
1. 简介
本文对《Vitis HLS 学习笔记--抽象并行编程模型-控制驱动与数据驱动-CSDN博客》中控制驱动任务的示例进行了详细解析。
通过分析 kernel 代码,理解了 diamond 函数及其内部各功能模块(funcA、funcB、funcC、funcD)的实现方式和并行处理机制。
2. 代码解析
2.1 kernel 代码回顾
#include "diamond.h"
void diamond(data_t vecIn[N], data_t vecOut[N]) {
data_t c1[N], c2[N], c3[N], c4[N];
#pragma HLS dataflow
funcA(vecIn, c1, c2);
funcB(c1, c3);
funcC(c2, c4);
funcD(c3, c4, vecOut);
}
void funcA(data_t* in, data_t* out1, data_t* out2) {
#pragma HLS inline off
Loop0:
for (int i = 0; i < N; i++) {
#pragma HLS pipeline
data_t t = in[i] * 3;
out1[i] = t;
out2[i] = t;
}
}
void funcB(data_t* in, data_t* out) {
#pragma HLS inline off
Loop0:
for (int i = 0; i < N; i++) {
#pragma HLS pipeline
out[i] = in[i] + 25;
}
}
void funcC(data_t* in, data_t* out) {
#pragma HLS inline off
Loop0:
for (data_t i = 0; i < N; i++) {
#pragma HLS pipeline
out[i] = in[i] * 2;
}
}
void funcD(data_t* in1, data_t* in2, data_t* out) {
#pragma HLS inline off
Loop0:
for (int i = 0; i < N; i++) {
#pragma HLS pipeline
out[i] = in1[i] + in2[i] * 2;
}
}
2.2 功能分析
void diamond(data_t vecIn[100], data_t vecOut[100])
{
data_t c1[100], c2[100], c3[100], c4[100];
#pragma HLS dataflow
funcA(vecIn, c1, c2);
funcB(c1, c3);
funcC(c2, c4);
funcD(c3, c4, vecOut);
}

2.3 查看综合报告
- diamond 主函数中,Pipelined 一列的标志为:dataflow
+ Performance & Resource Estimates:
PS: '+' for module; 'o' for loop; '*' for dataflow
