
深度学习分割任务——Unet++分割网络代码详细解读(文末附带作者所用code)
图像分割:分割任务就是在原始图像中逐像素的找到你需要的家伙。
分成语义分割和实例分割
- 语义分割:语义分割就是把每个像素都打上标签(这个像素点是人,树,背景等)(语义分割只区分类别,不区分类别中具体单位)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

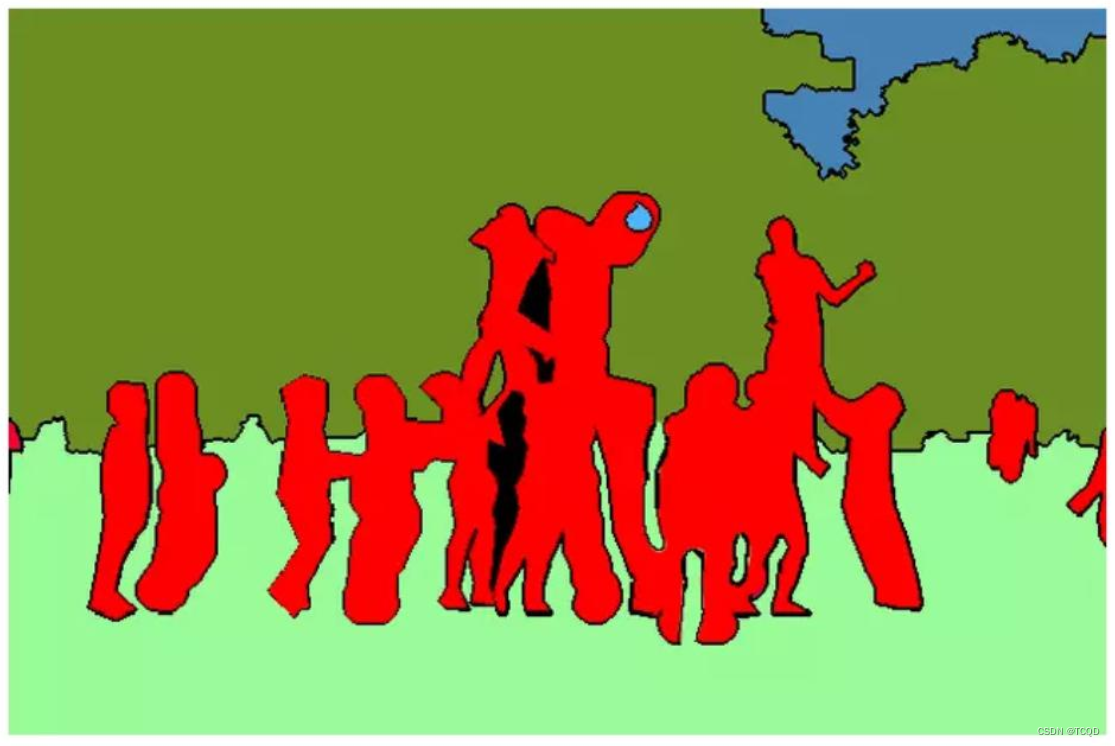
- 实例分割:实例分割不光要区别类别,还要区分类别中每一个个体[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传


损失函数
给定了一张图像,逐像素点判断,对每一个像素点都得到一个二分类结果,做二分类任务,前景想要的是人就是标签。
逐像素做二分类或者多分类,逐像素的交叉熵
交叉熵损伤函数:https://www.zhihu.com/tardis/zm/art/35709485?source_id=1003
根据前景和背景的比例,会加入一个权重项:pos_wight
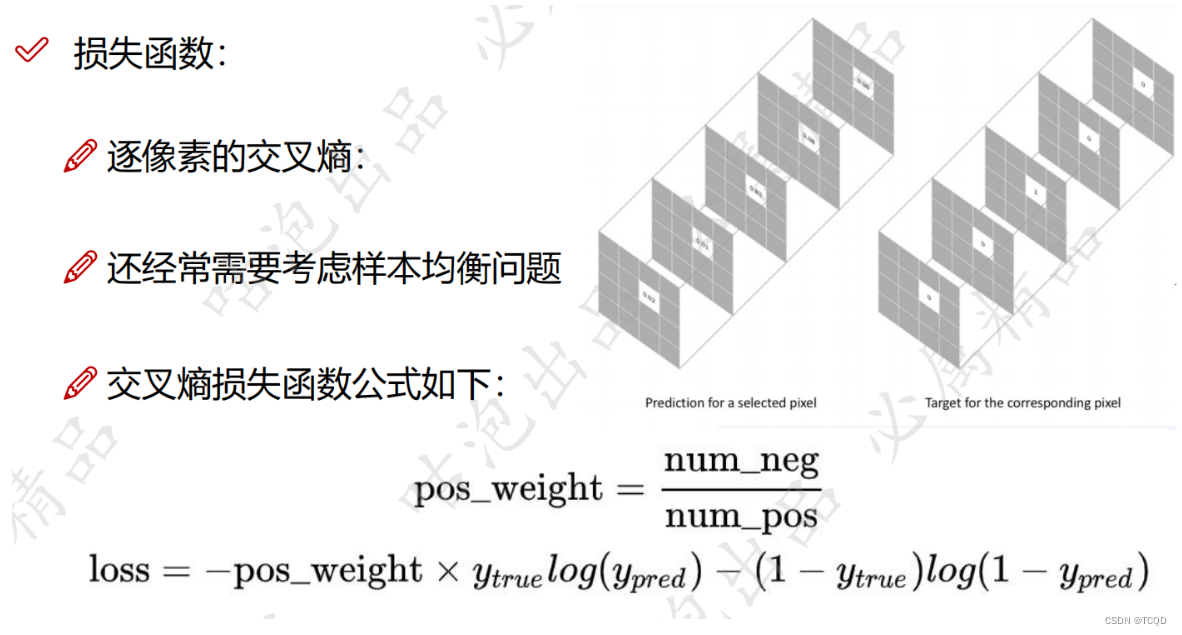
像素点也有难易之分,大前景和大背景都好区分,但是前景和背景相交的边缘点会存在问题。让比较难做的样本点,像素点在损失函数中显得重要一些。
引入gama值之后,使得像素点的难以区分更容易。权重值越高越重要越难区分

IOU计算(交并比)
评估的值IOU****:https://blog.csdn.net/lingzhou33/article/details/87901365



MIOU就是计算所有类别的平均值,一般当作分割任务评估指标
Unet网络简介
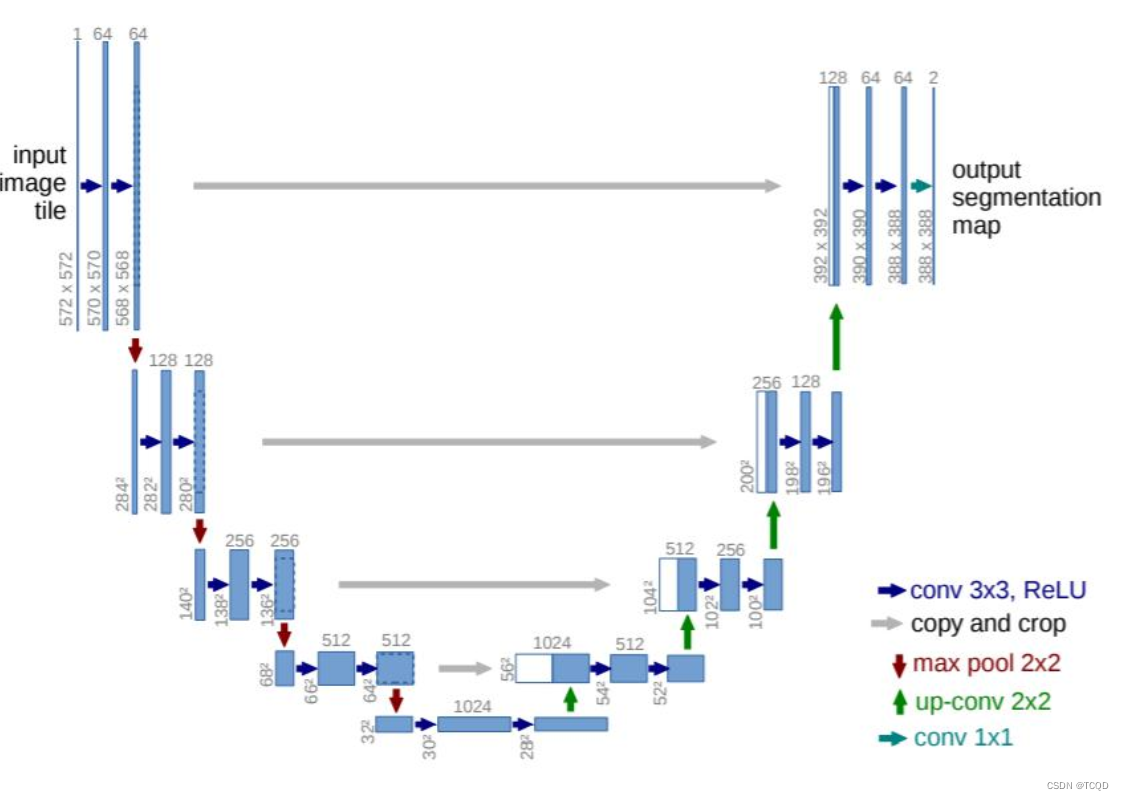
Unet网络,用的不是特别多,16年特别火的一件事,在小目标领域做分割做的相当好,最近的升级版,现在还在用,深度学习往往是越简单的网络用起来效果越好。
Unet最早发表论文是在医学领域。本质的思想解决小目标的问题,物体检测和实例分割很复杂。网络结构越简单,越适合小目标,做改性,做升级能玩的就比较多了。
编码解码。思想和谍战片是一样的,现在用的也很广,在小目标用的很广,95%都是用Unet去做的,简单的东西有时候也是高效的。
有数据之后—》做编码(拿一堆卷积层去提特征)特征提取层,输入到网络中—》走几个卷积层,越来越扁,说特征图的个数越来越多了。越来越矮,特征图都越来越小(H,W)。左侧为编码,做成一个特征,右侧为解码,进行上采样的过程,本质就是线性插值。
