
完整的项目代码在这里哦~
基于M3D-RPN实现单目3D检测 - 飞桨AI Studio
1. 项目说明
当前,3D 检测作为核心技术点,在机器人、增强现实等场景下应用广泛,发挥着至关重要的作用。传统依赖激光雷达的 3D 检测方法存在传感器昂贵难以部署,点云缺失纹理信息,分辨率低等诸多问题。
针对于此,开发单目 3D 检测模型,有效的利用图像相对于点云的种种优势,可以降低产业落地门槛,更广泛简单的部署到实际应用场景中。
单目的 3D 目标检测近几年一直是研究的热点,虽然往算法中添加先验知识,能够一定程度的提升准确率,但是也增加了获取标签的难度和算法设计的复杂性。
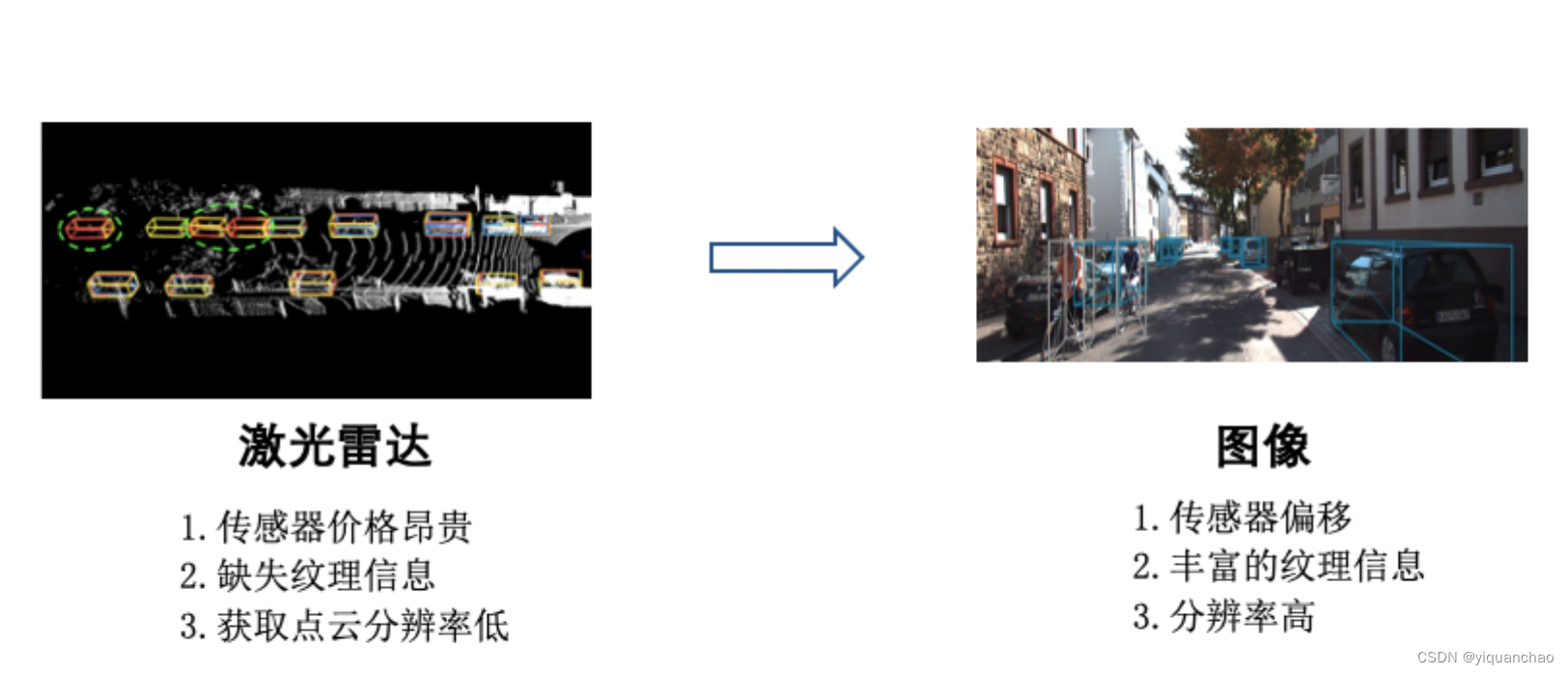
图 1 - 单目 3D 检测示例
欢迎扫码获取视频课程讲解,加入单目3D检测技术交流群,欢迎志同道合的同学:

方案难点:
- 深度信息缺失,由 2D 图像预测 3D 位置困难
- 相机传感器敏感,受环境影响(夜晚、雨天)等较大
- 图像层面,遮挡、截断等问题严重影响感知精度
2. 安装说明
2.1 环境要求
- Python >= 3.6
- paddlepaddle >= 2.0.2
- cuda >= 9
- boost 库
- 常见 Python 库
In [ ]
# 安装库
! pip install shapely
2.2 解压数据及代码
项目代码在
M3D-RPN-2.0.tar
文件中,数据集在
kitti.tar
文件中,解压到合适路径即可使用。
In [ ]
# 如果希望解压到其他目录
# 可选择其他路径(默认 /home/aistudio )
! tar xf ~/data/data141443/kitti.tar
! unzip -qo ~/data/data141443/M3D-RPN-2.0.zip
! rm -rf __MACOSX
2.3 安装依赖
In [ ]
# 删除已有软连接
! rm -rf ~/M3D-RPN-2.0/dataset/kitti_split1/training
! rm -rf ~/M3D-RPN-2.0/dataset/kitti_split1/validation
In [ ]
%cd ~/M3D-RPN-2.0/
! python dataset/kitti_split1/setup_split.py
! sh dataset/kitti_split1/devkit/cpp/build.sh
! cd lib/nms && make
3. 数据准备
3.1 数据介绍
KITTI 数据集是一个用于自动驾驶场景下的计算机视觉算法测评数据集,由德国卡尔斯鲁厄理工学院(KIT)和丰田工业大学芝加哥分校(TTIC)共同创立。包含场景有市区、乡村和高速公路。本案例使用公开的 KITTI 数据集用于训练测试,共有 14999 张图片,分为训练集 3712 张,验证集 3769 张,测试集 7518 张。示例图片如下图所示:

图 2 - KITTI 数据集示例图片
3.2 数据结构
整个数据集包含图片 images,标签 labels 和相机参数 calib,每个标签文件种包含以下字段:
type---物体类别
truncated---是否截断
occluded---是否遮挡
