
在人工智能领域,大语言模型(LLMs)已经在各种复杂的推理基准测试中展现出了令人瞩目的性能。传统上,这些推理能力是通过精心设计的提示技术来激发的,例如少量示例提示(few-shot prompting)或零示例提示(zero-shot prompting)。然而,这些方法往往涉及到手动密集的提示工程,限制了它们在不同任务中的通用性。
本项工作探索了一个不同的视角,提出了一个关键的问题:LLMs能否在没有特定提示的情况下有效地进行推理?研究发现一令人惊讶的结果,通过简单地改变解码过程,可以从预训练的LLMs中自然地激发出链式推理(CoT)路径。这种解码修改绕过了CoT提示,并且是完全无监督的,不需要模型调整。
研究还揭示了预训练语言模型固有的推理能力,这一发现与之前侧重于改进提示以促进推理的研究形成了鲜明对比。研究发现,当模型在其解码路径中存在CoT时,对其最终答案的信心增加。利用这种增加的信心,研究者提出了CoT解码方法,以选择更可靠的解码路径,从而在各种推理基准测试中显著提高了模型性能。
实验结果表明,CoT解码在解码过程中自然地揭示了CoT推理路径,显著提高了模型的推理能力,超越了贪心解码。此外还观察到这些路径在预训练数据中频繁出现的任务中更为普遍,而在复杂的合成任务中则不那么常见,在这些任务中,可能仍然需要高级提示技术来触发这些推理路径。
这与McCoy等人(2023年)和Prystawski等人(2023年)的发现一致。在这些场景中还发现,少量CoT示例在指导模型如何解决任务方面发挥了更大的“教学”作用,模型主要模仿这些提示的格式来生成准确的推理路径。
总之,研究表明,通过改变解码策略,可以有效地从LLMs中激发出推理能力,而无需依赖于特定的提示技术。这一发现不仅为理解LLMs的内在推理能力提供了新的视角,而且为未来的研究提供了新的方向,即如何利用这些模型固有的推理能力来解决更广泛的问题。
**论文标题:**Chain-of-Thought Reasoning Without Prompting
公众号「夕小瑶科技说」后台回复“Chain”获取论文PDF!
CoT-decoding的新视角:无需提示即可激发推理
1. CoT-decoding方法介绍
CoT-decoding是一种新的解码方法,它能够从预训练的大语言模型(LLMs)中激发出推理能力,而无需依赖于传统的提示技术。这种方法通过探索解码过程中的替代top-𝑘令牌,揭示了模型在生成答案时内在的推理路径(CoT路径)。这种方法的关键在于,它不仅避免了提示带来的混淆因素,而且允许我们更准确地评估LLMs的内在推理能力。
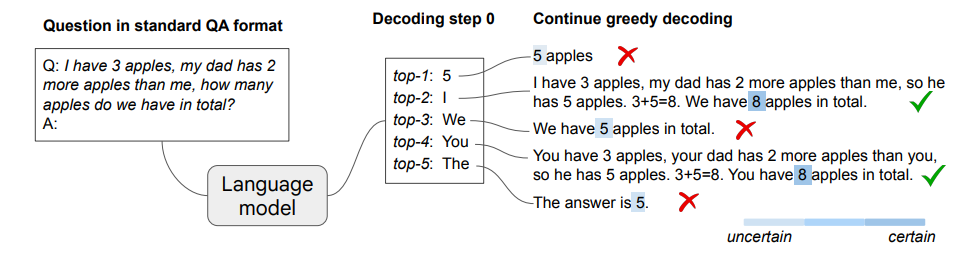
(图为CoT解码示意图,这些模型在解码最终答案时往往显示出更高的可信度)
2. 预训练LLM中的CoT路径发现
研究发现,即使在没有明确提示的情况下,预训练的LLMs在解码过程中也能自然地展现出CoT推理模式。