Unet网络计算过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传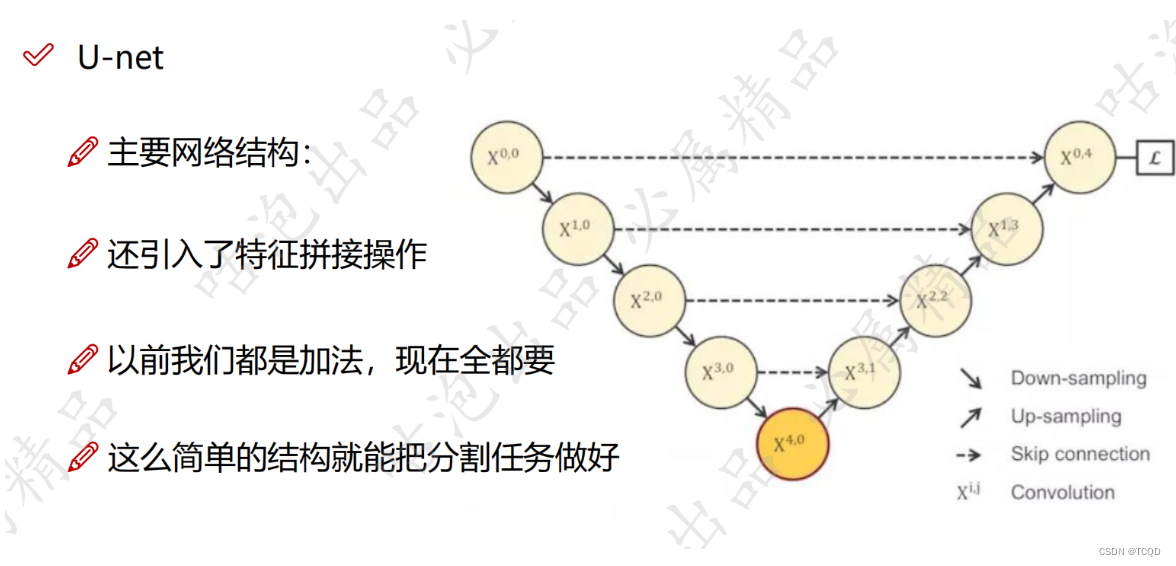
深度学习强调特征融合。以前特征最常用的是加法,现在做拼接更多。以前Unet结构做加法比较多,但是太直接了,现在先拼接再下采样得到相同的大小,然后横向进行拼接。
缺点:最开始的特征与最后面的特征代沟太大了。
于是有了Unet++的诞生
Unet++介绍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传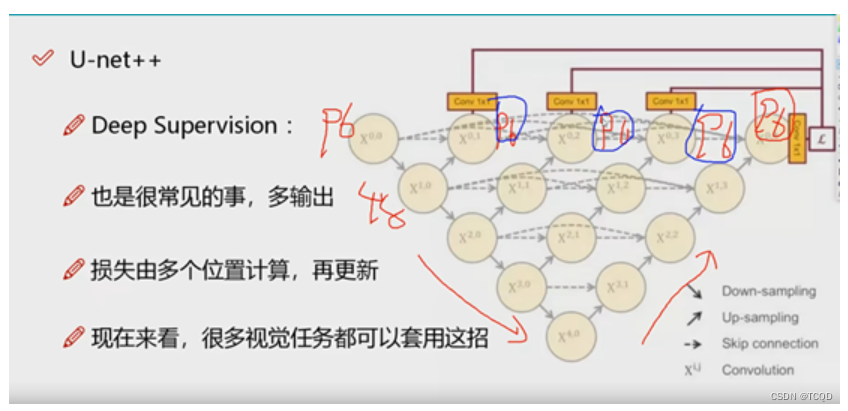
把前面有的特征,能拼的就全部一块去拼,还是特征融合,做拼接,构建网络结构,使其更丰富,特征越多越好。
Unet++继承了Unet的结构,同时又借鉴了DenseNet的稠密连接方式(图1中各种分支)。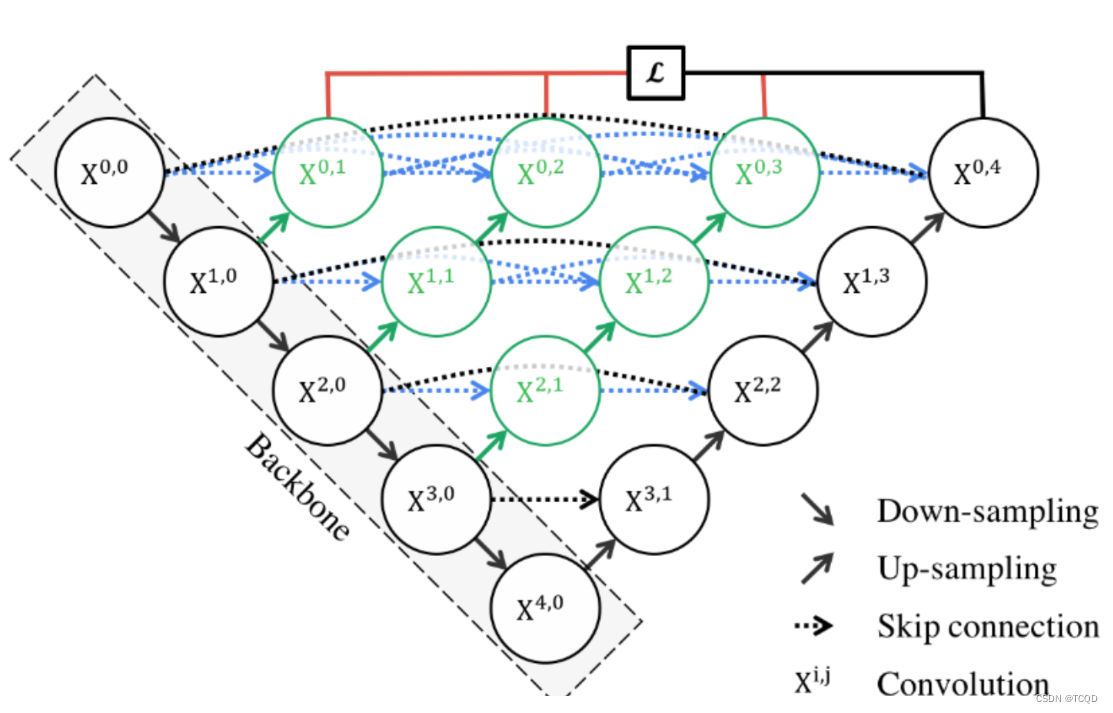
先看下采样过程,和Unet过程没有什么区别。
Unet++采用了稠密连接的方式,比如X(0,1)是通过X(0,0)和X(1,0)拼接起来的,拼接的过程如下:
假设输入为[8,3,96,96],分别为[batch,C,H,W],经过32个(3,3)卷积核提取特征(stirde=1,padding=1),得到X(0,0)[8, 32, 96, 96]。再经过下采样后进行卷积得到X(1,0)[8, 64, 48, 48]。然后通过对X(1,0)上采样后先进行拼接,再进行卷积得到X(0,1)[8, 32, 96, 96]。
结合后文arch.py代码进行理解。

依次类推,可以得到各个特征提取层。
Deep Supervision
Unet++最大的特点是更容易剪枝,如图,如果第三层的Unet++网络已经训练的很好了,就可以直接把最后一层去掉,得到更加轻量化的网络。
第二个特点就是,第一横排的输出都可以计算损失。打个比方:如果你要考清华,那么你不可能最后一次考试突然就680上清华了,肯定是每一次模拟考试的成绩都得好才行。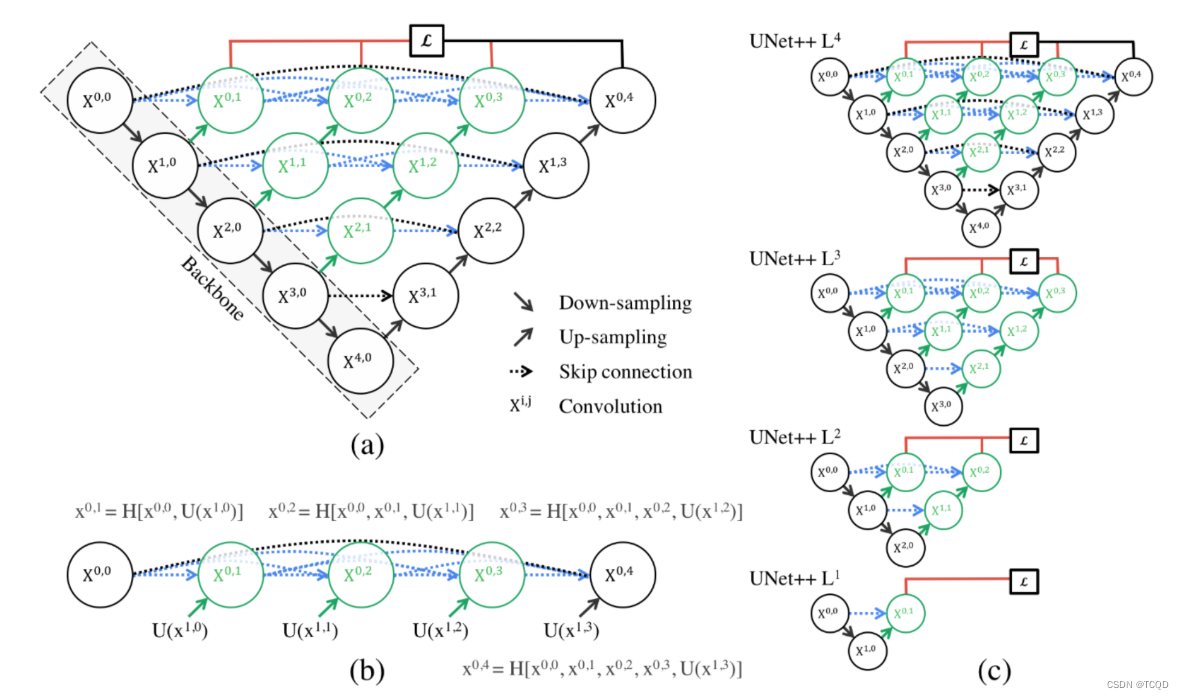
模型实现(文末有代码和数据集)
主要解读模型中的以下5个函数,大家训练的时候用train-20230718.py函数,其中有一个包由于更新,位置发生了变化,因此不采用原有的train函数
