
概念
官网对其的介绍是这样的:Redis replication | Redis
我们用一句话总结如下:复制(replica)就是主从复制,master以写为主,Slave以读为主。
当master数据变化的时候,自动将新的数据异步同步到其它slave数据库。
作用
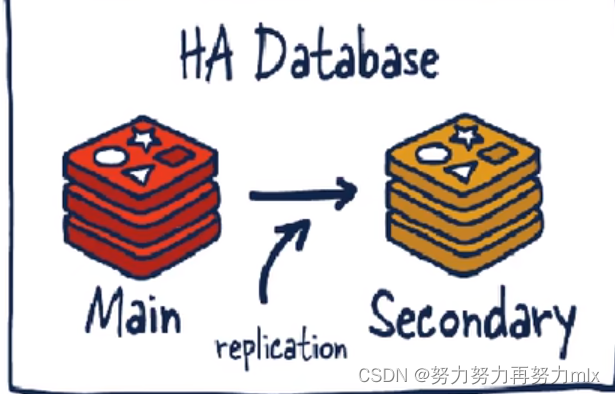
- 读写分离:主从复制中的读写分离,主要是指从主机中写入数据,然后使用从机对主机中的数据进行读取备份
- 容灾恢复:一旦主机redis发生宕机,可以在从机中进行读取恢复
- 数据备份:从机是在主机中读取数据
- 水平扩容支撑高并发:redis支持一主多从的主从模式,那么则可以设置很多的从机,这样可以在众多从机中进行轮巡读取,这样就能降低高并发环境下读取数据的压力,更好的适应高并发环境
