
习题来源于《信息检索导论》这本书,书籍封面如下图。该题库为我们老师标注的重点,仅供参考,具体重点还请大家咨询自己的课程老师。

第2章 词项词典及倒排记录表
习题 2-7:考虑利用如下带有跳表指针的倒排记录表 和一个中间结果表(如下所示,不存在跳表指针)进行合并操作。
和一个中间结果表(如下所示,不存在跳表指针)进行合并操作。 采用图2-10所示的倒排记录表合并算法,请问:
采用图2-10所示的倒排记录表合并算法,请问:
1.当两个表进行合并时,倒排记录之间的比较次数是多少?
解答:
18次:< 3,3>, <5,5>, <9,89>,<15,89>,<24,89>,<75,89>,<92,89>,<81,89>,<84,89>,<89,89>,<92,95>,<115,95>,<96,95>,<96,97>,<97,97>,<100,99>,<100,100><115,101>
2.如果不使用跳表指针,那么倒排记录之间的比较次数是多少?
解答:
19次: < 3,3>,<5,5>,<9,89>,<15,89>,<24,89>,<39,89>,<60,89>,<68,89>,<75,89>,<81,89>,<84,89>,<89,89> <92,95>, <96,95>,<96,97>,<97,97>,<100,99>,<100,100>,<115,101>
第3章 词典及容错式检索
习题 3-8:计算oslo和snow之间的编辑距离,其中的4 × 4 矩阵,包含每个前缀子串之间的计算结果。
解答:

第5章 索引压缩
习题 5-5:写出倒排记录表(777, 17743, 294068, 31251336)的可变字节编码及γ编码。在可能的情况下对间距而不是文档ID编码。请以8位二进制串的方式写出这些编码。
解答:
倒排记录表的间隔序列为(777,16966,276325,30957268)
二进制分别是:(1100001001, 100001001000110, 1000011011101100101, 1110110000101111011010100)



习题 5-8:对于下列采用γ 编码的间距编码结果,请还原原始的间距序列及倒排记录表。
1110001110101011111101101111011
解答:
1110 001; 110 10; 10 1; 111110 11011; 110 11
二进制为:1001;110;11;111011;111
十进制为:9;6;3;32+16+8+2+1=59;7
倒排记录表为:9;15;18;77;84
第6章 文档评分、词项权重计算及向量空间模型
习题 6-19:计算查询digital cameras及文档digital cameras and video cameras的向量空间相似度并将结果填入表6-1的空列中。假定N=10000000,对查询及文档中的词项权重(wf对应的列)采用对数方法计算,查询的权重计算采用idf,而文档归一化采用余弦相似度计算。将and看成是停用词。请在tf列中给出词项的出现频率,并计算出最后的相似度结果。
解答:




与表格中结果不太一致,可能是计算时保留位数不同的原因。
第8章 信息检索的评价
习题 8-1:计算系统1和系统2对查询1,2的正确率P@2,p@5,并分析两个系统对于查询1,2的优劣。 解答:
解答:
系统1查询1: P@2=1, P@5=2/5,R正确率=1;
系统1查询2: P@2=1/2, P@5=2/5,R正确率=0.5
系统2查询1: P@2=1/2, P@5=2/5,R正确率=0.5
系统2查询2: P@2=1, P@5=3/5;R正确率=1
显然对于查询1来说,系统1更优;对于查询2来说,系统2更优。
习题 8-2:计算kappa统计量 解答:
解答:
P(A)=(300+70)/400=370/400=0.925(两人一致性的判断率)
P(nonrelevant)=(80+90)/(400+400)=170/800=0.2125(边缘统计量)
P(relevant)=(320+310)/(400+400)=630/800=0.7878(边缘统计量)
P(E)=P(nonrelevant)2+P(relevant)2=0.212522+0.787822=0.665(两人的随机一致性比率)
Kappa=(P(A)-P(E))/(1-P(E))=(0.925-0.665)/(1-0.665)=0.776
习题 8-7:考虑一个有4篇相关文档的信息需求,考察两个系统的前10个检索结果(左边的结果排名靠前),相关性判定的情况如下所示:
系统1 R N R N N N N N R R
系统2 N R N N R R R N N N
(1) 计算两个系统的MAP值并比较大小。
系统1: (1+2/3+3/9+4/10)/4=0.6
系统2 (1/2+2/5+3/6+4/7)/4=0.492
(2) 上述结果直观上看有意义吗?能否从中得出启发如何才能获得高的MAP得分?
相关文档出现得越靠前越好。
(3) 计算两个系统的R正确性值。
系统1的R-Precision= 0.5(2,前4个结果2篇相关/4,4篇相关文档), 系统2 R-Precision= 0.25(1/4)
习题 8-8、在10000篇文档构成的文档集中,某个查询的相关文档总数为8,下面给出了某系统针对该查询的前20个有序结果的相关(用R表示)和不相关(用N表示)情况,其中有6篇相关文档:
R R N N N N N N R N R N N N R N N N N R
(1)前20篇文档的正确率是多少?
P@20=6/20=30%
(2)前20篇文档的F1值是多少?
F1=2PR/(P+R) =3/7=0.429,其中P=6/20,R=6/8
(3)在25%召回率水平上的插值正确率是多少?
2/8=0.25,即返回两个正确结果,前两个返回的均为正确结果,则正确率为2/2=1
(4)在33%召回率水平上的插值正确率是多少?
3/8=37.5%,即返回三个正确结果,前九个查询返回三个正确结果,正确率为3/9=33.3%
(4)假定该系统所有返回的结果数目就是20,请计算其MAP值。
(1+1+3/9+4/11+5/15+6/20)/8=0.4163
(5)假定该系统返回了所有的10 000篇文档,上述20篇文档只是结果中最靠前的20篇文档,那么该系统可能的最大MAP是多少?
从第21位开始,接连两篇相关文档,此时可以获得最大的MAP,此时有:
(1+1+3/9+4/11+5/15+6/20+7/21+8/22)/8=0.503
(6)该系统可能的最小MAP是多少?
(1+1+3/9+4/11+5/15+6/20+7/9999+8/10000)/8=0.4165
第12章 基于语言建模的信息检索模型
习题 12-7:假定某文档集由如下4篇文档组成: 为该文档集建立一个查询似然模型。假定采用文档语言模型和文档集语言模型的混合模型,权重均为0.5。采用MLE来估计两个一元模型。计算在查询click、shears以及click shears下每篇文档模型对应的概率,并利用这些概率来对返回的文档排序。将这些概率填在下表中。
为该文档集建立一个查询似然模型。假定采用文档语言模型和文档集语言模型的混合模型,权重均为0.5。采用MLE来估计两个一元模型。计算在查询click、shears以及click shears下每篇文档模型对应的概率,并利用这些概率来对返回的文档排序。将这些概率填在下表中。 由表格可知:doc4>doc1>doc2>doc3
由表格可知:doc4>doc1>doc2>doc3
第13章 文本分类及朴素贝叶斯方法
习题 13-1:估计朴素贝叶斯分类器的参数,对测试文档进行分类,基于下表中的数据,进行如下计算:
(i) 估计多项式NB分类器的参数;
(ii) 将(i)中的分类器应用到测试集;

 计算过程中为了避免零概率使用了加一平滑,词汇表大小即文档中不同词汇的个数,三次方因为Chinese出现了三次。
计算过程中为了避免零概率使用了加一平滑,词汇表大小即文档中不同词汇的个数,三次方因为Chinese出现了三次。
第16章 扁平聚类
习题 16-3:对于图16-4,同一类中的每个点d都用两个同样的d的副本来替换。 (i)那么,对于新的包含34个点的集合进行聚类,会比图16-4中17个点的聚类更容易、一样难还是更难?
(i)那么,对于新的包含34个点的集合进行聚类,会比图16-4中17个点的聚类更容易、一样难还是更难?
(ii)计算对 34个点聚类的纯度、RI。在点数增加一倍之后,哪些指标增大?哪些指标保持不变?
(iii)在得到(i)中的判断和(ii)中的指标之后,哪些指标更适合于上述两种聚类结果的质量比较?
(i)我认为更难,因为34个点比17点的计算量增大了。
(ii)节点复制为原先的一倍后,
簇1:10个x类文档,2个o类文档;
簇2:2个x类文档,8个o类文档,2个O类文档;
簇3:4个x类文档, 6个O类文档。
共有N=34篇文档。
计算纯度:(1/34)×(10+8+6)≈0.71:
计算RI:
TP=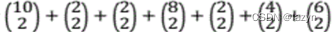 =97,将一对同类的文档分到相同聚类中的对数。
=97,将一对同类的文档分到相同聚类中的对数。
TN=10×8+10×2+2×2+2×2+10×6+2×4+2×6+2×6+8×4+8×6+2×4=288,将一对不同类的文档分到不同聚类中的对数。
RI=(TP+TN)/(34¦2)=(97+288)/561=0.69
(iii)对比N=17时,纯度为0.71,RI为0.68。得出节点复制为原先的一倍后,指标几乎不变。
版权归原作者 lazyn 所有, 如有侵权,请联系我们删除。