第三类是数据层的优化。
第1类:接入层的优化
- CDN缓存:通过部署CDN节点,缓存静态内容,加速用户访问。
- 就近接入:根据用户地理位置,将请求路由到最近的服务器或数据中心。
- 路由与负载均衡:智能路由和负载均衡技术,分散请求到多个服务器,防止单点过载。
接入层优化主要关注如何将用户的请求高效地引导到后端服务,减少网络延迟和提高吞吐量。
第2类:逻辑层的优化
- 多线程并行:利用多线程技术,并行处理任务,提高响应速度。
- 异步处理:将耗时操作设计为异步任务,避免阻塞主线程。
- 本地cache:在应用或服务器层面,缓存常用数据,减少对外部资源的访问。
- 数据聚合:聚合多个小请求为大请求,减少网络交互次数。
- 采用高性能算法:选择性能更优的算法处理数据和业务逻辑。
- 高性能编程语言:使用编译速度快、执行效率高的编程语言。
- stateless(无状态):设计无状态服务,简化状态管理和水平扩展。
- 二进制协议:使用二进制协议替代文本协议,提高数据传输效率。
- 消息队列:解耦服务间通信,实现异步处理和流量削峰。
逻辑层优化主要关注如何高效地处理用户的请求和业务逻辑,减少不必要的开销和提高系统的吞吐量。
第3类:数据层的优化
- 数据压缩:压缩存储和传输的数据,减少IO和带宽消耗。
- 区分OLAP/OLTP:根据业务需求优化数据库设计,区分分析型和事务型处理。
- Redis+DB双层架构:结合内存数据库和关系型数据库,优化数据访问性能。
- 慢SQL优化:针对数据库查询进行优化,提高查询效率。
数据层优化主要关注如何高效地存储、检索和管理数据,减少数据库的访问延迟和提高数据处理的性能。
4.2.高可用
质量理论与高可用
朱兰(Joseph M. Juran)是世界著名的质量管理专家,他所倡导的质量管理理念和方法对全球企业界以及质量管理领域产生了深远的影响。他提出的"质量策划、质量控制和质量改进"被誉为"朱兰三部曲",是质量管理中的核心框架。在他的理论中,质量策划是质量管理的第一步,它涉及到识别顾客需求、制定质量目标、设计满足这些目标的过程和策略。质量控制则是对过程和产品的监视和测量,以确保它们符合既定的质量要求。而质量改进则是一个持续的过程,它旨在通过识别和解决质量问题,提高过程和产品的质量和效率。
将朱兰质量管理的核心思想应用到高可用(HA)领域时,可以从两个方面入手。首先是在设计阶段,通过仔细的架构设计来提高系统的高可用性;然后是在运营阶段,通过持续度量持续改进,进一步提升高可用性。
设计阶段:高可用是设计出来的
- 确定高可用性目标:首先要明确业务对高可用性的具体需求,例如系统的故障恢复时间(RTO)和数据丢失容忍度(RPO)。
- 设计冗余和容错机制:在架构设计中考虑冗余部署,如负载均衡、主备切换、多活数据中心等,以确保单点故障不会导致整体服务中断。
- 风险评估:识别可能影响系统高可用性的各种风险,如硬件故障、网络中断、软件缺陷等。
- 代码和架构审查:通过代码审查和架构审查,确保实施过程中没有偏离高可用性设计的原则。
- 测试验证:通过模拟故障场景,对系统的高可用性进行严格的测试验证,确保系统能够在各种故障情况下保持服务。
运营阶段:持续度量持续改进
- 监控和度量:建立完善的监控系统,实时收集系统的运行状态和服务质量数据,如响应时间、错误率、可用性等。
- 故障分析和总结:对发生的故障进行深入分析,找出根本原因,避免同类故障再次发生。
- 持续改进:根据监控数据和故障分析结果,不断优化系统的高可用性设计,提高系统的稳定性和可靠性。