如何使用
权限细节
- master如果配置了 requirepass 参数,需要密码登录
- slave 需要配置 masterauth来设置检验密码,否则的话master会拒绝slave的访问请求

基本的操作命令
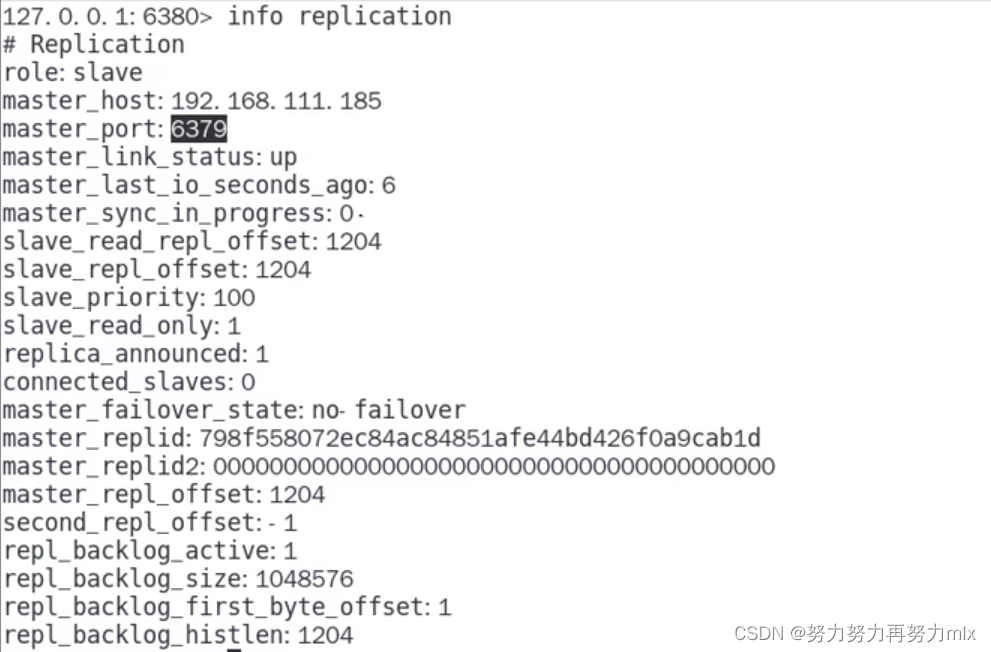
info replication // 查看复制节点的主从关系和配置信息
**
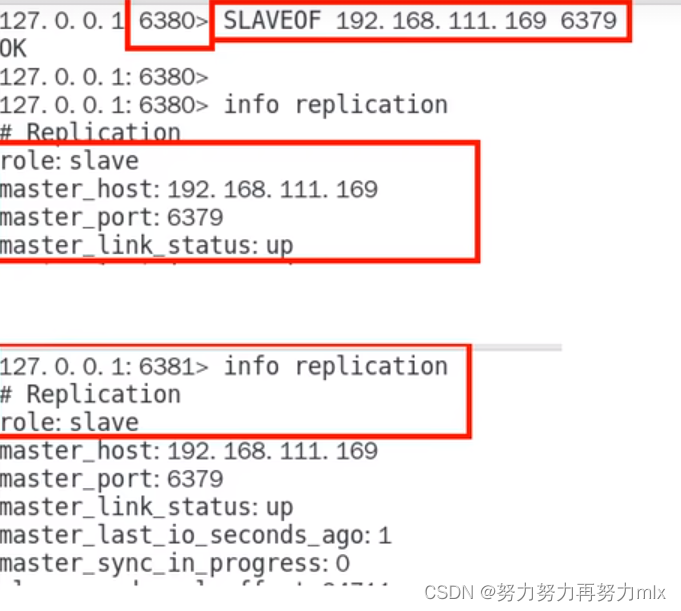
replicaof 主库IP 主库端口 // replicaof,一般写入进redis.conf配置文件内,在运行期间修改slave节点的信息,如果该数据库已经某个数据库的从数据库,那么会停止和原主数据库的同步关系转而和新的主数据库同步**** slaveof 主库IP 