准备数据集:kaggle细胞数据集(dsb2018_96)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
mask:

preprocess_dsb2018.py详细解读如下
由于标签是一个一个标的,首先要做一个预处理操作,将分开的图拼接到一起,
import os
from glob import glob
import cv2
import numpy as np
from tqdm import tqdm
# glob库主要用于获取匹配指定模式的文件路径列表,# tqdm库主要用于在循环中显示进度条,提供可视化的进度反馈。# 这两个库在数据处理、文件操作和任务执行过程中非常有用。# 第一步 预处理操作,将分开的图拼接到一起defmain():
img_size =96# 获取输入的文件路径,从指定目录inputs/stage1_train/下的文件
paths = glob('inputs/stage1_train/*')# 创建了两个目录,# 分别是inputs/dsb2018_<img_size>/images和inputs/dsb2018_<img_size>/masks/0,# 如果目录已存在则不进行任何操作
os.makedirs('inputs/dsb2018_%d/images'% img_size, exist_ok=True)
os.makedirs('inputs/dsb2018_%d/masks/0'% img_size, exist_ok=True)for i in tqdm(range(len(paths))):
path = paths[i]# b. 使用cv2.imread()函数读取图像文件,文件路径为path/images/<basename>.png,# 其中<basename>是当前路径的基本文件名。
img = cv2.imread(os.path.join(path,'images',
os.path.basename(path)+'.png'))# 创建一个与图像大小相同的全零矩阵mask,用于存储图像。
mask = np.zeros((img.shape[0], img.shape[1]))# 使用glob模块获取当前路径下所有图像文件的路径for mask_path in glob(os.path.join(path,'masks','*')):# 将读取的图像转换为灰度图像,并与阈值127进行比较生成二值图像