- 反馈循环:将运营阶段的经验和教训反馈到设计阶段,不断完善和更新高可用性的设计原则和方法。
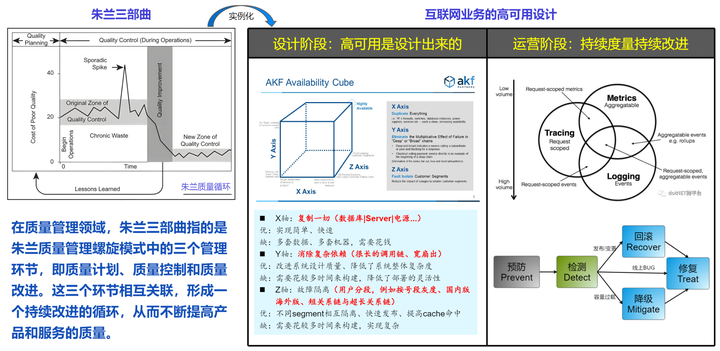
朱兰三部曲通常指的是质量计划(Planning)、质量控制(Control)和质量改进(Improvement),它们是质量管理中相互关联且持续进行的三个核心活动。在将这些概念应用到高可用性(HA)领域时,我们可以这样理解。
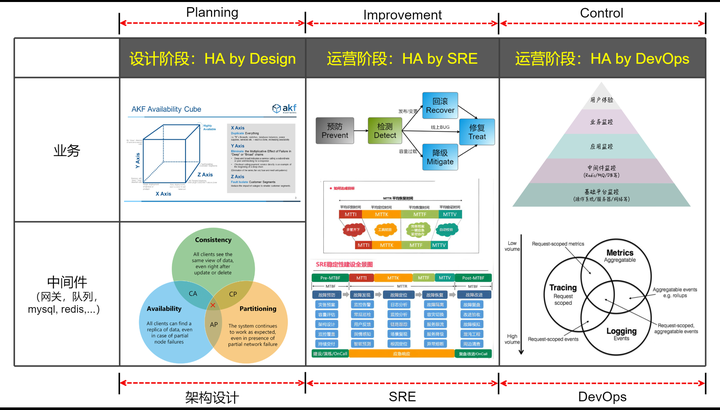
Planning:HA by Design(高可用性通过设计实现)
规划阶段是高可用性实现的起点,它涉及到对系统架构、冗余策略、容错机制以及恢复计划的设计和规划。在这一阶段,团队需要明确业务对高可用性的需求,并将其转化为具体的设计要求和技术选择。
- 确立高可用目标:确定业务连续性的具体指标,如恢复时间目标(RTO)和恢复点目标(RPO)。
- 风险评估:识别潜在的系统故障点,评估其对业务的影响。
- 设计冗余和容错:在架构层面考虑冗余部署、负载均衡、故障切换等策略。
- 制定恢复计划:设计详细的灾难恢复和业务连续性计划。
Improvement:HA by SRE(高可用性通过SRE实现)
改进阶段在高可用性领域通常指的是通过持续的监控、分析和优化来提升系统的可靠性。站点可靠性工程(SRE)是一种强调通过工程手段提升系统可靠性的方法论,它在这一阶段发挥重要作用。
- 持续监控:通过全面的监控系统来实时跟踪系统的健康状态和性能。
- 故障分析:对发生的故障进行深入分析,找出根本原因,并采取措施防止再次发生。
- 性能优化:基于监控数据和故障分析,对系统进行调优,提升性能和可用性。
- 引入新技术:关注新技术的发展,评估并引入能够提升系统可靠性的新技术或工具。
Control:HA by DevOps(高可用性通过DevOps实现)
控制阶段在高可用性上下文中可以理解为通过DevOps实践来确保系统在整个生命周期内保持高可用性。DevOps强调开发、运维和测试团队之间的紧密协作,以及自动化和持续集成/持续部署(CI/CD)的实践。
- 自动化测试:通过自动化测试来验证系统的可用性和可靠性。
- 持续集成和部署:采用CI/CD流程来减少部署错误,加快故障恢复速度。
- 配置管理:使用配置管理工具来跟踪和管理系统的配置变化,确保变更的可追溯性和一致性。
- 团队协作:打破开发与运维之间的壁垒,促进跨团队协作,共同维护系统的高可用性。
综上所述,Planning、Improvement和Control在高可用性领域分别对应着设计阶段的高可用性规划、通过站点可靠性工程实现的持续改进以及通过DevOps实践进行的控制和管理。这三个阶段相互支持,共同构成了一个完整的高可用性保障体系。
高可用指标
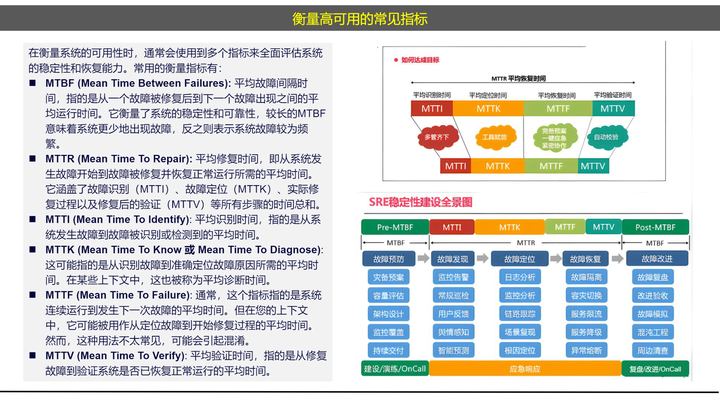
在科学上或工程上,要研究一个东西,首先要让这个东西变成是可衡量的。一个东西只有是可衡量的,那么它才是可改进的。如何度量可用性,我们已经发展出了一套完备的指标体系。
高可用设计 by Design
AKF可用性立方体是一个模型,用于指导关于如何实现高可用性的讨论,同时也是评估现有系统理论上的"按设计"可用性的工具。
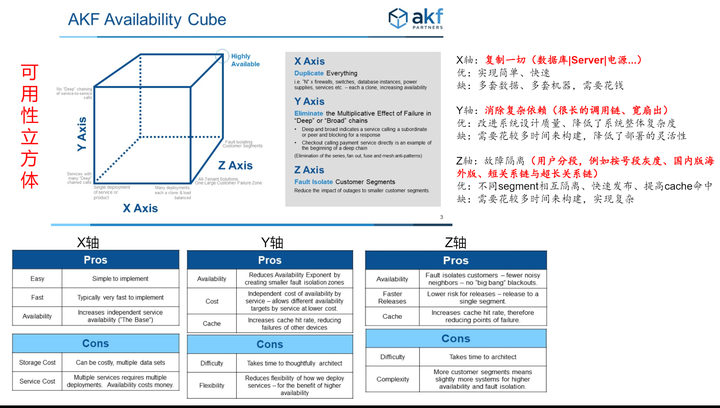
我们可以从架构设计角度对高可用进行度量:

上面这个公式并不是一个严格的数学意义上的公式,只是一个思考框架:
X轴用来衡量单个节点的可用性,提升单个节点的可用性,有利于提升系统的整体可用性。
Y轴和Z轴用来衡量节点之间的依赖关系,依赖关系越简单可用性越高,反之,依赖关系越复杂可用性就约低
高可用运营 by SRE
在前面"海量服务之道"那一节,已经介绍过SRE,这里不再赘述。这里分享一个笔者在实际工作,经常使用的高可用工具箱,包括一个checklist。
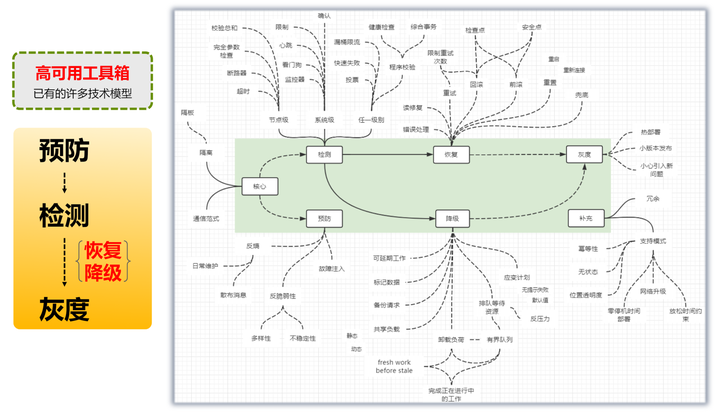

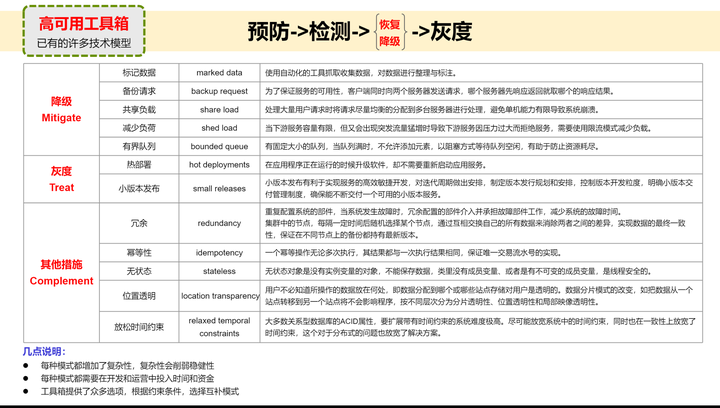
这里的方法非笔者自己总结,主要是参考了国外的一篇博客。原作者的一个观点,笔者非常认同:
方法论虽然多但大同小异,不要重新发明轮子,不要因为技术的更新换代,每几年就淘汰积累起来的共同知识记忆
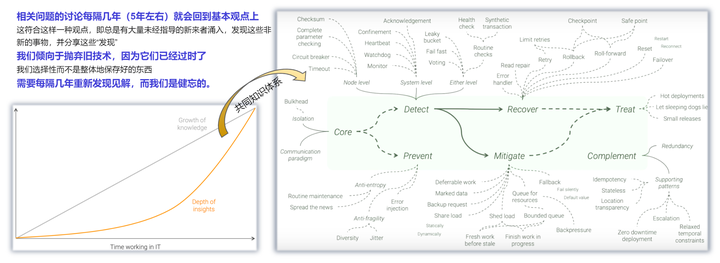
参考:弹性软件设计,http://alex-ii.github.io/notes/2019/04/22/7_quests_resilient_design.html
高可用运营 by DevOps
Devops发展到今天,已经蔚为壮观,从Devops开始,逐渐发展出了DevSecOps、DataOps、MLOps等。实际上,DevOps自诞生以来,已经逐渐发展成为一种强大的文化和方法论,旨在提高软件交付的速度、质量和效率。
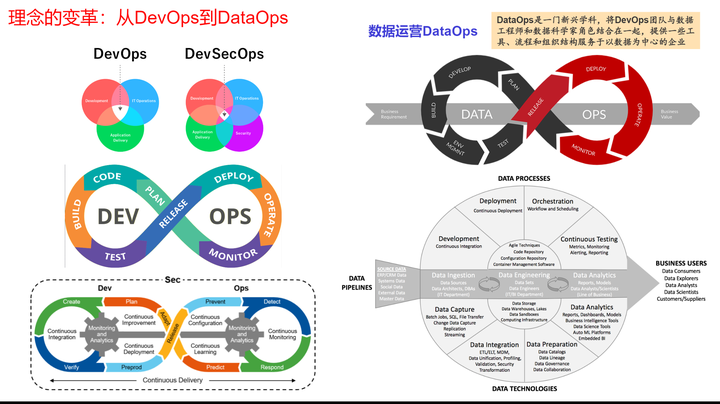
但是再厉害的工具,也需要人来使用,如何做好高可用,人的思想意识仍起着决定性的作用。
例如在腾讯,就一直强调要做好全面监控,做到一切尽在掌握中。

Devops体系虽然庞杂,但万变不离其宗,抓住了可观察三支柱,也就抓住了Devops的本质。
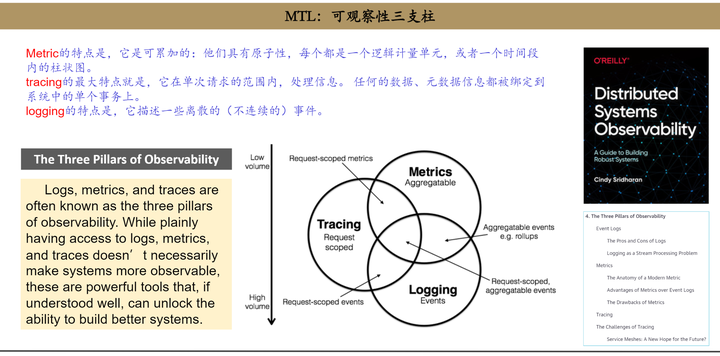
可观察三支柱,一个更直观的图:
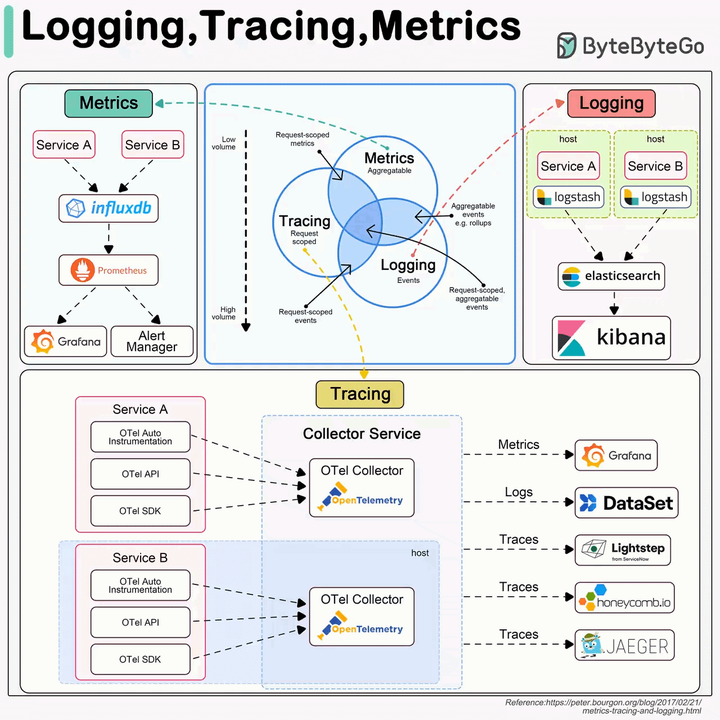
图片来源:ByteByteGo
4.3.扩展性
尽管扩展性不像高性能或高可用那样,容易通过具体的指标来度量,但它确实是系统设计中的一个重要考量因素。良好的扩展性意味着系统能够应对不断增长的用户需求、数据量和业务复杂性,而不需要进行根本性的重构或替换。
具体到扩展性设计方法,我们可以从扩展性方法、扩展性原则和可扩展架构三个方面来展开。
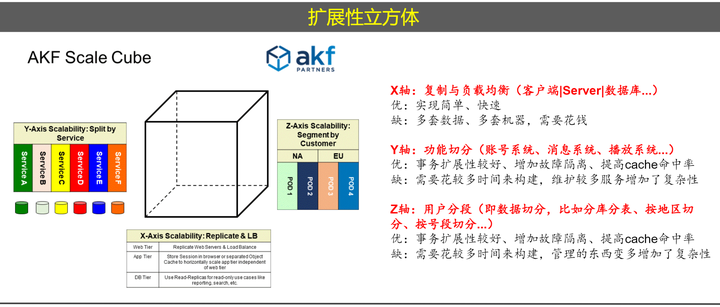
扩展性立方体
一个常见的扩展性设计方法是AKF扩展性立方体,总的来说,AKF扩展性立方体提供了一个全面的框架,帮助架构师和开发人员在设计和扩展系统时做出良好的决策。
AKF扩展性立方体是一个用于描述系统扩展性的模型,它涵盖了三个主要的扩展维度:X轴、Y轴和Z轴,每个轴代表了不同的扩展策略和方向。
- X轴代表复制与负载均衡,即通过增加服务实例和数据副本来分散负载,提高系统的容量和可用性。这种策略实现起来相对简单且快速,但可能会增加管理和运营成本。
- Y轴代表功能切分,将系统拆分成多个独立的服务或功能单元,每个单元可以独立扩展和维护。这种策略有助于提高系统的灵活性和可扩展性,但也可能增加系统的复杂性。
- Z轴代表用户分段或数据切分,即根据用户或数据的特征将其分散到不同的数据库或存储系统中。这种策略有助于提高系统的存储和处理能力,但也可能引入数据一致性和完整性的挑战。
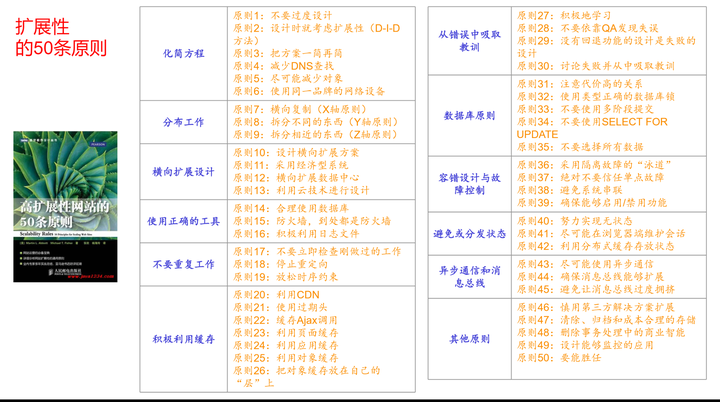
