
💟作者简介:大家好呀!我是路遥叶子,大家可以叫我叶子哦!❣️
📝个人主页:【路遥叶子的博客】
🏆博主信息:四季轮换叶,一路招摇胜!
专栏【安利Java零基础】 【数据结构-Java语言描述】🐋希望大家多多支持😘一起进步呀!~❤️
🌈若有帮助,还请【关注➕点赞➕收藏】,不行的话我再努力努力呀!💪
————————————————
⚡版权声明:本文由【路遥叶子】原创、在CSDN首发、需要转载请联系博主。
🍁想寻找共同成长的小伙伴,请点击【Java全栈开发社区】

前言


概念1:什么是路径?
在一棵树中,从一个结点到另一个结点所经过的所有结点,被我们称为两个结点之间的路径。
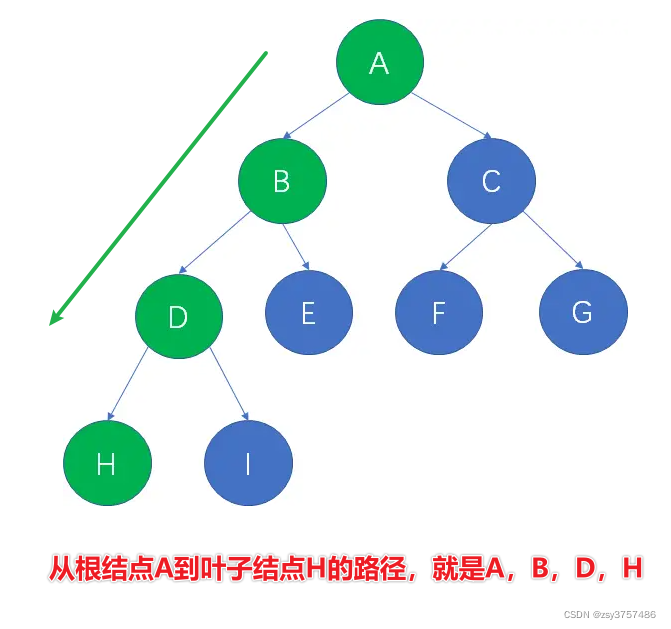
概念2:什么是路径长度?
在一棵树中,从一个结点到另一个结点所经过的“边”的数量,被我们称为两个结点之间的路径长度。

概念3:什么是结点的权?
在实际应用中,人们往往会给树中的每一个结点赋予一个具有某种实际意义的数值,这个数值被称为该结点的权值。

概念4:什么是结点的带权路径长度?
树的每一个结点,都可以拥有自己的“权重”(Weight),权重在不同的算法当中可以起到不同的作用。
结点的带权路径长度,是指树的根结点到该结点的路径长度与该结点的权值的乘积。