+--------------------------+------+------+---------+-----------+----------+---------+------+----------+--------+----+------------+-----------+-----+
| Modules | Issue| | Latency | Latency | Iteration| | Trip | | | | | | |
| & Loops | Type | Slack| (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP| FF | LUT | URAM|
+--------------------------+------+------+---------+-----------+----------+---------+------+----------+--------+----+------------+-----------+-----+
|+ diamond* | -| 0.00| 452| 4.520e+03| -| 175| -| dataflow| 4 (1%)| -| 1433 (~0%)| 3208 (2%)| -|
| + funcA | -| 0.00| 174| 1.740e+03| -| 174| -| no| -| -| 222 (~0%)| 652 (~0%)| -|
| + funcA_Pipeline_Loop0 | -| 0.00| 103| 1.030e+03| -| 103| -| no| -| -| 86 (~0%)| 123 (~0%)| -|
| o Loop0 | -| 7.30| 101| 1.010e+03| 3| 1| 100| yes| -| -| -| -| -|
| + funcB | -| 5.18| 102| 1.020e+03| -| 102| -| no| -| -| 17 (~0%)| 81 (~0%)| -|
| o Loop0 | -| 7.30| 100| 1.000e+03| 2| 1| 100| yes| -| -| -| -| -|
| + funcC | -| 5.95| 102| 1.020e+03| -| 102| -| no| -| -| 17 (~0%)| 66 (~0%)| -|
| o Loop0 | -| 7.30| 100| 1.000e+03| 2| 1| 100| yes| -| -| -| -| -|
| + entry_proc | -| 5.46| 0| 0.000| -| 0| -| no| -| -| 2 (~0%)| 20 (~0%)| -|
| + funcD | -| 0.00| 174| 1.740e+03| -| 174| -| no| -| -| 183 (~0%)| 692 (~0%)| -|
| + funcD_Pipeline_Loop0 | -| 0.00| 103| 1.030e+03| -| 103| -| no| -| -| 47 (~0%)| 131 (~0%)| -|
