

目录
本文相关数据资源免费下载
在本文中,你将学到:
0 如何构建模型并将其保存为Onnx模型
1 如何使用Netron可视化模型
2 如何在Web应用中使用模型进行预测
📈 机器学习最有用的实际用途之一是构建推荐系统,今天我们可以朝着这个方向迈出第一步!
一、内容介绍
在系列8的文章中,我们构建了一个基于UFO目击事件的回归模型,对其使用pickle库进行封装打包,并基于Flask库构建了Web应用,虽然这个打包方法简单易用,但是对于大多数Web应用,其构建环境是基于JavaScript语言的,因此使用一个JavaScript打包并使用模型更容易拓展和广泛应用。
1.Onnx模型
构建机器学习模型应用是AI业务系统中的重要组成部分。通过使用Onnx,我们可以在各种Web应用程序中使用模型。Python的第三方库skl2onnx可以帮我们把Scikit-learn模型转换为Onnx模型。
ONNX(Open Neural Network Exchange),开放神经网络交换,是用于在各种深度学习训练和推理框架转换的一个中间表示格式。在实际业务中,可以使用Pytorch或者TensorFlow训练模型,导出成ONNX格式,然后在转换成目标设备上支撑的模型格式,比如TensorRT Engine、NCNN、MNN等格式。ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性,开放性较强。
①skl2onnx库安装
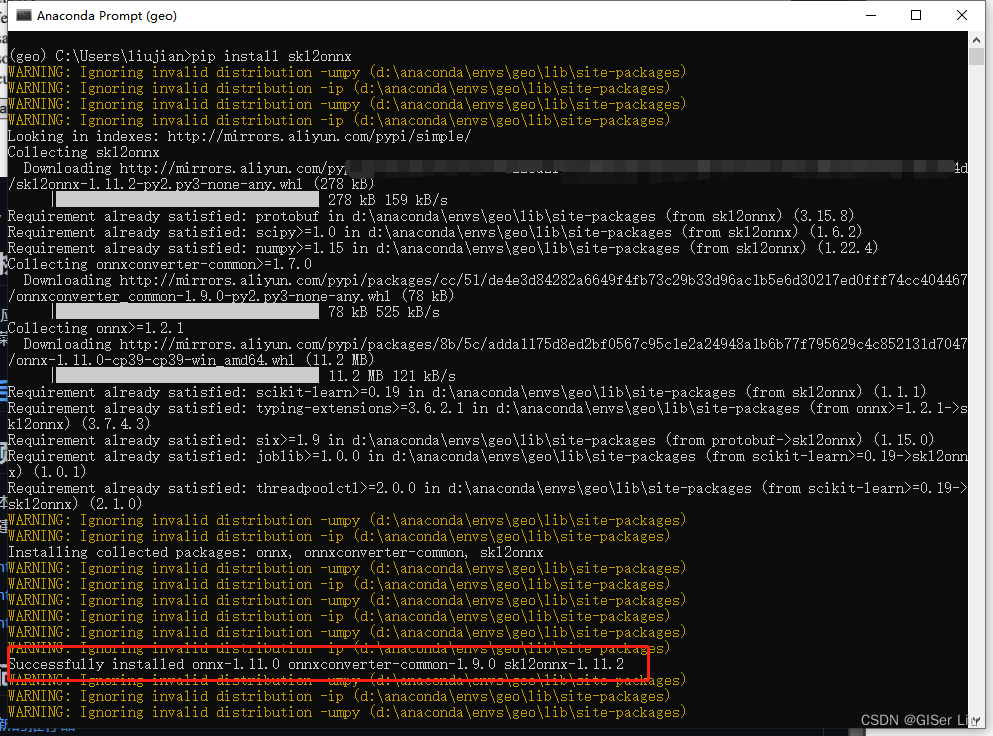
pip install -i https://mirrors.aliyun.com/pypi/simple/ skl2onnx
看到下图信息代表安装成功:
2.Netron安装
**Netron**是一个深度学习模型可视化库,其支持以下格式的模型存储文件:
ONNX (.onnx, .pb)
Keras (.h5, .keras)
CoreML (.mlmodel)
TensorFlow Lite (.tflite)
**netron**并不支持**pytorch**通过**torch.save**方法导出的模型文件,因此在**pytorch**保存模型的时候,需要将其导出为**onnx**格式的模型文件,可以利用**torch.onnx**模块实现这一目标。
Netron安装链接
安装好以后,双击即可运行,选中我们模型进行可视化查看。
二、模型构建
首先,使用我们之前已清理的亚洲美食数据集训练SVC线性分类模型。
1.数据加载
导入第三方库并调用查看之前处理好的亚洲美食数据集。
import pandas as pd
data = pd.read_csv('cleaned_cuisines.csv')
data.head()

2.划分可训练特征与预测标签
删去不需要的两列数据,并将剩余数据赋值给X,同理将标签另存为Y:
X = data.iloc[:,2:]#X为可训练特征
Y = data['cuisine']#Y为预测标签
3.训练模型
①第三方库导入
从Scikit-learn库中导入需要的函数:
from sklearn.model_selection import train_test_split#用于数据集的划分
from sklearn.svm import SVC#SVC模型
from sklearn.model_selection import cross_val_score#