概念5:什么是 树的带权路径长度?
在一棵树中,所有叶子结点的带权路径长度之和,被称为树的带权路径长度,也被简称为WPL。



哈夫曼树是由麻省理工学院的哈夫曼博士于1952年发明,这到底是一颗什么样的树呢?
刚才我们学习了树的带权路径长度(WPL),而哈夫曼树(Huffman Tree)是在叶子结点和权重确定的情况下,带权路径长度最小的二叉树,也被称为最优二叉树。
🐋最优二叉树(哈夫曼树)
- 给定n个权值并作为n个叶结点,按一定规则构造一颗二叉树,使其带权路径长度达到最小值,则这棵二叉树被称为最优二叉树,也称为哈夫曼树。
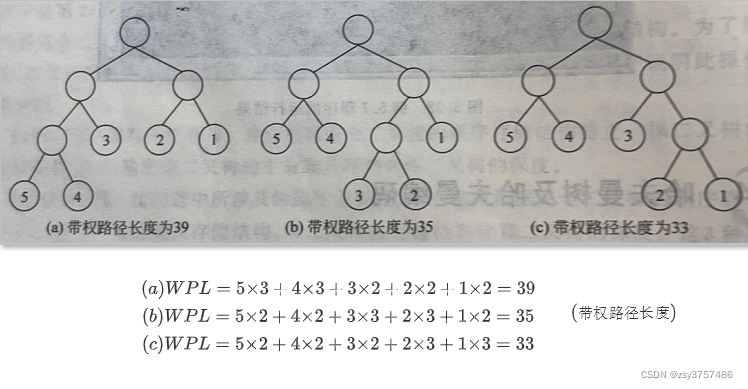
- 同一组数据的最优二叉树不唯一,因为没有限定左右子树,并且有权值重复时,可能树的高度都不唯一,唯一的只是带权路径长度之和最小。 构建哈夫曼树的时候即可以推导出。
🐋构建哈夫曼树
(1) 由已知给定的n个权值{w1,w2,w3,...,wn},构建一个有n棵二叉树所构建的森林
F={T1,T2,T3,...Tn},其中每一棵二叉树中只含一个带权值为wi根节点,其左、右子树为空
(2) 在二叉树森林F中选取根节点的权值最小和次小的两棵二叉树,分别把它们作为左子树和右子树
去构建一颗新二叉树,新二叉树的根节点权值为其左右子树根节点的权值之和。