主库端口 //在运行期间修改slave结点的信息,如果该数据库已经是波哥主数据库的数据库,那么会停止和原数据库的同步关系转而和新的数据库同步,即重新拜码头**
replicaof/slaveof no one // 使当前数据库停止与其他数据库的同步,升级为主数据库
案例说明
架构说明

配置一个master,两个slave,3台虚拟机,拷贝redis.conf文件
- redis6379.conf (master)
- redis6380.conf (slave)
- redis6381.conf (slave)
测试三个网络互通ping并且注意防火墙配置(注意三个网络均要相互配置)

三个指令的口令化描述
主从复制
在配置文件中修改 replicaof 主库 IP 主库端口 需要注意的是:配从库不配主库

改换门庭
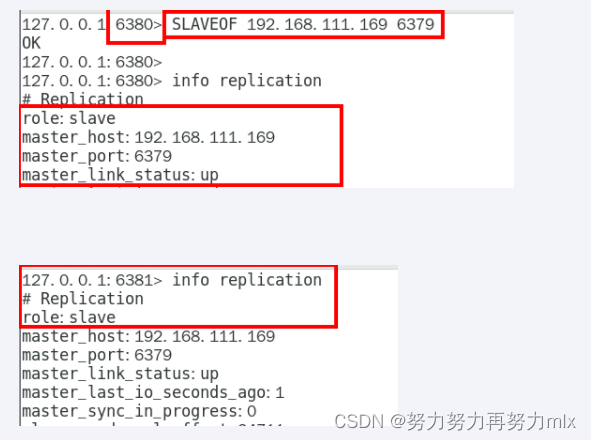
** 在redis启动之后在redis中执行salveof 新主库IP 新主库端口 指令**
自立为王
**在redis启动之后在redis中执行salveof no one 指令 **
notes:改换门庭和自立为王之后,之前储存在从机中的主机中的数据信息全部没有了
配置文件的细节操作
- 开启daemonize yes

- 注释掉bind 127.0.0.1

- Bprotected-mode no

- 指定端口

- 指定当前工作目录,dir 文件夹名

- pid文件名称,pidfilelog

- 日志文件名称,logfile
- requirepass 连接密码

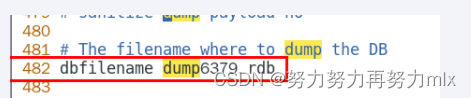
