
[1] Liang P P, Zadeh A, Morency L P. Foundations and recent trends in multimodal machine learning: Principles, challenges, and open questions[J]. arXiv preprint arXiv:2209.03430, 2022.
[2] Baltrušaitis T, Ahuja C, Morency L P. Multimodal machine learning: A survey and taxonomy[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(2): 423-443.
本篇文章将多模态学习的核心挑战分为六个内容: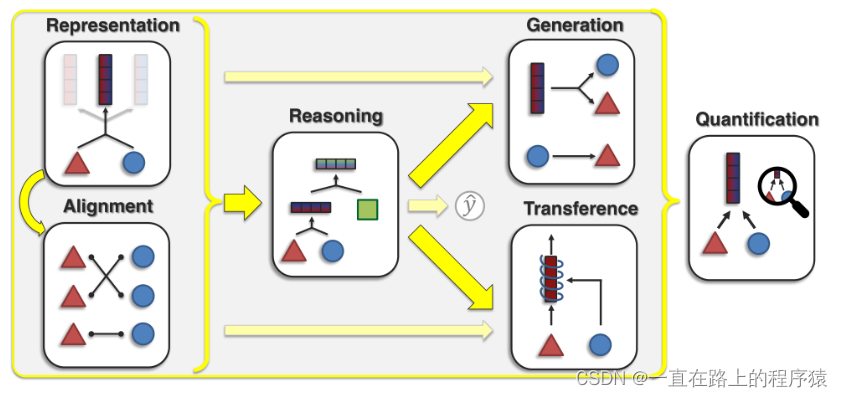
(Representation有一条指向Alignment的箭头表示Representation要使用Alignment技术。)
Representation,能否学习到能够反应多模态元素异质性和模态元素间相互联系的多模态表示?这里边有三种方法,1)representation fusion(表示融合),即融合两个或者三个模态的信息;2)representation coordination(表示协调),即跨模态的交互信息以保证表示的数量不变,从而改进多模态的上下文表示;3)representation fission(表示分裂),创建一个新的不相交的表示集合来反映多模态数据信息内部结构,比如数据聚类或者数据分解的知识。
Alignment,寻找来自两个或多个模态实例的子组件之间的关系和对应关系。
1.对齐
对齐旨在确定多种模态元素之间的联系(connections,比如相应元素的对应关系)和交互作用(interactions)。对齐方面的工作分为三个方向,Connections,Contextualized Cepresentations和Segmentation。
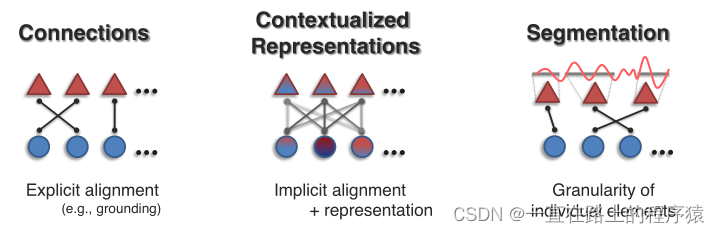
如果任务的主要建模目标是对齐两个或者多个模态的实例子组件,则为显式对齐;隐式对齐用作另一任务的中间步骤,
显示对齐,如果一个模型的优化目标是最大化多模态数据的子元素的对齐程度,则称为显示对齐,如Visual Grounding任务。无监督对齐:给定两个模态的数据作为输入,希望模型实现子元素的对齐,但是训练数据没有“对齐结果”的标注,模型需要同时学习相似度度量和对齐方式。而有监督方法存在标注,可训练模型学习相似度度量。
隐式对齐,如果模型的最终优化目标不是对齐任务,对齐过程仅仅是某个中间(或隐式)步骤,则称为隐式对齐。最受欢迎的方式是基于注意力机制的对齐,我们对两种模态的子元素间求取注意力权重矩阵,可视为隐式地衡量跨模态子元素间的关联程度。在图像描述,这种注意力被用来判断生成某个单词时需要关注图像中的哪些区域。在视觉问答中,注意力权重被用来定位问题所指的图像区域。
1.1 connections(显式对齐)
使用discrete grounding直接发现联系,或者使用continuous warping of representation spaces(表示空间的连续扭曲)发现联系。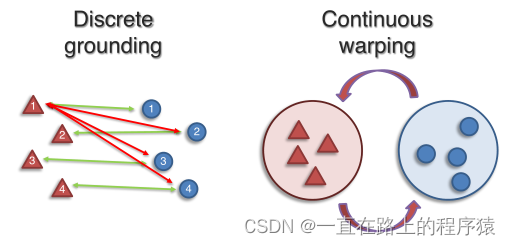
1.1.1 discrete grounding
discrete grounding适用于处理由离散单元组成的模态之间的对齐,如语言中的单词或图像、视频中物体的bounding boxes。该方法分为三种类别:Contrastive learning(对比学习),Matching algorithms(匹配算法)和Latent variable models(隐变量模型)。
对比学习:当获取有联系的模态对的监督数据时(有明显的对齐标签),对比学习是一种流行的对齐方法,其目标将不同模态中具有相同语义的表示进行匹配。
匹配算法:若真实的模态元素间的联系不可用(只给两个配对模态实体的离散单元表示,并未给这些离散单元实体的对齐监督信号),那么基于Optimal transport(最优运输)的方法是一种可行的解决办法,该类方法优化元素之间的协调函数和模态元素间的最优耦合。此类方法将对齐作为散度最小化问题,其目标是转换一组离散的源元素以匹配一组离散的目标元素。Wasserstein距离被用作该方法下的散度度量。
隐变量模型:提出隐变量图模型用于显示对齐。生成图网络被用来对齐图像中的视觉物体和其对应的单词,隐马尔可夫模型被用来对齐句子和相应的视频帧,动态贝叶斯网络被用来将讲话者和相应的视频对齐。
1.1.2 continuous warping
将不同模态元素表示为连续的表示空间(比如,将一个图片表示为连续的向量而不是用几个离散的实体向量表示),对这些连续的表示空间进行对齐。Adversarial training(对抗训练)是将一个表示空间变为另一个表示空间的常用方法(即两个空间对齐的方法)。对抗训练最初被用在域适应中,为了实现有效的域迁移,源域和目标域的数据表示不应该彼此分离,因此通过对抗训练学习到一种不能被域分类器区分域的表示,这种想法后被应用于对齐连续的多模态表示空间和多语言表示空间。
