
人工智能如何加速你的机器学习项目从特征工程到模型训练
人工智能如何加速你的机器学习项目从特征工程到模型训练 欢迎来到雲闪世界。
在本文中,我们将重点介绍这些 AI 工具如何协助机器学习项目。机器学习是数据科学的基石。虽然使用 LLM 模型完全自动化建模过程具有挑战性,但这些 AI 工具仍然可以显著简化许多 ML 步骤的流程。

添加图片注释,不超过 140 字(可选)
构建机器学习模型的步骤 与如今通常可以通过 AI 工具实现自动化的 SQL 或 EDA 不同,机器学习是另一种野兽。事实上,我花了很长时间才写这篇文章,因为我一直在努力思考应该如何评估 AI 工具,以及如何确定评分标准。 退一步来说,要评估哪种 AI 工具在协助 ML 项目方面真正大放异彩,至关重要的是要了解这些工具在 ML 模型构建的关键阶段可以做什么和不能做什么。以下是机器学习的八个基本步骤: 1. 问题定义:明确定义您要解决的问题。这包括了解业务背景、目标和期望结果。
- 人工智能辅助:有限。人工智能工具可以帮助澄清问题陈述,但如果没有人工输入,通常很难掌握复杂的业务背景。
- 数据收集:从各种来源收集相关数据,这可能涉及访问数据库、API 或网络抓取。
- 人工智能辅助:有限。虽然聊天机器人可能会建议数据来源,但繁重的数据收集工作通常需要人工或与团队合作。
- 探索性数据分析 (EDA):清理和预处理数据,并分析其结构、分布和关系。这涉及诸如输入缺失值、生成可视化和进行相关性分析等任务。
- AI 辅助:强大。AI 工具擅长生成可视化效果、提供描述性统计数据以及快速从数据中提出见解。
4.特征工程:创建新特征或转换现有特征以提高模型性能。这包括特征提取和选择。
- AI 辅助:强大。AI 可以建议新功能,解释某些转换可能有用的原因,并自动执行某些功能工程任务。
5.模型选择:根据问题类型和数据特点选择合适的机器学习模型(例如回归、分类、聚类)。
- AI 辅助:中等。AI 可以根据问题描述和数据推荐模型,但你可能需要进行实验才能找到最佳匹配。
- 模型训练和评估:根据数据训练模型,并使用适当的指标评估其性能。这涉及调整超参数并通过交叉验证选择最佳模型。
- AI 辅助:中等。AI 可以帮助生成训练脚本、建议评估指标和调整超参数,但运行代码通常需要外部执行和自动化。
- 模型部署:将模型部署到生产环境中,以便对新数据进行预测。
- AI 协助:有限。AI 聊天机器人可以指导您完成部署过程,但无法取代所需的实际工作。
- 监控和维护:持续监控生产中的模型性能,根据需要重新训练,并解决随时间推移出现的任何漂移或退化。
- 人工智能辅助:有限。虽然人工智能可能会建议使用监控工具,但持续维护是一项超出大多数人工智能工具(尤其是聊天机器人界面)能力的任务。
综上所述,AI 能够发挥最大作用的步骤是 EDA 和特征工程,并在模型选择、训练和评估方面提供一些有价值的指导。由于我们已经评估了 AI 在 EDA 中的表现,因此我们将重点介绍本文中的其余步骤。 评估机器学习中的人工智能聊天机器人 为了测试这些工具,我使用了Kaggle 的在线支付欺诈检测数据集( CC0:公共领域许可证)。欺诈检测是一种非常常见的机器学习用例,可以通过监督学习和无监督学习方法来实现。这个数据集太大,无法满足这三种工具的文件上传限制。因此,我提取了一个 0.5% 的随机样本(3181 行),欺诈率(真阳性率)为 0.2%。 我们将按照以下标准评估人工智能工具。
评估标准
1.特征工程
我首先上传带有列描述的数据集,并要求 AI 工具建议特征工程技术。
你是一家银行的数据科学家。
你获得了一个在线支付数据集,其中包含有关欺诈交易的历史信息。
你的目标是建立一个机器学习模型来检测在线支付中的欺诈行为。
以下是详细的列描述:
step:表示时间单位,1 步等于 1 小时
type:在线交易类型
amount:交易金额
nameOrig:开始交易的客户
oldbalanceOrg:交易前的余额
newbalanceOrig:交易后的余额
nameDest:交易收款人
oldbalanceDest:交易前收款人的初始余额
newbalanceDest:交易后收款人的新余额
isFraud:欺诈交易
让我们一步一步地完成任务。首先,请关注特征工程。
你能建议一些可以帮助提高我的模型性能的特征工程技术吗?