扩展性原则
有一本小册子,《高扩展性网站的50条原则》,专门介绍扩展性设计,可以看作是AKF扩展性立方体的具体展开。
AKF扩展性立方体作为一个理论框架,为我们理解系统扩展性提供了三个关键的维度:X轴(复制与负载均衡)、Y轴(功能切分或服务拆分)和Z轴(用户分段或数据库分片)。这个模型帮助架构师在宏观层面上思考如何设计可扩展的系统。
而《高扩展性网站的50条原则》则深入到具体的实现细节和策略中。它涵盖了诸如服务拆分、数据库分片、负载均衡、缓存策略、异步处理、自动化部署和监控等关键主题,这些都是在将AKF扩展性立方体的理论原则应用于实际项目时必须考虑的因素。
微服务架构
尽管扩展性可能难以直接度量,但通过采用合适的设计方法和架构模式,如微服务架构,我们可以构建出具有良好扩展性的系统。
微服务架构是近年来业界广泛采用的一种设计方法,它在扩展性方面表现优秀。通过将系统拆分成一系列小型的、独立的服务,微服务架构使得每个服务都可以采用最适合的技术栈和扩展策略。这种灵活性使得系统能够更容易地适应变化,无论是添加新功能、支持新的用户群体,还是应对突发的流量增长。
在微服务架构中,每个服务都可以独立部署和扩展,这意味着可以根据实际需求对特定服务进行扩容或缩容。这种精细化的控制有助于避免资源的浪费,并确保系统始终保持在最佳的运行状态。
此外,微服务架构还促进了团队之间的并行开发和协作。不同的团队可以独立地开发和部署自己的服务,而无需等待其他团队的进度。这种并行性不仅加快了开发速度,还有助于保持系统的模块化和可维护性。
关于微服务架构,在笔者的另外两篇文章里有详细阐述,感兴趣可以看看。
4.4.一致性
一致性是DFX里面最复杂的一部分,涉及非常多的理论内容,这里只做提纲挈领的介绍。
下面的一致性模型,有助于从整体上理解一致性。这个一致性模型,主要涉及三个维度:一致性的强弱,两大类一致性,一致性与可用性的关系。
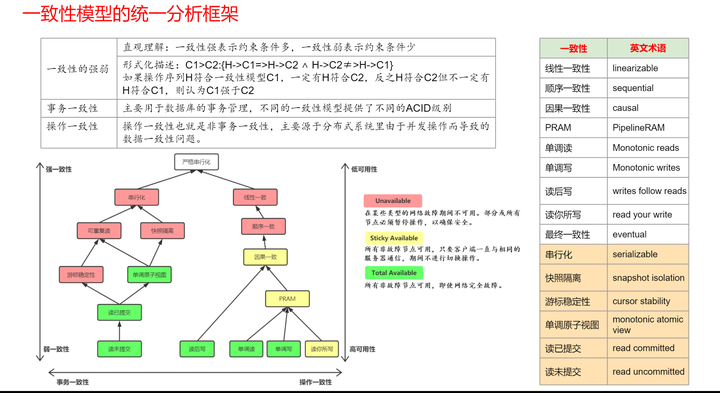
参考:https://jepsen.io/consistency
一致性的强弱
一致性的强弱确实可以通过直观理解为约束条件的多少。在形式化描述中,如果操作序列H符合一致性模型C1,则必然符合C2,但反之则不然,这种情况下我们认为C1强于C2。这种强弱关系在一致性模型的比较和选择中具有重要意义。
一致性的强弱与可用性关系密切:
强一致性要求系统在任何时刻都能提供一致的数据视图,这意味着所有的节点在同一时间点看到的数据都是相同的。这种一致性级别提供了最高的数据准确性保证,但也可能对系统性能产生负面影响,因为需要等待所有节点的更新确认,可能导致延迟增加和可用性降低。
相比之下,弱一致性允许系统在一定时间内提供可能不一致的数据视图,但最终会收敛到一致的状态。这种一致性级别提高了系统的可用性,因为不需要等待所有节点的更新确认,但可能牺牲了一定的数据准确性。
在实际应用中,系统设计者需要根据业务需求和系统特点来选择合适的一致性级别。对于需要高可用性的系统,可能会选择牺牲一定的数据一致性来换取更高的性能;而对于需要强数据准确性的系统,则可能会选择强一致性模型。
一致性的分类
一致性大体可以分为两类,事务一致性与分布式一致性。
- 事务一致性主要用于数据库的事务管理,确保在事务执行过程中数据的完整性和一致性。不同的一致性模型提供了不同的ACID级别,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。这些级别定义了事务在不同阶段对数据一致性的保证程度。
