
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
在学习顺序查找之前,我们首先要搞清楚——什么是算法?
一.算法
(1)算法的定义
任何被明确定义的计算过程都可以称为算法,它将某个值或一组值作为输入,并产生一组值作为输出。所以算法可以被称为将输入转为输出的一系列计算步骤。
这样的概括其实是比较标准和抽象的,说白了算法其实就是步骤明确的解决问题的方法。由于是在计算机中执行,所以通常先用伪代码来表示,清晰的表达出思路和步骤,这样在真正执行的时候,就可以使用不同的语言来实现出相同的效果。
因此,算法就是一个有穷规则(语句,指令)的有序集合,它确定了解决某一个问题的一个运算序列,对于问题的初始输入,通过算法有限步的运行,产生一个或多个输出。
(2)算法的特性
(1)有穷性——算法执行的步骤(或规则)是有限;
(2)确定性——每个计算步骤的无二义性;
(3)可行性——每个计算步骤能够在有限的时间内完成;
(4)输入——算法有零个或多个外部输入;
(5)输出——算法有一个或多个输出。
(3)算法的选择
解决一个问题仁者见仁,智者见智,所以解决问题的算法肯定不唯一,我们理应设计最为效率,最适合我们当前需要的算法。
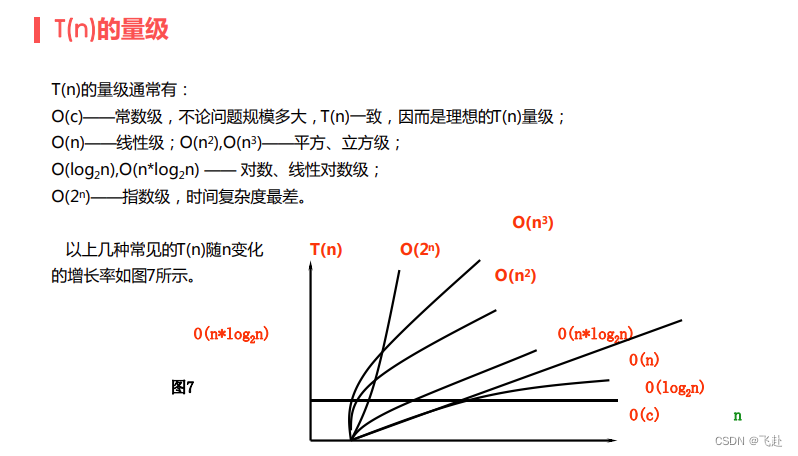
评价算法的几个点: ** 1.**消耗时间的多少 **2.**消耗存储空间的大小 ** 3.**容易理解,容易编程和调试,容易维护。 **4.**时间复杂度 通常把算法中的基本操作重复执行的频度称为算法的时间复杂度。算法中的基本操作一般是指算法中最深层循环内的语句(赋值、判断、四则运算等基础操作)。我们可以把时间频度记为T(n),它与算法中语句的执行次数成正比。其中的n被称为问题的规模,大多数情况下为输入的数据量。对于每一段代码,都可以转化为常数或与n相关的函数表达式,记做f(n)。如果我们把每一段代码的花费的时间加起来就能够得到一个刻画时间复杂度的表达式,在合并后保留量级最大的部分即可确定时间复杂度,记做O(f(n)),其中的O就是代表数量级。
常见的时间复杂度:常数阶O (1),对数阶O (log2n),线性阶O (n), 线性对数阶O (nlog2n),平方阶O (n^2),立方阶O (n^3),..., k次方阶O (n^k),指数阶O (2^n)。 随着问题规模n 的 不断增大,上述 **时间****复杂****度** 不断增大,算法 的 执行效率越低。
** 5.**空间复杂度 程序从开始执行到结束所需要的内存容量,也就是整个过程中最大需要占用多少的空间。为了评估算法本身,输入数据所占用的空间不会考虑,通常更关注算法运行时需要额外定义多少临时变量或多少存储结构。如:如果需要借助一个临时变量来进行两个元素的交换,则空间复杂度为O(1)。 tips:随着硬件的越来越强大,现在主流一般是用牺牲空间去换取时间,当然酌情考虑。
二.数据结构
(1)什么是数据结构?
