
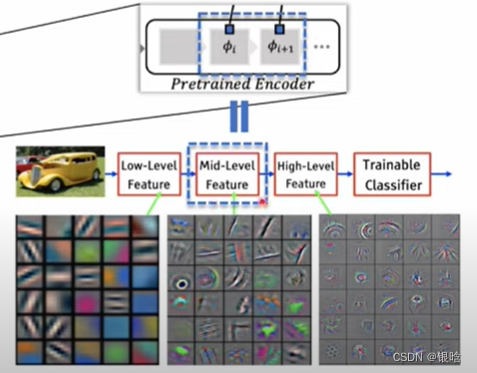
工业异常检测
Patchcore是截至2022年在AD数据集上表现最好的缺陷检测模型
- 本文深入浅出的让你看懂原理,解析顶会论文挺耗费时间的给个赞呗~
背景:
在工业图像的异常检测中,最大的问题就是冷启动的问题。
- 首先,在训练集中都是正常的图片,模型很容易捕获到正常图像的特征,但是很难捕获到异常缺陷的样本(这类样本很少,获取也难)
- 其次,分布漂移。正常图像和异常图像分布是不一样的,模型学习的是正常图像的数据分布,而异常图像的数据分布和正常图像不一样
AD数据集上的偏差: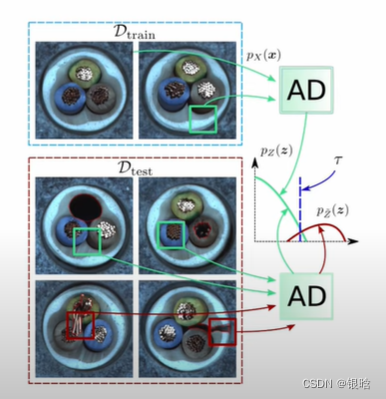
AD数据集介绍一下:
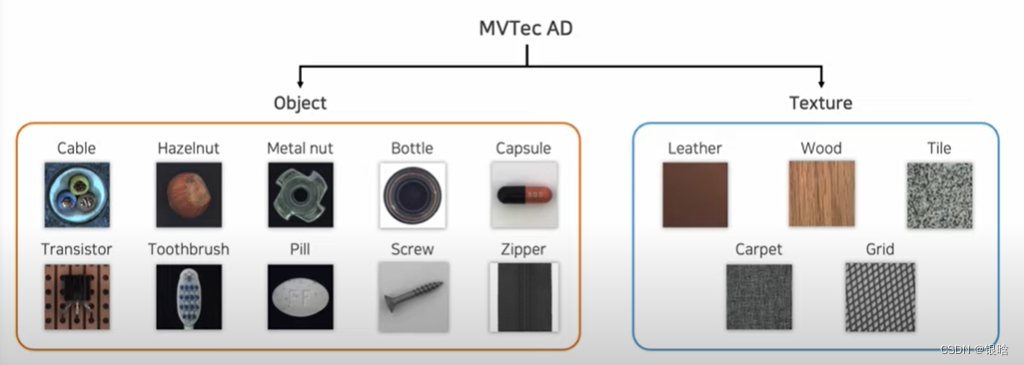
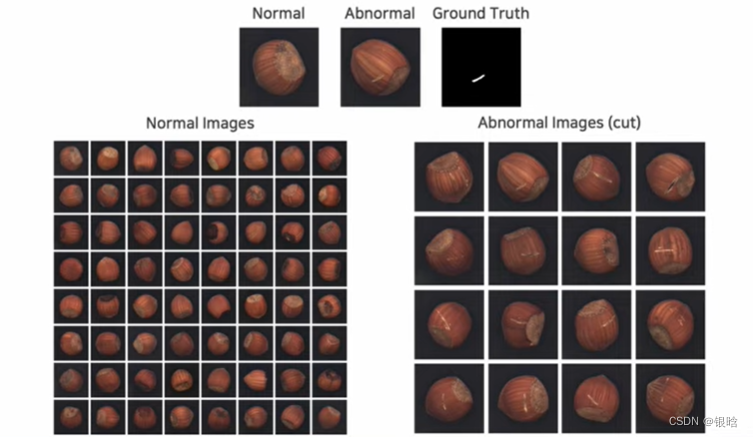
尝试解决:
- 如果基于分类的思想进行缺陷检测,很难,因为发生错误的地方不易察觉,小到一条划痕、大到一个组件直接消失