- 操作一致性,也称为非事务一致性或者分布式一致性,主要关注分布式系统中由于并发操作而导致的数据一致性问题。在分布式环境中,多个节点可能同时访问和修改共享数据,这就需要通过操作一致性来保证数据的正确性和一致性。
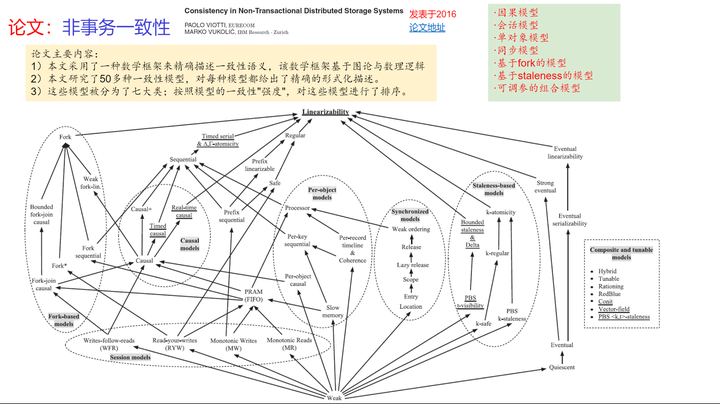
本文主要是关于分布式系统的设计,而分布式一致性,则涉及一个庞大的谱系,见下图:
如何取舍
既然一致性如此复杂,从弱一致性到强一致性,从事务一致性到分布式一致性,从ACID到BASE再到CAP,到底应该如何取舍,这里我们先留一个问题。
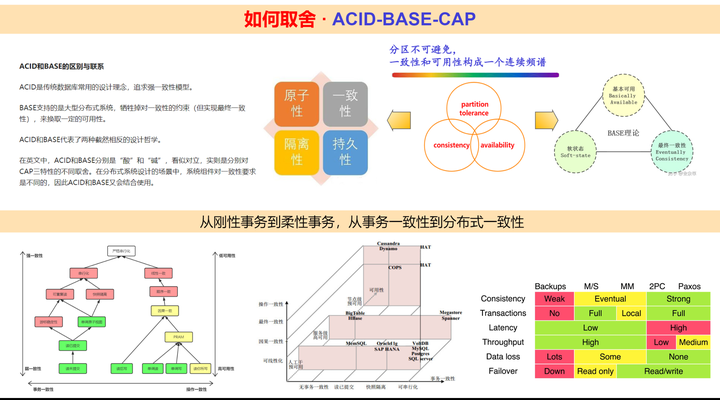
一致性的介绍,到此为止,后续专文展开。
5.控制原理

5.1.流量控制
流量控制是确保网络稳定性和高效性的关键因素之一,从更广泛的角度来看,流量控制不仅限于网络数据传输,还涉及到任何类型的系统或服务中请求的处理速度。
流量控制可以通过多种方式来实现,以下是一些常见的方法:
- 队列管理:将到达的请求放入队列中,并按照一定的优先级或先进先出(FIFO)的规则进行处理。当系统繁忙时,新请求可以在队列中等待,直到系统有足够的资源来处理它们。
- 速率限制:对进入系统的请求速率进行限制,以确保系统不会因为过多的请求而崩溃。这可以通过"令牌桶"算法或"漏桶"算法来实现。
- 负载均衡:在多个服务器或服务实例之间分配请求,以平衡负载并提高系统的整体吞吐量。这可以通过硬件负载均衡器、软件负载均衡器或基于云的服务来实现。
- 自适应调整:系统可以根据当前的负载情况动态地调整其处理请求的速率。这可以通过监控系统的性能指标(如CPU使用率、内存占用率、响应时间等)来实现,并据此调整流量控制策略。
- 预测和调度:更高级的方法可能包括使用机器学习或其他预测技术来预测未来的请求模式,并据此进行调度和流量控制。
常见的流控算法:
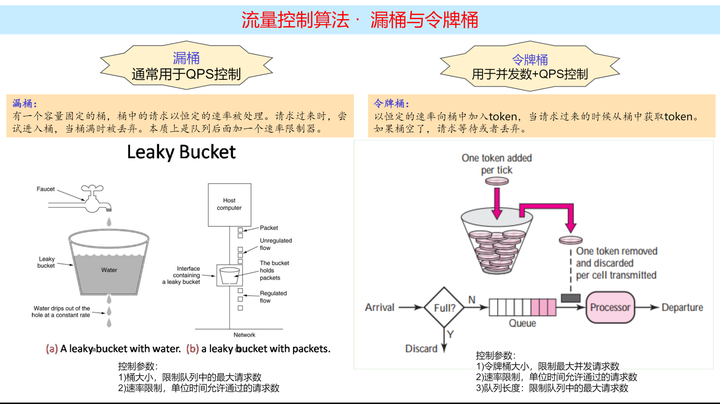
实际工作中,一般不用自己去实现这些算法,各厂商的技术组件都支持了完整的流量控制算法:
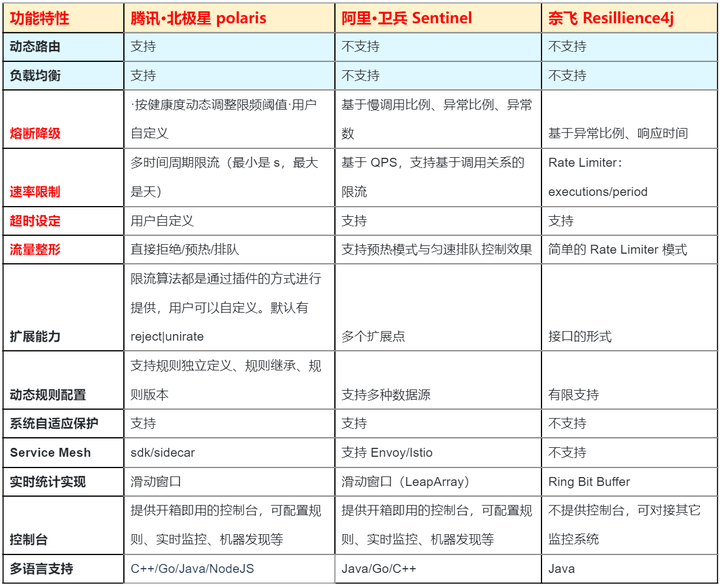
5.2.排队理论
《随机过程与排队论》是笔者硕士期间的一门核心课程,主要包含两部分内容:
- 随机过程:主要研究随机现象随时间演化的过程。这部分内容会涵盖各种随机过程的基本概念、性质以及应用。例如,马尔可夫过程、泊松过程、布朗运动等。通过学习这些随机过程,可以更好地理解随机现象的本质和规律。
- 排队论:又称随机服务系统理论,是研究系统随机聚散现象和随机服务系统工作过程的数学理论和方法。排队论会涉及到各种排队系统的模型、性能指标以及优化方法。例如,M/M/1、M/M/c、M/G/1等经典排队模型。通过学习排队论,可以掌握如何分析和优化实际生活中的排队系统,如银行、超市、医院等。
在工作中用的比较多的是排队论,下面是队列的形式化描述:

如何用排队论解决实际问题,下面是笔者整理的一个框架:
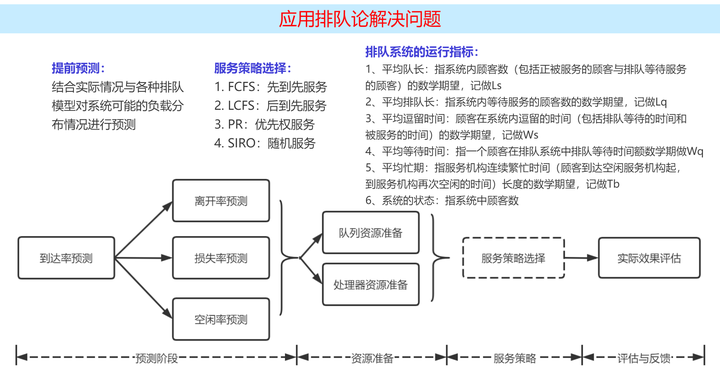
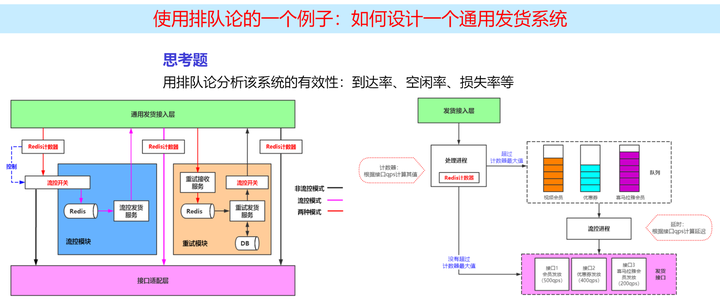
下面是一个实际工作中的案例:
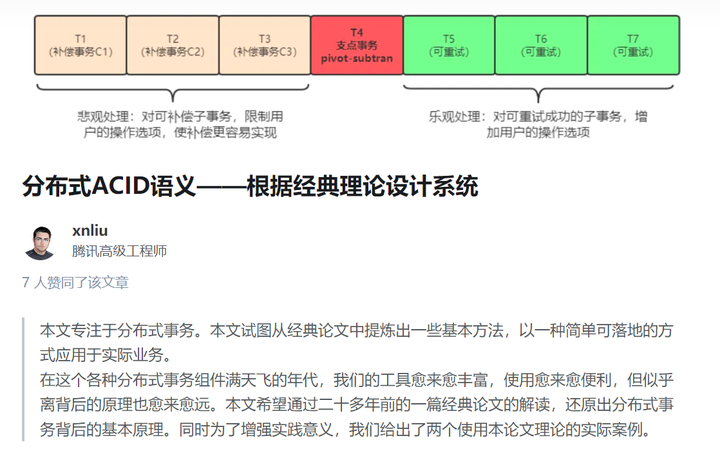
5.3.事务理论
事务理论,计算机科学的一大分支,本身非常复杂,后续专文展开。
下面是笔者之前写的一篇文章,感兴趣可以看看。