alpha---观测角
bbox---障碍物2D框
dimension---障碍物的3D大小
location---障碍物的3D底面中心点位置
rotation_y---障碍物的朝向角
最终数据集文件组织结构为:
kitti
└── training
├── calib
├── image_2
└── label_2
4. 模型选择
单目 3D 检测提供两种选择:基于 anchor 的方案和 anchor-free 的方案
基于anchor:从图像中估计出 3D 检测框,也无需预测中间的 3D 场景表示,可以直接利用一个区域提案网络,生成给点图像的 3D 锚点。不同于以往与类别无关的 2D 锚点,3D 锚点的形状通常与其语义标签有很强的相关性。
Anchor-free:将 2D 检测方法 CenterNet 扩展到基于图像的 3D 检测器,该框架将对象编码为单个点(对象的中心点)并使用关键点估计来找到它。此外,几个平行的头被用来估计物体的其他属性,包括深度、尺寸、位置和方向。
采用 anchor 的方法使用了 3D 障碍物的平均信息作为先验知识,3D 检测效果实际落地更好,所以我们采用经典的基于 anchor 的方法。在骨干网络部分,我们选择的是 DenseNet,这种网络建立的是前面所有层与后面层的密集连接,实现特征重用,有着省参数,扛过拟合等优点。我们提供了如下不同版本
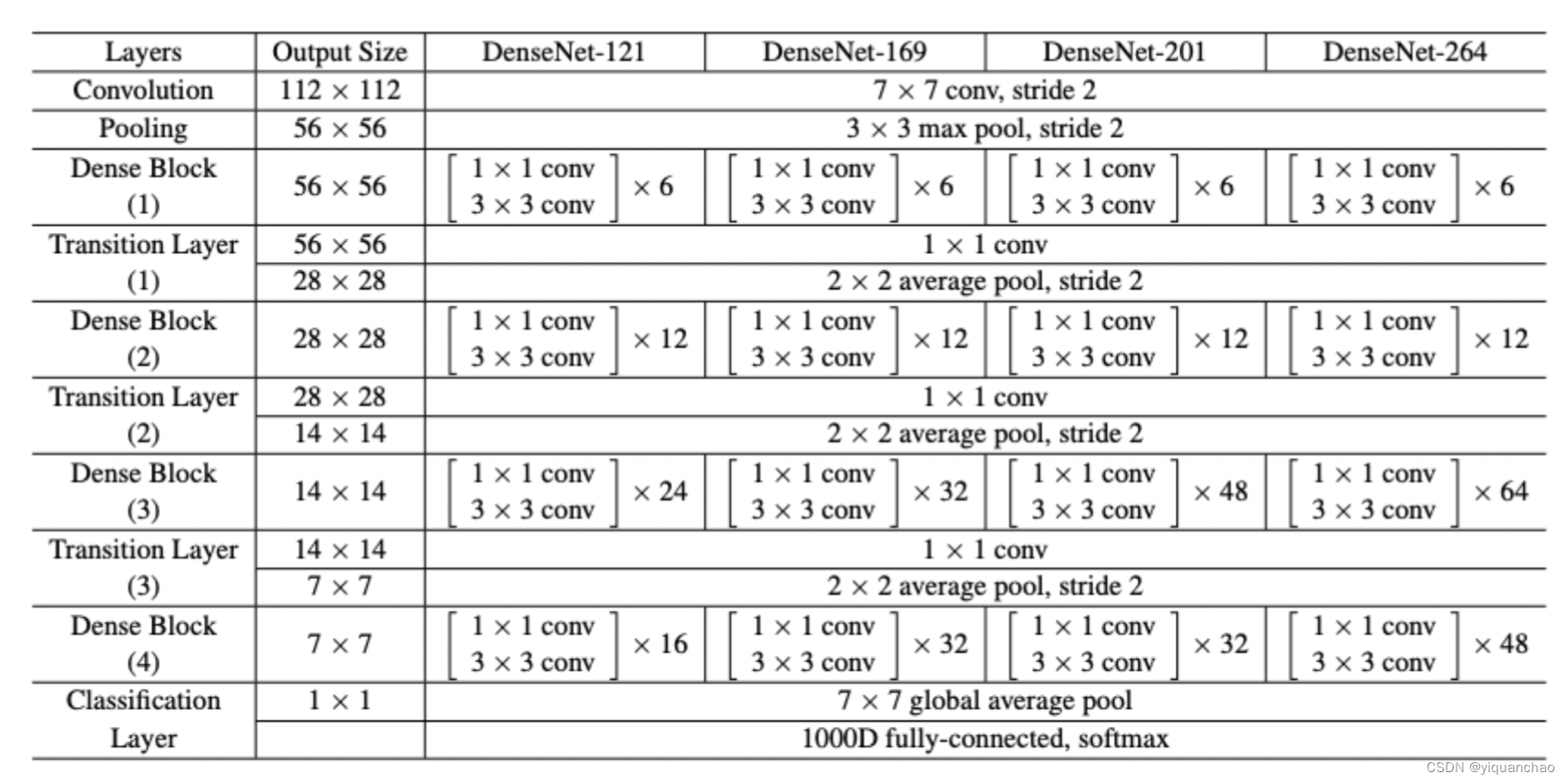
图 3 - 不同版本 DenseNet
根据单目 3D 检测实时性的要求,这里我们选择了 DenseNet121 作为我们的骨干网络。
5. 模型训练
训练被拆分成了热身配置和主要配置。详细信息可查看 config 中的配置。
首先,在启动模型训练之前,可以修改配置文件中相关内容, 主要包括数据集的地址以及类别数量。对应到配置文件中的位置如下所示:
基础配置
solver_type: 'sgd'
lr: 0.004
momentum: 0.9
weight_decay: 0.0005
max_iter: 50000
snapshot_iter: 10000
display: 20
do_test: True
数据集路径
dataset_test: 'kitti_split1'
datasets_train:
name: 'kitti_split1'
anno_fmt: 'kitti_det'
im_ext: '.png'
scale: 1
还有一些其他的配置诸如优化器配置、标签信息、检测器样本等,可以在
config
目录下查看。
- 启动热身配置训练 (不包含 depth-aware)
In [ ]
! python train.py --conf=kitti_3d_multi_warmup
6. 模型评估
评估默认配置:
output/kitti_3d_multi_warmup/conf.pkl
pkl配置
model: "model_3d_dilate"
solver_type: "sgd"
lr: 0.004
momentum: 0.9
max_iter: 50000
snapshot_iter: 10000
do_test: "True"
test_scale: 512