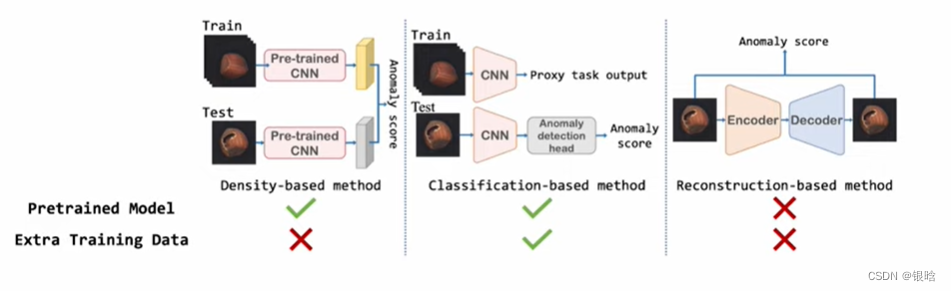
- 最近,采样预训练的模型是个好方法,但是不可避免ImageNet上训练的分类模型不适应目标分布
- 核心点:特征匹配。在训练集和测试集提取不同大小的深度特征表示。但是ImageNet的高层抽象的特征匹配有限
本篇文章采取的方法是基于密度的异常检测方法:
GAP:全局平均。
会定义一个anomaly score
就是你训练正常的数据,捕获正常图像的特征,然后有一个异常的数据进来,就会和正常数据产生一个差异,通过整个差异来判断是否是异常。
其实这篇文章也是站着巨人的肩膀上:
SPADE:
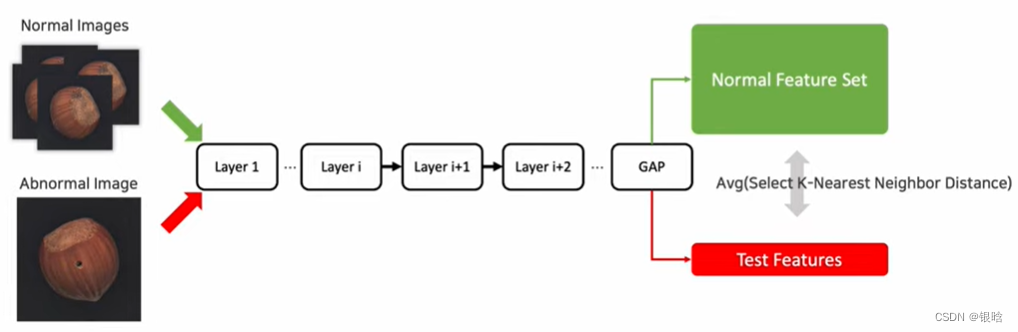
PaDim:
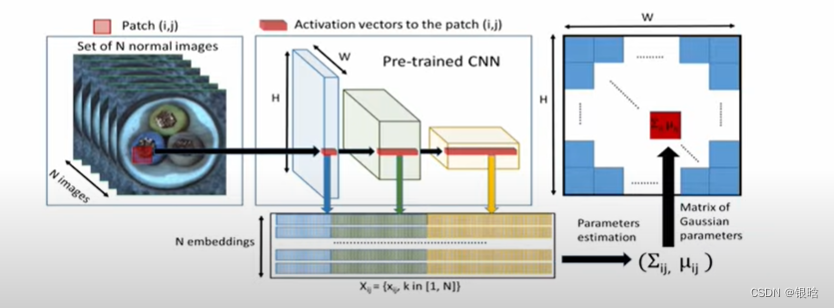
这篇文章提出3个方法:
- 在测试时,最大化提取正常数据的信息
- 减少ImageNet上的类别偏差
- 保持高的推理速度
总体流程:
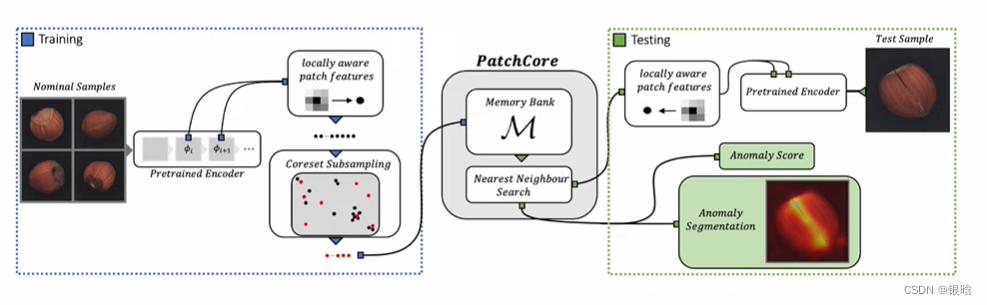
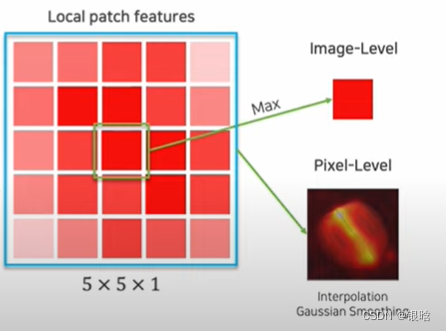
