
系列文章目录
第一章:会思考的机器你造嘛——AI技术
第二章:机器学习的概率统计模型(附代码)
第三章:深度学习敲门砖——神经网络
第四章:掌握神经网络的法宝(一)
第五章:掌握神经网络的法宝(二)
一. 神经网络的最优化
1.1 神经网络的参数和变量
1)参数和变量
- 像权重和偏置这种确定数学模型的常数称为模型的参数;
- 数字模型中值可以根据数据而变化的量称为变量;
- 神经网络中用到的参数和变量数量庞大;
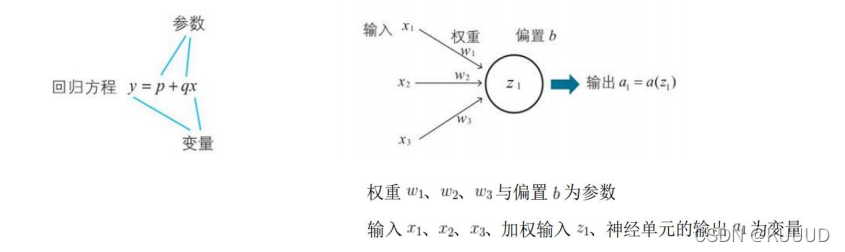
2)神经网络中的变量名和参数名
- 首先,我们对层进行编号,最左边的输入层为层1,隐藏层则一次递增(层2,层3······)最右边的输出层诶层l(l为last的意思):

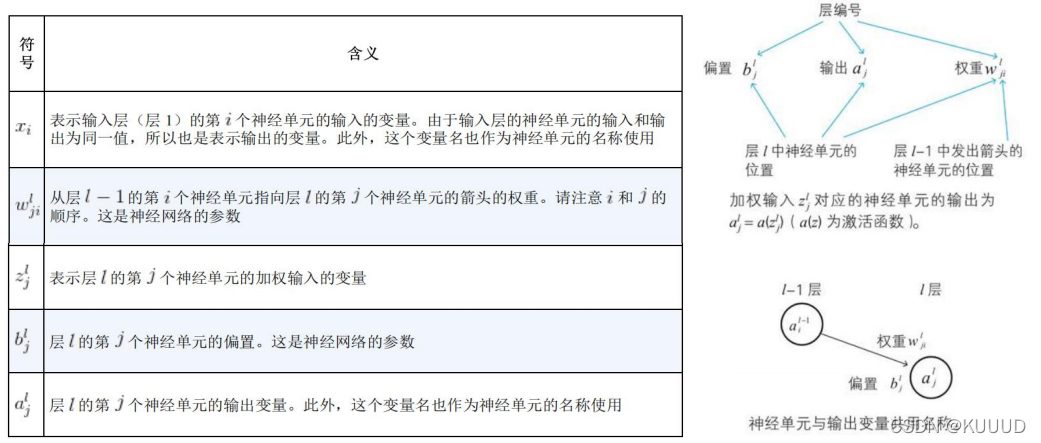
- **输出层的相关变量名 **
- ** 隐藏层、输出层的相关的参数名与变量名**
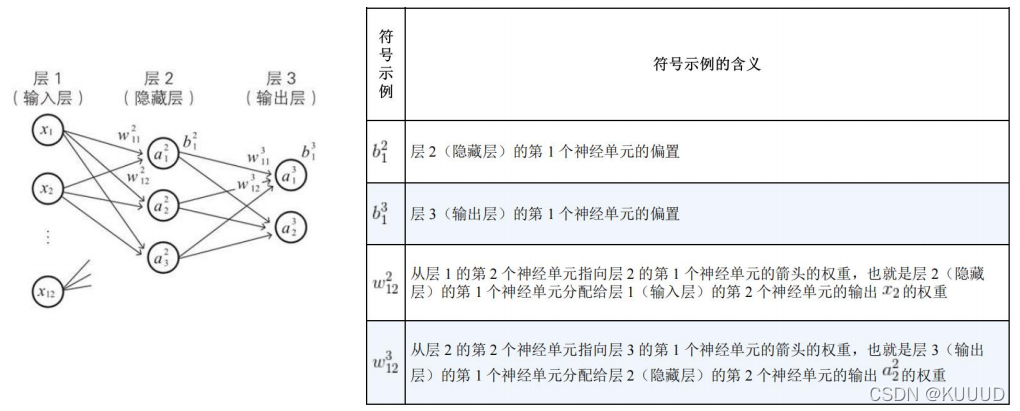
** 变量值的表示方法**
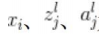为变量,它们的值根据学习数据的学习实例而变化,若具体给出了学习数据的一个图像,则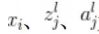就变成了数值,而不是变量;神经单元符号和变量名
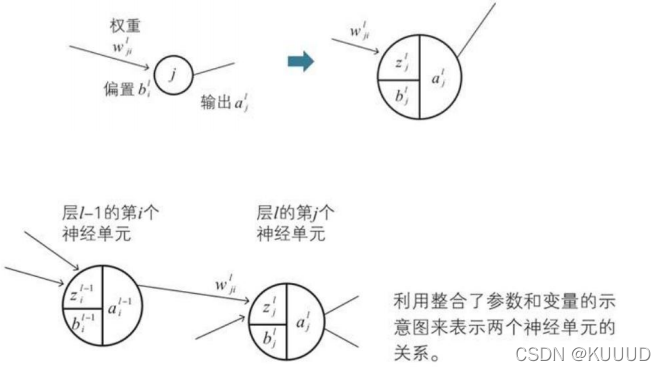
** 3)神经网络的变量的关系式**
输入层的关系式
我们将变量名的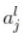定义为层l的第j个神经单元的输出值,由于输入层为层1(即l=1),所以前面的Xi可以如下表示: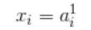** 隐藏层的关系式**