- 例如,在数学推理任务中,当模型不是简单地贪心解码,而是考虑top-𝑘令牌时,CoT路径就会自然出现。
这表明,预训练的LLMs在其解码轨迹中固有地包含了推理能力,这与以往依赖于提示技术来激发推理能力的研究形成了鲜明对比。
3. CoT路径与模型答案置信度的关联
CoT-decoding的另一个关键发现是,当解码过程中存在CoT路径时,模型在解码其最终答案时表现出更高的置信度。这种置信度可以通过模型在每个解码步骤中对top两个令牌的概率差异来衡量。
研究表明,CoT路径的存在通常会导致最终答案的解码更加自信,这一点通过模型对最终答案的概率评分显著高于非CoT路径的情况得到了证实。利用这一现象,研究者们开发了一种方法来筛选出最可靠的解码路径,即CoT-decoding,从而在各种推理基准测试中显著提高了模型的推理能力。
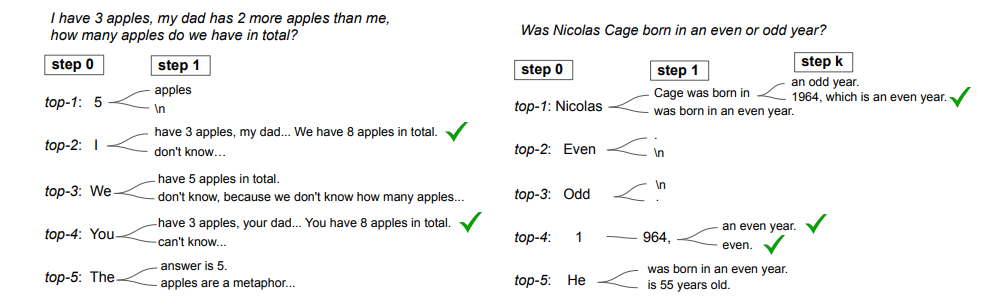
(图为通过考虑不同解码步骤的替代标记分析解码路径。虽然某些任务可能存在多个分支位置,但所有都通向正确推理路径)
实验设置:评估CoT-decoding的有效性
实验方法与模型选择
在评估CoT-decoding的有效性时,研究者们采用了一种新颖的解码方法,即考虑在解码过程中的top-𝑘备选词汇,而不是仅依赖于贪心解码路径。实验中使用的模型是预训练的PaLM-2大模型,与标准的贪心解码路径(𝑘 = 0)进行比较,其中𝑘 > 0表示在第一步解码时选择的第𝑘个词汇。此外,还探讨了Mistral-7B模型,包括预训练和指令调优(instruction-tuned)变体。
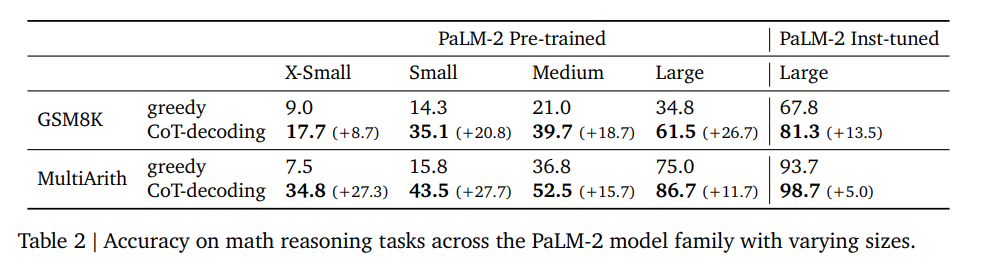
数学推理任务的实验结果
在数学推理任务中,CoT-decoding显著提高了模型的推理能力,与贪心解码相比,在不同规模的PaLM-2模型上均有一致的提升。
- 例如,在GSM8K数据集上,CoT-decoding在PaLM-2大型模型上实现了比贪婪解码高出26.7%的绝对准确率。值得注意的是,CoT-decoding甚至可以提高经过指令调优的模型的性能。
自然语言推理任务的实验结果
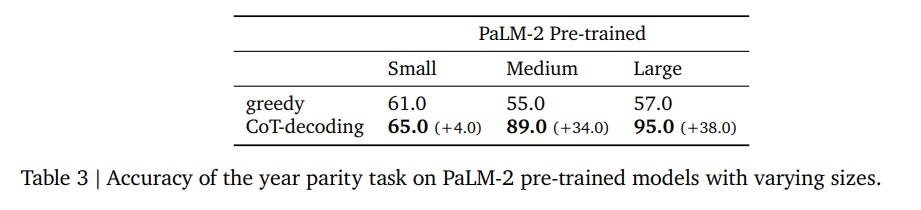
在自然语言推理任务中,研究者们探讨了“年份奇偶性”任务,发现即使是最先进的模型,如GPT-4,在直接提示的情况下也只能达到几率水平的准确率(约50%)。然而,通过CoT-decoding,模型能够在大多数情况下恢复CoT推理路径,并实现超过90%的准确率。
- 错误分析表明,大多数错误源自模型检索错误的出生年份,而生成的CoT路径在奇偶性和模型检索的年份之间保持高度一致。
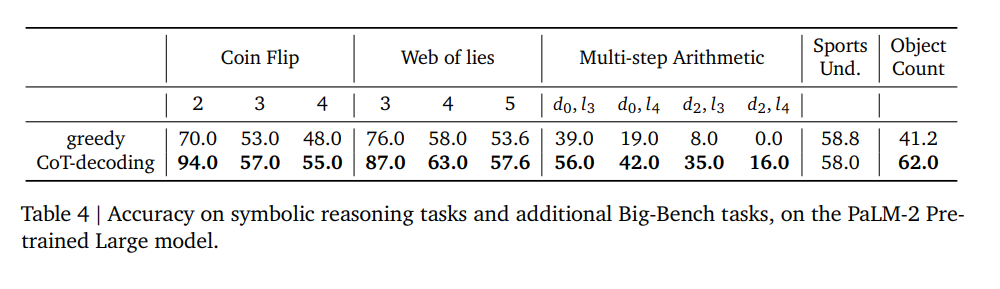
符号推理任务的实验结果
