
0 提纲
- 概述
- SQL注入方法
- SQL注入的检测方法
- SQL语句的特征提取
- 天池AI上的实践
1 概述
SQLIA:SQL injection attack SQL 注入攻击是一个简单且被广泛理解的技术,它把 SQL 查询片段插入到 GET 或 POST 参数里提交到网络应用。
由于SQL数据库在Web应用中的普遍性,使得SQL攻击在很多网站上都可以进行。并且这种攻击技术的难度不高,但攻击变换手段众多,危害性大,使得它成为网络安全中比较棘手的安全问题。
1.1 当前发展水平与现状
SQLIA 被大量关注并有丰富的文献。
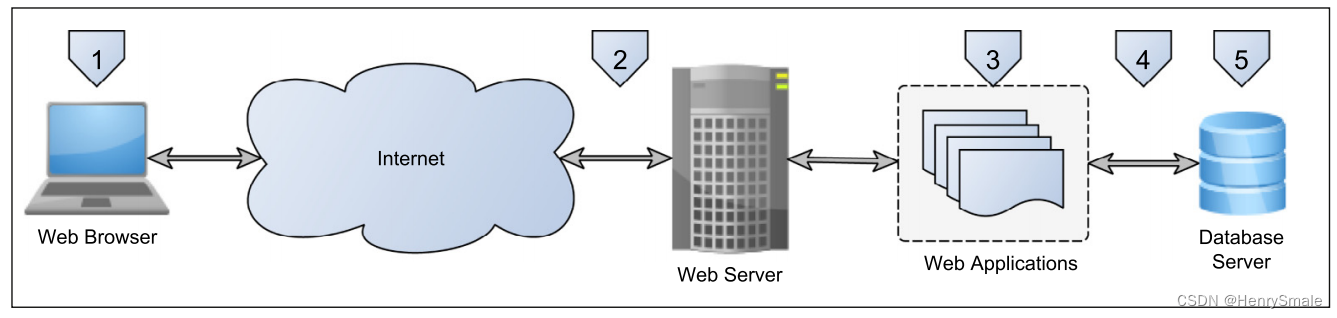
基于端到端的网站应用架构的 5 个关键层:
- 客户端
- 网络应用防火墙(WAF)
- 网络应用
- 数据库防火墙
- 数据库服务器
2 SQL注入方法
发生于Web+数据库的应用架构中。
Web页面存在注入点,如一个登录页面: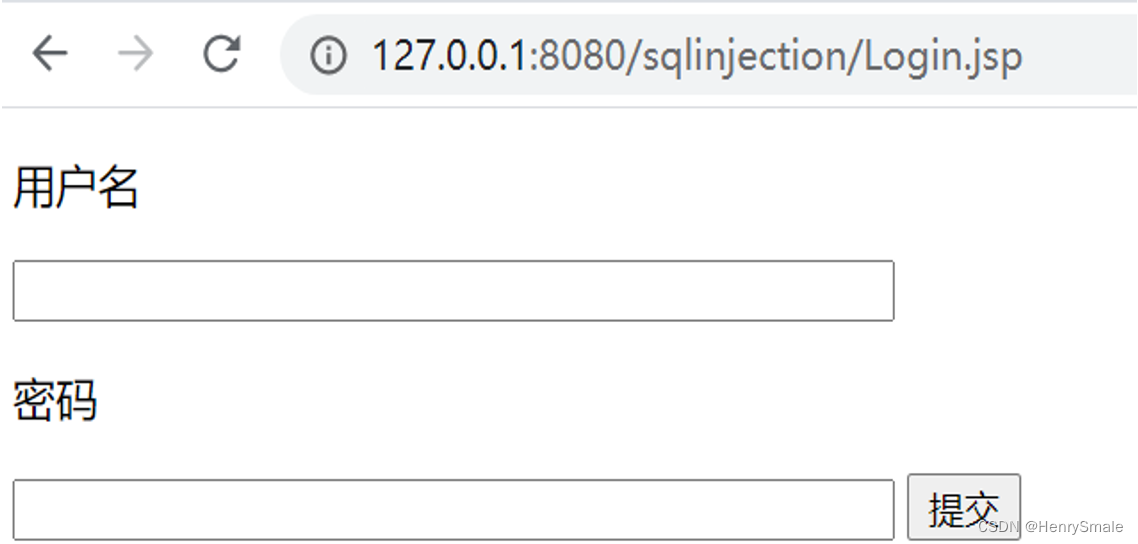
假如对登录用户身份进行合法性验证的SQL语句为:
select*fromuserwhere name = ‘{$name}’ and password ={$password}
攻击者即使没有该网站的用户账号和密码,也可能绕过账号验证而获得相应登录权限。
只需在登录提交表单中,用户名输入一个随意的字符串,如asndfas,密码框输入1 or 2=2。从而生成如下的注入SQL:
select*fromuserwhere username='asndfas'and passwd=1or2=2
由于2=2的条件恒成立,因此SQL执行的结果是返回user表中的所有记录。
利用注入SQL语句来进行数据库结构的猜测。例如攻击者想知道数据库中是否存在指定的表或表的字段名,在确定用户名/密码为bbb/2345的情况下,可以构建如下SQL语句来检查users表中是否存在emails字段:
select*from users where username='bbb'and passwd=2345andexists(select emails from users)