1.数据(data):数据及信息的载体,是能够输入到计算机中,并可以被计算机识别,存储和处理的符号总称。(例如:201902班的学生数据就是该班全体学生记录的集合),**数据元素**作为数据的基本单位,每一个学生的全部信息为一个元素。 2.数据项(data element):是具有独立含义的数据最小单位,也称为字段或域。(例如:201902班中的每个数据元素是由学号,姓名,性别等数据项组成) 3. 数据类型(data type):数据类型是对数据元素取值范围与运算的限定。(例如:姓名用char,年龄用int,分数float...)** **4.!!!数据结构(data structure):数据结构指的是数据元素之间的相互关系,这种关系组织起来的一批数据,应用计算机的语言,按照一定的存储方式把它们存储到计算机中,并为这些数据定义一个运算的集合,就称为数据结构。
总结:每一个数据项都有自己的数据类型,由所有的数据项组成了数据元素,由所有的数据元素组成了数据****。数据里面所有元素之间的关系按照一定的存储方式存储到计算机中,这就是数据结构。
(2)数据结构的内容
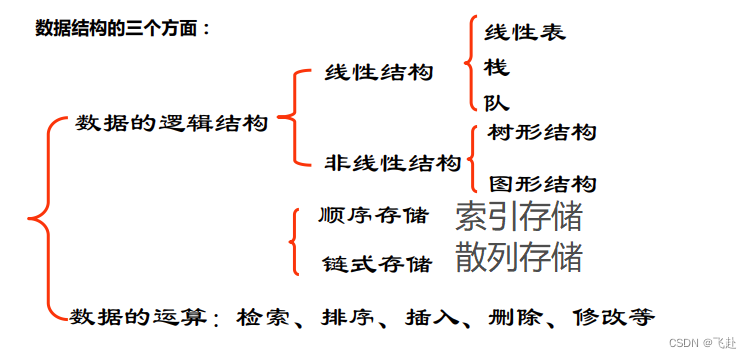
1.逻辑结构:表示数据运算之间的抽象关系(如邻接关系,从属关系等),每个元素可能具有的直接前驱数和后驱数将逻辑结构分为“线性”和“非线性”两大类。
2.存储结构:逻辑结构在计算机中的具体实现方法,分为顺序存储,链接存储,索引存储,散列存储。
3.数据运算:不管对于小白还是工作的程序员来说,增删改查以及排序,想必大家都很熟悉,我的任务就是带领大家深入,再次回顾。
tips:如果只是描述数据结构中数据元素之间的联系规律,即逻辑关系,则称为此时的数据结构为数据的逻辑结构,它是从具体问题中抽象出来的数学模型,是独立于计算机的,与机器无关。
(3)四种基本的数据结构
1.集合:数据元素间除了它们都属于一个数据集合之外没有其他的关系。
2.线性结构:一个对一个,例如线性表,栈,队列

3.树型结构:一个对多个,树
4.图状结构 :多个对多个,图** **

(4)四种数据的存储结构(或者物理结构)
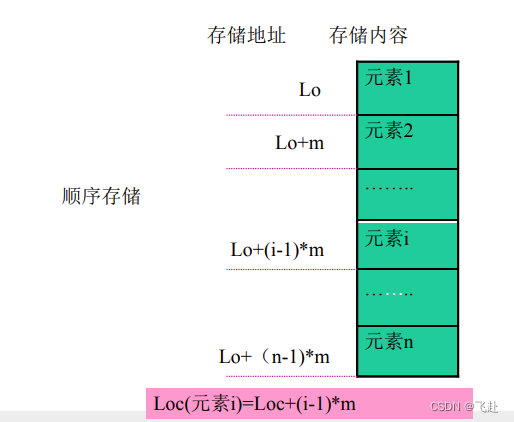
数据的存储结构指的是数据的逻辑结构在计算机存储器中的映像,存储结构是通过计算机语言所编写的程序来实现的,因而是依赖于具体的计算机语言的,数据结构常用的有这四种存储表示。 1.顺序存储(sequential storage):将数据结构中各元素按照其逻辑顺序存放于存储器一片连续的存储空间中(例如c语言中的一维数组)
顺序结构的特点 · 存储效率高,因为存储段元完全用于存放数据元素,数据元素之间的逻辑关系没有占用额外的存储空间。 · 可以实现元素的随机存取,可以由元素对应的逻辑序号直接计算出对应元素的存储地址 · 不便于数据修改,对元素的插入或删除操作不方便 2.链式存储(linked storage):将数据结构中各元素分布到存储器的不同点,用地址(或链指针)方式建立它们之间的联系,由此得到的存储结构为链式存储结构。
链式存储的特点 · 链式存储结构便于数据修改,在对元素进行插入或删除操作时仅需修改相应节点的指针域,不必移动结点。 · 链式存储对存储空间的利用率较低,因为分配给元素的存储单元有一部分被用来存储结点之间的逻辑关系 · 不能随机存取,逻辑上相邻的元素在存储空间中不一定相邻tips:这是一个重点哦!!!计算机内部很大程度上都是通过地址或指针来建立连接的!!