请考虑转换、特征之间的交互以及任何可能相关的特定于领域的特征。
为每个建议的特征或转换提供简要说明。
ChatGPT-4o(3/3):
ChatGPT 提出了八类特征,涵盖了各种各样的特征转换、交互和新的特征构想。
- 特征转换:ChatGPT建议对分类变量进行独热编码或频率编码。这是处理分类变量最常见的两种方法。
- 特征交互:ChatGPT 建议基于现有列创建余额差异、相对金额和交易时间等特征来检测交易异常。这些也是现实世界欺诈检测中常用的特征。
- 新功能:ChatGPT 还提出了意想不到的受益者的创意功能理想。



添加图片注释,不超过 140 字(可选)
我要求它在可能的情况下生成代码来创建新功能,整个过程运行良好,没有任何错误。

添加图片注释,不超过 140 字(可选)
克劳德 3.5 十四行诗(3/3) 克劳德提出了 10 类特征:
- 它首先将特征分类为基于时间、交易金额、余额相关、基于频率等主题。
- 然后它介绍了其他特征工程技术,如分类编码、交互、聚合等。
- 一些特征可以从现有的数据集中计算出来,而其他特征则是附加特征,例如交易速度特征。
它还能够生成正确计算特征的 Python 代码。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
双子座进阶版 (3/3) Gemini 提供了五类特征工程思路。其中许多与 ChatGPT 和 Claude 上面提出的非常相似。它生成的代码也表现良好。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
- 模型选择 接下来我让AI工具推荐最合适的模型:"Can you recommend the most suitable machine learning models for this task? For each recommended model, provide a brief explanation of why it is appropriate and mention any important considerations for using it effectively"。 聊天GPT-4o (3/3) ChatGPT 列出了八个具有明确用例和注意事项的候选模型。这几乎涵盖了所有常见的分类模型,以及用于异常检测的无监督模型(KNN 和孤立森林)。它还推荐了起点和后续步骤。 当我问它会选择什么具体模型时,它回答说,考虑到不平衡的数据集、捕捉复杂模式的能力、对特征重要性的洞察以及高效且良好的性能。这与业界的一般做法非常吻合。Gradient Boosting Machines (GBM), specifically XGBoost or LightGBM

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
