
动手学深度学习笔记
一、情感分析及数据集
情感分析研究人们在文本中(如产品评论、博客评论和论坛讨论等)“隐藏”的情绪。
这里使用斯坦福大学的大型电影评论数据集(large movie review dataset)进行情感分析。它由一个训练集和一个测试集组成,其中包含从IMDb下载的25000个电影评论。在这两个数据集中,“积极”和“消极”标签的数量相同,表示不同的情感极性。
1.读取数据集
import os
import torch
from torch import nn
from d2l import torch as d2l
d2l.DATA_HUB['aclImdb']=('http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz','01ada507287d82875905620988597833ad4e0903')
data_dir = d2l.download_extract('aclImdb','aclImdb')defread_imdb(data_dir, is_train):"""读取IMDb评论数据集文本序列和标签(1:积极,0:消极)"""
data, labels =[],[]for label in('pos','neg'):
folder_name = os.path.join(data_dir,'train'if is_train else'test', label)forfilein os.listdir(folder_name):withopen(os.path.join(folder_name,file),'rb')as f:
review = f.read().decode('utf-8').replace('\n','')
data.append(review)
labels.append(1if label =='pos'else0)return data, labels
2.预处理数据集
将每个单词作为一个词元,过滤掉出现不到5次的单词,从训练数据集中创建一个词表。
train_data = read_imdb(data_dir, is_train=True)
train_tokens = d2l.tokenize(train_data[0], token='word')
vocab = d2l.Vocab(train_tokens, min_freq=5, reserved_tokens=['<pad>'])
在词元化之后,绘制评论词元长度的直方图。
d2l.set_figsize()
d2l.plt.xlabel('# tokens per review')
d2l.plt.ylabel('count')
d2l.plt.hist([len(line)for line in train_tokens], bins=range(0,1000,50));
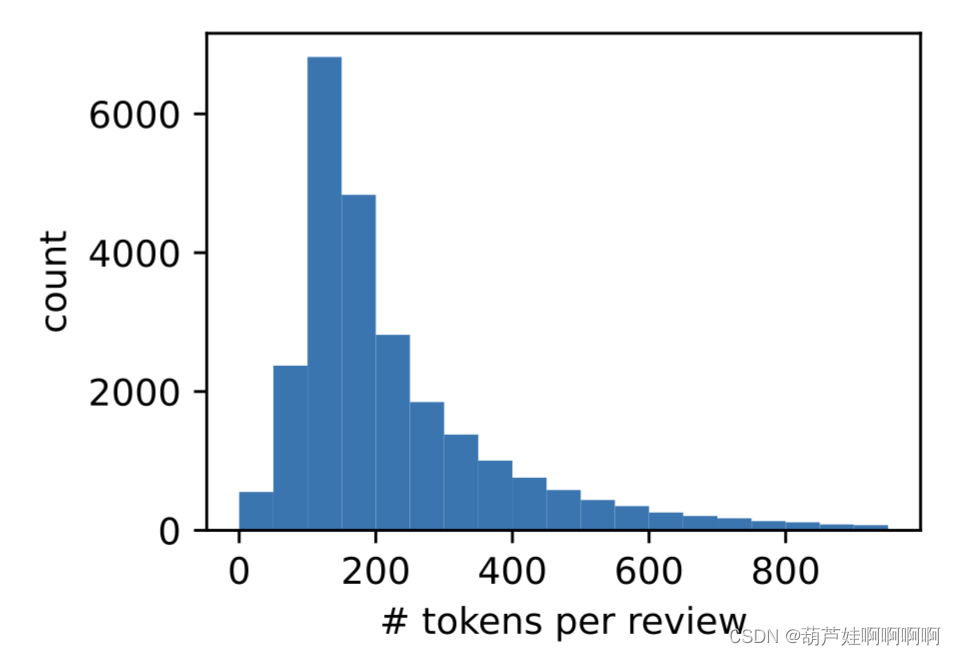
从上图可以看出评论的长度各不相同,为了每次处理一小批量这样的评论,通过截断和填充将每个评论的长度设置为500。类似于基于Seq2Seq的机器翻译-PyTorch中对机器翻译数据集的预处理步骤。