crop_size: [512, 1760]
mirror_prob: 0.5
distort_prob: -1
dataset_test: "kitti_split1"
datasets_train:
name: "kitti_split1"
anno_fmt: "kitti_det"
im_ext: ".png"
scale: 1
可视化
pkl
配置文件方法
In [ ]
import pickle
import numpy as np
PKL_PATH = 'output/kitti_3d_multi_warmup/conf.pkl'
f = open(PKL_PATH,'rb')
data = pickle.load(f)
print(data)
In [1]
%cd ~/M3D-RPN-2.0
! python test.py \
--conf_path output/kitti_3d_multi_warmup/conf.pkl \
--weights_path output/kitti_3d_multi_warmup/weights/iter50000.0_params.pdparams
预模型
output/kitti_3d_multi_warmup/weights/iter50000.0_params.pdparams
效果
Car
EasyModHard2D detection87.2781.7466.603D BEV24.9318.5816.693D detection19.1015.6913.15
Ped
EasyModHard2D detection72.4758.2850.073D BEV4.124.553.443D detection3.773.453.07
Cyclist
EasyModHard2D detection63.9745.9739.733D BEV11.7210.1610.163D detection10.5610.0710.07
7. 模型优化
本小节侧重展示在模型迭代过程中优化精度的思路
数据过滤:根据 bbox 可见程度、大小来过滤每个 bbox 标签,根据有无保留 bbox 过滤每张图片,整体平衡前后背景,保证训练的稳定性。
数据增强:主要使用 RandomFlip、Resize 两种数据增强策略
Anchor定义:模型输出
2D anchor定义3D anchor定义

后处理优化: 根据将 3D 相关信息组成 3D 框,投影到图像上得到投影的八点框,取八点最小外接包围框与 2D 预测结果算 IOU,通过不断的调整旋转角 ry 或深度 z,来使得 IOU 最大。此算法利用了 2D 检测的结果要比 3D 检测的结果准确的先验知识,用 2D 框来纠正预测的 3D 属性,来达到优化 3D 定位精度的目的。整体框架如下图所示:

经过调整后,在 car 类前后效果对比如下:
3D detectionEasyModHard优化前16.5713.8212.30优化后19.0915.7013.15增量+2.52+1.88+0.85
8. 模型推理
推理过程包括两个步骤:1)导出推理模型 2)执行推理代码
导出推理模型
