
文章介绍
2月26日,高通在2024年世界移动通信大会(MWC2024)上发布高通AI Hub, AI Hub 简化了AI 模型部署到边缘设备的过程。可以利用AI-hub云端托管 Qualcomm 设备上,在几分钟内完成模型的优化、验证和部署。本文以Pytorch版本的MobileNet模型为例子,介绍如何使用AI Hub。
更多关于Qualcomm AI Hub的入门指南,可以参考文档 Getting started — qai-hub documentation
第一步. 安装环境
建议使用Miniconda来管理您的python版本和环境。
Installing Miniconda — Anaconda documentation
1. Python环境
在您的机器上安装miniconda。
Windows:安装完成后,从「开始」菜单打开Anaconda Prompt。
macOS/Linux:安装完成后,打开一个新的shell窗口。
为Qualcomm AI Hub设置一个环境:
conda create python=3.8 -n qai_hub
conda activate qai_hub
2. 安装qai-hub客户端
pip3 install qai-hub
3. 登录
登陆到 Qualcomm AI Hub
Home - Qualcomm AI Hub
使用您的高通ID登录,登录后导航Account -> Settings -> API Token。生成API token后进入下一步配置您的客户端。
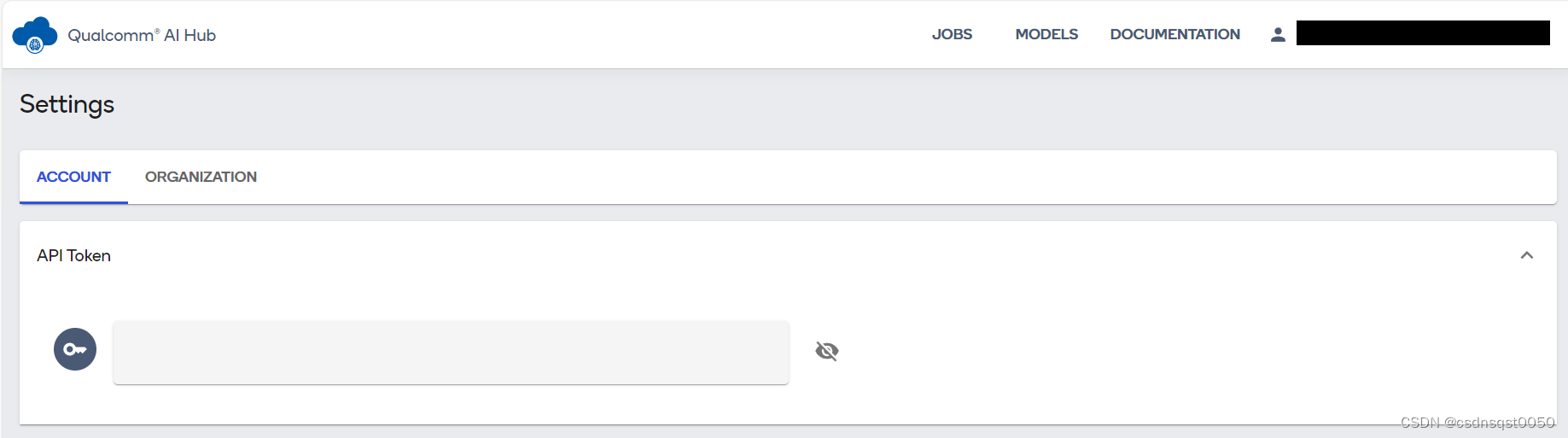
4. 配置API Token
接下来,在终端中使用以下命令使用API令牌配置客户端:
qai-hub configure --api_token INSERT_API_TOKEN
INSERT_API_TOKEN 是你在第3步中生成的token
您可以通过获取可用设备的列表来检查API令牌是否正确安装。为此,您可以在Python终端中键入以下内容:
import qai_hub as hub
hub.get_devices()
第二步. 模型编译部署(PyTorch)
设置好Qualcomm AI Hub环境后,我们演示如何模型给到AI-hub托管的云端设备,完成模型的编译与优化。
首先,安装此示例的依赖项:
pip3 install "qai-hub[torch]"
注意:如果任何代码段因API身份验证错误而失败,则表示您没有安装有效的API Token。请参阅安装说明以了解如何设置。
如果任何代码段因SSL:CERTIFICATE_VERIFY_FAILED错误而失败,则安装了SSL拦截和流量检查工具。请向您的IT部门咨询如何为Python pip和Python请求库设置证书的说明。
提交MobileNet v2网络的性能分析:
from typing import Tuple
import torch
import torchvision
import qai_hub as hub
Using pre-trained MobileNet
torch_model = torchvision.models.mobilenet_v2(pretrained=True)
torch_model.eval()
Trace model
input_shape: Tuple[int, ...] = (1, 3, 224, 224)
example_input = torch.rand(input_shape)
pt_model = torch.jit.trace(torch_model, example_input)
Profile model on a specific device
compile_job, profile_job = hub.submit_compile_and_profile_jobs(
pt_model,
name="MyMobileNet",
device=hub.Device("Samsung Galaxy S23 Ultra"),
input_specs=dict(image=input_shape),
)
这将提交一个编译工作,然后提交一个分析工作,打印这两个工作的URL。可以在
https://app.aihub.qualcomm.com/jobs/ 上查看您的所有作业的结果。
也可以通过编程方式查询工作的状态:
status = profile_job.get_status()
print(status)
您可以使用下面的代码段访问工作的结果。主要有三个部分
Profile:JSON格式的概要文件的结果。
Target Model:已优化的模型可供部署。
Results:包含所有工件(包括日志)的文件夹。
请注意,这些正在阻止等待工作完成的API调用:
#将配置文件结果下载为JSON(blocking call)
profile = profile_job.download_profile()
print(profile)
#下载优化模型(blocking call)
model = profile_job.model.download()
print(model)
#将结果下载到当前目录(blocking call)
profile_job.download_results(".")
作者:高通工程师,戴忠忠(Zhongzhong Dai)
版权归原作者 csdnsqst0050 所有, 如有侵权,请联系我们删除。