攻击者可以执行一些数据库操作,导致数据丢失。在密码框中输入2345; drop table tmp,从而形成了如下的注入SQL,其中注入的分号是将SQL指令分成多条指令执行。
select*from users where username='bbb'and passwd=2345;droptable tmp
当用户bbb具有数据库执行drop table的权限时,这条语句会实现删除tmp表的操作。也可以使用update等语句对数据表信息进行修改。由此会产生严重的数据库安全问题。
3 SQL注入的检测方法
SQL注入的检测通常要对输入的内容进行校验,其中较为有效的是对请求数据格式或者内容进行规则处理。目前主要的检测方法有:
- 针对特定类型的检查;
- 对特定格式的检查;
- SQL预编译的防御方法;
- 机器学习方法。
3.1 针对特定类型的检查
考虑到SQL注入是在特定的Web页面输入框中实现的,每个输入有其特定的格式要求。因此可以对页面变量的数据类型、数据长度、取值格式、取值范围等进行检查。例如:
where id = {$id}
对于输入的id进行类型检查。只有当这些要求都通过检查之后,才把请求发送到数据集执行。
优点:
- 对有特定数据格式输入可以起到防SQL注入的作用。
缺点:
- 局限性较大:只能对特定数据格式输入起作用,存在较大的遗漏或不准确;
- 工作量较大:对每个网页程序接口输入都进行格式判断。
3.2 对特定格式的检查
对于格式有明确要求的输入,如邮箱或电话等,可以采用正则表达式过滤方法,排除不符合要求的变量。
一些常见的注入也可以采用正则表达式过滤方法。例如对于
' or1=1
这样的注入,可以用如下正则表达式进行过滤:
('\s+)? or\s +[[:alnum:]]+\s *= \s *[[:alnum:]]+\s *(--)?
只要拒绝符合该正则表达式的输入即可达到防止SQL注入的目的。
优点:
- 可以过滤已知的各种注入方法。
缺点:
- 不能过滤未知的注入;
- 这种方法也会将带有符合过滤正则表达式的合法输入过滤掉,例如用户博客中的某一个句子带有’ or 1 = 1 --,那么这个句子会被错误过滤掉。
3.3 SQL预编译的防御方法
SQL预编译的基本思想是创建SQL语句模板,将参数值用“?”代替,例如:
selectfromtablewhere id = ?