1.2 Contextualized Representations(隐式对齐)
为了学习到更好的表示,上下文表示学习用来建模所有模态的联系和交互。
上下文表示常作为一个中间步骤来使用。上下文表示的工作可以分为以下三类:joint undirected alignment(无方向对齐),cross-modal directed alignment(定向对齐)和alignment with graph networks(使用图网络的对齐)。
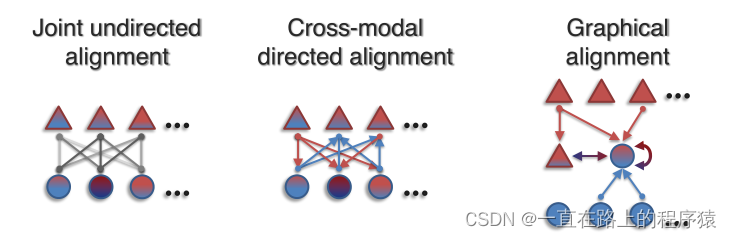
joint undirected alignment旨在捕获模态元素之间的无方向联系,模态元素之间的联系在任何一个方向上是对称的。对于一个多模态任务,通过参数化带有对齐层的模型和以端到端的方式训练以获得joint undirected alignment。对齐层可以包括注意力权重,张量积和乘法操作。在transformer模型上,对在序列维度拼接的多模态数据使用自注意力机制来执行joint undirected alignment。
cross-modal directed alignment为了将源模态的元素以定向的方式与目标模态联系起来,该方法会在建模源模态和目标模态之间不对称连接时提供额外的灵活性。该方向最近研究分为两类:Temporal attention models和Multimodal cross-attention transformers。
Temporal attention models:单模态的机器翻译,多模态的图像字幕、文本到语音等任务所使用的RNN、LSTM等模型中加入注意力机制捕获输入序列和输出序列的alignment,这些注意力机制通常是单方向的,即从输出模态到输入模态,以至于结果权重可以反映输入序列中的某一个内容在输入序列中的分布。
Multimodal cross-attention transformers:使用query-key-vlue的注意力机制实现多模态的交叉注意力实现定向对齐(双流模型)。
alignment with graph networks,上下文的表示可以通过图网络进行学习。图网络有几个好处:不需要连接所有的模态元素,允许用户为不同的模态连接选择不同的边函数。alignment with graph networks的解决方案是使用图神经网络迭代地学习以局部连通区域中的模态元素为上下文的模态元素的表示。上下文化可以通过平均池化、图卷积或者图注意力执行。
1.3 Segmentation
1.1和1.2有一个重要的假设是模态元素已被分割和离散化。做这样的假设是因为模态的联系和交互作用更容易在离散的模态元素上定义。但是在一些情况不容易提供分割,比如连续信号(金融或者医疗时间序列),时空数据(卫星和天气图像),或是没有明确语义边界的数据(MRI图像,即核磁共振图像)。
Segmentation旨在解决对齐过程中分割和元素粒度的不确定性问题,分为两个方向,Modality Segmentation(模态分割)和Discretization(离散)。
Modality Segmentation是将高维的多模态数据细分为具有语义含义边界的模态元素。常见的问题是时间分割,目的是发现时序数据之间的时间边界,比如将文本中的每个单词与录音中说它的时间边界对齐。forced alignment是时间分割的一种流行方法,将离散的语音单元与文本中的单个单词对齐。该方法利用声学模型将语音片段与文本中相应的单词或者短语对齐。
Dynamic time warping(DTW,动态时间扭曲)是一种分割和对齐多视图时间序列数据的方法,该方法通过时间扭曲(插入帧)的方式衡量两个序列的相似性质并寻找最优匹配。DTW要求两个序列中的时间步长具有可比性,并要求它们之间具有相似性度量。对于多模态任务,若使用DTW方法,需要设计模态之间的相似度度量。目前为止该方法被应用到了文本-语音、视觉-文本模态上。
Discretization是将连续的变量、模型或者函数转变为相应离散的对应对象的过程。离散化问题可以通过聚类(clustering),基于语义相似度对连续的数据进行分组解决。最近为了将基于语言的预训练泛化到基于视频或者音频的预训练,基于聚类的离散化成为了一个重要的预处理步骤,通过该步骤,原始的视频特征和音频特征聚集到一个离散的集合中,使得VideoBERT和HuBERT可以在原始的视频和音频数据上执行掩码预训练。
2.图文中所用的对齐方法
- 机器学习方法(最优运输方法(显式对齐方法)、生成图模型(需要手工构建映射关系))
- 注意力机制(单流模型中的自注意力机制,双流模型中的交叉注意力机制)(隐式对齐方法)
- 对比学习(设计各种各样的目标函数)(隐式对齐方法)
- 对抗训练(显示对齐方法)
版权归原作者 BBBBBAAAAAi 所有, 如有侵权,请联系我们删除。