mask_ = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)>127# 将二值图像中的值为True(大于阈值)的像素位置在mask矩阵中对应位置设置为1。
mask[mask_]=1iflen(img.shape)==2:# 如果图像是灰度图(通道数为2),则使用np.tile()函数将其复制为3通道图像。# 如果图像有4个通道,则仅保留前3个通道。
img = np.tile(img[...,None],(1,1,3))if img.shape[2]==4:
img = img[...,:3]
img = cv2.resize(img,(img_size, img_size))
mask = cv2.resize(mask,(img_size, img_size))
cv2.imwrite(os.path.join('inputs/dsb2018_%d/images'% img_size,
os.path.basename(path)+'.png'), img)
cv2.imwrite(os.path.join('inputs/dsb2018_%d/masks/0'% img_size,
os.path.basename(path)+'.png'),(mask *255).astype('uint8'))if __name__ =='__main__':
main()
dataset.py详细解读
import os
import cv2
import numpy as np
import torch
import torch.utils.data
classDataset(torch.utils.data.Dataset):def__init__(self, img_ids, img_dir, mask_dir, img_ext, mask_ext, num_classes, transform=None):"""
Args:
img_ids (list): Image ids.
img_dir: Image file directory.
mask_dir: Mask file directory.
img_ext (str): Image file extension.
mask_ext (str): Mask file extension.
num_classes (int): Number of classes.
transform (Compose, optional): Compose transforms of albumentations. Defaults to None.