defload_data_imdb(batch_size, num_steps=500):"""返回数据迭代器和IMDb评论数据集的词表"""
data_dir = d2l.download_extract('aclImdb','aclImdb')
train_data = read_imdb(data_dir,True)
test_data = read_imdb(data_dir,False)
train_tokens = d2l.tokenize(train_data[0], token='word')
test_tokens = d2l.tokenize(test_data[0], token='word')
vocab = d2l.Vocab(train_tokens, min_freq=5)
train_features = torch.tensor([d2l.truncate_pad(
vocab[line], num_steps, vocab['<pad>'])for line in train_tokens])
test_features = torch.tensor([d2l.truncate_pad(
vocab[line], num_steps, vocab['<pad>'])for line in test_tokens])
train_iter = d2l.load_array((train_features, torch.tensor(train_data[1])),
batch_size)
test_iter = d2l.load_array((test_features, torch.tensor(test_data[1])),
batch_size,
is_train=False)return train_iter, test_iter, vocab
二、利用RNN进行情感分析
由于IMDb评论数据集不是很大,使用在大规模语料库上预训练的文本表示可以减少模型的过拟合。使用预训练的GloVe模型来表示每个词元,并将这些词元表示送入多层双向RNN以获得文本序列表示,该文本序列表示将被转换为情感分析输出。
1.使用RNN表示单个文本
在文本分类任务(如情感分析)中,可变长度的文本序列将被转换为固定长度的类别。
在下面的
BiRNN
类中,虽然文本序列的每个词元经由嵌入层(
self.embedding
)获得其单独的预训练GloVe表示,但是整个序列由Bi-LSTM(
self.encoder
)编码。Bi-LSTM在初始和最终时间步的隐状态(在最后一层)被连结起来作为文本序列的表示。
batch_size =64
train_iter, test_iter, vocab = load_data_imdb(batch_size)classBiRNN(nn.Module):def__init__(self, vocab_size, embed_size, num_hiddens, num_layers,**kwargs):super(BiRNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.encoder = nn.LSTM(embed_size, num_hiddens, num_layers=num_layers,
