
实践出真知,欢迎关注我的公众号:Hoeller
对于一些Saas化软件,当某个租户在执行查询SQL时,如果查询条件出现了BUG,导致去查了所有租户的数据,这种情况是非常严重的,此时就需要在架构层面做限制,禁止一些特殊SQL的执行,另外,为了保护数据库,也可能会限制某些查询语句不要查询太多的数据,那么怎样在平台架构层面对业务层的SQL做拦截和校验呢?本文分享一下我司的做法。
我们集团里有的项目用的Mybatis,有的项目用的Spring Data JPA,共同点在于都用的Druid连接池,所以可以在Druid层面做SQL的拦截和校验。
Druid提供了FilterEventAdapter机制,可以用来拦截数据库连接的创建、Statement或PreparedStatement的创建、SQL语句的执行等等,我们可以自定义一个FilterEventAdapter:
其中
statementExecuteQueryBefore()
方法表示在执行某个查询语句前的拦截点,
preparedStatement_executeQuery()
方法表示执行查询语句的地方,比如正常情况下
preparedStatement_executeQuery()
方法顺利执行的话就会得到ResultSetProxy,可以理解为就是ResultSet,也就代表查询结果集。
所以如果我们想做查询语句的拦截,这两个方法都可以做到,回到文章题目:想要限制每次查询的结果集不能超过10000行,该如何实现?我这里给两种不同的实现方式。
对于某一个查询SQL,我们首先得知道这个SQL将会查出多少条数据,那就得把该查询SQL,比如