Note:
Make sure to put the files as the following structure:
<dataset name>
├── images
| ├── 0a7e06.jpg
│ ├── 0aab0a.jpg
│ ├── 0b1761.jpg
│ ├── ...
|
└── masks
├── 0
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
|
├── 1
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
...
"""
self.img_ids = img_ids # 用于记录数据集中的图像id
self.img_dir = img_dir # 用于存储图像文件的目录路径
self.mask_dir = mask_dir # 用于存储标签文件的目录路径
self.img_ext = img_ext # 用于指定图像文件的扩展名
self.mask_ext = mask_ext # 用于指定标签文件的扩展名
self.num_classes = num_classes # 用于记录数据集中的类别数量
self.transform = transform # 用于对图像和掩膜进行增强处理。默认为None,表示不进行数据增强。def__len__(self):returnlen(self.img_ids)def__getitem__(self, idx):# 构建训练的batch,这是一张图片的处理
img_id = self.img_ids[idx]# 第一步,把数据读进来
img = cv2.imread(os.path.join(self.img_dir, img_id + self.img_ext))# 第二步,读标签
mask =[]for i inrange(self.num_classes):# 使用OpenCV的cv2.imread()函数读取mask图像文件,以灰度图像的形式加载。# mask图像文件路径由目录、类别索引、图像id和扩展名拼接而成。# 读取的灰度图像通过[..., None]转换为形状为(H, W, 1)的三维数组,并将其添加到mask列表中。
mask.append(cv2.imread(os.path.join(self.mask_dir,str(i),
img_id + self.mask_ext), cv2.IMREAD_GRAYSCALE)[...,None])
mask = np.dstack(mask)# 使用NumPy的np.dstack()函数将mask列表中的多个mask图像沿深度方向堆叠,# 生成形状为(H, W, num_classes)的三维数组。# 第三步数据增强if self.transform isnotNone:
augmented = self.transform(image=img, mask=mask)# 这个包比较方便,能把mask也一并做掉
img = augmented['image']# 参考https://github.com/albumentations-team/albumentations
mask = augmented['mask']# 第四步归一化
img = img.astype('float32')/255# 使用NumPy的transpose()函数将图像的维度顺序从(H, W, C)转换为(C, H, W)。
img = img.transpose(2,0,1)
mask = mask.astype('float32')/255
mask = mask.transpose(2,0,1)return img, mask,{'img_id': img_id}
archs.py解读
因为本文主要是针对Unet++进行解读,关于不多做赘述,可以主要看到class NestedUNet(nn.Module)中的forward函数
最重要的也就是forward函数,通过执行函数再去看定义 一目了然,最重要的是该forward函数对应的就是Unet++这个表,最好的办法就是在forward的函数后打一个断点,然后一个一个去观察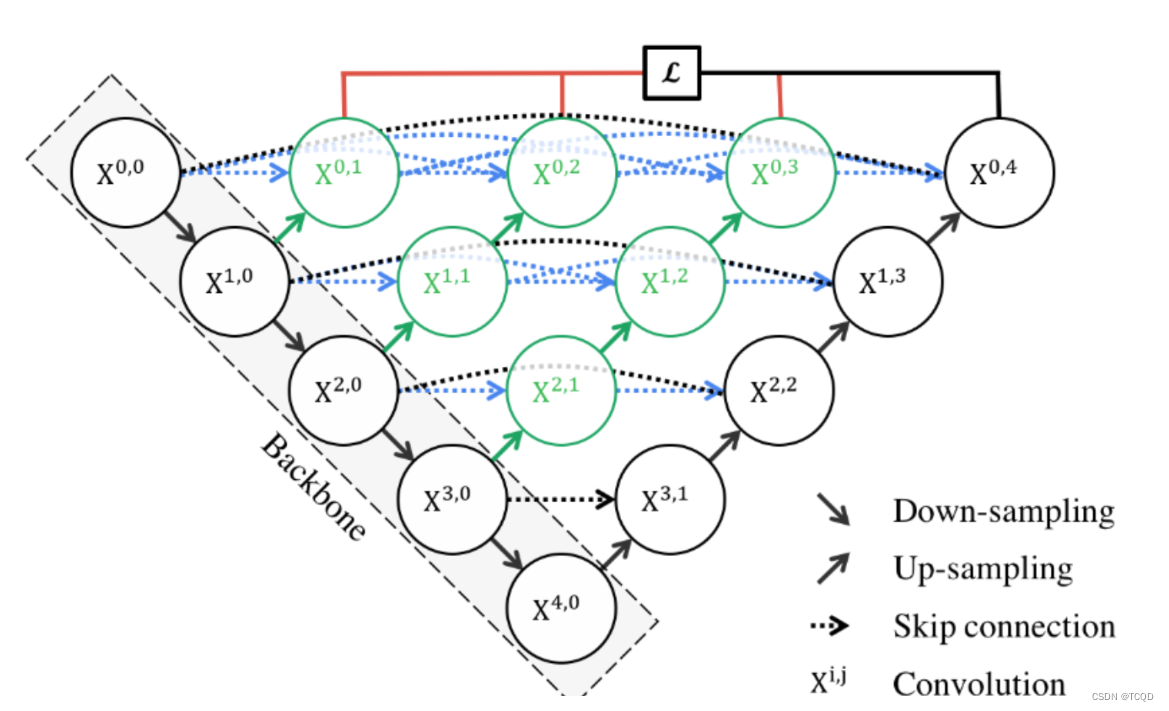
import torch
from torch import nn
__all__ =['UNet','NestedUNet']# 基本计算单元classVGGBlock(nn.Module):def__init__(self, in_channels, middle_channels, out_channels):super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels,3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels,3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)defforward(self, x):# VGGBlock实际上就是相当于做了两次卷积
out = self.conv1(x)
out = self.bn1(out)# 归一化
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)return out
classUNet(nn.Module):def__init__(self, num_classes, input_channels=3,**kwargs):super().__init__()
nb_filter =[32,64,128,256,512]
self.pool = nn.MaxPool2d(2,2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#scale_factor:放大的倍数 插值
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)defforward(self,input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)],1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)],1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)],1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)],1))
output = self.final(x0_4)return output
classNestedUNet(nn.Module):def__init__(self, num_classes, input_channels=3, deep_supervision=False,**kwargs):super().__init__()# 定义了一个列表,包含NestedUNet中不同层的通道数
nb_filter =[32,64,128,256,512]# 深度监督:是否需要都计算损失函数
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2,2)# 最大池化,池化核大小为2x2,步幅为2# 创建一个上采样层实例,尺度因子为2,采用双线性插值的方式进行上采样,边缘对齐方式为True
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)defforward(self,input):# 入口函数打个断点,看数据的维度很重要print('input:',input.shape)
x0_0 = self.conv0_0(input)# 第一次卷积print('x0_0:',x0_0.shape)# 升维 input: torch.Size([8, 32, 96, 96])
x1_0 = self.conv1_0(self.pool(x0_0))print('x1_0:', x1_0.shape)# 升维,降数据量,x1_0: torch.Size([8, 32, 96, 96])
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)],1))# cat 拼接,再经历一次卷积,input是96=32+64,output=32print('x0_1:', x0_1.shape)# x0_1: torch.Size([8, 32, 96, 96])# 梳理清楚一个关键点即可,后面依次类推,可以打印结果自己手动推一下
x2_0 = self.conv2_0(self.pool(x1_0))print('x2_0:', x2_0.shape)