bidirectional=True)
self.decoder = nn.Linear(4* num_hiddens,2)defforward(self, inputs):# inputs的形状是(批量大小,时间步数)# LSTM要求输入的第一个维度是时间维,所以在获得词元表示之前,输入会被转置。# 输出形状为(时间步数,批量大小,词向量维度)
embeddings = self.embedding(inputs.T)
self.encoder.flatten_parameters()# 返回上一个隐藏层在不同时间步的隐状态,# outputs的形状是(时间步数,批量大小,2*隐藏单元数)
outputs, _ = self.encoder(embeddings)# 连结初始和最终时间步的隐状态,作为全连接层的输入,# 其形状为(批量大小,4*隐藏单元数)
encoding = torch.cat((outputs[0], outputs[-1]), dim=1)
outs = self.decoder(encoding)return outs
构造一个具有两个隐藏层的双向LSTM来表示单个文本以进行情感分析。
embed_size, num_hiddens, num_layers =100,100,2
devices = d2l.try_all_gpus()
net = BiRNN(len(vocab), embed_size, num_hiddens, num_layers)
definit_weights(m):iftype(m)== nn.Linear:
nn.init.xavier_uniform_(m.weight)iftype(m)== nn.LSTM:for param in m._flat_weights_names:if"weight"in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(init_weights)'''
BiRNN(
(embedding): Embedding(49345, 100)
(encoder): LSTM(100, 100, num_layers=2, bidirectional=True)
(decoder): Linear(in_features=400, out_features=2, bias=True)
)
'''
2.加载预训练的词向量
为词表中的单词加载预训练的100维(需要与
embed_size
一致)的GloVe嵌入。
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')# 打印词表中所有词元向量的形状
embeds = glove_embedding[vocab.idx_to_token]
embeds.shape
使用预训练的词向量表示评论中的词元,并且在训练期间不更新这些向量。
net.embedding.weight.data.copy_(embeds)
net.embedding.weight.requires_grad =False