- dump.rdb名字
- aof文件,appendfilenan
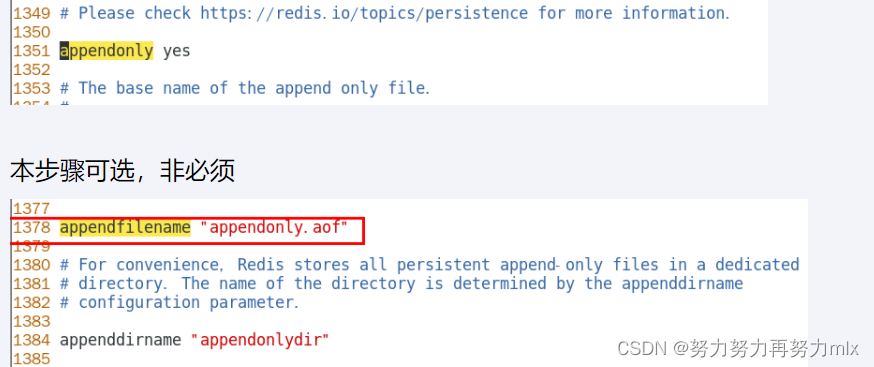
- (从机需要配)从机访问主机的通行密码masterauth,主机的ip、端口

常用三招
一主二仆
方案1 配置文件固定写死
配置两个从机 6380.conf 和 6381.conf
主从依次启动
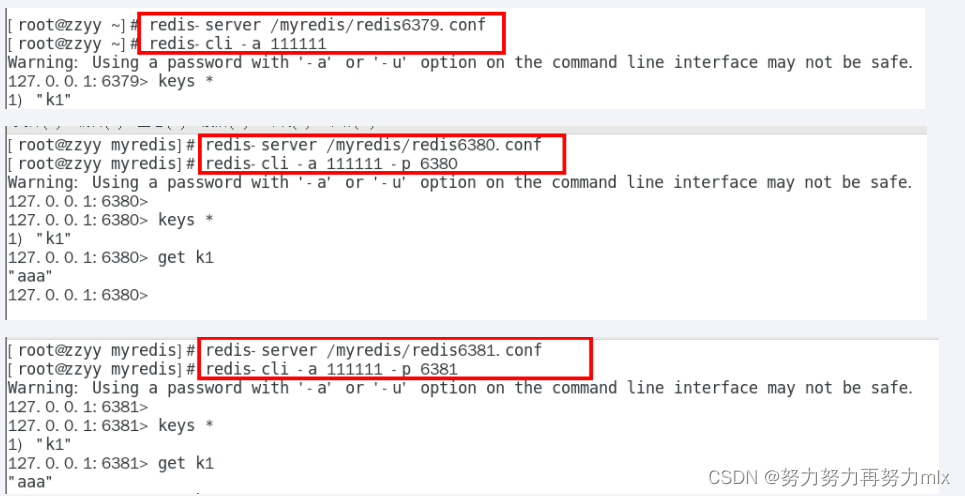
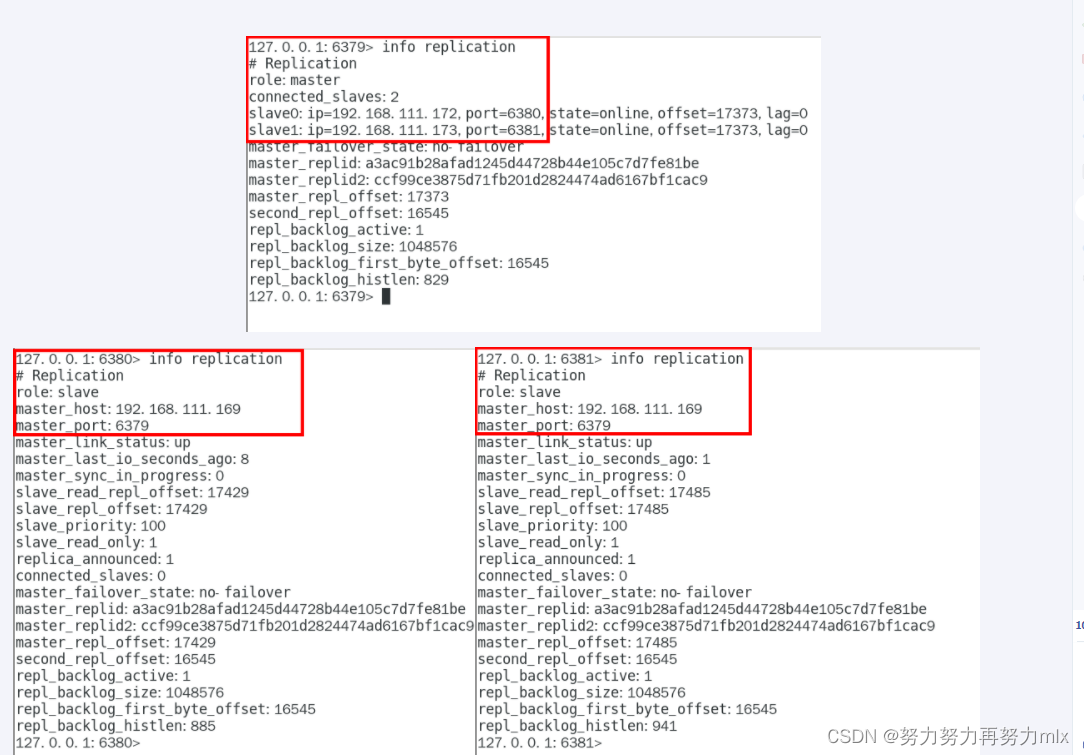
主从关系查看
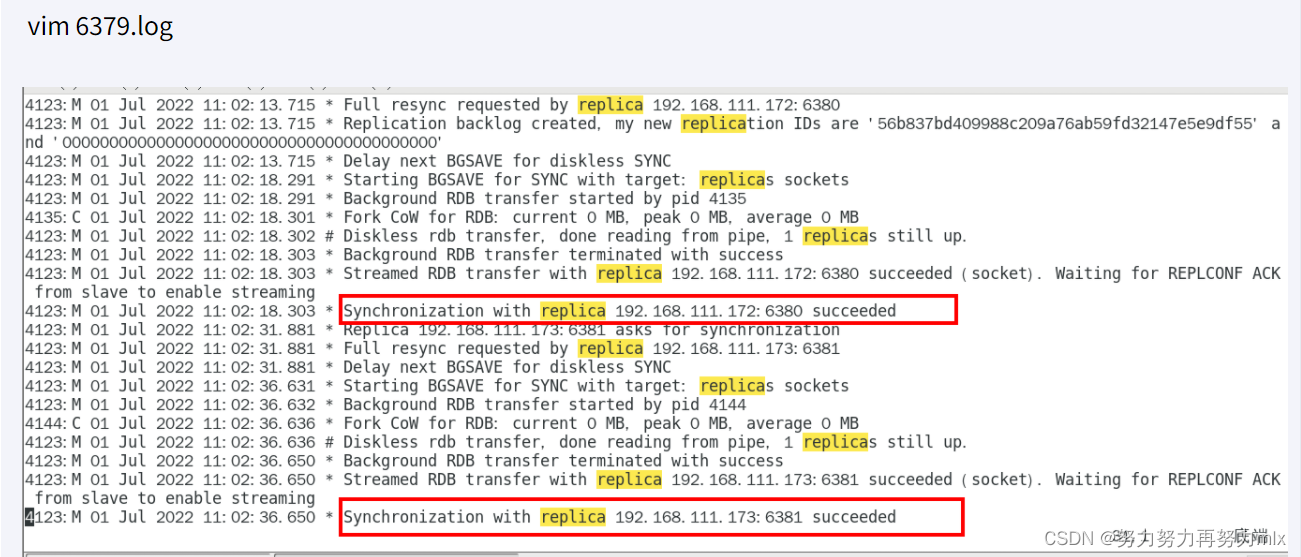
日志查看
主机日志 查看
从机日志查看
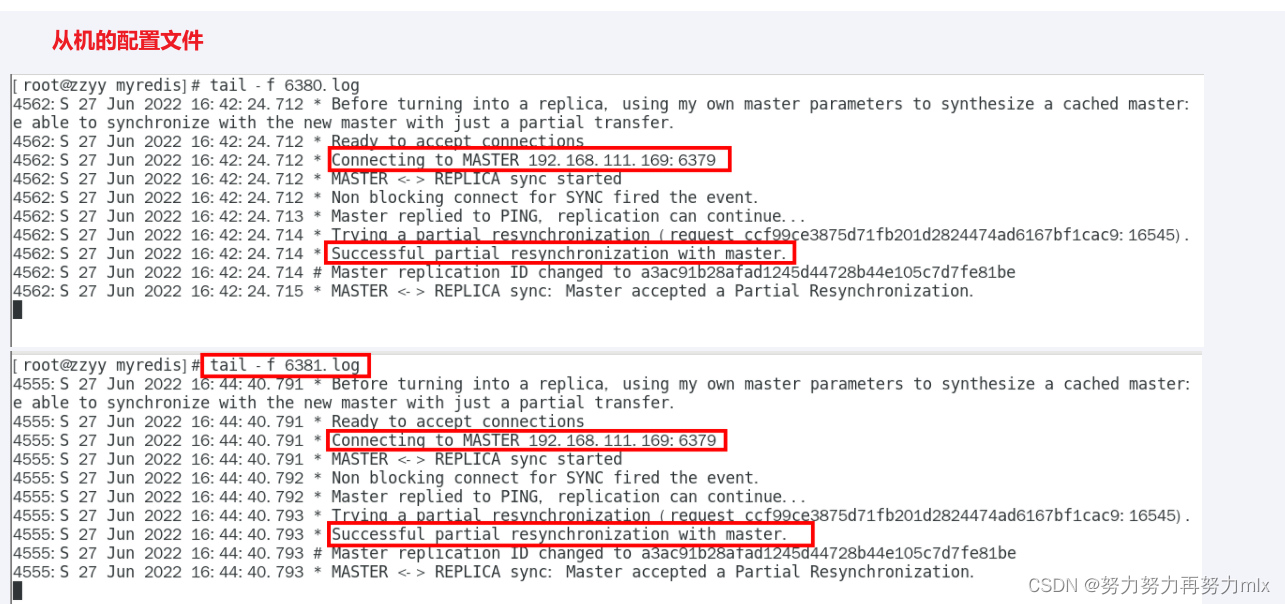
