
该文档主要参考:
概述
该项目要求从网络上爬取相关设备故障和维修解决方式,并构建知识库,当设备出现故障时,用户通过输入数控机床相关参数(品牌、型号、故障代码、某个或多个超出阈值参数、故障描述(文字或语音)等),系统可以根据知识库来进行故障诊断和排除,如果没有满意的方案,系统会再次进行网络爬取,如果答案有效,则对知识库进行补充和优化。
数据来源:
数据来源是《实用数控机床故障诊断及维修技术500例》
对文档里的每一条故障描述进行拆解和分类(CNN),构建出了5种三元式推理规则,分别为:故障现象和故障现象之间存在并发症,故障前执行的操作间接导致的故障现象,某故障原因导致的故障现象,报警信息伴随的故障现象,故障部位常见的故障现象。
使用效果:
使用Neo4j图数据库存储。当用户输入一条故障信息时,我们按照上面构建RDF的方法,对故障描述先按照标点符号分句,然后使用CNN分类,识别出此次故障中用户执行了哪些操作,出现了哪些故障现象,然后根据知识图谱进行对照,除了推理出故障原因以及解决办法之外,还会推理出与已经发现的故障相关的未发现的设备故障,通过用户进一步检查反馈,可以进一步提高诊断结果的可靠性。
功能延申
如果用户没有找到满意的解决方法,还可以通过在线爬取网上的解决办法来做参考,如果找到了满意的解决办法,系统会将此次维修记录补充到知识图谱中,实现知识库的自学习。
知识图谱流程图:
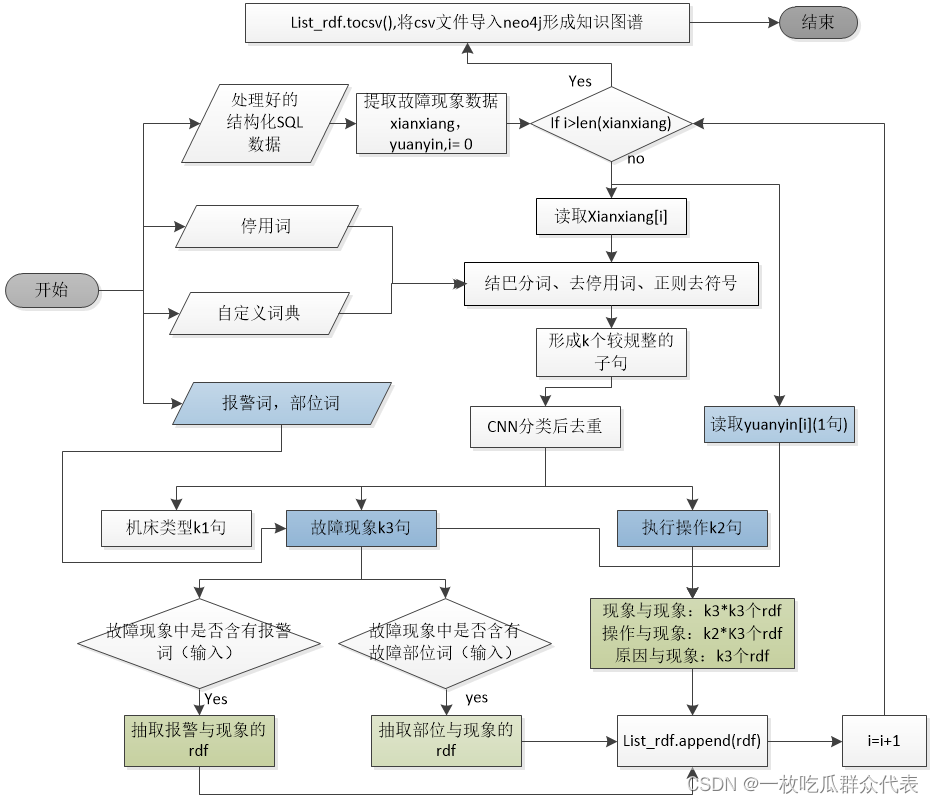
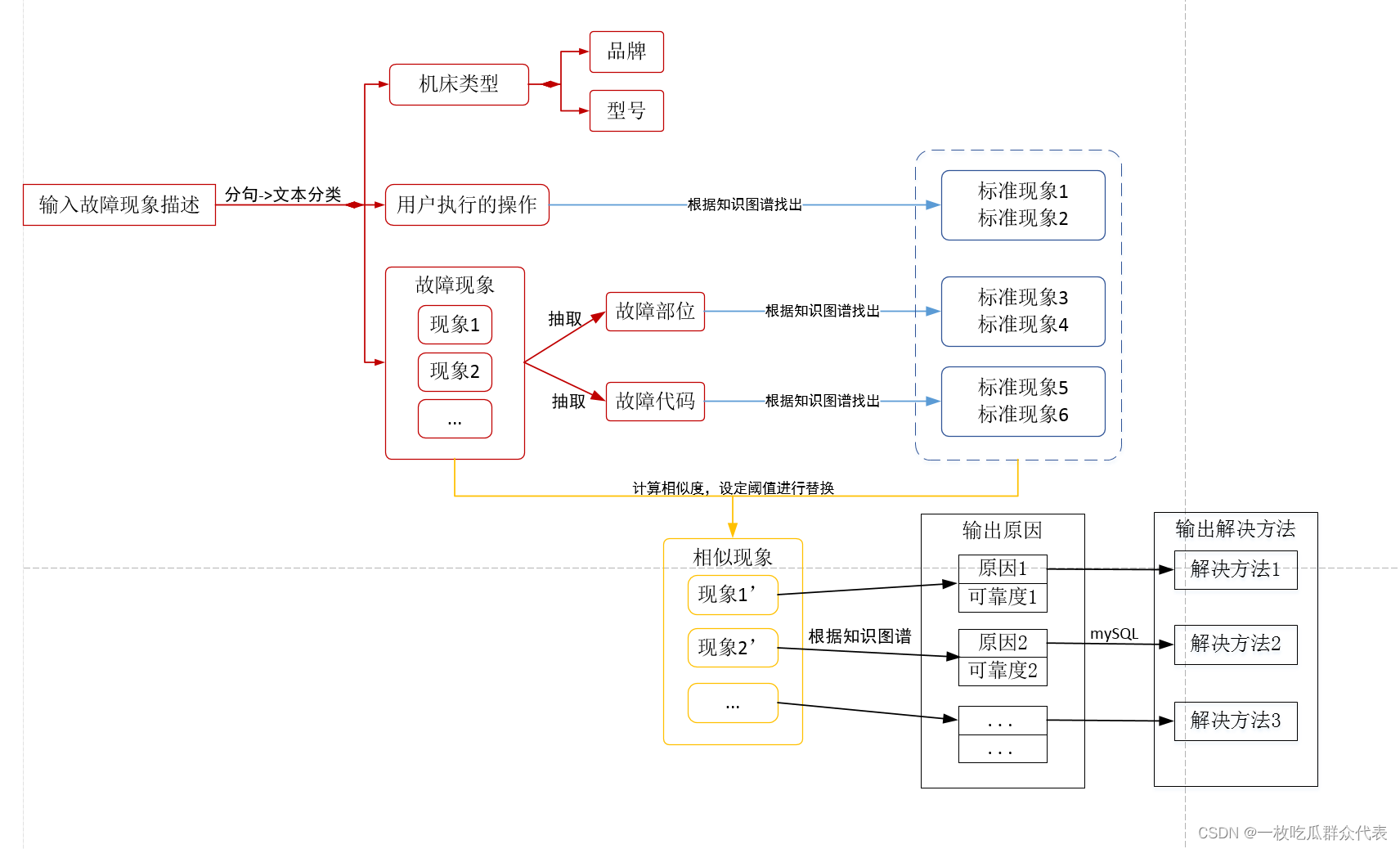
故障诊断过程图:
代码目录结构
├── Shukongdashi
└── demo
├── checkpoints //存放CNN的训练模型
├── data //CNN预测辅助代码和文件
├── cnews //使用CNN预测用到的词
└── cnews_loader.py //为数据的预处理文件
├── fencidian.txt //分词词典
├── question_answer.py //第一版故障诊断代码(已弃用)
├── question_baocun.py //处理用户反馈的代码
├── question_buquan.py //自动补全代码
├── question_pa.py //在线分析性代码,爬取解决方法
├── question_wenda.py //问答功能
├── question_zhenduan.py //故障诊断代码
├── stopwords.txt //停用词词典
└── zhuyu.txt //故障部位词典
├── Model
└── neo_models.py //执行neo4j数据库操作
├── test_my
├── data_wordToMysql //将word中的数据转换成csv文件,存储到MySQL中
├── test_cnnrnn //CNN卷积神经网络预测
├── checkpoints //存储训练模型
├── data //数据的预处理文件
├── neo4j //导入Neo4j的数据
├── baojing.csv //故障代码
├── caozuo.csv //执行的操作
├── caozuoxianxaing.csv //由于执行某操作引起了某现象
├── xianxaingbaojing.csv //某现象对应的报警信息
├── xianxaingbuwei.csv //某现象对应的故障部位
├── xianxiang.csv //故障现象
