

** 📹北大快手联合推视频生成框架VideoTetris**
VideoTetris框架成功攻克复杂视频生成难题,超越商用模型Pika和Gen-2。
定义了组合视频生成任务,支持复杂指令和长视频生成,保留位置信息和细节特征。
采用时空组合扩散方法,优化训练数据预处理和引入参考帧注意力机制,生成更具动感和自然的视频。
🔗 VideoTetris: Towards Compositional Text-To-Video Generationt
🔗 北大快手攻克复杂视频生成难题!新框架轻松组合各种细节,代码将开源-CSDN博客


🖥️NVIDIA 发布 Nemotron-4 340B 开源模型
主要用于生成高质量的合成数据
Nemotron-4 340B可以生成多样化的合成数据,这些数据模仿现实世界的数据特征。
开发者可以用它来生成合成数据,以训练适用于各种行业(如医疗、金融、制造和零售等)的大型、大语言模型。
Nemotron-4 340B 包括 Nemotron-4-340B-Base、Nemotron-4-340B-Instruct 和 Nemotron-4-340B-Reward。
🔗详细介绍:https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-lm-training/
🔗论文:https://research.nvidia.com/publication/2024-06_nemotron-4-340b
🔗模型下载:
https://huggingface.co/nvidia/Nemotron-4-34OB-Instruct
https://huggingface.co/nvidia/Nemotron-4-340B-Reward
🔗 https://blink.csdn.net/details/1732502


🤖加州大学研发出新的 Transformer 架构 显著减少大模型对GPU的依赖
该架构完全消除了语言模型中的矩阵乘法(MatMul),在保持高性能的同时显著减少内存使用。
推理过程中,内存消耗减少了10倍以上。
通过使用优化后的内核,推理速度提升了4.57倍。
实验表明,所提出的无MatMul模型在2.7B参数规模下的性能与需要更多内存的最先进Transformer相当。
还展示了一种在FPGA上实现的自定义硬件解决方案,处理十亿参数规模的模型时功耗为13W,接近人脑的效率。


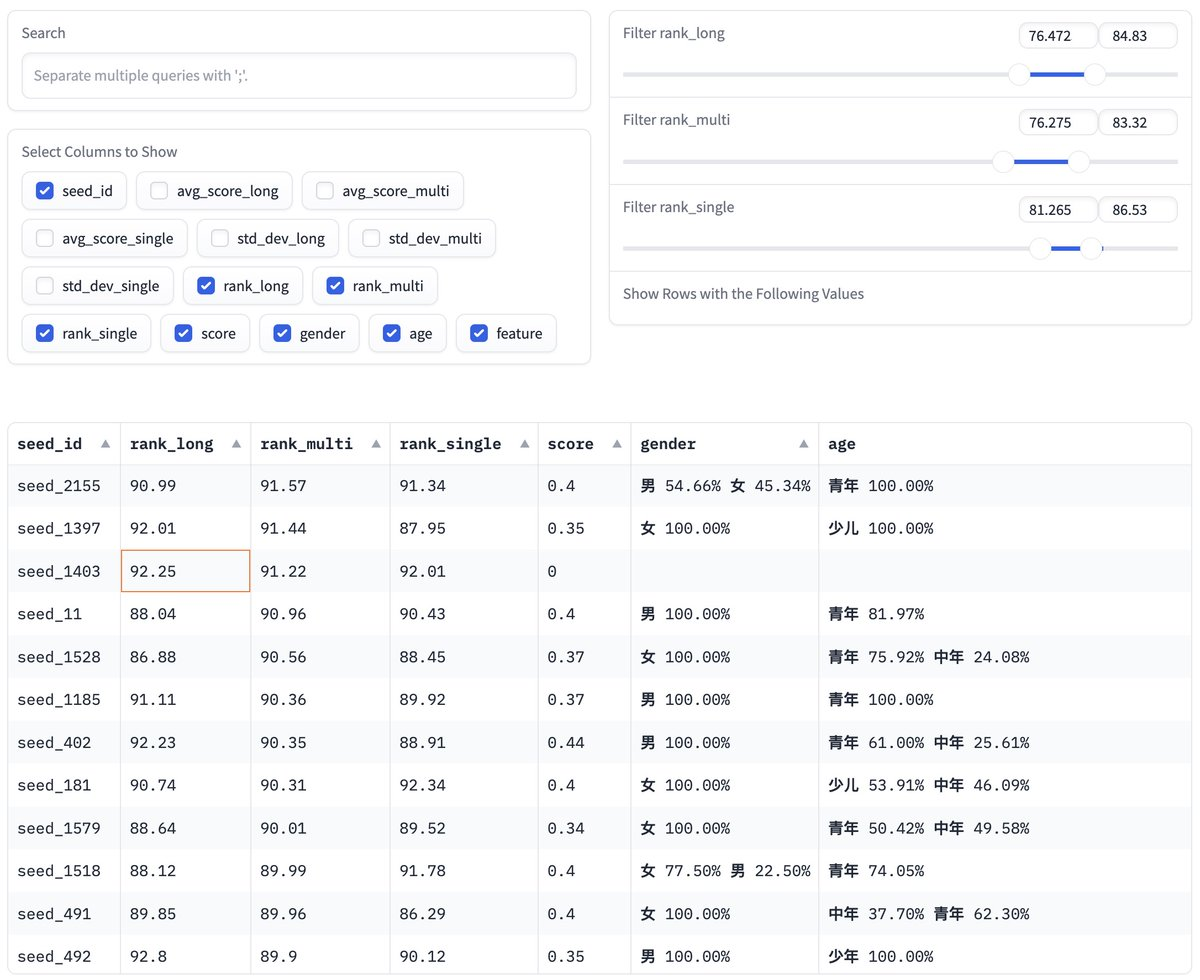
**🎵基于 ChatTTS 2600个音色库稳定性评分 **
并按性别和年龄分类 可试听
提供了一个系统化的方法对不同音色进行评估和打分,帮助用户选择在不同应用场景下音色稳定性较好的音色。
用户可以根据自己的需求,比如长句、短句、多句文本的音色稳定性,选择最合适的音色。
项目不仅提供了音色稳定性评分,还按照性别和年龄进行了分类,这对需要特定性别和年龄音色的应用场景(如个性化语音助手、教育软件等)非常有用。
🔗 https://huggingface.co/spaces/taa/ChatTTS_Speaker

🚀奥特曼计划将OpenAI转变为营利性公司
OpenAI的首席执行官Sam Altman最近向一些股东表示,公司正在考虑改变其治理结构。
OpenAI正在考虑将治理结构转变为营利性公益公司,脱离非盈利董事会的控制。
这一变动可能为OpenAI的 IPO 铺平道路,OpenAI当前估值为860亿美元。
也将允许CEO Sam Altman持有公司股份,这是一些投资者一直推动的举措。
据一位听过这些评论的人说,Altman提到的一个方案是成为像Anthropic和xAI那样的营利性公益公司。

版权归原作者 程序员的店小二 所有, 如有侵权,请联系我们删除。