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report#调用精度评价函数
②数据集划分
将数据集以7:3的比例划分为训练集与测试集:
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.3)
③SVC模型构建
构建一个SVC模型,核函数为“linear”。使用划分好的训练集数据进行模型训练。
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,Y_train.values.ravel())
④精度评价
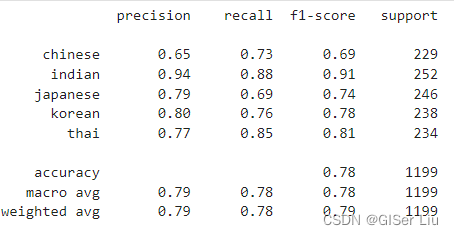
用训练好的模型预测出预测标签Y_pred,并打印出精度评价表。
Y_pred = model.predict(X_test)
print(classification_report(Y_test,Y_pred))
二、模型转换及可视化
在前文中,我们以及训练好了SVC模型,其精度达到了79%。现在我们需要将模型转换为Onnx格式。
确保使用正确的张量数进行转换,此数据集中有380个特征,因此我们需要在FloatTensorType函数中设定好特征数量。
1.参数配置
配置好Onnx模型参数,如数据类型为Float,数据类型为[1,380]的张量。
from skl2onnx import convert_sklearn
from skl2onnx.commmon.data_types import FloatTensorType
initial_type = [('float_input',FloatTensorType([None, 380]))]
options = {id(model):{'nocl': True, 'zipmap': False}}
2.Onnx模型生成
基于以上参数生成Onnx模型并保存在**model.onnx**文件中:
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("model.onnx", "wb") as f:
f.write(onx.SerializeToString())
现在,我们可以在文件夹中看到Onnx模型。

3.可视化模型
Onnx模型结构在代码中看起来并不是很明显,我们**Netron**软件来可视化模型。打开Netron软件,点击**Open model**,加载模型,选择我们刚刚生成的model.onnx文件。
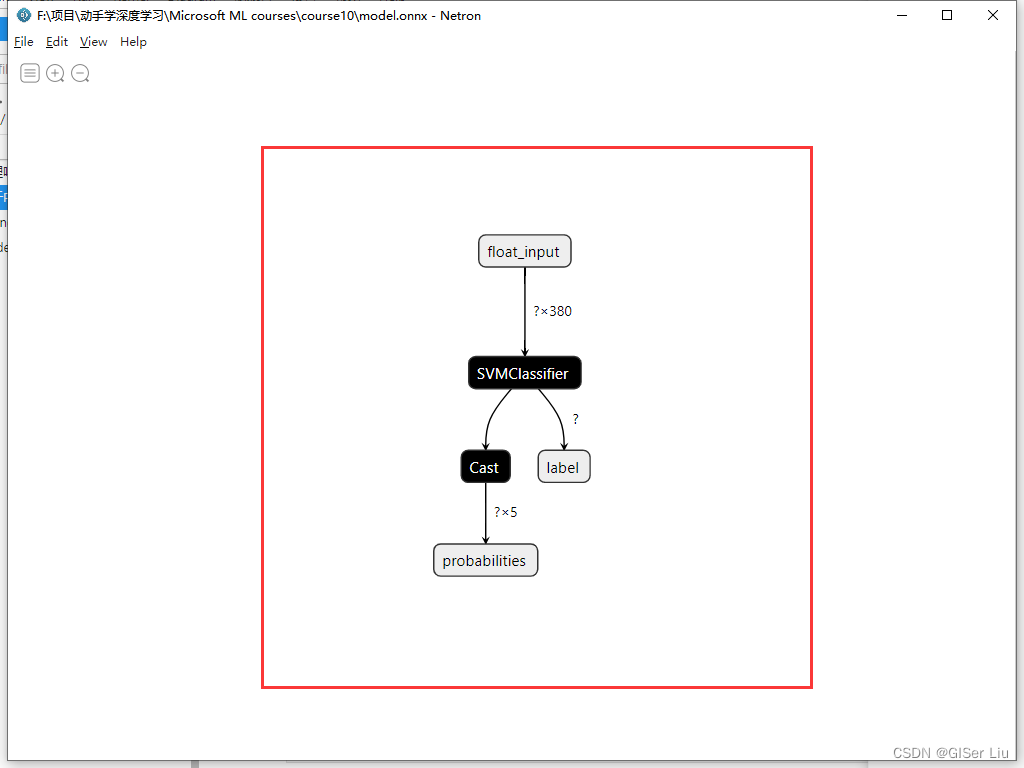
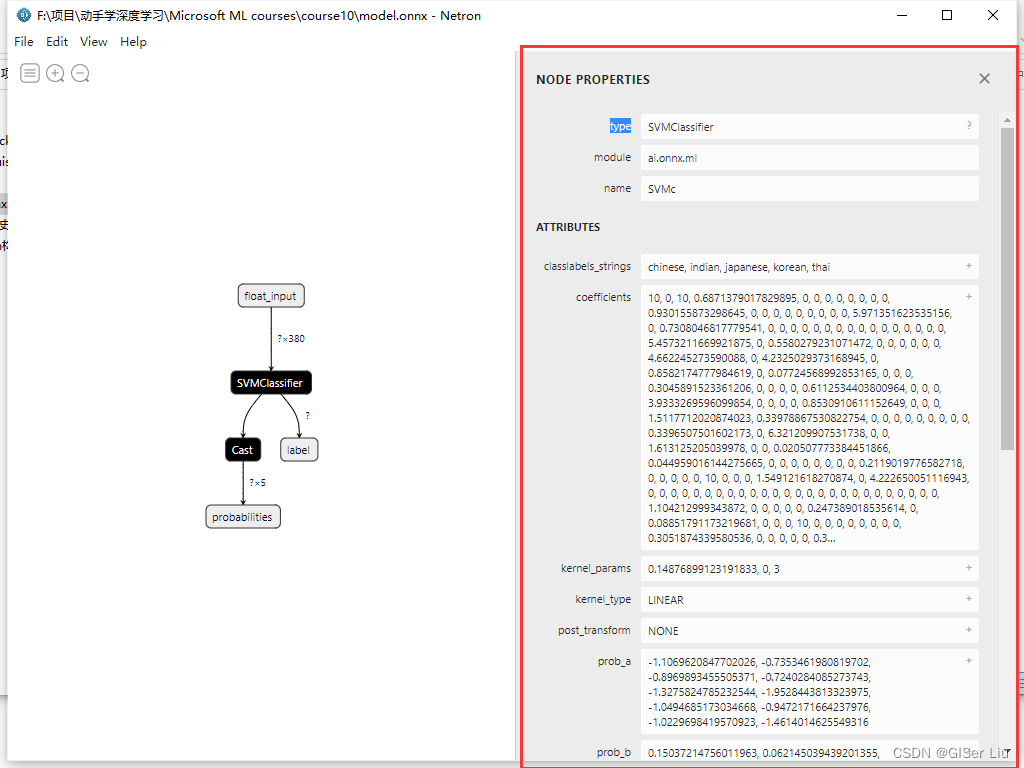
可以看到,模型的结构已被可视化,其中列出了380个特征输入与所用的分类器。我们可以点击不同的部分查看其数据类型,输出结果类型以及参数配置。
四、构建Web应用程序
现在,我们已经准备在Web应用程序上使用此模型,首先,我们先构建一个Web应用程序。
1.构建HTML文件
在文件夹下新建index.html,加入以下代码:(简单的Web代码,有点前端基础应该都能看懂)
<div class="boxCont">
<input type="checkbox" value="247" class="checkbox">
<label>pear</label>
</div>