Locally patch features 局部块特征
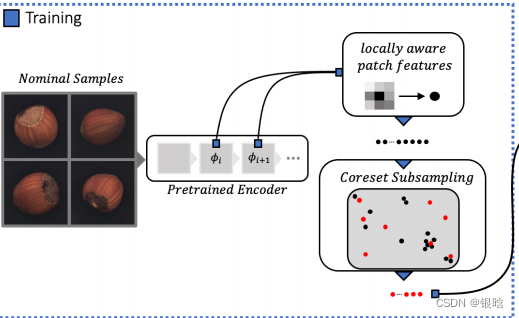
patchcore采用ImageNet的预训练模型
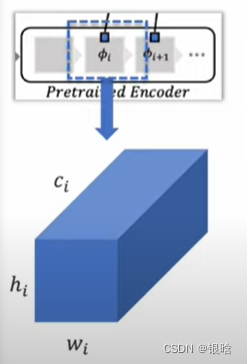
fi代表网络 ;
i
i
i代表样本 ;
j
j
j代表网络层级
局部特征提取
采用ResNet-50 / WideResNet-50 进行特征提取,由4个残差块组成。
一般来说,获取提取的特征是在ResNet最后一层获取,但是存在两个问题
- 损失太多的信息
- 深度抽象的特征对当前的分类任务存在较大的偏差,因为冷启动带来的问题,缺陷特征很少,很难推测出来
解决:
- 创建一个存储块:memory bank,存储patch features(可理解为块特征)
- 不从Resnet最后一层获取特征,而是从中间获取
什么是中间特征:
- 为了不损失空间的分辨率和有用的特征,采用局部邻居聚合的方法来增加感受野,然后合并特征h是高度,w是宽度,c是通道 , patchsize是块大小
