
在计算机视觉中,生成模型是一类能够生成合成图像的模型。例如,一个被训练来生成人脸的模型,每次都会生成一张从未被该模型或任何人看到过的人脸。生成模型最著名的例子是GAN(生成对抗网络)。它有生成器和鉴别器,它们相互对抗,然后生成图像。由于模型本身具有对抗性,因此很难进行训练。这使得很难达到一个最优的平衡。利用扩散模型可以解决这个问题。(下图为常见的生成模型的基本架构)
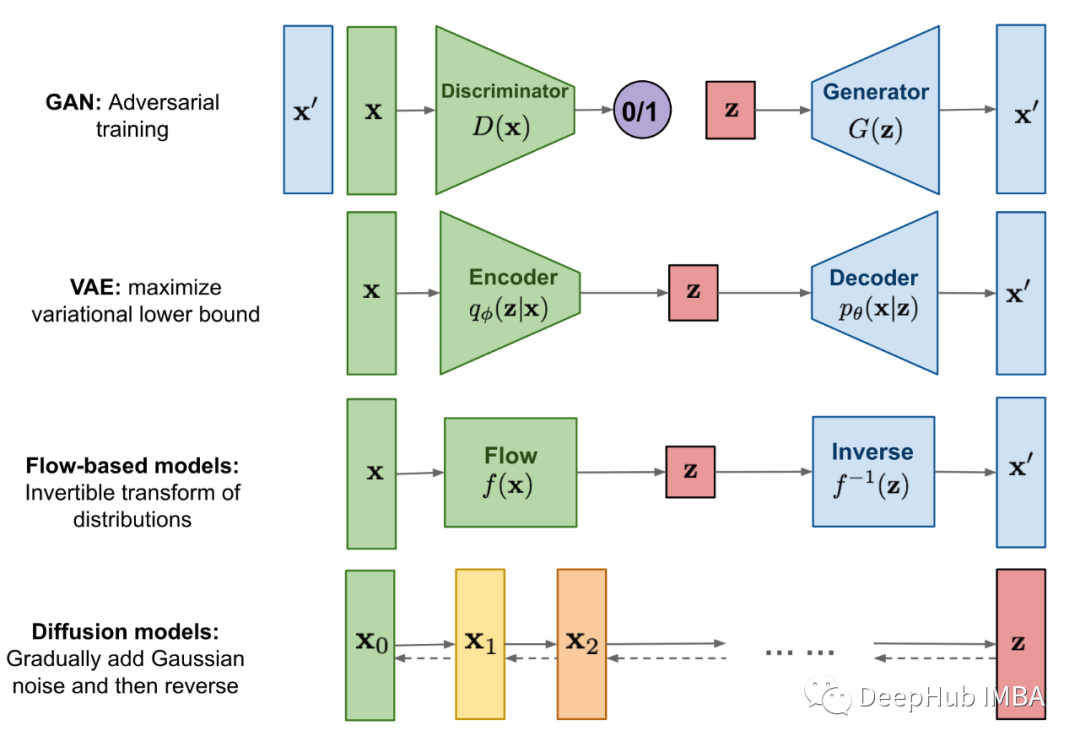
扩散模型也是生成模型,扩散模型背后的直觉来源于物理学。在物理学中气体分子从高浓度区域扩散到低浓度区域,这与由于噪声的干扰而导致的信息丢失是相似的。所以通过引入噪声,然后尝试通过去噪来生成图像。在一段时间内通过多次迭代,模型每次在给定一些噪声输入的情况下学习生成新图像。
扩散模型是如何工作的
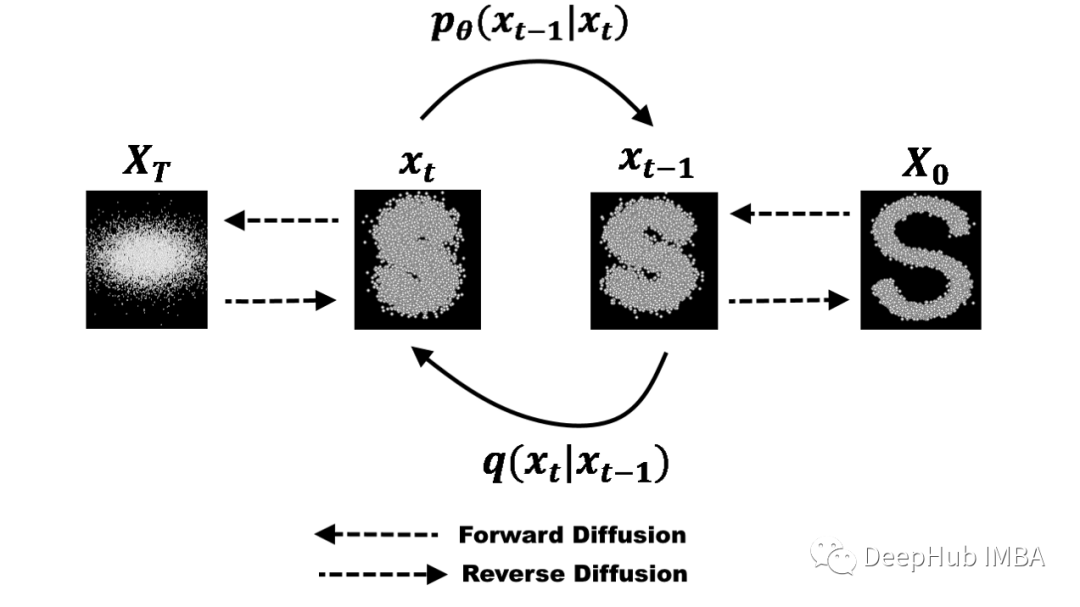
扩散模型的工作原理是学习由于噪声引起的信息衰减,然后使用学习到的模式来生成图像。该概念也适用于潜在变量,因为它试图学习噪声分布而不是数据分布。噪声分布使用马尔可夫链的概念建模。这使它成为一个概率模型。
正向过程


正向过程遵循马尔可夫链的概念。其中状态t表示马尔可夫链中的状态。状态的变化遵循概率分布而概率是潜变量的函数。该模型的目标是学习在扩散模型中控制扩散的潜在变量。
给定数据样本x0,时间步长t和真实噪声Ɛ,可以定义如下的训练损失函数。这是在训练阶段实现的,并最终在反向处理步骤中使用去噪图像。

去噪样本
去噪操作与正向过程相反。我们使用学习到的潜在变量来计算状态转换的概率,从而实现马尔可夫链。去噪也是分阶段进行的,每个阶段都会产生一个噪声稍小的样本,直到我们到达原始样本的第 0 阶段。