PaddlePaddle 框架保存的权重文件分为两种:支持前向推理和反向梯度的训练模型和只支持前向推理的推理模型。二者的区别是推理模型针对推理速度和显存做了优化,裁剪了一些只在训练过程中才需要的 tensor,降低显存占用,并进行了一些类似层融合,kernel 选择的速度优化。因此可执行如下命令导出推理模型。
In [2]
! python export_model.py \
--conf_path output/kitti_3d_multi_warmup/conf.pkl \
--weights_path output/kitti_3d_multi_warmup/weights/iter50000.0_params.pdparams
生成的推理模型位于
inference
目录,里面包含三个文件,分别为
- inference.pdmodel
- inference.pdiparams
- inference.pdiparams.info。
其中 inference.pdmodel 用来存储推理模型的结构, inference.pdiparams 和 inference.pdiparams.info 用来存储推理模型相关的参数信息。
结果保存在
inference_result
目录下。
In [4]
! python infer.py \
--conf_path output/kitti_3d_multi_warmup/conf.pkl
9. 模型可视化
In [ ]
! python vis.py
10. 模型部署
使用飞桨原生推理库 paddle-inference,用于服务端模型部署
总体上分为三步:
- 创建 PaddlePredictor,设置所导出的模型路径
- 创建输入用的 PaddleTensor,传入到 PaddlePredictor 中
- 获取输出的 PaddleTensor ,将结果取出
#include "paddle_inference_api.h"
// 创建一个 config,并修改相关设置
paddle::NativeConfig config;
config.model_dir = "xxx";
config.use_gpu = false;
// 创建一个原生的 PaddlePredictor
auto predictor =
paddle::CreatePaddlePredictor<paddle::NativeConfig>(config);
// 创建输入 tensor
int64_t data[4] = {1, 2, 3, 4};
paddle::PaddleTensor tensor;
tensor.shape = std::vector<int>({4, 1});
tensor.data.Reset(data, sizeof(data));
tensor.dtype = paddle::PaddleDType::INT64;
// 创建输出 tensor,输出 tensor 的内存可以复用
std::vector<paddle::PaddleTensor> outputs;
// 执行预测
CHECK(predictor->Run(slots, &outputs));
// 获取 outputs ...
更多内容详见 > C++ 预测 API介绍
版权归原作者 一拳超超 所有, 如有侵权,请联系我们删除。