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)],1))print('x1_1:',x1_1.shape)
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)],1))print('x0_2:',x0_2.shape)
x3_0 = self.conv3_0(self.pool(x2_0))print('x3_0:',x3_0.shape)
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)],1))print('x2_1:',x2_1.shape)
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)],1))print('x1_2:',x1_2.shape)
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)],1))print('x0_3:',x0_3.shape)
x4_0 = self.conv4_0(self.pool(x3_0))print('x4_0:',x4_0.shape)
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)],1))print('x3_1:',x3_1.shape)
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)],1))print('x2_2:',x2_2.shape)
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)],1))print('x1_3:',x1_3.shape)
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)],1))print('x0_4:',x0_4.shape)if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)return[output1, output2, output3, output4]else:# 输出一个结果,结果是0~1之间
output = self.final(x0_4)return output
train.py解读
train函数分为四个部分
第一部分主要是在parameters输入给定参数的,
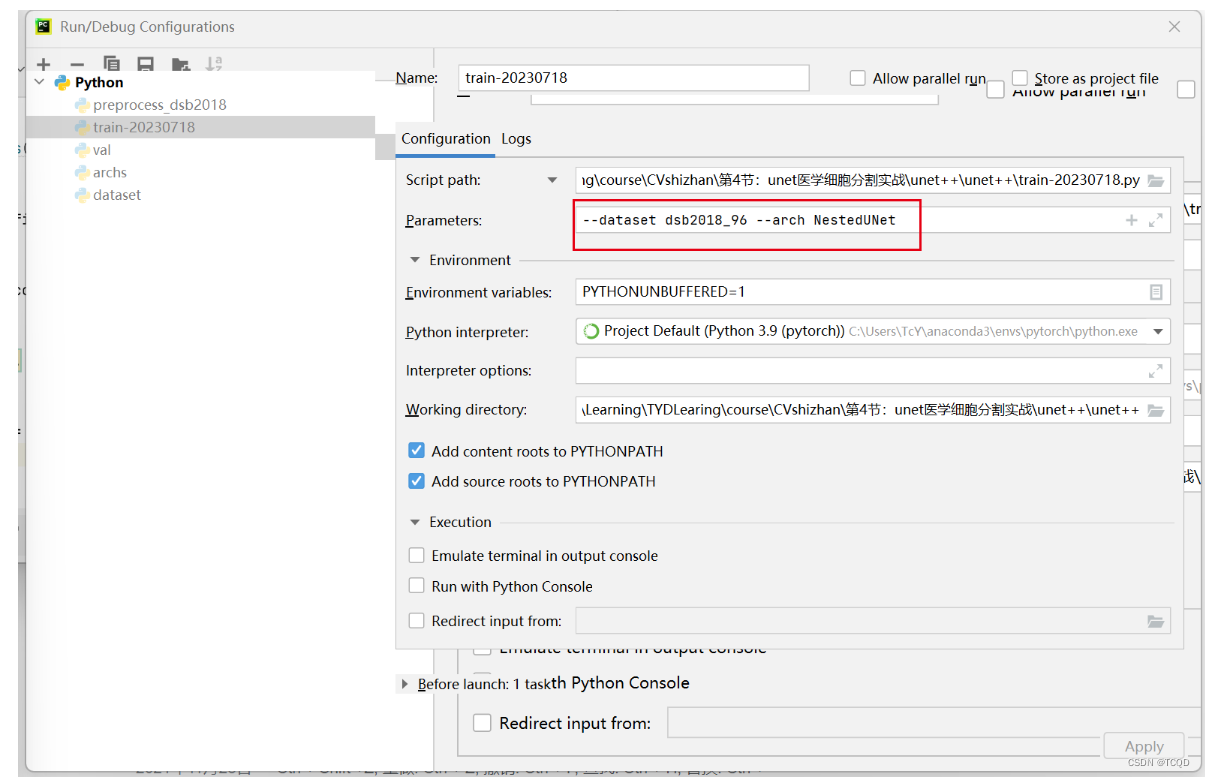
第二部分函数是训练函数
第三部分是验证函数
最后一部分是执行函数
import argparse
import os
from collections import OrderedDict
from glob import glob
import pandas as pd
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
import yaml
import albumentations as albu
from albumentations.augmentations import transforms
from albumentations.core.composition import Compose, OneOf
from sklearn.model_selection import train_test_split
from torch.optim import lr_scheduler
from tqdm import tqdm
import archs
import losses
from dataset import Dataset
from metrics import iou_score
from utils import AverageMeter, str2bool
ARCH_NAMES = archs.__all__
LOSS_NAMES = losses.__all__
LOSS_NAMES.append('BCEWithLogitsLoss')"""
指定参数:
--dataset dsb2018_96
--arch NestedUNet
"""# 解析命令行参数并返回配置信息。defparse_args():
parser = argparse.ArgumentParser()# 指定网络的名字-unet++
parser.add_argument('--name', default=None,help='model name: (default: arch+timestamp)')# 迭代多少轮
parser.add_argument('--epochs', default=100,type=int, metavar='N',help='number of total epochs to run')# batch_size
parser.add_argument('-b','--batch_size', default=8,type=int,
metavar='N',help='mini-batch size (default: 16)')# model
parser.add_argument('--arch','-a', metavar='ARCH', default='NestedUNet',
choices=ARCH_NAMES,help='model architecture: '+' | '.join(ARCH_NAMES)+' (default: NestedUNet)')
parser.add_argument('--deep_supervision', default=False,type=str2bool)
parser.add_argument('--input_channels', default=3,type=int,help='input channels')
parser.add_argument('--num_classes', default=1,type=int,help='number of classes')
parser.add_argument('--input_w', default=96,type=int,help='image width')
parser.add_argument('--input_h', default=96,type=int,help='image height')# loss
parser.add_argument('--loss', default='BCEDiceLoss',
choices=LOSS_NAMES,help='loss: '+' | '.join(LOSS_NAMES)+' (default: BCEDiceLoss)')# dataset
parser.add_argument('--dataset', default='dsb2018_96',help='dataset name')
parser.add_argument('--img_ext', default='.png',help='image file extension')
parser.add_argument('--mask_ext', default='.png',help='mask file extension')# optimizer
parser.add_argument('--optimizer', default='SGD',
choices=['Adam','SGD'],help='loss: '+' | '.join(['Adam','SGD'])+' (default: Adam)')
parser.add_argument('--lr','--learning_rate', default=1e-3,type=float,
metavar='LR',help='initial learning rate')
parser.add_argument('--momentum', default=0.9,type=float,help='momentum')
parser.add_argument('--weight_decay', default=1e-4,type=float,help='weight decay')
parser.add_argument('--nesterov', default=False,type=str2bool,help='nesterov')# scheduler
parser.add_argument('--scheduler', default='CosineAnnealingLR',
choices=['CosineAnnealingLR','ReduceLROnPlateau','MultiStepLR','ConstantLR'])