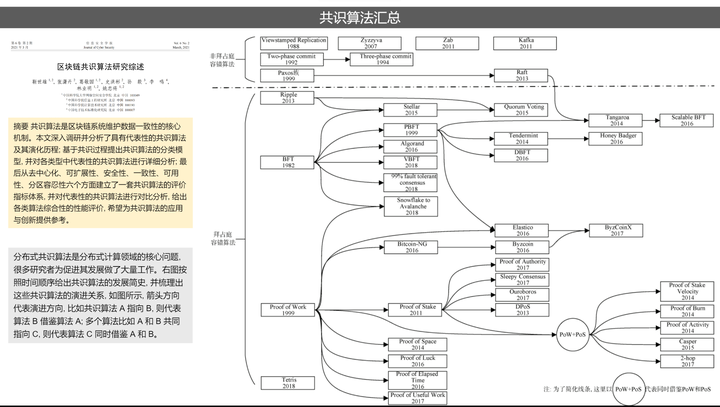
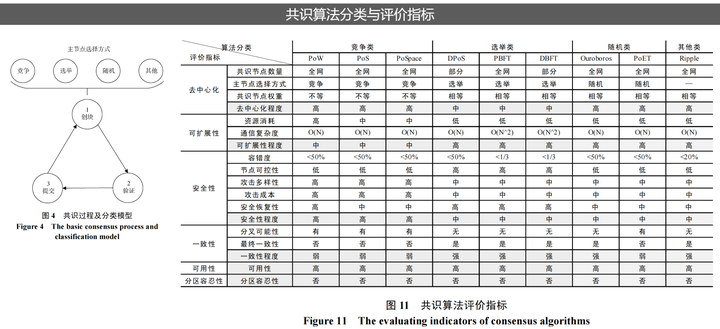
5.4.共识机制
重点是理解Paxos和Raft协议。
Paxos和Raft都是分布式选举算法,用于解决分布式系统中的数据一致性问题。它们的目标是在多个节点之间达成某种状态或值的共识,以确保系统的可靠性和容错性。
Paxos算法是由Leslie Lamport在1998年提出的,它使用基于消息传递的方式,通过在不同的阶段进行消息传递来达成一致性。Paxos算法的基本流程包括:提议者(Proposer)向多个接受者(Acceptor)发起提议,接受者对提议进行投票,并将投票结果告知提议者,最终提议者根据接受者的投票结果确定一个值。Paxos算法在分布式系统中被广泛采用,如Google的Chubby、Megastore和Spanner等。
Leslie Lamport,毋庸置疑,分布式计算领域的一代宗师:

Raft算法则是由Diego Ongaro和John Ousterhout在2013年提出的,它也是一种基于消息传递的分布式一致性算法。Raft算法的主要目标是提高分布式一致性算法的可理解性和可实现性。与Paxos相比,Raft算法具有更简单的结构和更清晰的流程。Raft算法将一致性问题分解为三个相对独立的子问题:领导者选举、日志复制和安全性。在Raft中,节点有三种状态:领导者(Leader)、跟随者(Follower)和候选人(Candidate)。通过领导者选举机制,Raft算法确保在任一时间只有一个领导者节点,负责处理所有的写请求和日志复制。
共识算法本身非常复杂,后续专文展开。
6.安全设计

6.1.接口安全
12种提升API接口安全的方式:
- 使用HTTPS加密协议:利用SSL证书,对TCP连接、传输数据和返回结果进行加密,以防止数据被截获和篡改。
- OAuth2接口鉴权:采用OAuth2作为接口鉴权方式,更侧重于对接口客户端的身份进行核查。
- WebAuthn身份验证:利用WebAuthn(Web Authentication)进行身份验证,例如常见的会员用户账号密码登录,提高账户安全性。
- API密钥管理:通过统一认证服务为接口客户端分配API密钥,客户端使用密钥访问目标服务。
- 权限控制:在应用层和业务层实施权限控制,根据用户身份、角色、等级等判断账号的查看、修改、删除等权限。
- 限流措施:对单个IP、用户或行为进行接口流量限制,例如限制1秒内的请求次数,以防止恶意攻击或滥用。
- 版本控制:在接口路由中加入版本号,如GET /v1/users/123,以便管理和维护不同版本的接口。
- 白名单配置:针对IP、用户等设置白名单规则,只允许白名单内的访问,提高接口安全性。
- 安全漏洞扫描:定期扫描接口是否存在安全漏洞,及时发现并修复潜在的安全风险。
- API网关使用:使用API接口网关作为统一入口,进行请求转发、身份验证、限流等操作,增强接口的安全性和管理性。
- 错误处理:对接口错误进行统一处理,提供具有自我描述性的错误信息,有助于问题定位和解决,避免接口崩溃或无意义的错误码。
- 输入验证:对来自客户端的所有参数进行严格的规则校验,包括是否必填、数据类型、取值范围、默认值等,确保输入数据的合法性和安全性。
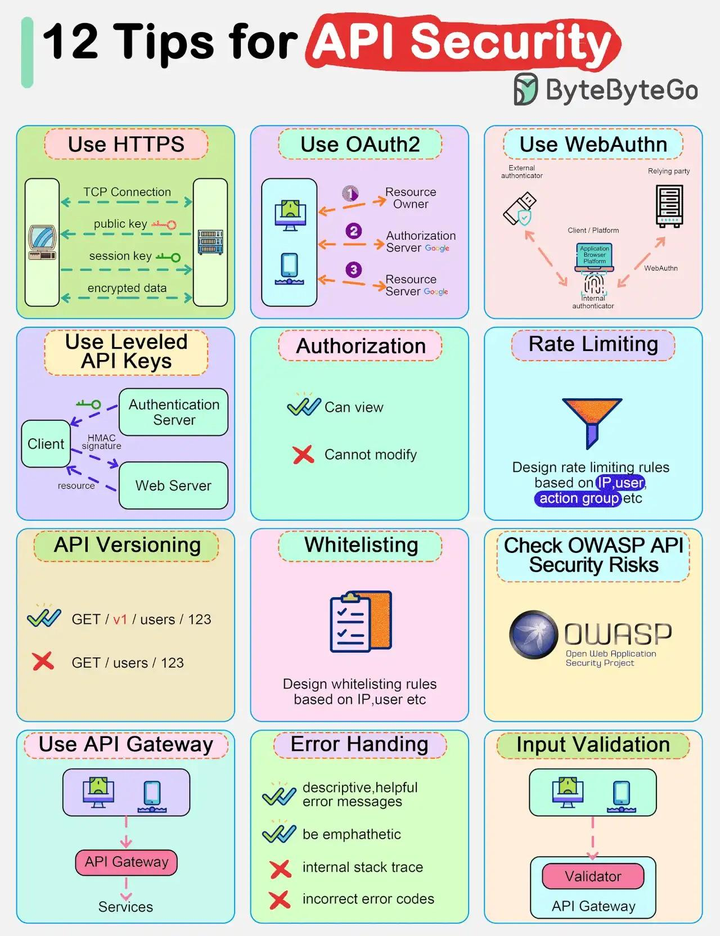
图片来源:ByteByteGo
