
作为数据科学家,使用正确的工具和技术来最大限度地利用数据是很重要的。Pandas是数据操作、分析和可视化的重要工具,有效地使用Pandas可能具有挑战性,从使用向量化操作到利用内置函数,这些最佳实践可以帮助数据科学家使用Pandas快速准确地分析和可视化数据。

在本文中,我们将重点介绍在DataFrame上经常执行的两个最常见的任务,特别是在数据科学项目的数据操作阶段。这两项任务是有效地选择特定的和随机的行和列,以及使用replace()函数使用列表和字典替换一个或多个值。
在本文中,我们将使用下面的数据集:
- 扑克牌游戏数据集
- 婴儿名字数据集
我们使用的第一个数据集是扑克牌游戏数据集,如下所示。
poker_data = pd.read_csv('poker_hand.csv')
poker_data.head()
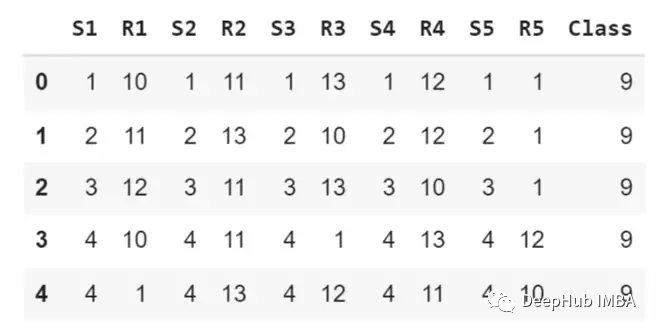
在每个回合中,每个玩家手里有五张牌,每一张牌都有花色:红心、方块、梅花或黑桃,以及它的数字,范围从1到13。该数据集由一个人可以拥有的五张卡片的每一种可能组合组成。
Sn:第n张牌的符号,其中:1(红心),2(方块),3(梅花),4(黑桃)
Rn:第n张牌的排名,其中:1(王牌),2-10,11(J),12(Q),13(K)
第二个数据集是流行的婴儿名字数据集,其中包括2011年至2016年间最流行的新生儿名字:
names = pd.read_csv('Popular_Baby_Names.csv')
names.head()

该数据集还包括按年份、性别和种族划分的美国最受欢迎的名字。例如,2011年,Chloe 这个名字在所有亚裔和太平洋岛民女性新生儿中排名第二。
下面我们开始进入正题
为什么需要高效的代码?
高效代码是指执行速度更快、计算容量更低的代码。在本文中,我们将使用time()函数来测量计算时间,我们通过在执行前和执行后获取时间,然后计算其差值获得代码的执行时间。下面是一个简单的例子:
import time
# record time before execution
start_time = time.time()
# execute operation
result = 5 + 2
# record time after execution
end_time = time.time()
print("Result calculated in {} sec".format(end_time - start_time))
让我们看一个提高代码运行时间并降低计算时间复杂度的示例:我们将计算每个数字的平方,从0到100万。首先,我们将使用列表推导式来执行此操作,然后使用for循环重复相同的过程。
首先使用列表推导式:
#using List comprehension
list_comp_start_time = time.time()
result = [i*i for i in range(0,1000000)]
list_comp_end_time = time.time()
print("Time using the list_comprehension: {} sec".format(list_comp_end_time -
list_comp_start_time))