在符号推理任务中,CoT-decoding的收益随着任务复杂性的增加而减小。
- 模型在高度合成的任务中,即那些在预训练分布中缺乏显著表示的任务,无法生成准确的CoT路径。
这些任务包括需要准确状态跟踪的任务,如Coin-Flip和Web-of-Lies,以及多步算术任务。在这些任务中,CoT提示技术在教导模型如何解决任务方面发挥了更大的“教学”作用。
通过这些实验,研究者们展示了预训练语言模型在解码过程中固有的推理能力,并通过CoT-decoding显著提高了各种推理基准测试中的模型性能。
CoT-decoding与传统方法的比较
1. CoT-decoding与贪心解码的对比
CoT-decoding方法与传统的贪心解码(greedy decoding)有显著的不同。在贪心解码中,大语言模型(LLMs)通常会直接生成一个答案,而不会展示出解决问题的思考过程(chain-of-thought,CoT)。这种方法在处理简单问题时可能效果不错,但在需要复杂推理的任务上,模型往往会直接给出错误答案。
- 例如,在数学问题GSM8K中,贪心解码可能会直接给出“$60.00”作为答案,而不展示计算过程。
相比之下,CoT-decoding方法通过考虑解码过程中的top-𝑘个备选词,能够揭示出隐藏在解码轨迹中的CoT推理路径。这种方法不需要显式的提示(prompting),也不需要模型训练或指令调整。实验表明,CoT-decoding能够自然地揭示出CoT路径,并显著提高模型在各种推理基准测试中的表现。
- 例如,在同一个GSM8K问题中,CoT-decoding能够在𝑘=9的路径中找到正确的计算过程,并给出正确答案“$64”。
此外,CoT-decoding方法还能够通过模型在解码过程中的置信度来区分CoT和非CoT路径。这一现象可以用于从多个解码路径中筛选出更可靠的输出。即:当CoT路径存在时,模型在解码最终答案时表现出更高的置信度。
2. CoT-decoding与CoT提示方法的对比
CoT-decoding与CoT提示方法(如few-shot CoT prompting和zero-shot CoT prompting)相比,提供了一种不依赖于显式提示的推理能力激发方式。
- CoT提示方法通常需要手动设计针对特定任务的提示,这不仅耗时而且限制了方法的通用性。
- CoT-decoding则通过修改解码过程,允许评估LLMs的内在推理能力,而无需依赖于特定的提示设计。
实验结果显示,CoT-decoding在没有特定提示的情况下,能够与few-shot CoT prompting和zero-shot CoT prompting方法相媲美,甚至在某些情况下表现更好。
- 例如,在处理GSM8K数据集的数学问题时,CoT-decoding生成的CoT与few-shot CoT提示方法相比,展现出更自由形式的推理过程。