├── xianxiangxianxiang.csv //故障现象和故障现象之间的关联关系
├── xianxiangyuanyin.csv //故障现象的间接故障原因
├── yuanyin2.csv //故障原因
└── zhuyu.csv //故障部位
├── cnn_model.py //CNN配置
├── guzhangfenxi.py //构建Neo4j数据库用的数据
└── predict.py //CNN预测识别故障描述类型
└── xianxiangfenxi //故障部位词典
├── baojing.csv //对故障现象进行拆分,抽取出故障部位,故障现象,故障发生的背景,手动标记后进一步标注含义
├── biaozhu_minming.txt //标注好的数据,用于训练CNN模型
└── guzhangxianxiang.csv //用于分析的故障现象文件
├── toolkit
└── pre_load.py //预加载训练模型和Neo4j数据库,还可以对读取词典进行预加载,进行性能优化
├── settings.py //配置访问端口等
├── urls.py //配置URL与python函数的映射
├── view.py //默认页面
└── wsgi.py
├── db.sqlite3
└── manage.py //Django框架项目启动入口
关于CNN训练模型的模块请参考@gaussic的text-classification-cnn-rnn项目。通过训练模型,可以实现预测文本内容的分类。
在我们的项目中,我们将数控机床维修案例的文本数据切分之后,手动标注了两千多条数据,用来做训练,标注的文本见**Shukongdashi/test_my/xianxiangfenxi/biaozhu_minming.txt**
环境配置
python3和Neo4j(任意版本)
1. 导入数据
开启neo4j,进入neo4j控制台。将Shukongdashi/test_my/test_cnnrnn/neo4/下的文件放入neo4j安装目录下的/import目录。在控制台依次输入:
//导入节点
LOAD CSV WITH HEADERS FROM "file:///baojing.csv" AS line MERGE (:Errorid { title: line.title });
CREATE CONSTRAINT ON (c:Errorid) ASSERT c.title IS UNIQUE;
LOAD CSV WITH HEADERS FROM "file:///caozuo.csv" AS line MERGE (:Caozuo { title: line.title });
CREATE CONSTRAINT ON (c:Caozuo) ASSERT c.title IS UNIQUE;
LOAD CSV WITH HEADERS FROM "file:///xianxiang.csv" AS line MERGE (:Xianxiang { title: line.title });
CREATE CONSTRAINT ON (c:Xianxiang) ASSERT c.title IS UNIQUE;
LOAD CSV WITH HEADERS FROM "file:///zhuyu.csv" AS line MERGE (:GuzhangBuwei { title: line.title });
