
文章目录
对于数据异常值处理,我的理解是,这里的异常值不是代表数据出现的异常,而是对于你需要建立的模型来说,处于异常值。
比如你需要正太分布的数据,那么一些不符合正太分布,或者离群太远的值,可以更具你的需要去进行删除,这样你的模型效果就会更好。
简单统计分析
首先是简单的统计分析,比如通过最大最小值判断,什么意思呢?之前比赛遇到过一个二手车价格的问题,别的二手车都是几万到10几万不等,有一个要1000万的二手车。
1000万???,没错就是1000万的二手车,这样的数据,就算他是改装过后的玛莎拉蒂,是真实数据,但是这样的数据会影响模型的判断,所以在数据量大的时候,还是需要删除的。
df_train.max()#最大值
df_train.min()#最小值
3σ原则
在正态分布中,σ代表标准差,μ代表均值,x=μ即为图像的对称轴。3σ原则为
数值分布在(μ-σ,μ+σ)中的概率为0.6826,
数值分布在(μ-2σ,μ+2σ)中的概率为0.9544,
数值分布在(μ-2σ,μ+2σ)中的概率为0.9544。
可以认为,Y 的取值几乎全部集中在(μ-3σ,μ+3σ)]区间内,超出这个范围的可能性仅占不到0.3%。几乎是不可能事件。
import numpy as np
#设定法则的左右边界
left=num.mean()-3*num.std()
right=num.mean()+3*num.std()#获取在范围内的数据
new_num=num[(left<num)&(num<right)]
这里数据是numpy的数组。
这些删除数据的方式,都有一定的依据,但是也不能完全按照这些依据,具体情况要看数据。
箱线图
箱线图是一种强大的,数据可视化工具,用于了解数据的分布。它将数据分成四分位数,并根据从这些四分位数得出的五个数字对其进行汇总:
- 中位数:数据的中间值。标记为 Q2,描绘了第 50 个百分点。
- 第一个四分位数:“最小非异常值”和中位数之间的中间值。标记为 Q1,描绘了第 25 个百分点。
- 第三四分位数:“最大非异常值”和中位数之间的中间值。标记为 Q3,描绘了第 75 个百分点。
- “最大非异常值”:按 (Q3 + 1.5*IQR) 计算。高于此值的所有值都被视为异常值。
- “最小非异常值”:按 (Q1 – 1.5*IQR) 计算。低于此值的所有值都被视为异常值。
它还可以表示数据的对称性、偏度和分布。
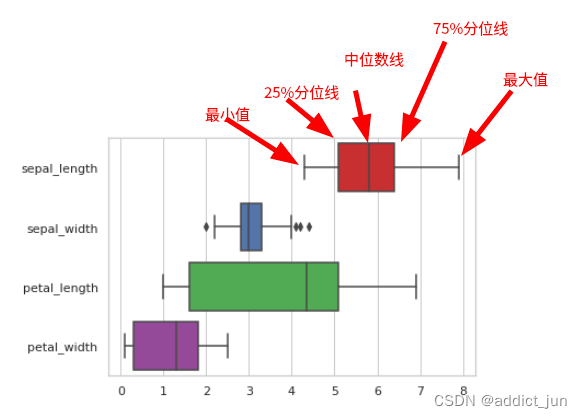
sns.boxplot(x='diagnosis', y='area_mean', data=df)
上述三种是异常值的分析方法,而当找到异常值之后,我们因该如何处理这些异常值呢?
异常值方法处理
1.直接删除
如果数据量多的话,可以直接删除。参考上方3σ原则,或者根据实际情况,删除大于某个值的部分。
2.缺失值
当多缺省值进行处理。
3.修改为平均值
其实也是缺省值中的一种方法。
4.盖帽法
这种方法比较“轻柔”,不容易用力过猛。
5.分箱法
通过分箱,分桶这样的方式,在进行数据填充,会比较合理。
6不处理
这可能是异常值的特点,但是需要使用更加稳健的模型来修饰。
版权归原作者 addict_jun 所有, 如有侵权,请联系我们删除。