<div class="boxCont">
<input type="checkbox" value="77" class="checkbox">
<label>cherry</label>
</div>
<div class="boxCont">
<input type="checkbox" value="126" class="checkbox">
<label>fenugreek</label>
</div>
<div class="boxCont">
<input type="checkbox" value="302" class="checkbox">
<label>sake</label>
</div>
<div class="boxCont">
<input type="checkbox" value="327" class="checkbox">
<label>soy sauce</label>
</div>
<div class="boxCont">
<input type="checkbox" value="112" class="checkbox">
<label>cumin</label>
</div>
</div>
<div style="padding-top:10px">
<button onClick="startInference()">预测</button>
</div>
</body>
tip:我们可以看到每个复选框都有一个值value,这个值是食材特征在模型张量中对应的索引。
2.构建JavaScript代码
在标签下方继续构建JavaScript脚本。
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/ort.min.js"></script>
<script>
//创建一个380的向量,并全部赋值为0
const ingredients = Array(380).fill(0);
//定义全局检查变量,用于获取复选框值
const checks = [...document.querySelectorAll('.checkbox')];
//foreach语句是for语句特殊情况下的增强版本,简化了编程,提高了代码的可读性和安全性。
checks.forEach(check => {
check.addEventListener('change', function() {
// toggle the state of the ingredient
// based on the checkbox's value (1 or 0)
ingredients[check.value] = check.checked ? 1 : 0;
});
});
//定义函数,检查check列表中是否有复选框被勾选,有则返回Ture,否则False
function testCheckboxes() {
return checks.some(check => check.checked);
}
//构建异步加载函数
async function startInference() {
let atLeastOneChecked = testCheckboxes()
if (!atLeastOneChecked) {
alert('请至少勾选一个复选框.');
return;
}
try {
// 创建一个新的 sessio加载模型.