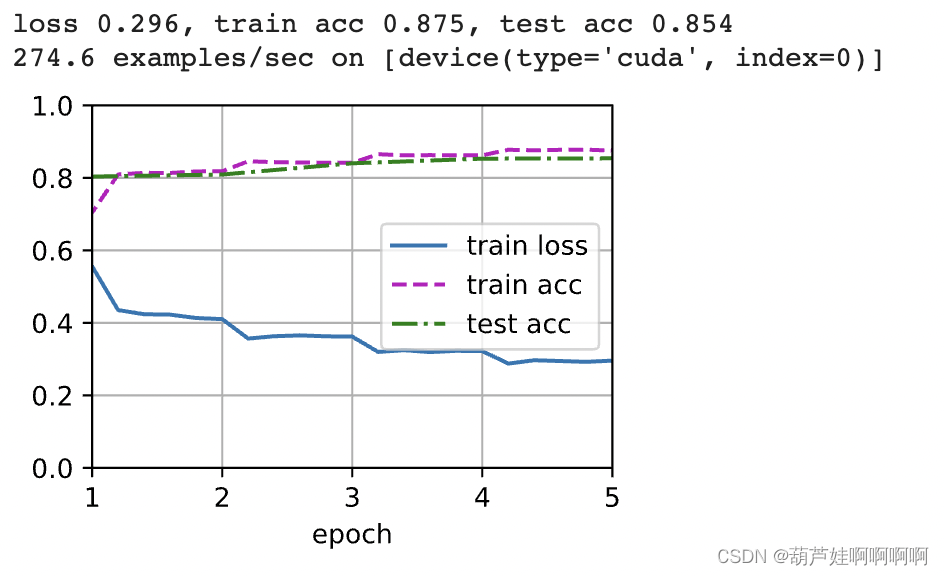
3.训练和评估模型
现在我们可以训练双向循环神经网络进行情感分析。(CPU跑不动,5个epochGPU跑了10分钟)
lr, num_epochs =0.01,5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
4.预测
来使用训练好的模型
net
预测文本序列的情感。
defpredict_sentiment(net, vocab, sequence):"""预测文本序列的情感"""
sequence = torch.tensor(vocab[sequence.split()], device=d2l.try_gpu())
label = torch.argmax(net(sequence.reshape(1,-1)), dim=1)return'positive'if label ==1else'negative'print(predict_sentiment(net, vocab,'this movie is so great'))print(predict_sentiment(net, vocab,'this movie is so bad'))
三、利用CNN进行情感分析
通过将文本序列想象成一维图像,一维卷积神经网络可以处理文本中的局部特征,例如n元语法。
使用
t
e
x
t
C
N
N
textCNN
textCNN 模型演示如何设计一个表示单个文本的卷积神经网络架构。
1.一维卷积

一维互相关运算
在一维情况下,卷积窗口在输入张量上从左向右滑动。
defcorr1d(X, K):"""一维互相关运算"""
w = K.shape[0]
Y = torch.zeros((X.shape[0]- w +1))for i inrange(Y.shape[0]):
Y[i]=(X[i: i + w]* K).sum()return Y
对于任何具有多个通道的一维输入,卷积核需要具有相同数量的输入通道。然后,对于每个通道,对输入的一维张量和卷积核的一维张量执行互相关运算,将所有通道上的结果相加以产生一维输出张量。
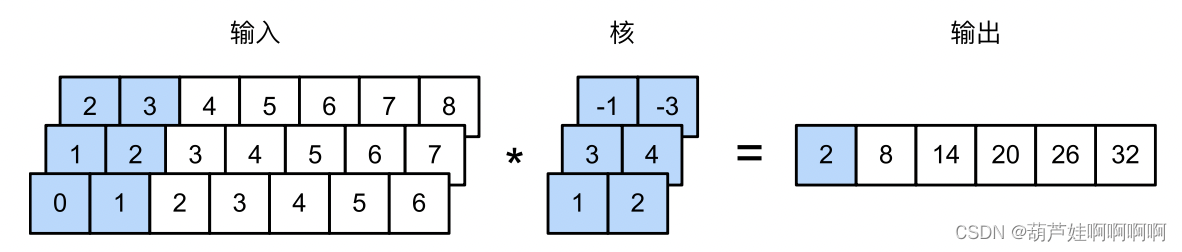
具有3个输入通道的一维互相关运算
defcorr1d_multi_in(X, K):# 首先,遍历'X'和'K'的第0维(通道维),然后,把它们加在一起。returnsum(corr1d(x, k)for x, k inzip(X, K))
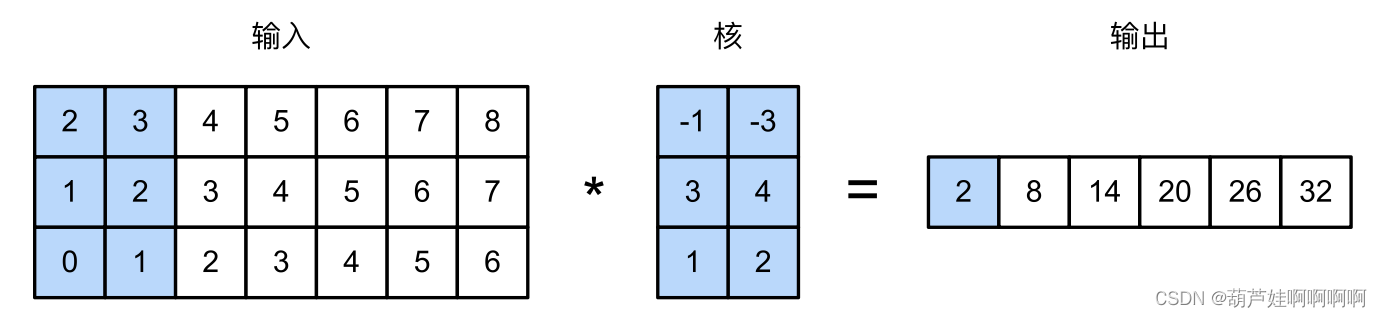
具有单个输入通道的二维互相关操作
注意,
多输入通道的一维互相关等同于单输入通道的二维互相关
。多输入通道一维互相关的等价形式是单输入通道二维互相关,其中卷积核的高度必须与输入张量的高度相同。
2.textCNN模型
使用一维卷积和最大时间汇聚,textCNN模型将单个预训练的词元表示作为输入,然后获得并转换用于下游应用的序列表示。
对于具有由
d
d
d 维向量表示的
n
n
n 个词元的单个文本序列,输入张量的宽度、高度和通道数分别为
n
n