| o Loop0 | -| 7.30| 101| 1.010e+03| 3| 1| 100| yes| -| -| -| -| -|
+--------------------------+------+------+---------+-----------+----------+---------+------+----------+--------+----+------------+-----------+-----+
- vecIn、vecOut 的映射关系,可以观察到是 m_axi_gmem 接口。
- vecIn、vecOut 为非本地存储器,因此采用控制驱动 TLP 模型;
* SW-to-HW Mapping
+----------+---------------+-----------+----------+------------------------------------+
| Argument | HW Interface | HW Type | HW Usage | HW Info |
+----------+---------------+-----------+----------+------------------------------------+
| vecIn | m_axi_gmem | interface | | |
| vecIn | s_axi_control | register | offset | name=vecIn_1 offset=0x10 range=32 |
| vecIn | s_axi_control | register | offset | name=vecIn_2 offset=0x14 range=32 |
| vecOut | m_axi_gmem | interface | | |
| vecOut | s_axi_control | register | offset | name=vecOut_1 offset=0x1c range=32 |
| vecOut | s_axi_control | register | offset | name=vecOut_2 offset=0x20 range=32 |
+----------+---------------+-----------+----------+------------------------------------+
2.4 查看 Schedule Viewer
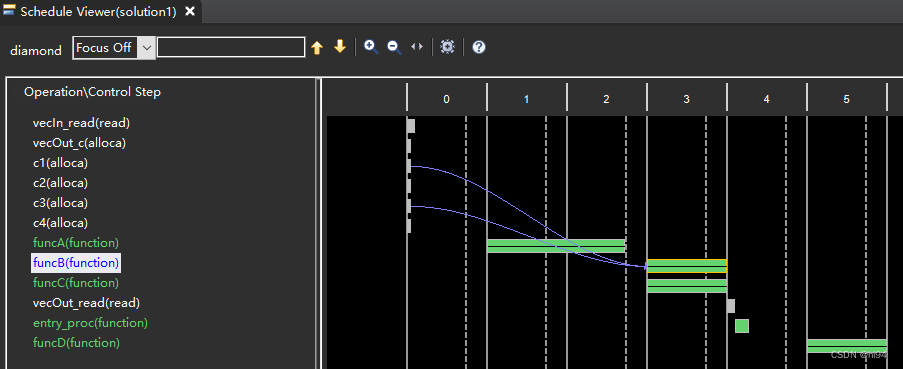
可以看到 funcB 和 funcC 被并行执行。
2.5 查看 Dataflow Viewer
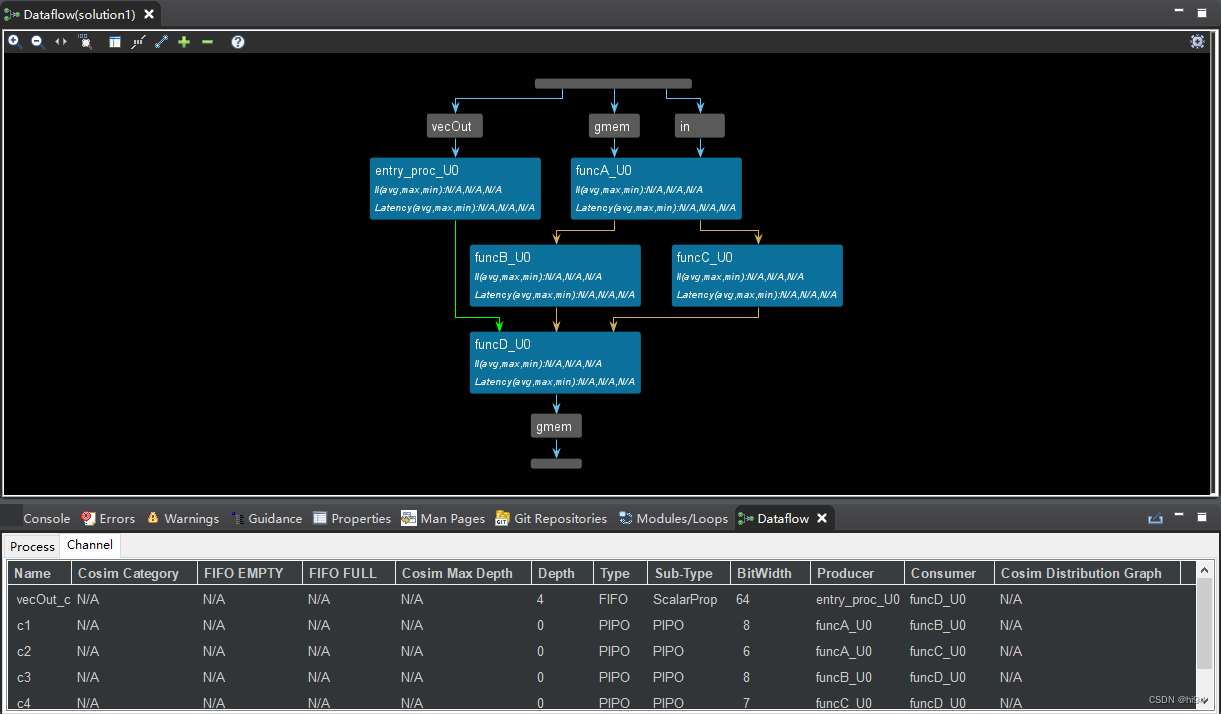
可以看到 vecOut 被设置成 FIFO,而 c1、c2、c3、c4 被设置为 PIPO。
3. Vitis IDE的关键设置
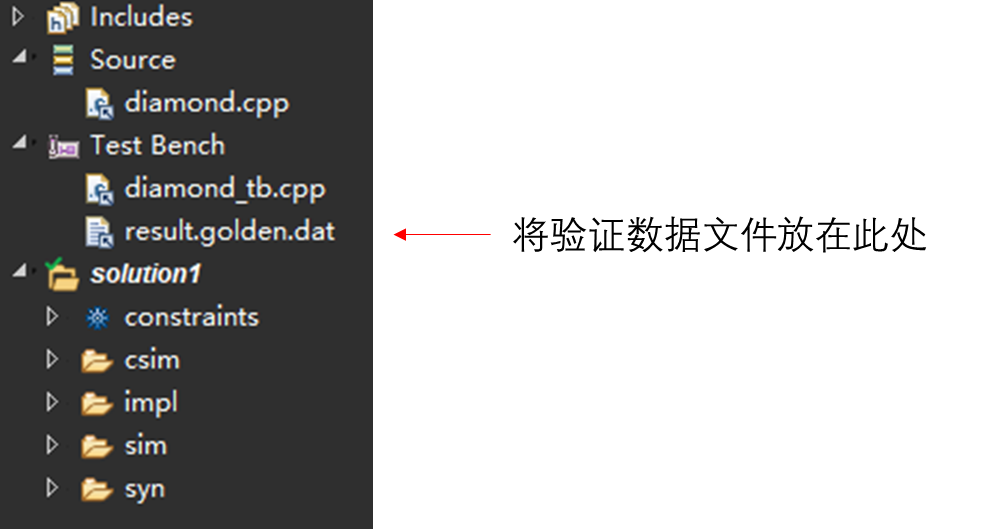
3.1 加载数据文件