除了以上方法,常见的加强API安全性的方法,还有接口签名算法、幂等、频控等方法。以下是笔者在工作中用到的一些方法。
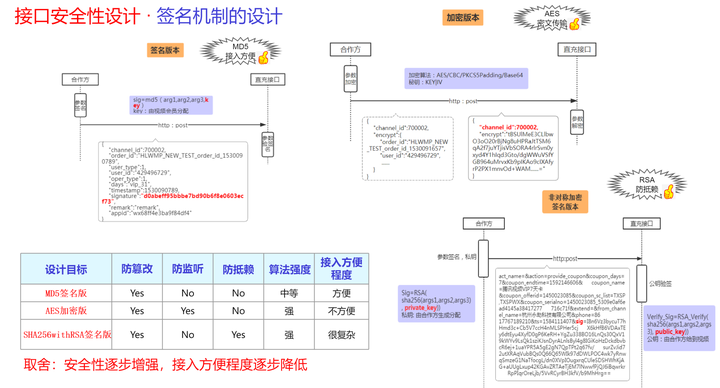
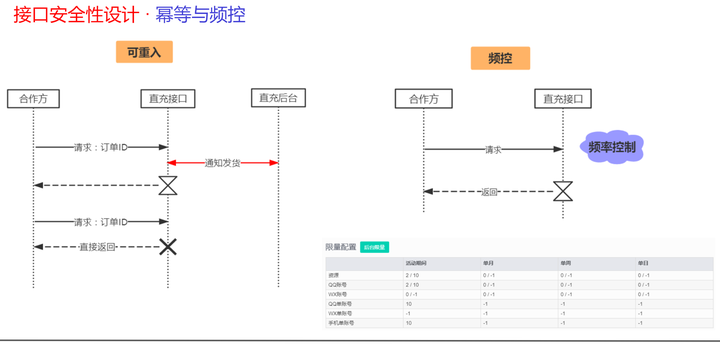
6.2.RBAC
参考下面这篇文章:

6.3.Oauth
同上。
6.4.密码学
同上。
7.工程上如何落地
前面介绍的内容都偏理论,理论只有落实到工程才有用,那么在工程上如何落地呢?
下面介绍一些腾讯的技术经验。
腾讯内部,历史上有过非常多的开发框架,例如svrframework,spp,going,taf等,各BG独立发展,山头林立。2018年前后,一些硅谷技术专家加入腾讯,有专家说"来了腾讯,就像来到了技术的沙漠一样"。当时的情况就是这样,各种技术栈错综复杂,俄罗斯套娃式的接口调用,从一个部门转到另一个部门,所有的技术栈需要重新学习一遍,学习成本很高。
迫于内外形势的压力,腾讯在2018.9.30做了战略变革,全公司在技术层面有两大变化,一个是内部开源,一个是统一编程框架。
- 内部开源有力打破了部门间的技术壁垒,促进技术资源的共享和协同。通过开源内部项目,腾讯鼓励员工跨部门参与项目开发和维护,从而增强技术交流与合作。这种策略有助于形成统一的技术文化和标准,提高整体技术水平和创新能力。
- 统一编程框架则解决了技术栈复杂的问题。通过制定统一的编程框架和规范,腾讯希望能够简化开发流程,降低学习和维护成本,提高开发效率和质量。这一举措有助于减少部门间的技术壁垒,促进技术的统一性和标准化,避免了不停地重复造轮子。
7.1.开源共建
开源共建,事后回过头来看,确实打破了各个BG(事业群)山头林立、技术碎片化的问题,促进了公司整体的技术共享与协同。好处是明显的,同时阻力也是巨大的。当时公司高层亲自下场,甚至不惜将一些有阻力的经理拿下,强制要求各个BG(事业群)的代码开源,并制定开源率指标,在这些强有力的措施之下,开源共建终于开花结果。
现在还没有内部开源的企业,可以参考腾讯的开源共建实践,其好处是:
- 促进技术共享与协同:通过开源,不同部门的开发人员可以更容易地访问、理解并使用彼此的代码,这有助于减少重复劳动,促进跨部门的合作与协同。
- 提高代码质量:开源通常意味着代码会接受来自更广泛社区的审查和反馈。这种公开的审查过程有助于提高代码的质量、可靠性和安全性。
- 加速技术创新:开源环境鼓励创新和实验。当开发人员能够自由地访问和使用公司内部的各种技术和工具时,他们更有可能进行创新和尝试新的解决方案。
- 培养开放的企业文化:开源不仅仅是关于代码,它还涉及到一种开放、透明和协作的文化。这种文化有助于吸引和留住顶尖人才,同时也使公司更加灵活和适应变化。
当然,任何好的事情,都伴随挑战:
- 文化转变:对于习惯了闭源开发模式的团队来说,转向开源可能需要一段时间的文化适应和流程调整,尤其当这种转变,牵扯到一些人的利益时,会产生很多阻力。
- 安全和隐私:在开源环境中,需要格外注意保护敏感数据和确保代码的安全性。
7.2.统一框架
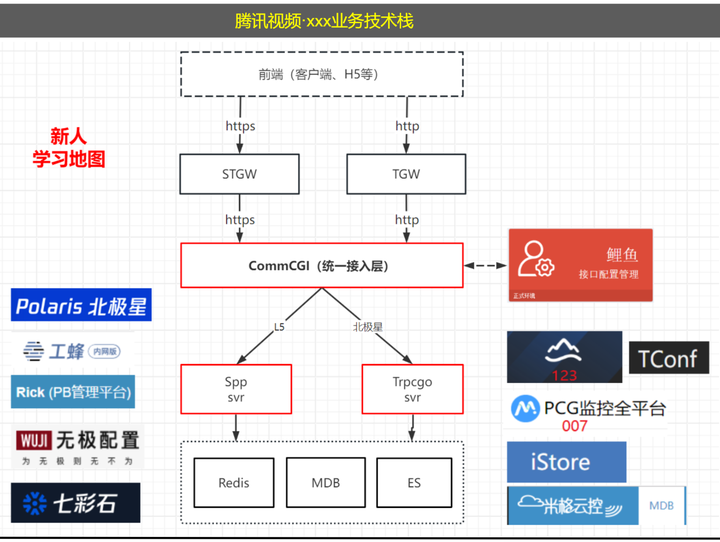
2018年之前,一个新人入职腾讯后,需要学习一系列的技术组件和编程框架。七七八八的技术组件加上一套SPP编程框架,通常会经历2~3个月的学习期。

2018年之前腾讯视频使用的技术栈:
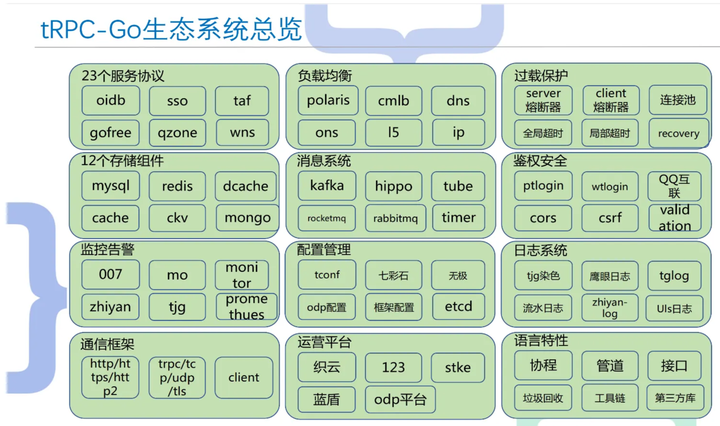