CREATE CONSTRAINT ON (c:GuzhangBuwei) ASSERT c.title IS UNIQUE;
LOAD CSV WITH HEADERS FROM "file:///yuanyin2.csv" AS line MERGE (:Yuanyin { title: line.title });
CREATE CONSTRAINT ON (c:Yuanyin) ASSERT c.title IS UNIQUE;
//导入关系
LOAD CSV WITH HEADERS FROM "file:///caozuoxianxaing.csv" AS line MATCH (entity1 {title:line.title1}),(entity2 {title:line.title2}) CREATE (entity1)-[:CX { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM "file:///xianxiangyuanyin.csv" AS line MATCH (entity1 {title:line.title1}),(entity2 {title:line.title2}) CREATE (entity1)-[:XY { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM "file:///xianxiangxianxiang.csv" AS line MATCH (entity1 {title:line.title1}),(entity2 {title:line.title2}) CREATE (entity1)-[:XX { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM "file:///xianxaingbuwei.csv" AS line MATCH (entity1 {title:line.title1}),(entity2 {title:line.title2}) CREATE (entity1)-[:XB { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM "file:///xianxaingbaojing.csv" AS line MATCH (entity1 {title:line.title1}),(entity2 {title:line.title2}) CREATE (entity1)-[:XJ { type: line.relation }]->(entity2)
2.修改Neo4j用户
进入Shukongdashi/Model/neo_models.py,修改第8行的neo4j账号密码,改成你自己的
3. 启动服务
进入项目根目录,然后运行脚本:
python manage.py runserver 0.0.0.0:8000
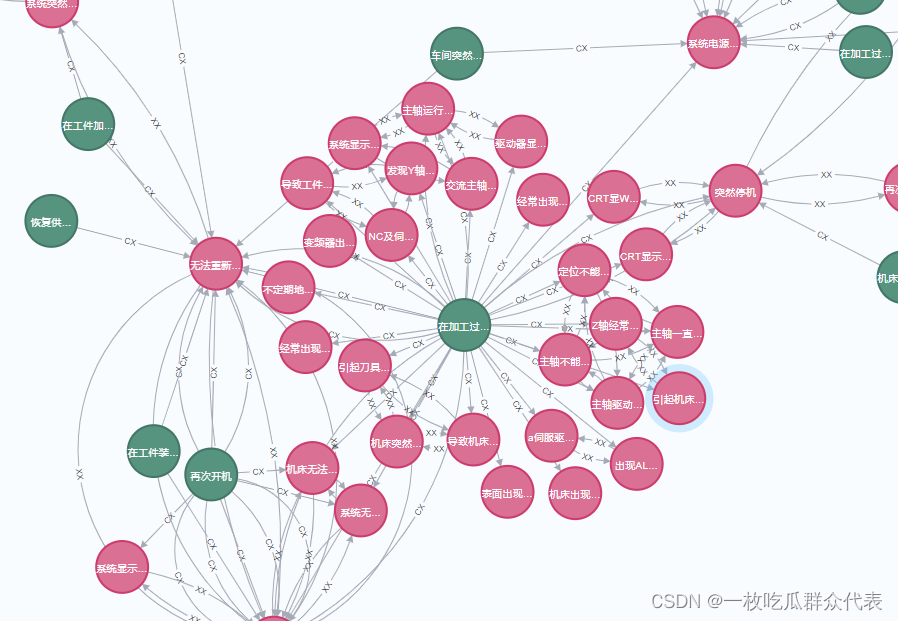
系统功能
构建的知识图谱如图:
接口设计
本系统采用前后端分离的技术,服务器端代码接收参数,处理后返回json格式的结果,前台进行展示。后端服务器采用Django框架,前台使用APICloud技术
故障诊断接口
//参数含义:pinpai:品牌 xinghao:型号 errorid:故障代码 question:故障描述 relationList:相关现象