- 针对位置(h,w)的特征处理:
先放图片理解:
特征提取: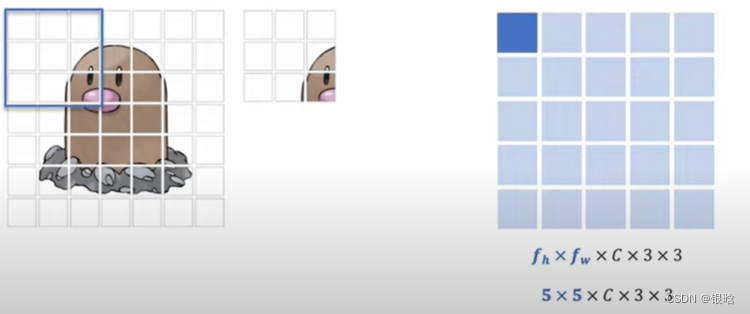
扫描所有的:
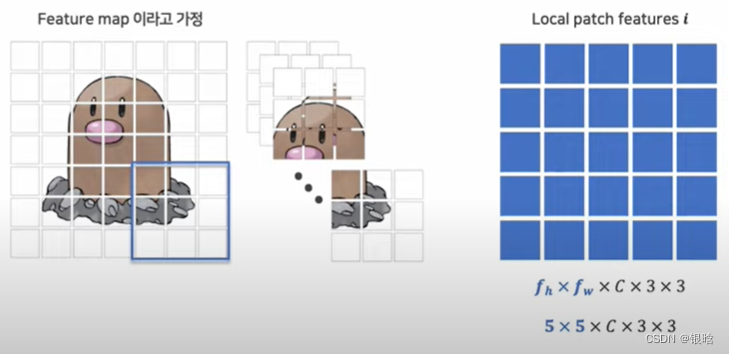
- 再提取下一层,再合并,形成一个local patch:
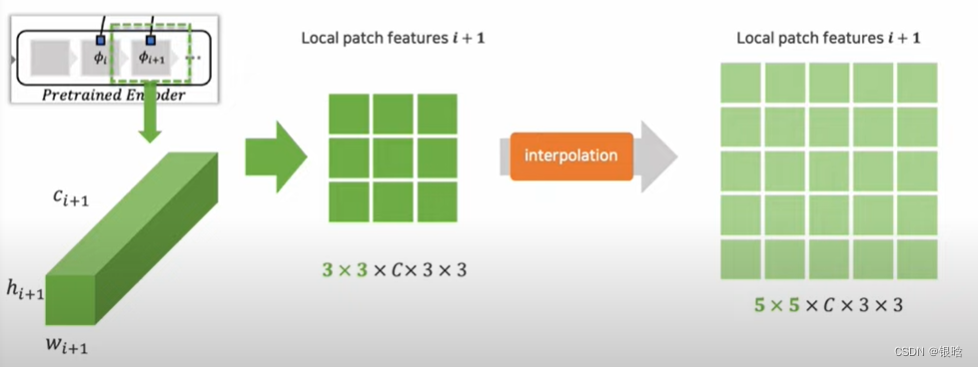
- 多个local patch合并:
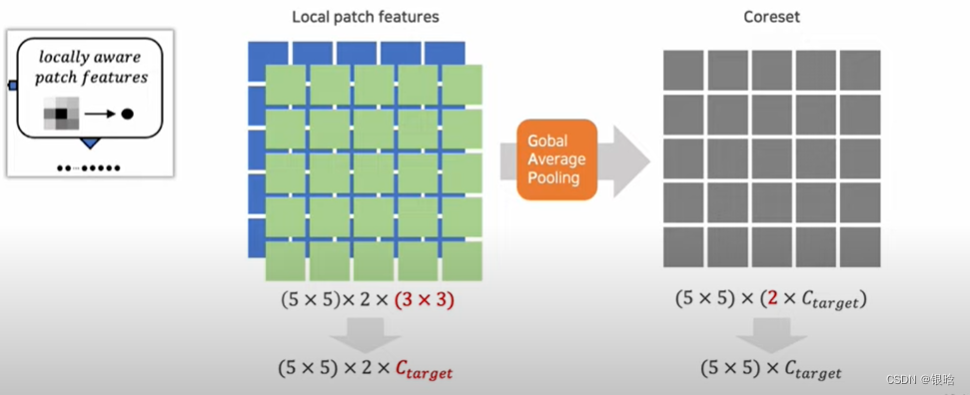
- 提取邻居的特征集合
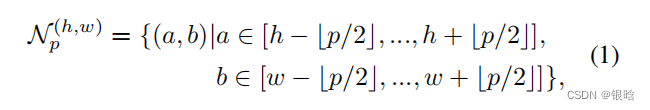
- 合并邻居的特征集合,组成单个feature map
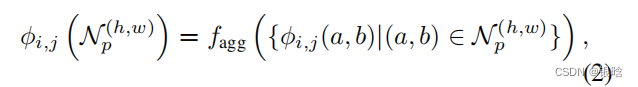
- 局部特征集合
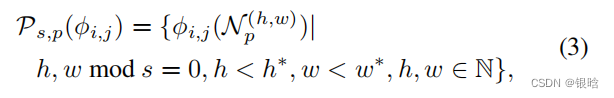
- 最后遍历完整个数据集,取并集,得到特征存储块
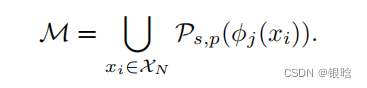
Coreset Subsampling