2018年之后,随着Golang 语言的兴起,以及公司内部的大力推广,用了大概2年的时间,终于形成了一个公司级的统一编程框架Trpcgo。这个框架采用插件架构,兼容了公司各种各样的组件和技术栈。从此,全公司的技术人员都可以在一套框架下工作。技术沙漠终于变成了技术生态。
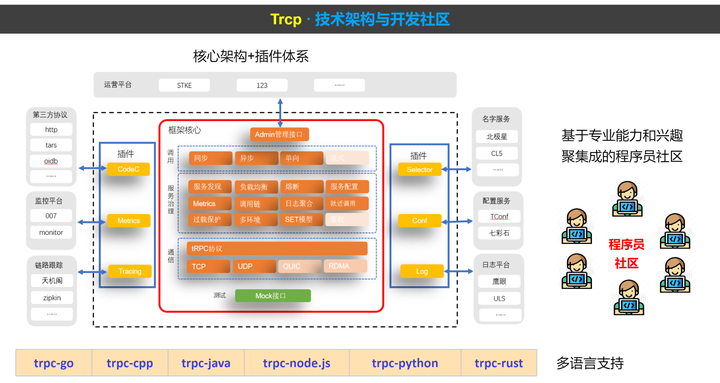
Trcp框架本身是个多语言框架,Trpcgo是其Golang语言分支,之后陆续推出了C++、Java、python、nodejs、rust等语言分支。开发模式上采用内部开源的方式,全公司的开发都可以参与,然后有个专门的OTeam小组,由技术骨干组成,用来协调大家的工作。
新框架好是好,但是从老框架切换到新框架,涉及很多迁移与重构工作,繁琐且容易出错,需要搞很久。当时我们从项目启动,到取得阶段性成果,大概用了一年半的时间。在这之前,至少花了半年的时间来学习Golang语言。所以前前后后加起来,大概花了两年多的时间。
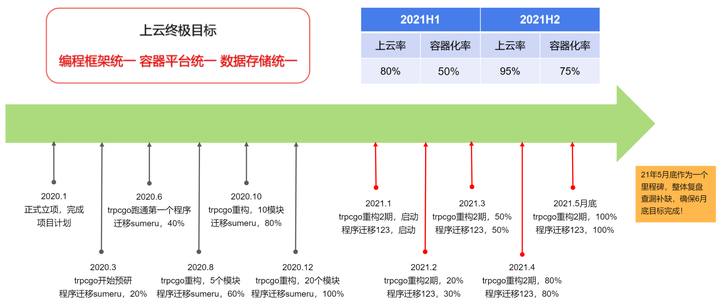
过程是艰难的,但结果是好的。打那以后,不管是胖子的柔道,还是分布式计算,都汇入到trpc编程框架这个技术生态,哲学问题与科学问题最终统一成了一个工程问题,横亘在各个部门之间的那座巴别塔终于被推倒了,所有开发者都讲同一种语言,人员转岗后也可以快速上手。
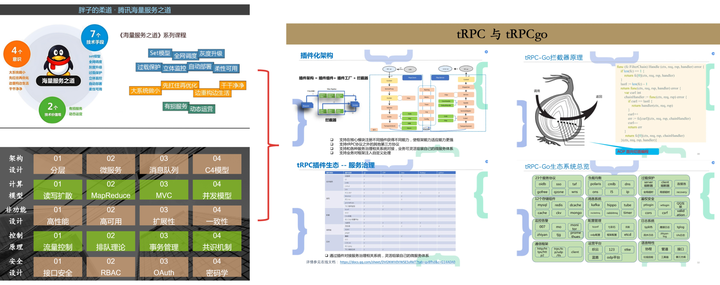
7.3.引入外脑
为了顺利推动这次战略的顺利落地,腾讯专门聘请了业内知名的技术咨询公司的ThoughtWorks。这是笔者加入腾讯十几年,第一次见到腾讯公司聘请专业咨询公司,来做一次从上到下的技术变革。
对于腾讯这样规模的科技公司而言,聘请业内知名的技术咨询公司,来参与和推动从上到下的技术变革,显示了领导层对这次战略变革的决心。
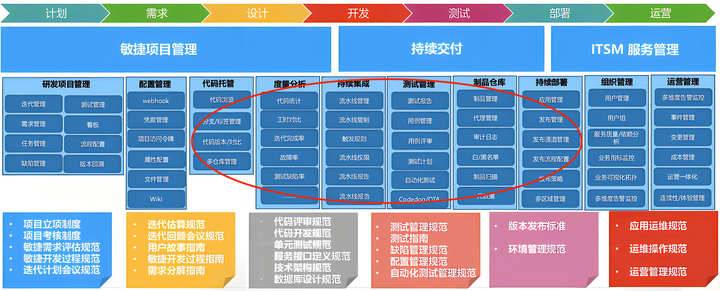
咨询团队由乔梁老师(《持续交付2.0》的作者)带队,用了将近三年的时间,将下面的流程构建为电子流,并在整个腾讯推广起来。
8.写在最后
笔者在腾讯码了十几年代码,看过上百本技术专著,读过上百篇技术论文。上面这些技术点是笔者长期工作实践的总结。
有人会问,这些很理论的东西,对我的工作到底有什么用呢?
借用《教父》的一句话:“花一秒钟就看透事物本质的人,和花一辈子都看不清事物本质的人,注定是截然不同的命运。”
在企业里面,经常有些代码写的好的人,非常看不起那些PPT写得好的人,但事实就是会写PPT的比会写Code的赚的多。背后的原因不难理解:
尽管在腾讯没有某些公司那样的"胶片文化",但互联网公司所谓的"成果显性化",在腾讯也是适应的。"成果显性化"意味着将工作成果以可视化、可量化的方式清晰地呈现出来,以便于内部和外部人员理解和评估。这种理念在互联网行业尤为重要,因为互联网行业的竞争激烈,产品迭代迅速,团队需要快速展示工作成果以获取反馈、支持和资源。
在腾讯,虽然没有像华为那样强调通过PPT进行工作汇报,但团队成员仍然需要以各种方式将工作成果显性化。这可能包括通过数据报告、产品演示、项目进度更新等方式来展示工作进展和成果。这样的做法有助于增强团队之间的协作和沟通,提高工作效率,同时也能够向管理层和外部利益相关者展示团队的工作价值和成果。
希望本文对你有所帮助,尤其是那些TeamLeader/TechLead/架构师岗位上工作的人。
版权归原作者 文慧的科技江湖 所有, 如有侵权,请联系我们删除。