使用for循环来执行相同的操作:
# Using For loop
for_loop_start_time= time.time()
result=[]
for i in range(0,1000000):
result.append(i*i)
for_loop_end_time= time.time()
print("Time using the for loop: {} sec".format(for_loop_end_time - for_loop_start_time))
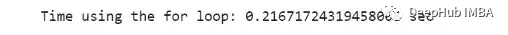
可以看到它们之间有很大的差异,我们可以用百分比来计算它们之间的差异:
list_comp_time = list_comp_end_time - list_comp_start_time
for_loop_time = for_loop_end_time - for_loop_start_time
print("Difference in time: {} %".format((for_loop_time - list_comp_time)/
list_comp_time*100))
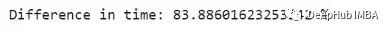
可以看到仅仅使用了不同的方法,但是在执行效率方面有了很大的不同。
使用.iloc[]和.loc[]选择行和列
这里我们将介绍如何使用.iloc[] & .loc[] pandas函数从数据中高效地定位和选择行。我们将使用iloc[]作为索引号定位器,使用loc[]作为索引名定位器。
在下面的例子中,我们选择扑克数据集的前500行。首先使用.loc[]函数,然后使用.iloc[]函数。
rows = range(0, 500)
# Time selecting rows using .loc[]
loc_start_time = time.time()
poker_data.loc[rows]
loc_end_time = time.time()
print("Time using .loc[] : {} sec".format(loc_end_time - loc_start_time))
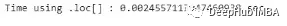
rows = range(0, 500)
# Time selecting rows using .iloc[]
iloc_start_time = time.time()
poker_data.iloc[rows]
iloc_end_time = time.time()
print("Time using .iloc[]: {} sec".format(iloc_end_time - iloc_start_time))
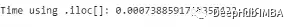
loc_comp_time = loc_end_time - loc_start_time
iloc_comp_time = iloc_end_time - iloc_start_time
print("Difference in time: {} %".format((loc_comp_time - iloc_comp_time)/
iloc_comp_time*100))
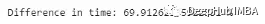
虽然这两个方法使用的方式是相同的,但iloc[]的执行速度比loc[]快近70%。这是因为.iloc[]函数利用了索引的顺序,索引已经排序因此速度更快。
我们还可以使用它们来选择列,而不仅仅是行。在下一个示例中,我们将使用这两种方法选择前三列。
iloc_start_time = time.time()
poker_data.iloc[:,:3]
iloc_end_time = time.time()
print("Time using .iloc[]: {} sec".format(iloc_end_time - iloc_start_time))
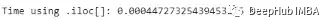
names_start_time = time.time()
poker_data[['S1', 'R1', 'S2']]
names_end_time = time.time()
print("Time using selection by name: {} sec".format(names_end_time - names_start_time))

loc_comp_time = names_end_time - names_start_time
iloc_comp_time = iloc_end_time - iloc_start_time
print("Difference in time: {} %".format((loc_comp_time - iloc_comp_time)/
loc_comp_time*100))
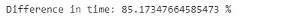
可以看到,使用.iloc[]进行列索引仍然要快80%。所以最好使用.iloc[],因为它更快,除非使用loc[]更容易按名称选择某些列。
替换DF中的值
替换DataFrame中的值是一项非常重要的任务,特别是在数据清理阶段。
让我们来看看之前加载的婴儿名字数据集:

首先看看性别列:
names['Gender'].unique()
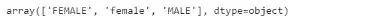
我们可以看到,女性用大写和小写两个值表示。这在实际数据中非常常见,但是对于我们来说只需要一个统一的表示就可以了,所以我们需要将其中一个值替换为另一个值。这里有两种方法,第一种是简单地定义我们想要替换的值,然后我们想用什么替换它们。如下面的代码所示:
start_time = time.time()
names['Gender'].loc[names.Gender=='female'] = 'FEMALE'
end_time = time.time()
pandas_time = end_time - start_time
print("Replace values using .loc[]: {} sec".format(pandas_time))
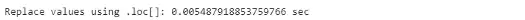
第二种方法是使用panda的内置函数.replace(),如下所示:
start_time = time.time()
names['Gender'].replace('female', 'FEMALE', inplace=True)
end_time = time.time()
replace_time = end_time - start_time
print("Time using replace(): {} sec".format(replace_time))