基于贪心策略的子采样方法:
流程解释:
- M是我们需要的特征集,整个特征集不能太大(放在内存里面的),尽可能小弟coreset能代表绝大多数的数据特征
- 遍历所有的图像,获得经过ResNet提取后的特征,还是太多,得优化
- l是设定的coreset的特征子集个数,是个超参数
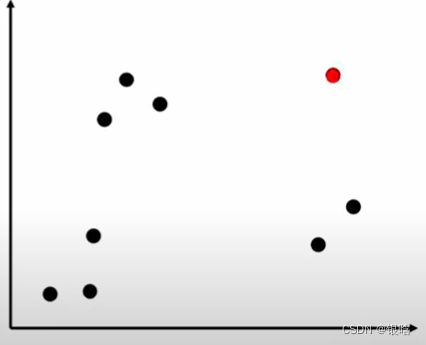
- 关键:如果选才能满足1中的要求? 就是,每次选一个coresset( M C M_C MC)中的点,在M中找一个最近又最远(贪心策略)的点,抽出来
- 解释一下什么是最近又最远:在最近的范围内找到最远的点,也就是在局部找到一个最远的点,即最优解。如果不这样,搜索计算量巨大NP难的问题
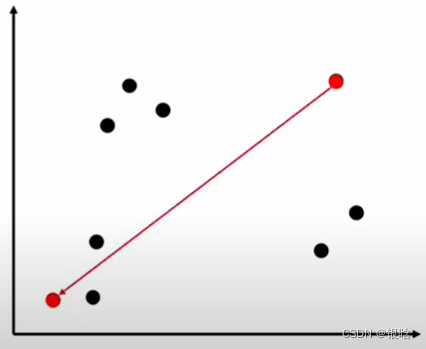
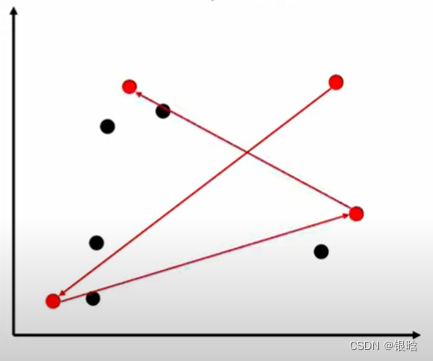
- 这波很妙,也很关键!
对比一波传说中的随机采样: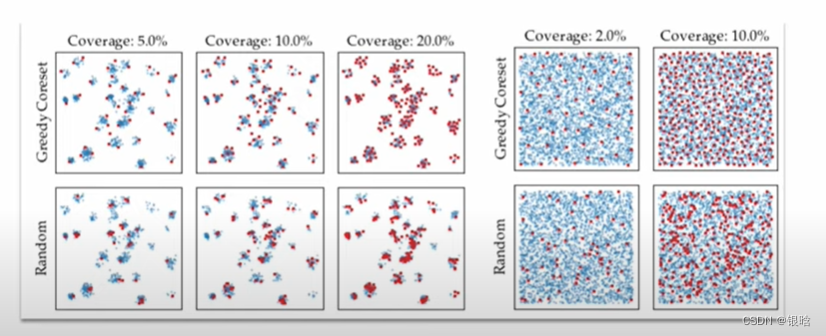
- 兄弟,吊打啊!