然后通过语法树分析、查询计划生成、缓存到数据库。这种方式不论输入内容包含什么,总是被当作字符串。这样用户传进来的参数只能被视为字符串用于查询,而不会被嵌入SQL中去执行语法分析。
一些Web框架如Hibernate、MyBatis等已经实现了参数化查询,是目前比较有效防止SQL注入的方法。
3.4 机器学习方法
机器学习方法把SQL注入检测看作一个二分类问题,从而按照机器学习的一般流程进行设计。主要环节包括:
- 训练数据集收集与标注;
- 特征提取;
- 分类器选择与训练;
- 执行分类。
4 SQL语句的特征提取
使用机器学习进行SQL注入的检测,首先需要解决SQL语句特征表示的问题。主要的方法有基于图论的方法,基于文本分析的方法。
4.1 基于图论的方法
基于图论的方法把SQL查询建模成标记图,进而生成以标记为节点、节点间的交互为带权边的图,利用该图实现SQL语句的转换和表示。
4.1.1 节点标记
定义SQL语句中的标记(Token),把SQL中的关键字、标识符、操作符、分隔符、变量以及其他符号都称为标记。
一条SQL查询,无论是真正的查询还是注入的查询,都是一个标记序列。
检测的基本思路就是,对真正查询和注入查询的序列进行特征提取,然后在特征空间中构建识别注入查询的分类器模型。
定义映射表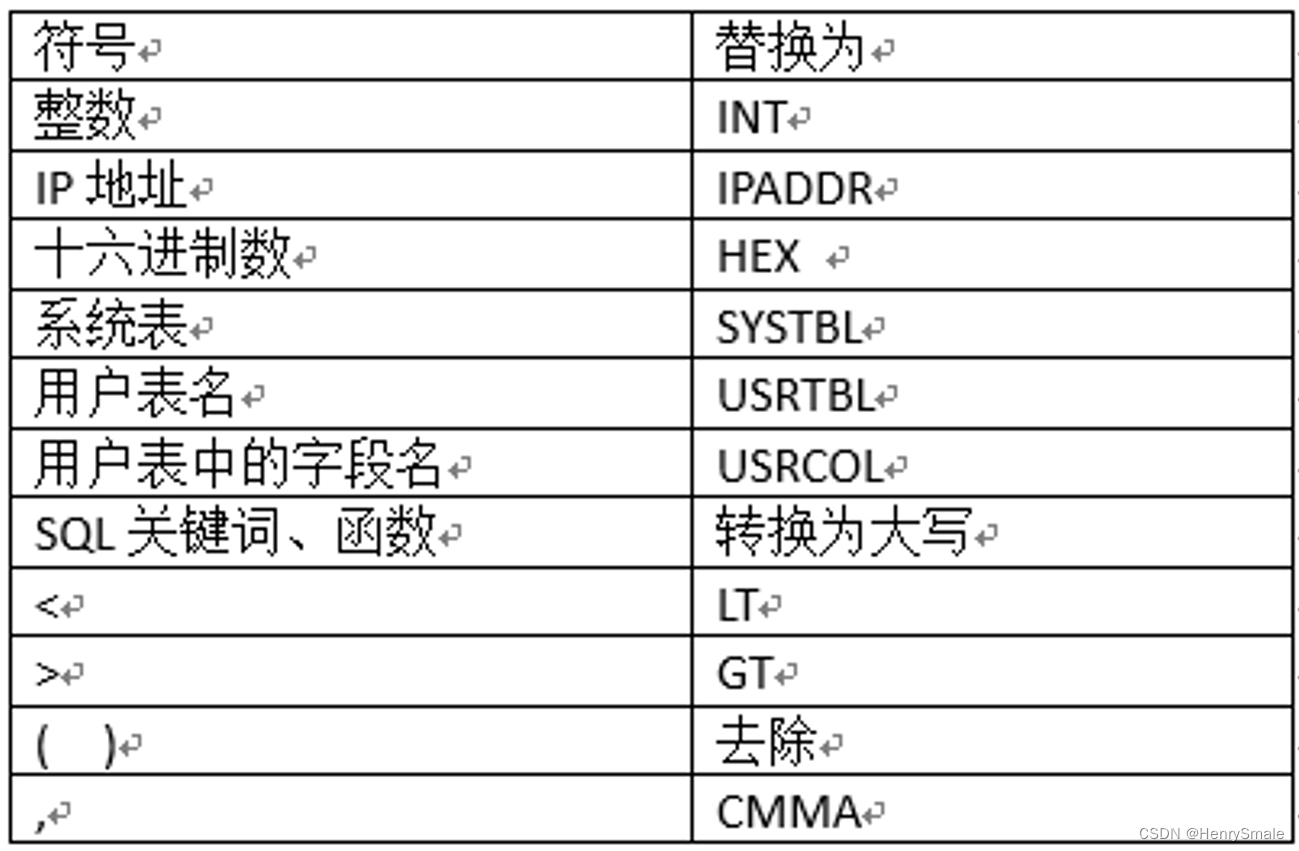


对于一条SQL语句,使用token对照表进行转换,同时对语句做特殊处理:
- (1) 对能够匹配的括号对进行删除;对不能匹配的括号给予保留,并转化成标记;
- (2)可以删除空注释(包含只有空白字符的注释),但非空注释必须保留。这是因为攻击者通常在注入代码中嵌入空注释来做混淆(例如/**/ OR / ** /1/ ** / = / ** /1),企图绕过检测。
两个例子:
(1)
select*from books where price>20.5and discount<0.8
规范化为:
SELECT STAR FROM USRTBL WHERE USRCOL GT DECAND USRCOL LT DEC
(2)
selectcount(*),sum(amount)from orders orderbysum(amount)
规范化为:
SELECT COUNT STAR CMMA SUM USRCOL FROM USRTBL ORDERBY SUM USRCOL
最终,构建了686个不同的标记。每个标记都被看作最终数据集中的一个属性(维度)。