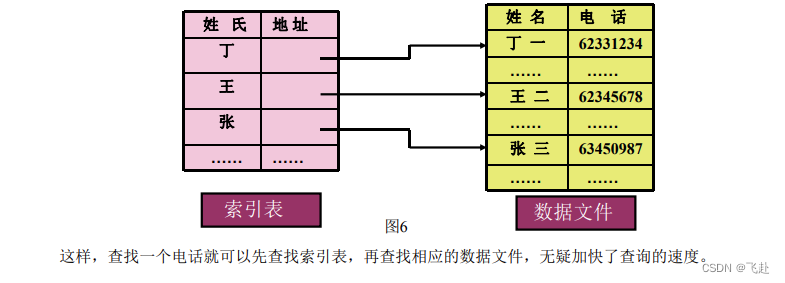
3.索引存储(indexed storage):在存储数据的同时,建立一个附加的索引表,即索引存储结构=数据文件+索引表例如:电话号码查询表,在存储用户数据文件的同时,建立一张姓氏索引表
索引存储结构的特点: · 查找效率高 · 需要建立索引表,额外增加了空间的开销 4.哈希(或散列)存储结构(hashed storage structure):是根据元素的关键字通过哈希(或散列)函数直接计算出一个值,并将这个值作为该元素的存储地址 哈希存储结构的特点: · 查找速度快,只要给出待查元素的关键字就可立刻算出该元素的存储地址 · 但哈希存储方法只存储元素的数据,不存储元素之间的逻辑关系 哈希一般只适合要求对数据能够进行快速查找和插入的场合


四种基本的存储方法就到这里,这些方法既可以单独使用,也可以组合使用。
用一种逻辑结构采用不同的存储方法可以得到不同的存储结构,要考虑运算方便及算法的时空要求来选择存储结构哟~
我是真的怕新人听晕,再看看这个图应该好很多:
** 三.算法+数据结构=程序**
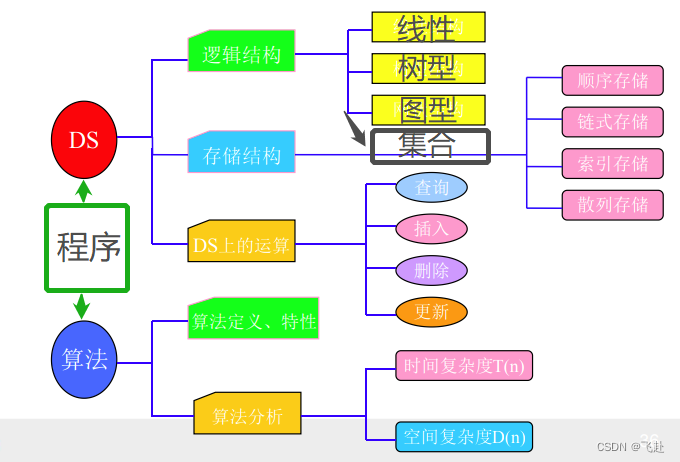
** 那今天就到这了,我的重心是其实这些东西,不会在数据结构的道路上走远,深究数据结构的同学得自己去找找学习资源了:**
1.顺序查找
2.直接选择排序
3.折半查找
4.折半插入排序
5.冒泡排序
6.快速排序
7.希尔排序
8.索引查找
后面会陆续更新,期望大家关注,我们一起成长!
版权归原作者 飞赴 所有, 如有侵权,请联系我们删除。