Detection and Localization
测试集的数据进来

- 按照patch feature的思想,一个一个patch到coreset里面去找对比anomaly score,看是不是异常的,是异常的,ok,红色标出来; 不是,也ok,平平淡淡才是真!
最近邻
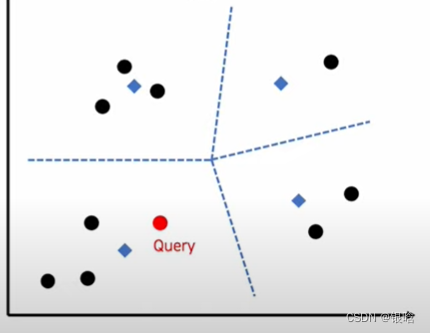
每个query进来都要找最近的邻居,又是一波骚操作
- 假设领域内邻居数为3
 公式如下:
公式如下: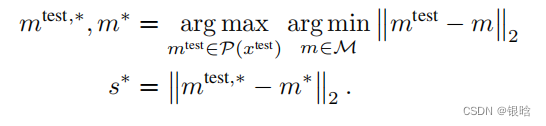 又是一波最小又最大,解释一下:
又是一波最小又最大,解释一下:
- 每个query进来,首先找最近距离最近的领域质心(蓝色标记,非数据点)
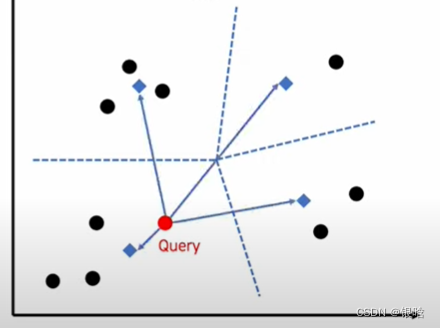
- 找到距离query最近的质心后,锁定该领域
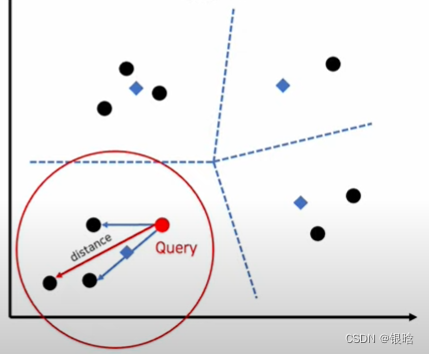
- 然后在该领域内计算距离最远的数据点,用该距离计算anomaly score,判断是否异常,得到结果
效果
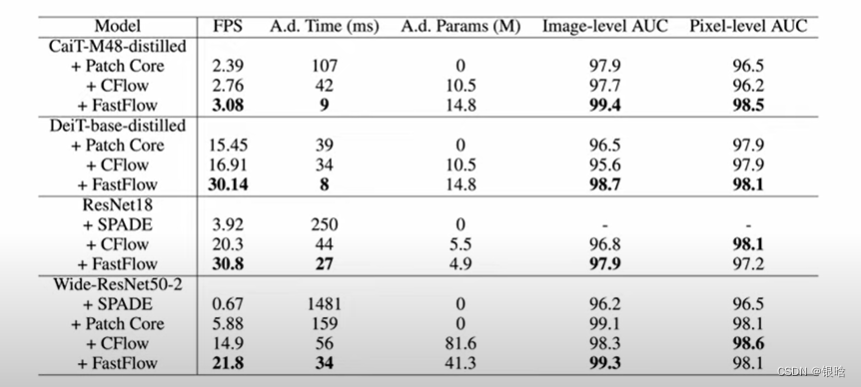
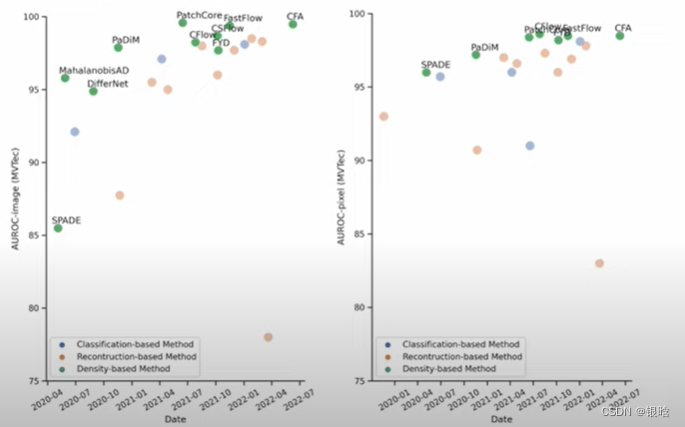
- 目前为止最好的异常检测模型!