select a,b,c from t where a=1
,改造成为
select count(1) from t where a=1
,执行改造后的count语句就能知道原始SQL会查出多少条记录了。
我这里提供一个方法,能够把简单的select语句改造为count语句(原谅我不能把公司内部的代码贴出来~~~)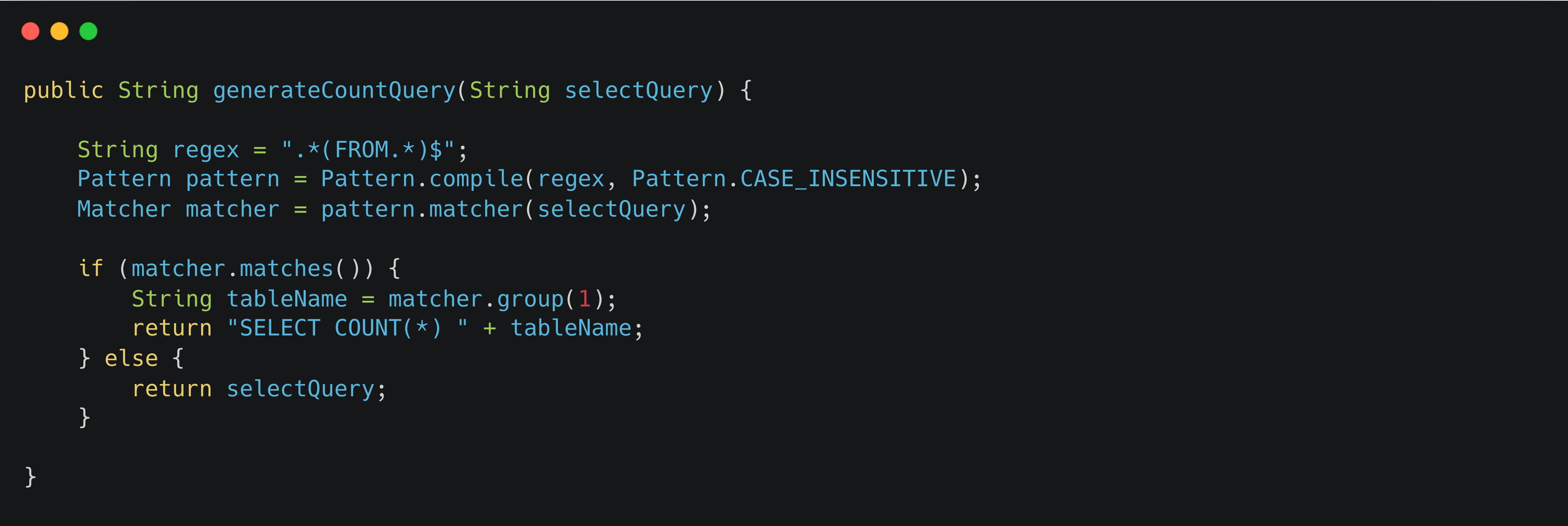
然后,我们就能在statementExecuteQueryBefore()方法中做拦截判断了:
这种方式的好处是:如果某个查询SQL确实超过限制了,那么就它被拦截了,但是缺点是:如果很多SQL并没有超过限制,那么就多余执行了count语句,降低了性能。
那么我们来看看第二种方案,这种方法重写的是
preparedStatement_executeQuery
方法,思路是:先执行原始SQL,得到ResultSet,然后通过ResultSet来判断结果集是否超过了限制,如果超过了限制则告警,比如代码为: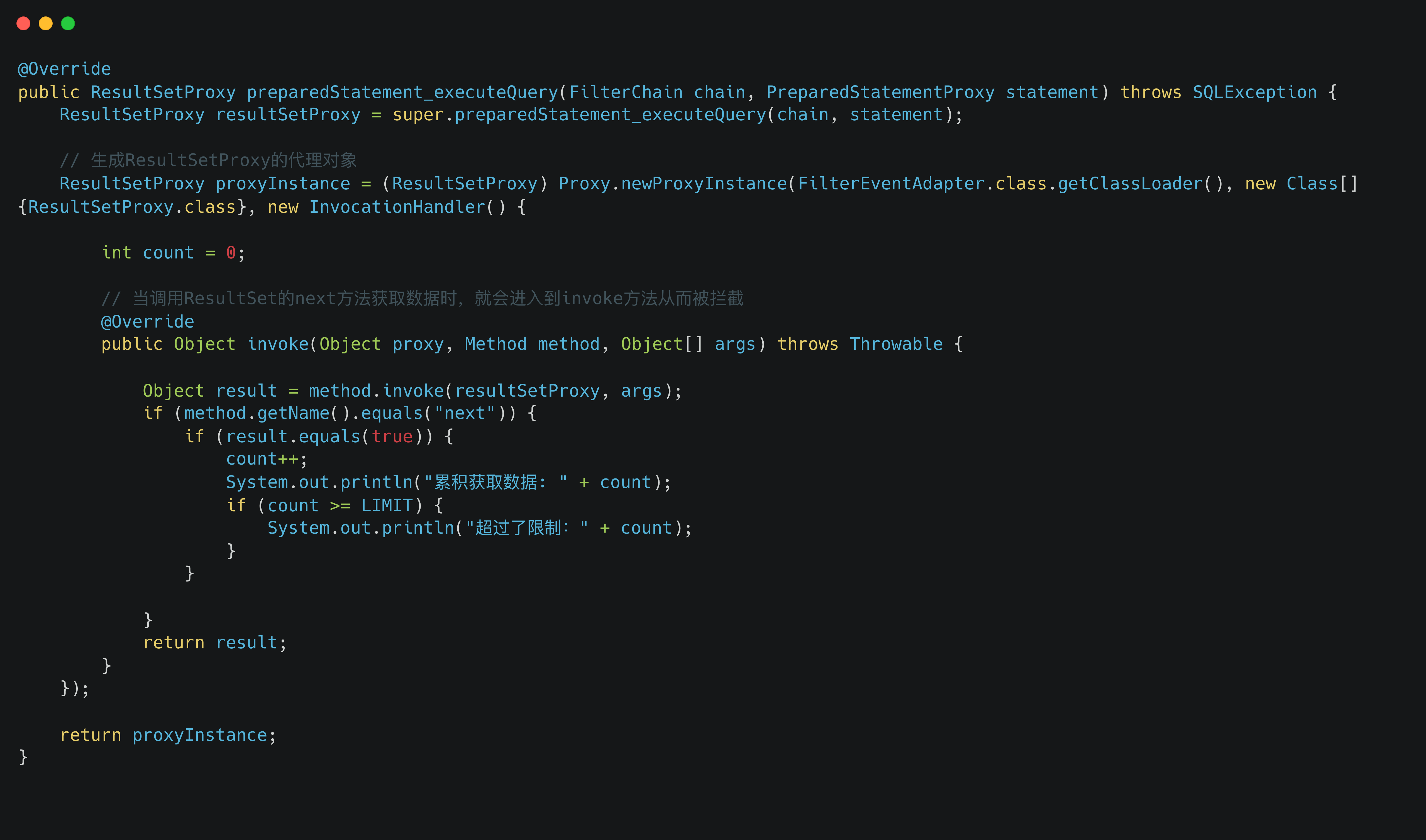
这种方案和第一种方案的优缺点正好相反,优点是:没有额外执行count语句,缺点是:如果查询语句确实超过了限制只能事后告警了。
这两种方案似乎鱼和熊掌不可兼得,大家觉得哪个方案更好呢?
我是大都督,之前是一名讲师,现在是一名架构师,实践才能出真知,这是我重回一线的原因!如果大家觉得有所收获,可以关注我的公众号:Hoeller,里面也有我的联系方式,欢迎勾搭。
版权归原作者 爱读源码的大都督 所有, 如有侵权,请联系我们删除。