马尔可夫链的条件概率是使用神经网络和潜在变量作为输入来学习的。这为我们提供了可以从图像中去除的噪声分布。这与实现马尔可夫链时的正向过程完全相反。并且使用上面提到的损失函数进行训练。去噪步骤可以表示如下。
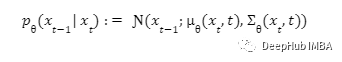
将扩散模型应用于实际问题。
扩散模型已经被用于图像生成。最好的例子是DALL- E模型,它使用扩散模型来使用文本标题生成图像。也被称为文本到图像的生成。
虽然DALL-E是一个复杂的系统,但它使用了两个主要组件。CLIP(contrast Language-image pre-training)模型和先验模型。
可以通过将图像和标题传递给图像来训练 CLIP。然后在推理过程中它会为图像生成标题。这是ViT模型的一个示例, CLIP 存储图像的视觉特征和语言特征,有了这些数据我们就可以说图像被翻译成语言。扩散模型的反向过程用于 DALL-E 中的推理:给出一个文本标题将返回一个图像。但CLIP不是一个生成模型,因为我们可以训练它产生图像,但它只能返回它不知道的图像。而DALL-E可以为文本提示生成图像,如“爱因斯坦打扮成贝多芬”。
而先验模型是一种能够从噪声中生成图像的扩散模型。然而在扩散模型中,我们无法控制模型产生的图像类型。对于“爱因斯坦打扮成贝多芬”这种文本标题,需要爱因斯坦和贝多芬的图像。因此使用CLIP生成图像,图像的特征被增强为噪声样本,然后传递到先验模型。先验模型对图像进行去噪处理,最终得到的图像应该与输入的文本信息接近。
让我们使用DALL-E mini来尝试一下,以下是结果(因为DALL-E 是要钱的我们这里使用免费的DALL-E mini)。
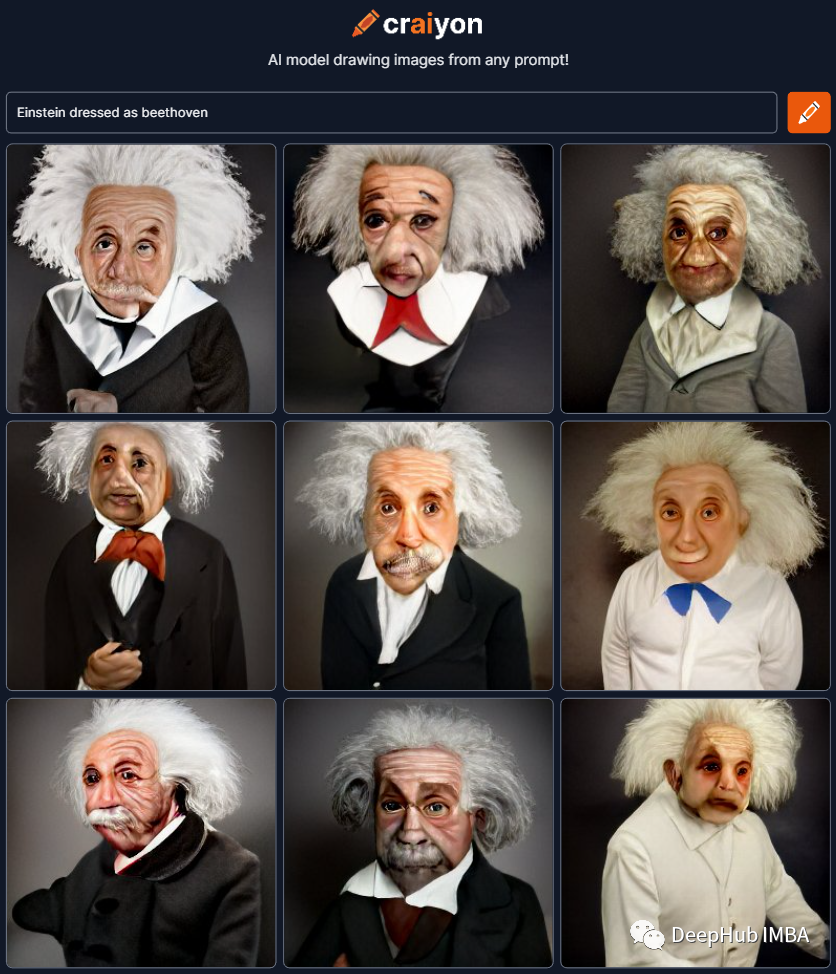
虽然这不是最好的图像,但我认为它能说明本文上面观点。
总结