(3) 作为新二叉树的左右子树的这两棵二叉树从森林F中删除,同时加入刚生成的新二叉树
(4) 重复步骤(2)和(3),直到森林F中只剩一颗二叉树为止,该二叉树就是哈夫曼树。
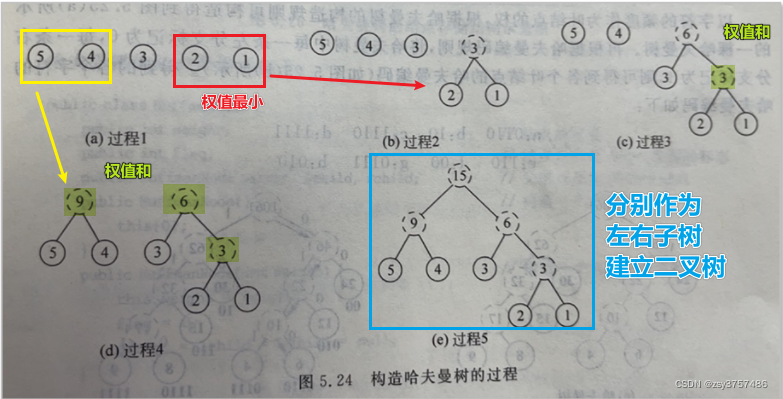
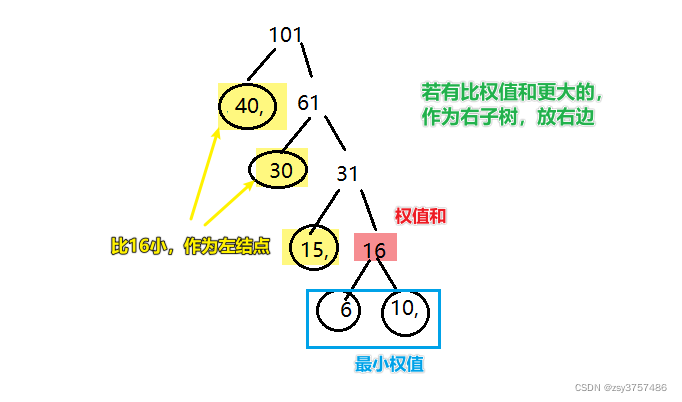
练习:
有5个带权结点 {A,B,C,D,E},其权值分别为W={10,30,40,15,6},权值作为结点数据,绘制一颗哈夫曼 。
🐋哈夫曼编码
- 编码诉求:对字符集进行二进制编码,使得信息的传输量最小。如果能对每一个字符用不同的长度的二进制编码,并且尽可能减少出现次数最多的字符的编码位数,则信息传送的总长度便可以达到最小。
- 哈夫曼编码:用电文中各个字符使用的频度作为叶结点的权,构造一颗具有最小带权路径长度的哈夫曼树,若对树中的每个**==*左分支赋予标记0,右分支赋予标记1*==**,则从根节点到每个叶结点的路径上的标记连接起来就构成一个二进制串,该二进制串被称为哈夫曼编码。
- 例题讲解:
** 已知在一个信息通信联络中使用了8个字符:a、b、c、d、e、f、g和h,每个字符的使用频度分别为:6、30、8、9、15、24、4、12,试设计各个字符的哈夫曼编码。**
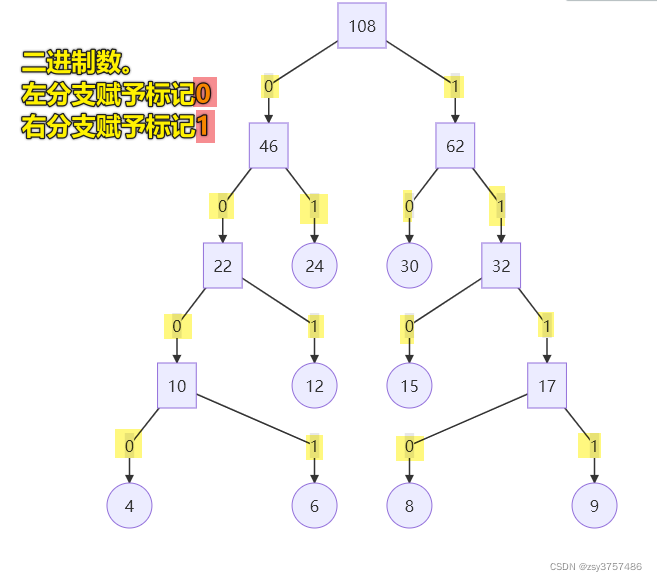