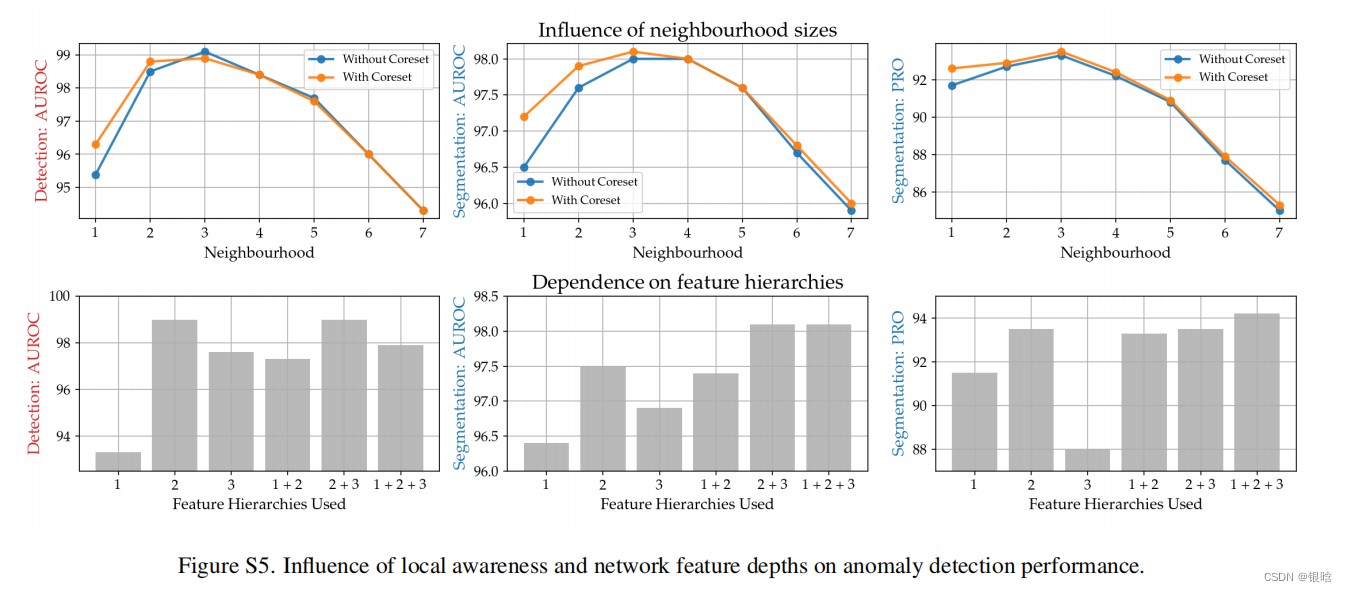
超参数调整
都是DL秃头人,解析顶会论文写到博客挺耗费时间的给个赞呗~~
本文转载自: https://blog.csdn.net/RandyHan/article/details/127681935
版权归原作者 银晗 所有, 如有侵权,请联系我们删除。
版权归原作者 银晗 所有, 如有侵权,请联系我们删除。