n、
1
1
1和
d
d
d。textCNN模型将输入转换为输出,如下所示:
- 定义多个一维卷积核,并分别对输入执行卷积运算。具有不同宽度的卷积核可以捕获不同数目的相邻词元之间的局部特征。
- 在所有输出通道上执行最大时间汇聚层,然后将所有标量汇聚输出连结为向量。
- 使用全连接层将连结后的向量转换为输出类别。Dropout可以用来减少过拟合。
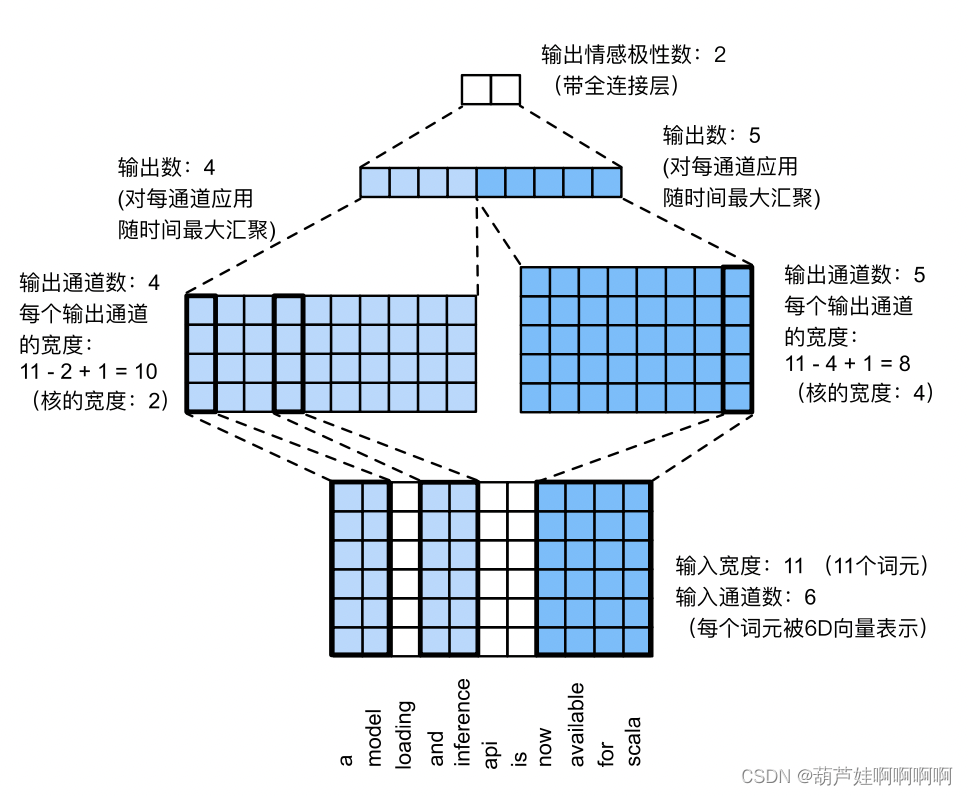
输入是具有11个词元的句子,其中每个词元由6维向量表示。因此,有一个宽度为11的6通道输入。定义两个宽度为2和4的一维卷积核,分别具有4个和5个输出通道。它们产生4个宽度为
11
−
2
+
1
=
10
11-2+1=10
11−2+1=10的输出通道和5个宽度为
11
−
4
+
1
=
8
11-4+1=8
11−4+1=8的输出通道。尽管这9个通道的宽度不同,但最大时间汇聚层给出了一个连结的9维向量,该向量最终被转换为用于二元情感预测的2维输出向量。
- 定义模型
与上文的双向LSTM模型相比,除了用卷积层代替循环神经网络层外,还使用了两个嵌入层:一个是可训练权重,另一个是固定权重。
classTextCNN(nn.Module):def__init__(self, vocab_size, embed_size, kernel_sizes, num_channels,**kwargs):super(TextCNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)# 这个嵌入层不需要训练
self.constant_embedding = nn.Embedding(vocab_size, embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels),2)
self.pool = nn.AdaptiveAvgPool1d(1)
self.relu = nn.ReLU()# 创建多个一维卷积层
self.convs = nn.ModuleList()for c, k inzip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(2* embed_size, c, k))defforward(self, inputs):# 沿着向量维度将两个嵌入层连结起来,# 每个嵌入层的输出形状都是(批量大小,词元数量,词元向量维度)连结起来
embeddings = torch.cat((
self.embedding(inputs), self.constant_embedding(inputs)), dim=2)# 根据一维卷积层的输入格式,重新排列张量,以便通道作为第2维
embeddings = embeddings.permute(0,2,1)# 每个一维卷积层在最大时间汇聚层合并后,获得的张量形状是(批量大小,通道数,1)# 删除最后一个维度并沿通道维度连结
encoding = torch.cat([
torch.squeeze(self.relu(self.pool(conv(embeddings))), dim=-1)for conv in self.convs], dim=1)