- 哈夫曼树进行译码- 哈夫曼编码是一种前缀码,任何一个字符的编码都不是同一个字符集中另一个字符的编码的前缀。- 译码过程是编码过程的逆过程。从哈夫曼树的根开始,从左到右把二进制编码的每一位进行判别,若遇到0,则选择左分支走向下一个结点;若遇到1,则选择右分支走向下一个结点,直至到达一个树叶结点,便求得响应字符。
练习:
** 有5个带权结点{A,B,C,D,E},其权值分别为W={10,30,40,15,6},权值作为结点数据,绘制一颗哈夫曼,并编写哈夫曼编码。**
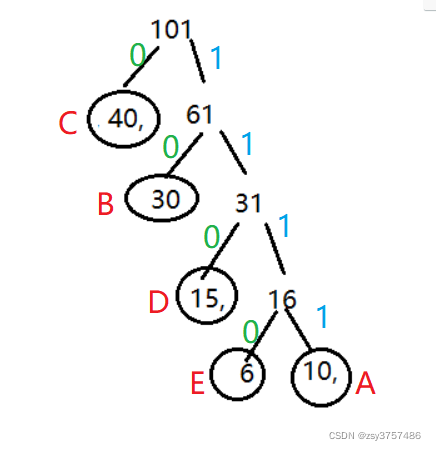
A:1111
B:10
C:0
D:110
E:1110
编码:编码字符串 AABBEDCC-->111111111010111011000
🐋哈夫曼编码类【算法实现】
- n个权值,组成哈夫曼树节点个数:2n-1
哈夫曼结点类 :
public class HuffmanNode {
public int weight;// 权值
public int flag; // 节点是否加入哈夫曼树的标志
public HuffmanNode parent,lchild,rchild; // 父节点及左右孩子节点
// 构造一个空节点
public HuffmanNode(){
this(0);
}
// 构造一个具有权值的节点
public HuffmanNode(int weight){
this.weight = weight;
flag=0;
parent=lchild=rchild=null;
}
}
哈夫曼编码类 :
public class HuffmanTree {
// 求哈夫曼编码的算法,w存放n个字符的权值(均>0)
public int[][] huffmanCoding(int[] W){
int n = W.length; // 字符个数
int m = 2*n -1; //哈夫曼树的节点数
// 构造n个具有权值的节点
HuffmanNode[] HN = new HuffmanNode[m];
int i = 0;
for (; i<n ; i++) {
HN[i] = new HuffmanNode(W[i]);
}
// 创建哈夫曼树
for (i = n; i<m ; i++) {
// 在HN[0...1]选择不在哈夫曼树中,且权值weight最小的两个节点min1和min2
HuffmanNode min1 = selectMin(HN,i-1);
min1.flag = 1;
HuffmanNode min2 = selectMin(HN,i-1);
min2.flag = 1;
// 构造 min1和min2的父节点,并修改父节点的权值
HN[i] = new HuffmanNode();
min1.parent=HN[i];
min2.parent=HN[i];
HN[i].lchild = min1;
HN[i].rchild = min2;
HN[i].weight = min1.weight+min2.weight;
}
// 从叶子到根 逆向求每个字符的哈夫曼编码
int[][] HuffCode = new int[n][n]; // 分配n个字符编码存储空间
for (int j =0;j<n;j++){
// 编码的开始位置,初始化为数组的结尾
int start = n-1;
// 从叶子节点到根,逆向求编码
for(HuffmanNode c = HN[j],p=c.parent;p!=null;c=p,p=p.parent){
if(p.lchild.equals(c)){
HuffCode[j][start--]=0;
}else{
HuffCode[j][start--]=1;
}
}
// 编码的开始标志为-1,编码是-1之后的01序列
HuffCode[j][start] = -1;
}
return HuffCode;
}
// 在HN[0...1]选择不在哈夫曼树中,且权值weight最小的两个节点min1和min2
private HuffmanNode selectMin(HuffmanNode[] HN, int end) {
// 求 不在哈夫曼树中, weight最小值的那个节点
HuffmanNode min = HN[end];
for (int i = 0; i < end; i++) {
HuffmanNode h = HN[i];
// 不在哈夫曼树中, weight最小值
if(h.flag == 0 && h.weight<min.weight){
min = h;
}
}
return min;
}
}
哈夫曼编码会用类似如下格式进行存储 :
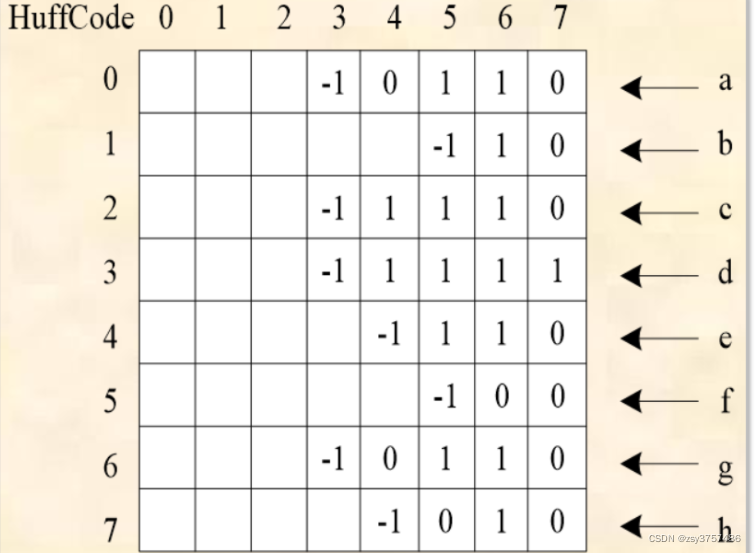
** 测试类 :**
public class Demo02 {
public static void main(String[] args) {
// 一组权值
int[] W = {6,30,8,9,15,24,4,12};
// 创建哈夫曼树
HuffmanTree tree = new HuffmanTree();
// 求哈夫曼编码
int[][] HN = tree.huffmanCoding(W);
//打印编码
System.out.println("哈夫曼编码是: ");
for (int i = 0; i < HN.length; i++) {
System.out.print(W[i]+" ");
for (int j = 0; j < HN[i].length; j++) {
if(HN[i][j] == -1){
for (int k = j+1; k <HN[i].length ; k++) {
System.out.print(HN[i][k]);
}
break;
}
}
System.out.println();
}
}
}
如果文章对您有帮助,就拿起小手赶紧给博主点赞💚评论❤️收藏💙 一下吧!

想要了解更多吗?没时间解释了,快来点一点!
路遥叶子的博客_CSDN博客-数据结构,安利Java零基础,spring领域博主路遥叶子擅长数据结构,安利Java零基础,spring,等方面的知识https://blog.csdn.net/zsy3757486?spm=1000.2115.3001.5343
版权归原作者 路遥叶子 所有, 如有侵权,请联系我们删除。