扩散模型是生成模型,在生成新图像方面优于GANs和VAEs。它是有效的并且易于实施,可以产生卓越的质量的图像。使用生成模型并不只是为了好玩,我们可以通过它生成合成数据。特斯拉正在使用合成数据创建真实世界的模拟来训练他们的自动驾驶汽车。就像他们人工智能负责人自己说的那样,即使有特斯拉车队中大量的样本,也很难找到描述特殊场景的图像,所以生成模型提供了这种可能。
另外还可以将这些模型与3D重建技术相结合,生成AR/VR所需的3D图像或环境,或者从噪音中产生新的音频。它应该在本质上遵循相同的原则,尽管训练数据的性质可能会有所不同。
引用
- Ho, J., Jain, A. and Abbeel, P., 2020. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, pp.6840–6851.
- Sohl-Dickstein, Jascha, et al. “Deep unsupervised learning using nonequilibrium thermodynamics.” International Conference on Machine Learning. PMLR, 2015.
- Luo, Calvin. “Understanding Diffusion Models: A Unified Perspective.” arXiv preprint arXiv:2208.11970 (2022).
- Dhariwal, Prafulla, and Alexander Nichol. “Diffusion models beat gans on image synthesis.” Advances in Neural Information Processing Systems 34 (2021): 8780–8794.
作者:Sharad Nataraj