克劳德 3.5 十四行诗(3/3) Claude 还列出了 7 个候选模型,既有监督模型也有无监督模型。它还列出了集成方法,这绝对是提高模型性能的好方法。与 ChatGPT 类似,它建议从梯度提升模型开始。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
双子座进阶版 (3/3) Gemini 给出了五项模型建议,从逻辑回归到基于树的模型和神经网络。它进一步列出了不平衡数据集的四个重要考虑因素,这在欺诈检测的背景下非常重要。 我继续提问If I don’t have the isFraud column, what model will you recommend?以测试它对无监督模型的了解。它推荐了 Isolation Forest,这与 ChatGPT 和 Claude 一致。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
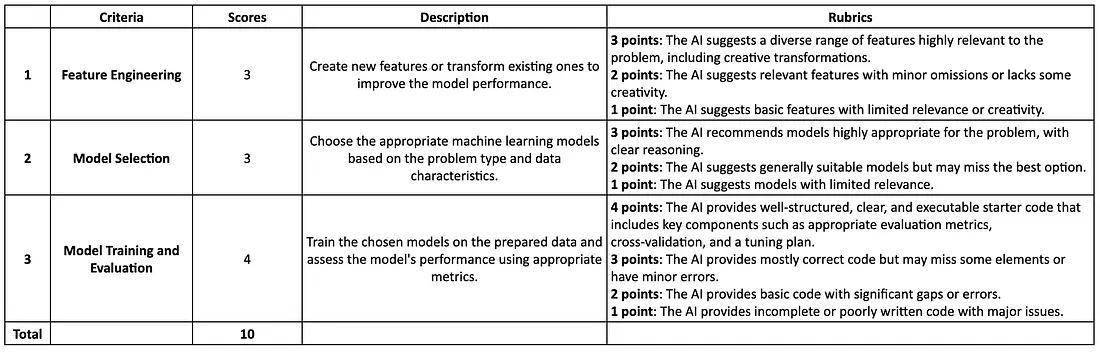
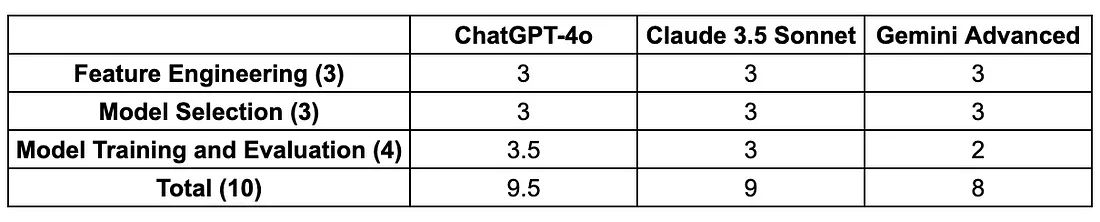
3.模型训练与评估 现在我们进入最后一轮——模型训练和评估。这是我的提示:Can you provide the code to train an XGBoost model? Please ensure that it includes steps like splitting the data into training and testing sets and performing cross-validation. Please also suggest the appropriate evaluation metrics and potential hyperparameters tunning opportunities. ChatGPT-4o(3.5/4) ChatGPT 提供了准确且结构良好的代码脚本,涵盖了从模型训练、评估和交叉验证到超参数调整的所有方面。代码成功运行,没有任何错误。它还解释了评估指标的选择,并提供了具有良好理由的超参数调整建议。 到目前为止,一切看起来都很好。但是,我仍然扣了 0.5 分,因为它没有涵盖对不平衡数据集的任何处理,例如上采样、SMOTE 或调整 XGBoost 中的相关参数(例如scale_pos_weight)。我们的数据集只有 0.2% 的真阳性率,因此在训练模型时必须考虑到这一点。这凸显了仅依赖 AI 工具进行机器学习的一个重大缺点——它们可以生成功能代码,但由于现实世界数据的复杂性,可能会忽略关键步骤,例如处理不平衡数据集。

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
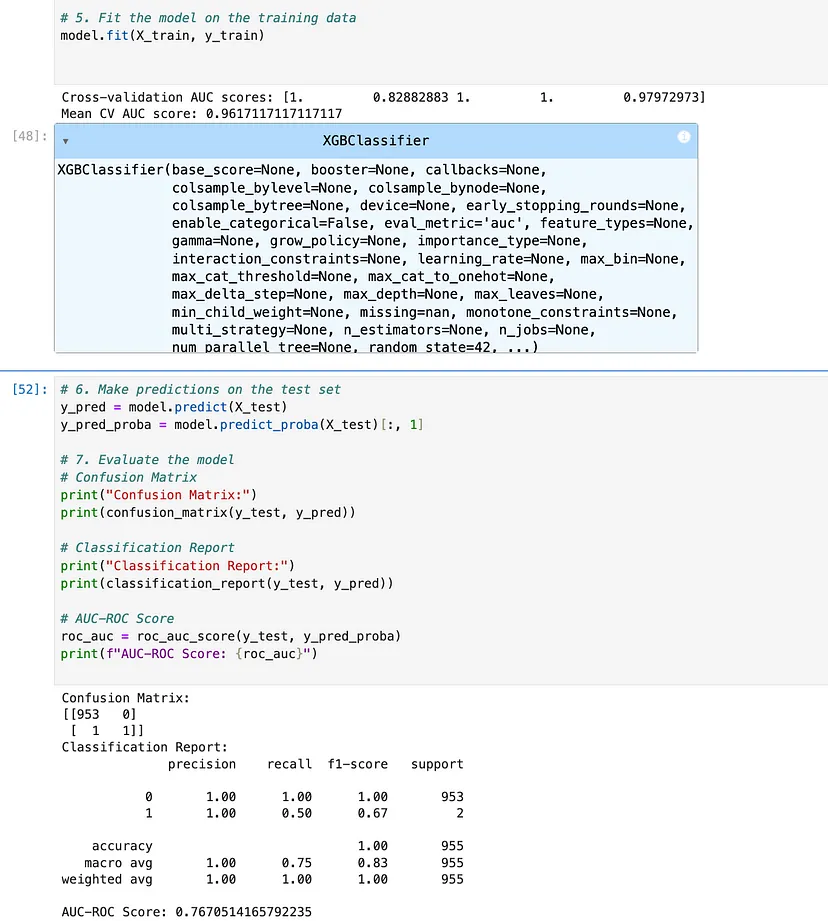
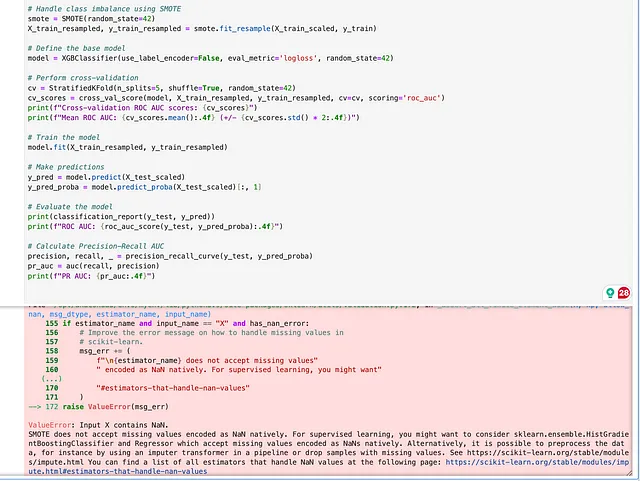