parser.add_argument('--min_lr', default=1e-5,type=float,help='minimum learning rate')
parser.add_argument('--factor', default=0.1,type=float)
parser.add_argument('--patience', default=2,type=int)
parser.add_argument('--milestones', default='1,2',type=str)
parser.add_argument('--gamma', default=2/3,type=float)
parser.add_argument('--early_stopping', default=-1,type=int,
metavar='N',help='early stopping (default: -1)')
parser.add_argument('--num_workers', default=0,type=int)
config = parser.parse_args()return config
# 定义训练过程。使用训练数据集进行训练,计算损失函数和评估指标,并更新模型参数。deftrain(config, train_loader, model, criterion, optimizer):# 初始化平均指标(损失和IOU)的AverageMeter对象
avg_meters ={'loss': AverageMeter(),'iou': AverageMeter()}# 将模型设置为训练模式
model.train()# 进度条可视化
pbar = tqdm(total=len(train_loader))# 遍历训练数据加载器,获取输入和目标数据。forinput, target, _ in train_loader:# 将输入和目标数据移至GPUinput=input.cuda()
target = target.cuda()# compute output# 计算模型的输出和损失。if config['deep_supervision']:
outputs = model(input)
loss =0for output in outputs:
loss += criterion(output, target)
loss /=len(outputs)
iou = iou_score(outputs[-1], target)else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)# compute gradient and do optimizing step
optimizer.zero_grad()# 梯度清零
loss.backward()# 反向传播
optimizer.step()# 更新模型参数# 更新平均指标(损失和IOU)的值
avg_meters['loss'].update(loss.item(),input.size(0))
avg_meters['iou'].update(iou,input.size(0))# 根据当前训练进度,更新并显示进度条的后缀信息,包括平均损失和平均IOU
postfix = OrderedDict([('loss', avg_meters['loss'].avg),('iou', avg_meters['iou'].avg),])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()return OrderedDict([('loss', avg_meters['loss'].avg),('iou', avg_meters['iou'].avg)])defvalidate(config, val_loader, model, criterion):
avg_meters ={'loss': AverageMeter(),'iou': AverageMeter()}# switch to evaluate mode
model.eval()with torch.no_grad():
pbar = tqdm(total=len(val_loader))forinput, target, _ in val_loader:input=input.cuda()
target = target.cuda()# compute outputif config['deep_supervision']:
outputs = model(input)
loss =0for output in outputs:
loss += criterion(output, target)
loss /=len(outputs)
iou = iou_score(outputs[-1], target)else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)
avg_meters['loss'].update(loss.item(),input.size(0))
avg_meters['iou'].update(iou,input.size(0))
postfix = OrderedDict([('loss', avg_meters['loss'].avg),('iou', avg_meters['iou'].avg),])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()return OrderedDict([('loss', avg_meters['loss'].avg),('iou', avg_meters['iou'].avg)])defmain():# 解析命令行参数
config =vars(parse_args())if config['name']isNone:if config['deep_supervision']:
config['name']='%s_%s_wDS'%(config['dataset'], config['arch'])else:
config['name']='%s_%s_woDS'%(config['dataset'], config['arch'])
os.makedirs('models/%s'% config['name'], exist_ok=True)print('-'*20)for key in config:print('%s: %s'%(key, config[key]))print('-'*20)# 配置参数config保存到文件'models/%s/config.yml' % config['name']中。withopen('models/%s/config.yml'% config['name'],'w')as f:
yaml.dump(config, f)# define loss function (criterion)if config['loss']=='BCEWithLogitsLoss':
criterion = nn.BCEWithLogitsLoss().cuda()# WithLogits 就是先将输出结果经过sigmoid再交叉熵else:
criterion = losses.__dict__[config['loss']]().cuda()# 启用CUDNN加速
cudnn.benchmark =True# create model,建模print("=> creating model %s"% config['arch'])
model = archs.__dict__[config['arch']](config['num_classes'],
config['input_channels'],
config['deep_supervision'])
model = model.cuda()# 过滤出需要更新的模型参数,并根据配置参数config中的优化器类型和参数设置创建优化器对象optimizer:## 如果config['optimizer']为'Adam',使用optim.Adam()创建Adam优化器,# 指定学习率config['lr']和权重衰减config['weight_decay']。# 如果config['optimizer']为'SGD',使用optim.SGD()创建SGD优化器,# 指定学习率config['lr']、动量config['momentum']、是否使用Nesterov动量config['nesterov']和权重衰减config['weight_decay']。# 否则,抛出NotImplementedError异常
params =filter(lambda p: p.requires_grad, model.parameters())if config['optimizer']=='Adam':