** 输出层的关系式**

** 4)神经网络的学习数据和正解**
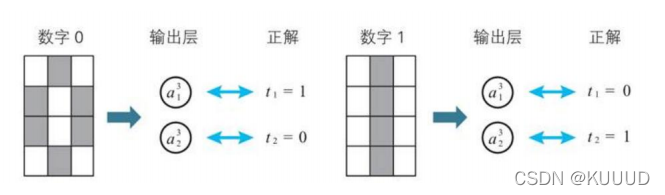
通过这样的方式来定义正解,就可以像下面这样表示神经网络算出的预测值和正解的平方误差: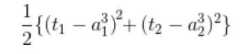
** 5)神经网络的代价函数**
** 表示模型准确度的代价函数**
通过调整参数(权重和偏置),使模型的输出符合实际的数据(在神经网络中就是学习数据),从而确定数学模型,这个过程在数学上称为**最优化,**在神经网络的世界称为**学习;**
** ** 在数学上,用模型参数表示的总体误差的函数称为代价函数,此外也可以称为损失函数、目的函数、误差函数等;

** 最优化的基础:代价函数的最小化**
确定神经网络的权重和偏置,使得从神经网络得出的代价函数 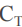达到最小** 参数的个数和数据的规模**
以一个12个输入层,3个隐藏层,2个输出层的神经网络为例:
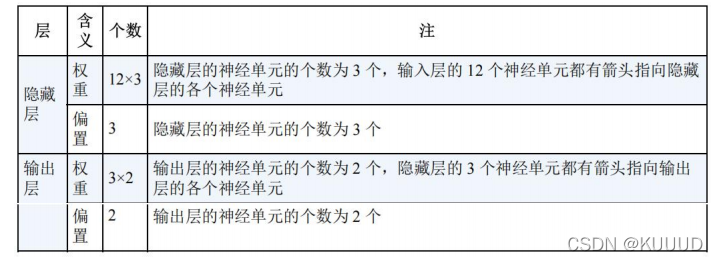
根据上表,参数的总数 =(12x3+3)+(3x2+2)= 47
而我们要确定模型,就必须准备好规模大于擦书个数的数据,所以在这次学习用的图像至少需要47张。
二. 误差反向传播法
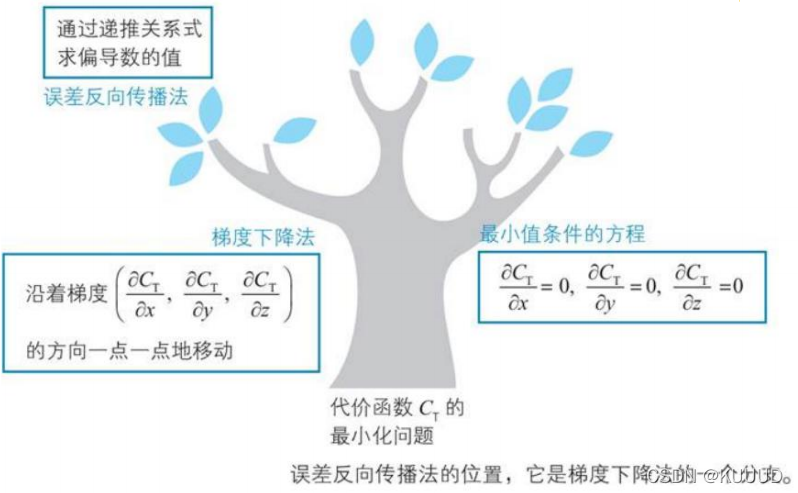
梯度下降法
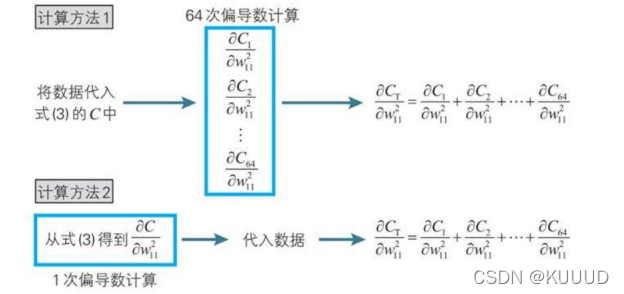
根据我们上一章学到的梯度下降法可知,梯度下降法是先求导后求和,梯度分量是一个一个学习实例的简单的和,即代价函数 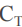的偏导数是从各个学习实例得到的偏导数的和:
** 神经单元误差**

误差反向传播法的特点是将繁杂的导数计算替换为数列的递推关系式,而提供这递推关系式的就是名为**神经单元误差**(error)的变量。利用平方误差C,其定义如下所示:
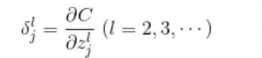
该变量称为第l层第j个神经单元的误差。
** ** 用** **表示平方误差C关于权重、偏置的偏导数: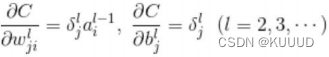
- 和
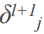 的关系
的关系如果神经误差能求出来,那么梯度下降法的计算所需的平方误差式的偏导数也能求出来:

可以得出: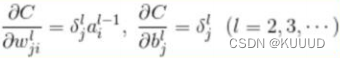
** 通过递推关系式越过导数计算**
误差反向传播法以梯度下降法为基础,它的特点是将繁杂的导数计算替换为数列的递推关系式:
通过推广可以的出层l与下一层l+1的一般关系式:
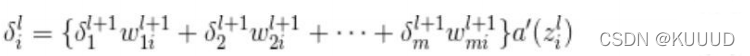
- 中间层的 :不求导也可以得到值
** ** 只要求出输出层的神经单元误差,其他的神经单元误差就不需要进行偏导数计算;
关系式一般是按照层编号从高到低的方向来确定值的,这与之前考察过的数列的递推关系式的想法相反,这就是反向传播中“反向”的由来:
总结
以上就是今天要讲的内容,本文介绍了神经网络所需的数学方法,神经网络的最优化和误差反向传播法的相关知识。
欢迎大家留言一起讨论问题~~~
本文转载自: https://blog.csdn.net/weixin_53919192/article/details/124067880
版权归原作者 KUUUD 所有, 如有侵权,请联系我们删除。
版权归原作者 KUUUD 所有, 如有侵权,请联系我们删除。