这表明CoT-decoding能够更好地揭示LLMs在解决问题时的内在策略,而不受外部提示可能引入的偏见影响。
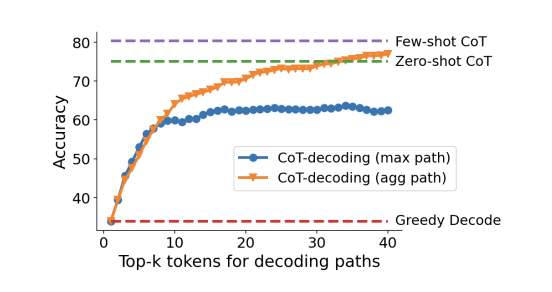
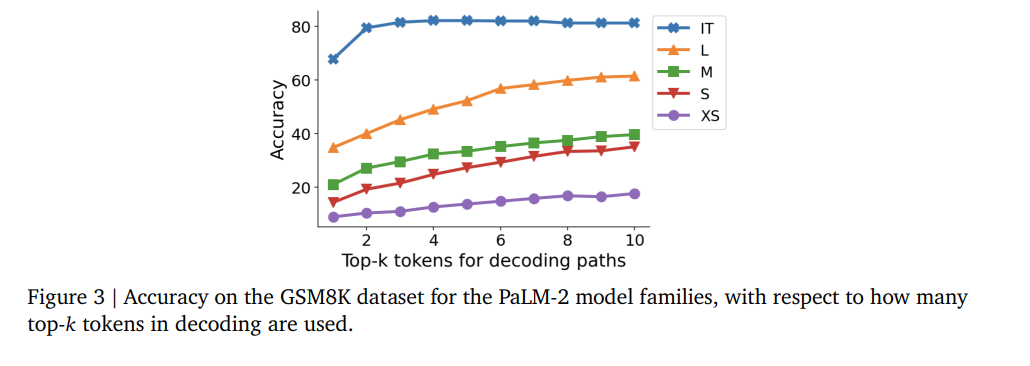
(图为PaLM-2大模型的GSM8K数据集上的CoT解码精度,显示出与解码中使用了多少top-𝑘令牌有关)
总的来说,CoT-decoding为我们提供了一种新的视角,通过简单地改变解码策略,就能有效地激发出模型的推理能力,这一发现对于未来LLMs的研究和应用具有重要意义。
讨论:CoT-decoding的计算成本与未来方向
CoT-decoding,即链式推理解码,是一种新颖的方法,它通过改变解码过程来从预训练的大语言模型(LLMs)中引出推理能力,而无需特定的提示技术。这种方法的优势在于它能够揭示模型在生成答案时的内在推理路径,同时避免了提示技术可能引入的混淆因素,更准确地评估模型的固有推理能力。
然而,CoT-decoding的一个主要挑战是计算成本。由于它涉及到在解码过程中考虑多个备选的top-𝑘令牌,因此需要更多的计算资源来探索和评估这些备选路径。
未来的研究方向可能包括利用CoT-decoding路径来微调模型,以增强其推理能力。此外,目前的探索主要集中在第一个令牌的分支上,因为这样可以产生高度多样化的解码路径,但未来的工作可以探索在任何令牌上进行分支,并在解码阶段搜索最佳路径。尽管这将大幅增加计算成本,如何在搜索过程中可靠地识别最佳令牌将是一个值得探索的方向。
总结:CoT-decoding在LLM推理中的潜力展望
1. CoT-decoding的发现和意义
研究表明,通过改变解码过程,即使没有显式提示,预训练的大语言模型(LLM)也能自然地产生链式思考(CoT)推理路径。这种方法被称为CoT-decoding,它通过考虑解码过程中的顶部-k个代替令牌,揭示了CoT路径通常是这些序列中的固有部分。CoT-decoding不仅绕过了提示的混淆因素,而且还允许我们评估LLM的内在推理能力。
2. CoT-decoding与模型信心的关联
研究观察到,当解码路径中存在CoT时,模型在解码其最终答案时表现出更高的信心。这种信心度量有效地区分了CoT路径和非CoT路径。在各种推理基准测试中的广泛实证研究表明,所提出的CoT-decoding方法显著优于标准的贪心解码。
3. CoT-decoding在不同任务中的表现
在数学推理、自然语言推理和符号推理任务中,CoT-decoding都显示出了显著的性能提升。特别是在那些在预训练数据中频繁出现的任务上,CoT-decoding能够自然地揭示CoT路径,而在复杂的合成任务中,可能仍然需要高级提示来触发这些推理路径。
公众号「夕小瑶科技说」后台回复“Chain”获取论文PDF!

版权归原作者 夕小瑶 所有, 如有侵权,请联系我们删除。