optimizer = optim.Adam(
params, lr=config['lr'], weight_decay=config['weight_decay'])elif config['optimizer']=='SGD':
optimizer = optim.SGD(params, lr=config['lr'], momentum=config['momentum'],
nesterov=config['nesterov'], weight_decay=config['weight_decay'])else:raise NotImplementedError
# 根据配置参数config中的学习率调度器类型和参数设置创建学习率调度器对象scheduler:if config['scheduler']=='CosineAnnealingLR':
scheduler = lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config['epochs'], eta_min=config['min_lr'])elif config['scheduler']=='ReduceLROnPlateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, factor=config['factor'], patience=config['patience'],
verbose=1, min_lr=config['min_lr'])elif config['scheduler']=='MultiStepLR':
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(e)for e in config['milestones'].split(',')], gamma=config['gamma'])elif config['scheduler']=='ConstantLR':
scheduler =Noneelse:raise NotImplementedError
# Data loading code
img_ids = glob(os.path.join('inputs', config['dataset'],'images','*'+ config['img_ext']))# 提取文件名
img_ids =[os.path.splitext(os.path.basename(p))[0]for p in img_ids]# 将文件名列表img_ids分割为训练集和验证集,使用train_test_split()函数,并指定验证集占比、随机种子。
train_img_ids, val_img_ids = train_test_split(img_ids, test_size=0.2, random_state=41)# 数据增强:
train_transform = Compose([
transforms.RandomRotate90(),
transforms.Flip(),
OneOf([
transforms.HueSaturationValue(),
transforms.RandomBrightness(),
transforms.RandomContrast(),], p=1),# 按照归一化的概率选择执行哪一个
transforms.Resize(config['input_h'], config['input_w']),
transforms.Normalize(),])
val_transform = Compose([
transforms.Resize(config['input_h'], config['input_w']),
transforms.Normalize(),])# 构建数据集
train_dataset = Dataset(
img_ids=train_img_ids,
img_dir=os.path.join('inputs', config['dataset'],'images'),
mask_dir=os.path.join('inputs', config['dataset'],'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=train_transform)
val_dataset = Dataset(
img_ids=val_img_ids,
img_dir=os.path.join('inputs', config['dataset'],'images'),
mask_dir=os.path.join('inputs', config['dataset'],'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=val_transform)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=config['batch_size'],
shuffle=True,
num_workers=config['num_workers'],
drop_last=True)# 不能整除的batch是否就不要了
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=config['batch_size'],
shuffle=False,
num_workers=config['num_workers'],
drop_last=False)
log = OrderedDict([('epoch',[]),('lr',[]),('loss',[]),('iou',[]),('val_loss',[]),('val_iou',[]),])
best_iou =0
trigger =0# 计数器for epoch inrange(config['epochs']):print('Epoch [%d/%d]'%(epoch, config['epochs']))# train for one epoch
train_log = train(config, train_loader, model, criterion, optimizer)# evaluate on validation set
val_log = validate(config, val_loader, model, criterion)if config['scheduler']=='CosineAnnealingLR':
scheduler.step()elif config['scheduler']=='ReduceLROnPlateau':
scheduler.step(val_log['loss'])print('loss %.4f - iou %.4f - val_loss %.4f - val_iou %.4f'%(train_log['loss'], train_log['iou'], val_log['loss'], val_log['iou']))
log['epoch'].append(epoch)
log['lr'].append(config['lr'])
log['loss'].append(train_log['loss'])
log['iou'].append(train_log['iou'])
log['val_loss'].append(val_log['loss'])
log['val_iou'].append(val_log['iou'])
pd.DataFrame(log).to_csv('models/%s/log.csv'%
config['name'], index=False)
trigger +=1if val_log['iou']> best_iou:
torch.save(model.state_dict(),'models/%s/model.pth'%
config['name'])
best_iou = val_log['iou']print("=> saved best model")
trigger =0# early stoppingif config['early_stopping']>=0and trigger >= config['early_stopping']:print("=> early stopping")break
torch.cuda.empty_cache()if __name__ =='__main__':
main()
训练结束后,可以通过valid看下模型的训练效果
效果还是不错的。

代码和数据集请百度网盘自取~
链接:https://pan.baidu.com/s/1OztNLJ0wjcDaJeY1Cs06Pw?pwd=h0ca
提取码:h0ca
–来自百度网盘超级会员V4的分享
版权归原作者 TCQD 所有, 如有侵权,请联系我们删除。