克劳德 3.5 十四行诗(3/4) Claude 还提供了全面的代码,涵盖了从训练和评估到超参数调整的所有必要步骤。其中包括使用 SMOTE 处理类别不平衡的步骤。但是,当我尝试在本地运行代码时,由于某些列中缺少值,我遇到了 SMOTE 错误。它的超参数调整代码在方法中也存在语法错误fit。 因此,我给它4分中的3分。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
我想提出的另一个非常重要的问题是,Claude 在早期步骤中创建了基于频率的特征(例如transaction_count_per_customer,unique_recipients_per_customer)。然而,这些特征是在训练和测试分割之前基于完整数据集计算的,这会导致潜在的数据泄露。当我向 Claude 提出这个问题时,他很快就意识到了这个问题,并提出了基于时间的分割等解决方案。然而,这是另一个很好的例子,说明如果没有领域专业知识,LLM 很容易忽略细微差别。虽然我没有因此扣分——但因为 ChatGPT 和 Gemini 没有遇到的问题而惩罚 Claude 似乎有点不公平,因为他们没有创建这些特征。

添加图片注释,不超过 140 字(可选)
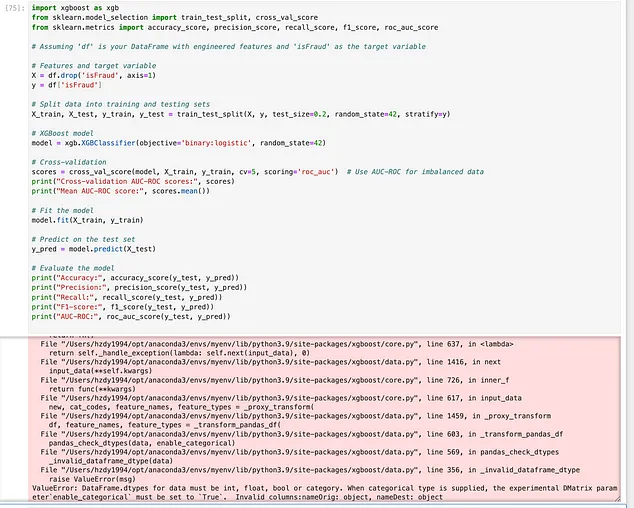
双子座进阶版 (2/4) Gemini 还选择了合理的评估指标。它提供的代码涵盖了基本的模型训练、交叉验证和评估。但是,它没有从数据框中排除分类变量,导致在本地运行模型训练时出错。当我要求它生成用于超参数调整的代码时,它首先在聊天机器人界面中显示一些错误消息并失败,然后提供带有明显语法错误的代码……(不幸的是,在我的整个测试中,Gemini 是这三种 AI 工具中最不稳定的。) 因此,我给它打 2 分(满分 4 分)。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
最终结果
添加图片注释,不超过 140 字(可选)
在本轮 ML 助手竞赛中,获胜者是......🥁 ChatGPT-4o! 这主要归功于它在模型训练和评估过程中代码生成的准确性很高。同时,这三种工具在特征工程和模型选择方面都表现出了强大的能力。 话虽如此,人工智能工具在协助机器学习方面仍然存在许多局限性:
- 他们擅长提出新功能、推荐模型和生成代码,但将这些步骤集成为一个无缝的流程仍然是一个挑战。
- 此外,人类专业知识在今天的机器学习中仍然至关重要。如果你不了解处理不平衡数据集的必要性,那么仅仅按照 ChatGPT 的脚本操作就会错过这一步。同样,由于特征工程设置不当而导致的 Claude 数据泄露问题也是人类专业知识仍然不可或缺的另一个完美例子。
总而言之,人工智能工具(尤其是 ChatGPT-4o)是生成新特征、探索各种模型选项和制定评估策略的绝佳头脑风暴伙伴。然而,构建稳健有效的机器学习模型仍然需要人类的专业知识。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
版权归原作者 数云界 所有, 如有侵权,请联系我们删除。