命令:info replication
方案2 命令操作手动指定
去掉配置文件中配置的从属关系 每个机器都是主机
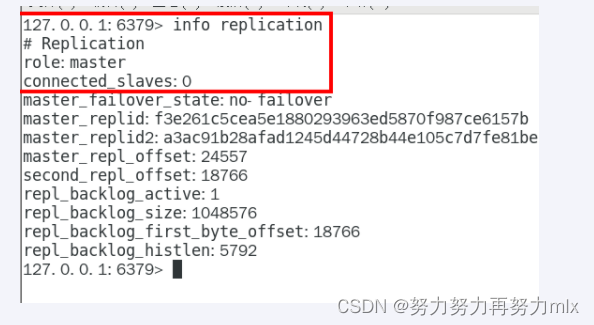
replicaof/slaveof no one 升级为主机
replicaof/slaveof 主库IP 主库端口 称为主库的从机
配置VS命令的区别
配置,持久稳定
命令,当次生效
几个经典的问题
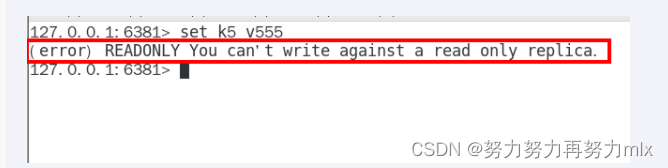
1.从机是否可以执行写命令
2.从机切入点问题
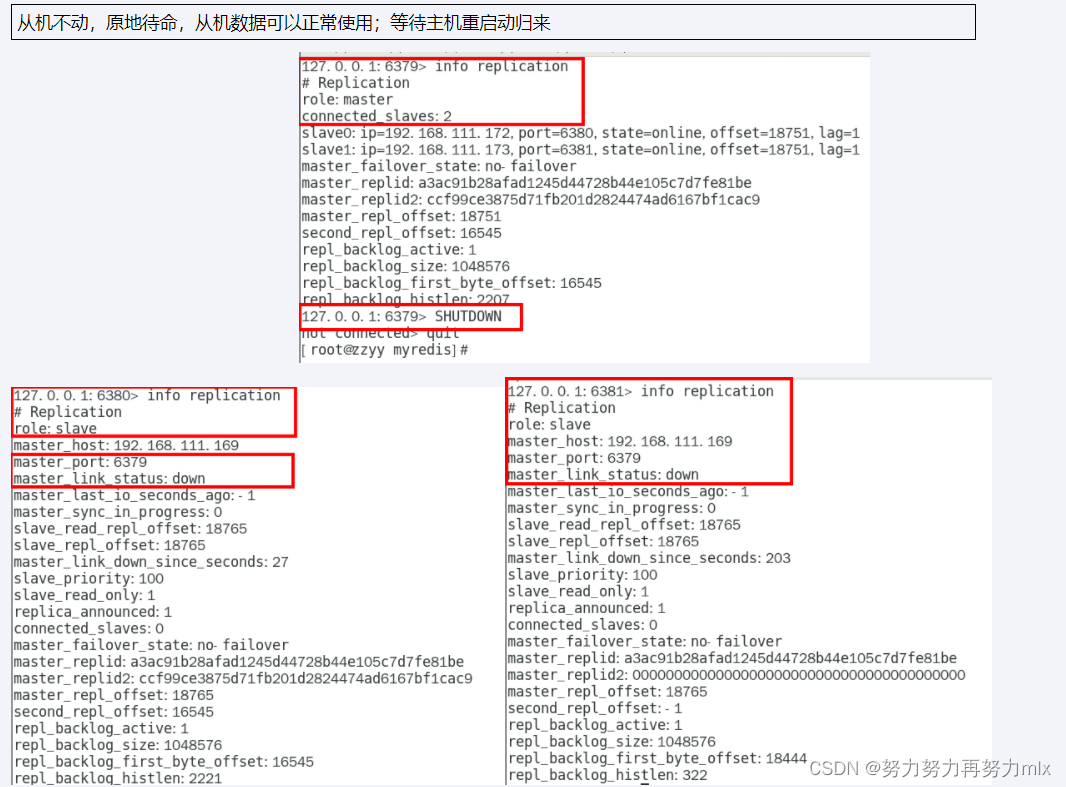
3.主机shutdown之后,从机会自己上位吗
4.主机shutdown之后,重启后主从关系还存在吗?从机能否顺利复制主机之前的数据?