const session = await ort.InferenceSession.create('model.onnx');
alert('模型加载成功!')
//创建一个[1,380]的张量对象
const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]);
const feeds = { float_input: input };
alert('参数输入成功!')
//输入模型session并开始预测,将结果赋值给results
const results = await session.run(feeds);
//读取results的值并以弹出框的形式展示结果
alert('你可以享受' + results.label.data[0] + ' 的美味!')
} catch (e) {
console.log(`模型加载失败!`);
console.error(e);
}
}
</script>
代码解析:
0 我们首先创建了一个包含380个值的数组,值默认全为0,这些值需要设置好后输入到模型进行预测,我们可以通过是否勾选复选框来更改某些参数。
1 我们创建了一个复选框数组,当我们选中该复选框时,数组中对应位置的值则会发生变化,变为1。默认为0。
2 我们创建了一个函数testCheckboxes,用于检查是否选中复选框。
3 当按下按钮时,该函数被调用,如果存在被选中的复选框,则加载模型,开始预测结果。
3.测试Web程序
在文件夹中选中双击我们建立的index.html软件,稍等片刻可以看到,界面已经加载出来。输入参数即可运行。
部分读者可能运行后没有效果,因为引入的js代码网站有墙。禁止访问,导致引入超时。读者可自行下载相关JavaScript代码,进行本地调用。
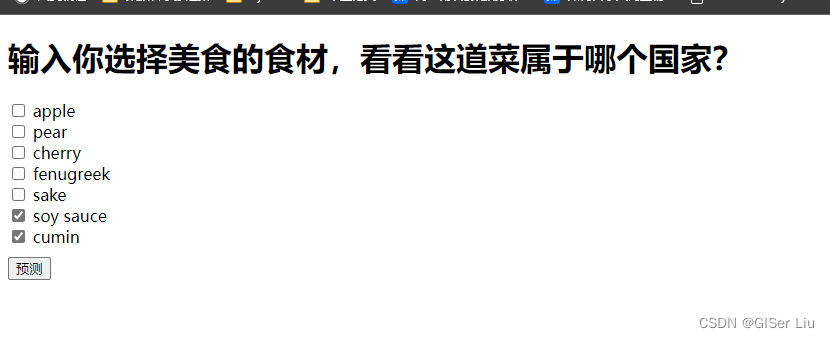
🏆🏆至此,我们的Web应用测试成功!你可以将其部署到你的服务器上或者硬件上😁。
六、总结
在本文中,我们基于之前的亚洲美食数据集构建了SVC模型,并介绍了模型可视化工具Netron与Onnx模型格式的使用。**与之前基于Python的pkl格式模型相比,Onnx格式的模型适用性更好,可以在多个平台使用。**且OnnxRuntime拥有各种语言的API,💻我们可以在各个环境中部署机器学习模型应用!

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
系列文章
机器学习系列0 机器学习思想_GISer Liu的博客-CSDN博客
机器学习系列1 机器学习历史_GISer Liu的博客-CSDN博客
机器学习系列2 机器学习的公平性_GISer Liu的博客-CSDN博客_公平机器学习
机器学习系列3 机器学习的流程_GISer Liu的博客-CSDN博客
机器学习系列4 使用Python创建Scikit-Learn回归模型_GISer Liu的博客-CSDN博客
机器学习系列5 利用Scikit-learn构建回归模型:准备和可视化数据(保姆级教程)_GISer Liu的博客-CSDN博客
机器学习系列6 使用Scikit-learn构建回归模型:简单线性回归、多项式回归与多元线性回归_GISer Liu的博客-CSDN博客_多元多项式回归机器学习系列7 基于Python的Scikit-learn库构建逻辑回归模型_GISer Liu的博客-CSDN博客机器学习系列8 基于Python构建Web应用以使用机器学习模型_GISer Liu的博客-CSDN博客
一文读懂机器学习分类全流程_GISer Liu的博客-CSDN博客
版权归原作者 GISer Liu 所有, 如有侵权,请联系我们删除。