//其中故障描述必须有,其他均可选,相关现象是在诊断出结果之后,用户反馈相关现象,再次进行诊断时用到的。多个相关现象中间用"|"分隔
http://127.0.0.1:8000/qa?pinpai=发那科&xinghao=MATE-TD&errorid=ALM401&question=自动换刀时刀链运转不到位,刀库停止运转&relationList=机床自动报警
在线分析接口:
//在线分析接口参数同故障诊断
http://127.0.0.1:8000/pa?pinpai=发那科&xinghao=MATE-TD&errorid=ALM401&question=自动换刀时刀链运转不到位,刀库停止运转&relationList=机床自动报警
问答接口:
//基于知识图谱,目前支持四类问题的问答:某故障原因会引起哪些现象?执行某操作时会遇到哪些错误?某部位常发生的故障有哪些?某故障报警的含义是什么?
http://127.0.0.1:8000/wenda?question=外部24V短路的故障会引起哪些现象
反馈接口:
http://127.0.0.1:8000/save?pinpai=发那科&xinghao=MATE-TD&errorid=ALM401&question=自动换刀时刀链运转不到位,刀库停止运转&relationList=机床自动报警&answer=使用时间较长,液压站的输出压力调得太高,导致联轴器的啮合齿损坏,从而当液压电动机旋转时,联轴器不能很好地传递转矩,从而产生异响。更换该联轴器后,机床恢复正常。
设计思路
系统的核心是围绕着构建知识库,通过拆分,将故障描述信息拆分成短文本的知识,构建关联关系。在使用过程中通过用户反馈,不断完善知识库的精度和广度。
首先,我们爬取了大量数控机床维修案例,使用NLP自然语言处理技术对文本做了噪声移除和句法分析,然后使用CNN卷积神经网络识别出了故障描述中用户所做的操作和出现的故障现象,结合词性标注,正则表达式处理等技术,最终提取出了故障描述中,对机床执行的操作,故障的现象,故障的部位,存在的报警信号。
基于Neo4j图数据库能够清晰的表示数据模型的优点,我们经过上面对故障描述的拆分和标注,表示出了做了什么操作会引起了什么故障现象,故障现象之间的并发或间接导致的关联关系,一个故障原因会间接或直接导致哪些故障现象的发生,机床的某个部位会出现的故障现象,报警代码和故障现象之间的关联,构成了知识图谱,使用基于规则的推理模型实现了我们的推理算法。
当一个新的故障发生时,通过分析,如果现有的知识不能解决新的故障,这时通过在线分析,爬取解决方案,通过用户人为反馈和语料库对比分析程序,确认结果可靠之后,分析当前的故障描述,原理同上述构建知识库的过程,拆分之后,对新的知识进行补充,对已经存在的知识,进一步完善和优化,最终实现知识库的自学习功能。
在故障诊断的过程中,类似上述的处理方法,分析故障描述,通过分析故障部位,出现的现象,所做的操作,结合知识图谱,分析出导致这些现象出现的最可能的故障原因,设置权值,然后通过CNN卷积神经网络对故障现象进行预测,对诊断出的故障结果的权值进行微调,排序之后展示给用户。
本文转载自: https://blog.csdn.net/weixin_38643701/article/details/125544214
版权归原作者 一枚吃瓜群众代表 所有, 如有侵权,请联系我们删除。
版权归原作者 一枚吃瓜群众代表 所有, 如有侵权,请联系我们删除。