4.1.2 图的构建
可以构造的图种类包括:有向图/无向图, 含权图/无权图。
定义(标记图):标记图是一个有权图
G
=
(
V
,
E
,
w
)
G = (V, E, w)
G=(V,E,w),其中
V
V
V的每个顶点对应一个规范化序列中的标记,
E
E
E是边的集合,
w
w
w是一个定义边权重的函数。如果
t
i
t_i
ti和
t
j
t_j
tj在一个长度为
s
s
s个标记的滑动窗口中同时出现,则称在标记
t
i
t_i
ti和
t
j
t_j
tj间有一条权重为
w
i
j
w_{ij}
wij的边。如果在滑动过程中,
t
i
t_i
ti和
t
j
t_j
tj间已经有一条边了,则它的权重要加上新的权重。
定义(无向图):在无向标记图中,如果标记
t
i
t_i
ti和
t
j
t_j
tj中有一条边,那么它具有对称的权重
w
i
j
=
w
j
i
w_{ij} = w_{ji}
wij=wji。如果在同一个长度为
s
s
s个标记的滑动窗口中出现了
t
i
t_i
ti和
t
j
t_j
tj,不进行权重累加。
定义(有向图):在有向标记图中,当一个长度为
s
s
s个标记的窗口滑过时,如果
t
i
t_i
ti出现在
t
j
t_j
tj之前,则认为
t
i
→
t
j
t_i \rightarrow t_j
ti→tj形成一条权重为
w
i
j
w_{ij}
wij的边。边
t
i
→
t
j
t_i \rightarrow t_j
ti→tj和
t
j
→
t
i
t_j \rightarrow t_i
tj→ti的权重是独立计算的。
计算含权图中两个节点间连接权重的两种加权方法如下:
(1)在
s
s
s滑动窗口内,每个标签具有相同的权重;
(2)在
s
s
s滑动窗口内,离得近的标签权重大,离得远的标签权重小。
例:第一个标记在滑动窗口内与后续标记的连接关系及权重,下面例子每个边的权重置为1, 生成的是无权图:
下面例子每个边的权重根据距离目标标记的远近按比例进行设置, 生成的是含权图:
最终,对一个SQL查询可以转换成为标记图: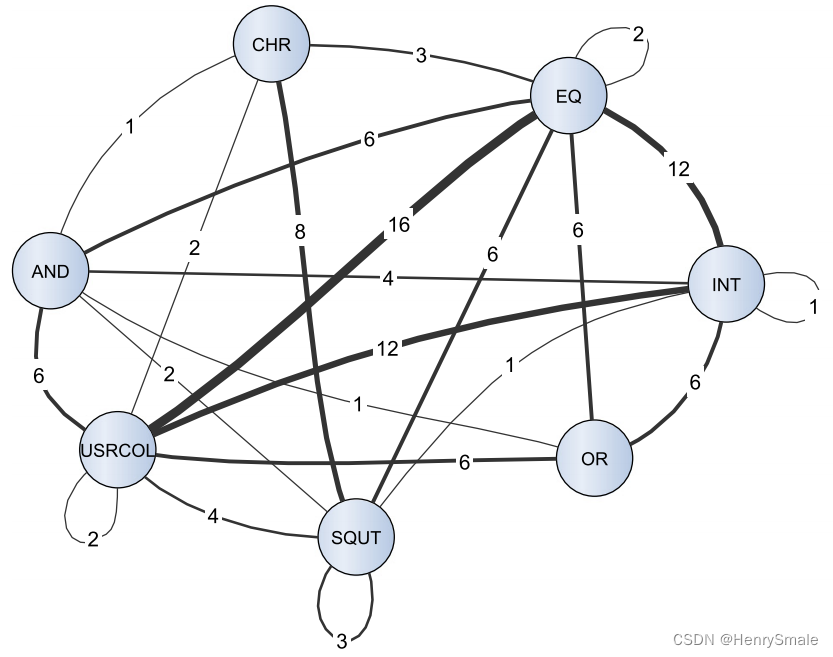
进一步对该图提取特征,可以是节点的度/入度/出度/紧密度等,从而将一个查询转换成为SQL标记的特征向量。而后可以使用各类分类器进行训练。
4.2 基于文本分析的方法