可以看到,与使用.loc()方法查找值的行和列索引并替换它相比,内置函数的快了157%。
print('The differnce: {} %'.format((pandas_time- replace_time )/replace_time*100))
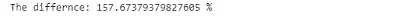
我们还可以使用列表替换多个值。比如说将所有WHITE NON-HISPANIC或WHITE NON-HISP都改为WNH。这里我们使用.loc[]函数和' or '语句定位我们正在寻找的种族。然后进行替换赋值。
start_time = time.time()
names['Ethnicity'].loc[(names["Ethnicity"] == 'WHITE NON HISPANIC') |
(names["Ethnicity"] == 'WHITE NON HISP')] = 'WNH'
end_time = time.time()
pandas_time= end_time - start_time
print("Results from the above operation calculated in %s seconds" %(pandas_time))
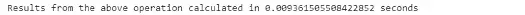
或者使用pandas内置.replace() 函数执行相同的操作,如下所示:
start_time = time.time()
names['Ethnicity'].replace(['WHITE NON HISPANIC','WHITE NON HISP'],
'WNH', inplace=True)
end_time = time.time()
replace_time = end_time - start_time
print("Time using .replace(): {} sec".format(replace_time))
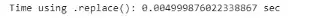
我们可以再次看到,使用.replace()方法比使用.loc[]方法快得多。为了更好地直观地了解它有多快,让我们运行下面的代码:
print('The differnce: {} %'.format((pandas_time- replace_time )/replace_time*100))
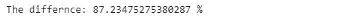
.replace()方法比使用.loc[]方法快87%。如果数据很大,需要大量的清理,它将有效的减少数据清理的计算时间,并使pandas代码更快。
最后,我们还可以使用字典替换DataFrame中的单个值和多个值。如果想在一个命令中使用多个替换函数,这将是非常有用的。
我们要用字典把每个男性的性别替换为BOY,把每个女性的性别替换为GIRL。
names = pd.read_csv('Popular_Baby_Names.csv')
start_time = time.time()
names['Gender'].replace({'MALE':'BOY', 'FEMALE':'GIRL', 'female': 'girl'}, inplace=True)
end_time = time.time()
dict_time = end_time - start_time
print("Time using .replace() with dictionary: {} sec".format(dict_time))
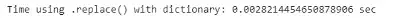
names = pd.read_csv('Popular_Baby_Names.csv')
start_time = time.time()
names['Gender'].replace('MALE', 'BOY', inplace=True)
names['Gender'].replace('FEMALE', 'GIRL', inplace=True)
names['Gender'].replace('female', 'girl', inplace=True)
end_time = time.time()
list_time = end_time - start_time
print("Time using multiple .replace(): {} sec".format(list_time))
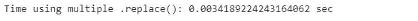
比较这两种方法,可以看到使用字典的运行速度快了大约22%。
使用字典可以替换几个不同列上的相同值。我们想把所有种族分成三大类:黑人、亚洲人和白人。这里的代码也非常简单。使用嵌套字典:外键是我们要替换值的列名。值是另一个字典,其中的键是要替换的字典。
start_time = time.time()
names.replace({'Ethnicity': {'ASIAN AND PACI': 'ASIAN', 'ASIAN AND PACIFIC ISLANDER': 'ASIAN',
'BLACK NON HISPANIC': 'BLACK', 'BLACK NON HISP': 'BLACK',
'WHITE NON HISPANIC': 'WHITE', 'WHITE NON HISP': 'WHITE'}})
print("Time using .replace() with dictionary: {} sec".format (time.time() - start_time))
总结
- 使用.iloc[]函数可以更快地选择行和列并且它比loc[]要快,但是loc[] 提供了一些更方便的功能,如果速度不是优先考虑或者iloc[]实现的比较麻烦的话,再考虑使用loc[]。
- 使用内置的replace()函数比使用传统方法快得多。
- 使用python字典替换多个值比使用列表更快。
作者:Youssef Hosni