outputs = self.decoder(self.dropout(encoding))return outputs
创建一个textCNN实例。它有3个卷积层,卷积核宽度分别为3、4和5,均有100个输出通道。
embed_size, kernel_sizes, nums_channels =100,[3,4,5],[100,100,100]
devices = d2l.try_all_gpus()
net = TextCNN(len(vocab), embed_size, kernel_sizes, nums_channels)definit_weights(m):iftype(m)in(nn.Linear, nn.Conv1d):
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)'''
TextCNN(
(embedding): Embedding(49345, 100)
(constant_embedding): Embedding(49345, 100)
(dropout): Dropout(p=0.5, inplace=False)
(decoder): Linear(in_features=300, out_features=2, bias=True)
(pool): AdaptiveAvgPool1d(output_size=1)
(relu): ReLU()
(convs): ModuleList(
(0): Conv1d(200, 100, kernel_size=(3,), stride=(1,))
(1): Conv1d(200, 100, kernel_size=(4,), stride=(1,))
(2): Conv1d(200, 100, kernel_size=(5,), stride=(1,))
)
)
'''
3.加载预训练词向量
加载预训练的100维GloVe嵌入作为初始化的词元表示。这些词元表示(嵌入权重)在
embedding
中将被训练,在
constant_embedding
中将被固定。
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.data.copy_(embeds)
net.constant_embedding.weight.requires_grad =False
4.训练和评估模型
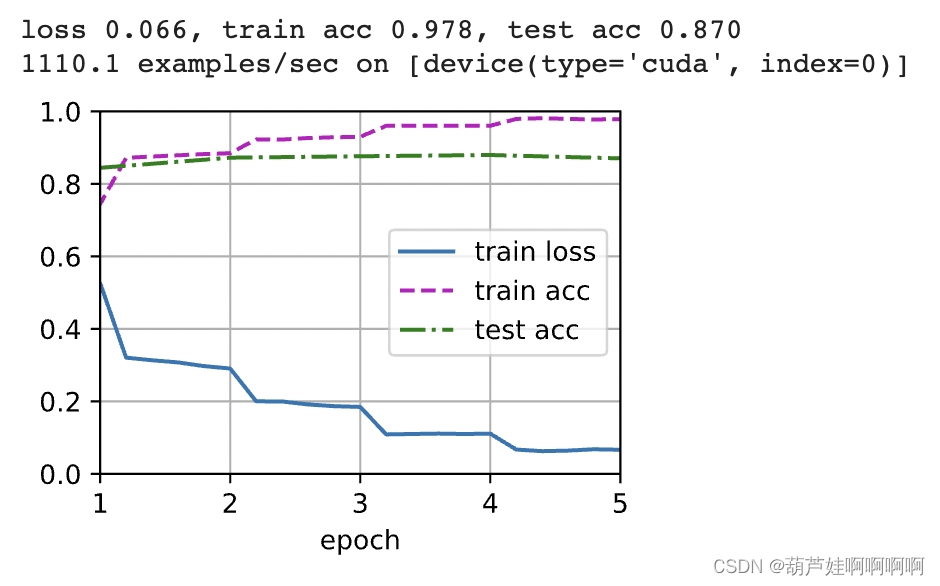
训练textCNN模型进行情感分析。(GPU约三分钟)
lr, num_epochs =0.001,5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
5.预测
print(predict_sentiment(net, vocab,'this movie is so great'))print(predict_sentiment(net, vocab,'this movie is so bad'))
版权归原作者 葫芦娃啊啊啊啊 所有, 如有侵权,请联系我们删除。