需要添加验证数据文件,直接将其放在导航树 Test Bench 分支之下即可。
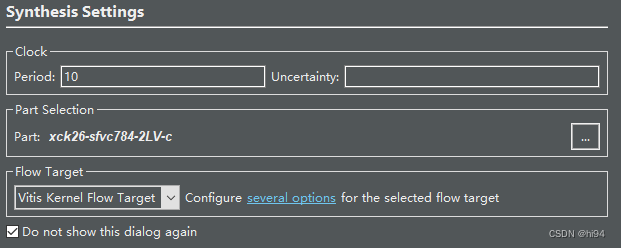
3.2 设置 Flow Target
将 Flow Target 设置成 Vitis Kernel Flow Target
区分 Vitis Kernel 和 Vivado IP Flow Taget
Vivado IP 流程和 Vitis 内核流程是两种不同的开发流程,它们在设计目标、灵活性和接口要求方面有所区别:
- Vivado IP 流程
设计灵活性:Vivado IP 流程提供了更大的设计灵活性。开发者可以自定义代码以实现广泛的接口标准,以满足特定的设计目标。
接口要求:几乎没有限制,可以根据需要选择不同的接口标准。
RTL开发:Vivado IP 流程专注于RTL开发,允许开发者使用Vivado工具直接编辑RTL代码,进行仿真验证,综合布局布线,以及时序分析。
IP封装:开发者可以将RTL代码封装为IP,以便在Vivado Design Suite中使用。
- Vitis 内核流程
特定要求和限制:Vitis 内核 (.xo) 是一种特殊类型的Vivado IP,它具有特定的要求和限制,例如必须遵循Vitis内核流程的接口标准。
自动化:Vitis HLS工具可以自动执行代码修改操作,如为函数实参生成接口,以及对代码内的循环和函数执行流水线化。
应用加速:主要用于Vitis应用加速开发流程中,在可编程逻辑中实现和最优化C/C++代码,以实现低时延和高吞吐量。
接口推断:Vitis HLS的基本作用是通过推断所需的编译指示来为函数实参生成正确的接口。
- Vitis Kernel Flow Target 的默认接口协议

Vitis 内核流程的默认执行模式为流水打拍执行,即启用内核的重叠执行以改善吞吐量。
- Vivado IP Flow Target 的默认接口协议
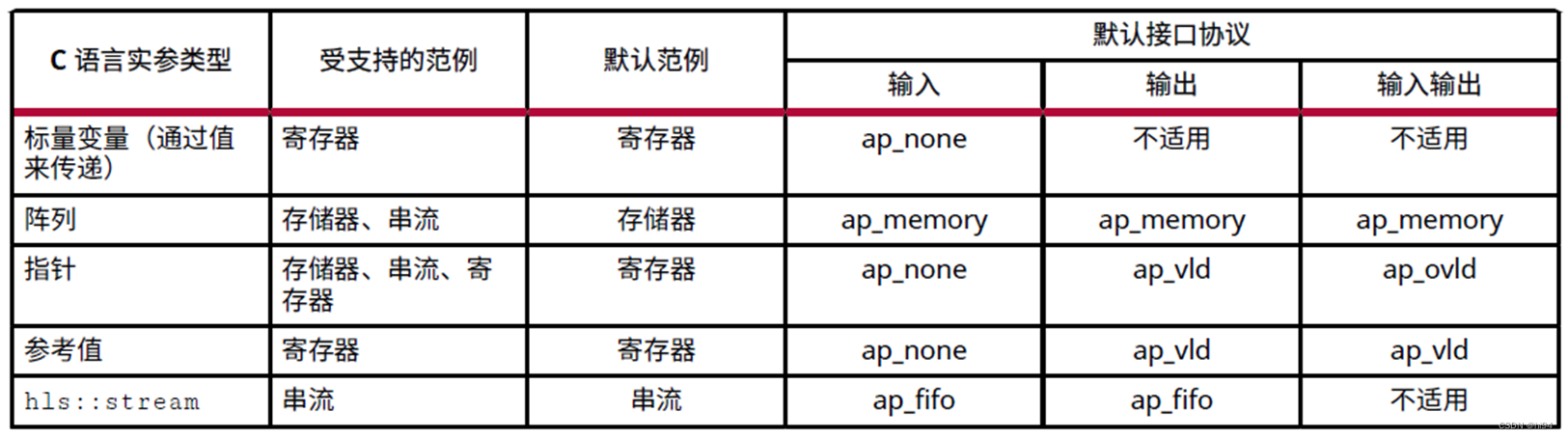
对于以上表格中范例的细化解释:

3.3 配置 fifo 深度
查看 DATAFLOW fifo 的默认深度:

也可以通过编译器指令进行配置:
Set any optimization directives
config_dataflow -default_channel fifo -fifo_depth 2
4. 总结
本文对《Vitis HLS 学习笔记--抽象并行编程模型-控制驱动与数据驱动-CSDN博客》中的控制驱动任务示例进行了详细解析,重点分析了 kernel 代码的并行处理机制及各模块的实现。通过查看综合报告、Schedule Viewer 和 Dataflow Viewer,确认了 funcB 和 funcC 的并行执行和 vecOut 的 FIFO 设置。并介绍了 Vitis IDE 的关键设置,包括数据文件加载、Flow Target 配置及 FIFO 深度调整。总结了 Vivado IP 流程与 Vitis 内核流程的区别,帮助理解两者在设计灵活性、接口要求及应用场景上的不同。

版权归原作者 hi94 所有, 如有侵权,请联系我们删除。