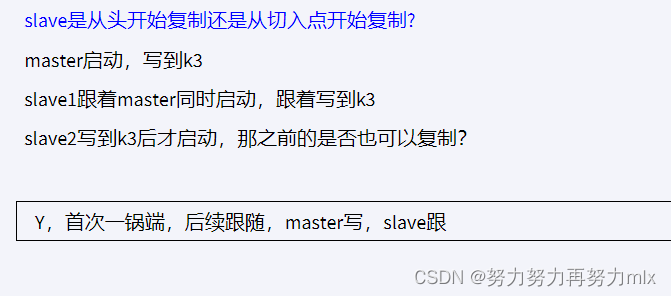
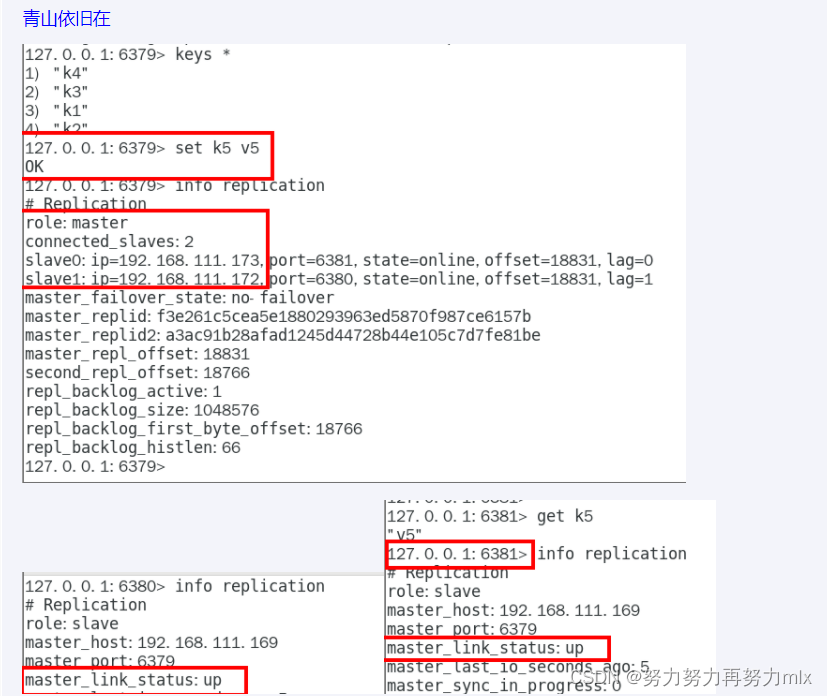
5.某台从机down后,master继续写入数据,从机重启后还能跟上大部队吗(复制down之后主机写入的数据)?** 可以**
薪火相传
- 上一个slave可以是下一个slave的master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻主master的写压力
- 中途变更转向:会清除之前的数据,重新建立拷贝最新的
- slaveof/replicaof 新主库IP 新主库端口
反客为主
slaveof/replicaof no one 使当前数据库停止与其他数据库的同步,转成主数据库
工作原理和流程
slave启动,同步初请
- slave启动成功连接到master后会发送一个sync命令
- slave首次全新连接master,一次完全同步(全量复制)将被自动执行,slave自身原有数据会被master数据覆盖清除
首次连接,全量复制
- master节点收到sync命令后会在后台开始保存快照(即RDB持久化,主从复制会触发RDB),同时收集所有接收到的用于修改数据集命令缓存起来,master节点执行RDB持久化后,master将rdb快照文件和缓存的命令发送到所有slave,已完成一次完全同步
- 而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中,从而完成复制初始化
心跳持续,保持通信
- repl-ping-replica-period 10
- master发出PING包的周期,默认是10秒(即每十秒钟master给slave发送心跳包,确认从机的的存活性)
进入平稳,增量复制
master 继续将新的所有收集到的修改命令自动一次传给slave,完成同步
从机下线,重连续传
- master 会检查backlog里面的offset,master和slave都会保存一个复制的offset怀有一个masterId
- offset 是保存在backlog 中的。master只会把已经复制的offset后面的数据赋值给slave,类似断电续传
复制的缺点
复制延时,信号衰减
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
master挂了
默认情况下不会在slave节点自动重选一个master
需要人工干预
版权归原作者 努力努力再努力mlx 所有, 如有侵权,请联系我们删除。