由于注入内容是一种文本信息,其语法基本遵循SQL语言,而非扎乱无章的内容。从这点看,它与自然语言类似。因此,可以尝试按照自然语言文本分类的方式来进行SQL注入的检测。
把SQL语句注入的请求信息进行分割,按照逻辑顺序进行切分,在逻辑上存在间隔的地方加上空格。 例如:
--post-data"Login='and'1'='1~~~&Password='and'1'='1~~~&ret_page='and'1'='1~~~&qu
erystring='and'1'='1~~~&FormAction=login&FormName=Login"
转化为:
“-post-data "Login=' and '1'='1~~~&Password=' and '1'='1~~~&ret_page=' and '1'='1~~~&querystring='
and '1'='1~~~&FormAction=login&FormName=Login”
把这些从Web日志中提取出来的字符串按照标点符号进行切分,最终获得其中的词汇特征集。这样的做法是把这些字符串当作文本来处理。
接下来,采用普通的文本分类技术,使用信息增益、方差阈值等特征选择方法选择有利于分类的Top
K
K
K个特征,从而完成文本向量空间的构建。
从文本的角度,当然也可以把文本分类中的经典神经网络用来进行SQL注入的检测。例如Text CNN等。
5 天池AI上的实践
数据集是来自一个网站收集的链接请求,只有normal/attack两类,分别对应于标签0/1。该数据集共480条记录,有注入记录339条,正常记录141条。以下两条记录分别是注入和非注入样本。
基本思路是,把整个训练文本集进行切分,转换称为tf-idf向量,然后使用各类分类器进行训练和测试。
(1)数据处理部分
‘’’
train_data = pd.read_csv(“train.txt”, header = None, sep = “,”)
test_data = pd.read_csv(“test.txt”, header = None, sep = “,”)
train_data.dropna(inplace = True) #删除有缺失值的行
test_data.dropna(inplace = True)
(2)文本-向量转换处理,使用sklearn提供的TfidfVectorizer完成向量表示。
(3)构建分类器,测试性能
- 可以实现神经网络模型等更多分类器进行测试
版权归原作者 HenrySmale 所有, 如有侵权,请联系我们删除。