
💛 前情提要💛
恭喜大家成功完成
C语言
,入门了这美丽的世界呀
本章节就开始进入
数据结构
啦~
接下来我们即将进入一个全新的空间,对代码有一个全新的视角~
以下的内容一定会让你对
数据结构
有一个颠覆性的认识哦!!!
❗以下内容以
C语言
的方式实现,对于
数据结构
来说最重要的是
思想
哦❗
以下内容干货满满,跟上步伐吧~
作者介绍:
🎓 作者: 热爱编程不起眼的小人物🐐
🔎作者的Gitee:代码仓库
📌系列文章&专栏推荐:
- 🐶《刷题特辑》—实现由小白至入门者的学习记录_专栏
- 😺C语言学习【小白->入门】_全过程_专栏
- 【数据结构】顺序表(增、删、查、改)的实现 [初阶篇_ 复习专用] 📒我和大家一样都是初次踏入这个美妙的“元”宇宙🌏 希望在输出知识的同时,也能与大家共同进步、无限进步🌟
📌导航小助手📌
💡本章重点
- 链表的概念
- 链表
- 链表的实现
- 链表的优缺点
- 一级指针&二级指针接收问题
🍞一.链表的概念
🥐Ⅰ.什么是链表
- 链表是一种
物理存储结构上非连续、非顺序的存储结构 - 数据元素的
逻辑顺序是通过链表中的指针链接次序实现的
❗综上:
链表也符合我们在顺序表中提及的线性表,即链表也是线性表的一种
🥯Ⅱ.总结
✨综上:就是链表的概念啦~
➡️简单来说:链表是
逻辑结构
上类似于顺序表的连续的
结构
,但实际
物理结构
是不一定连续存储的
以下,我们便具体说说为什么?
🍞二.链表
🥐Ⅰ.结构
①逻辑结构
②物理结构
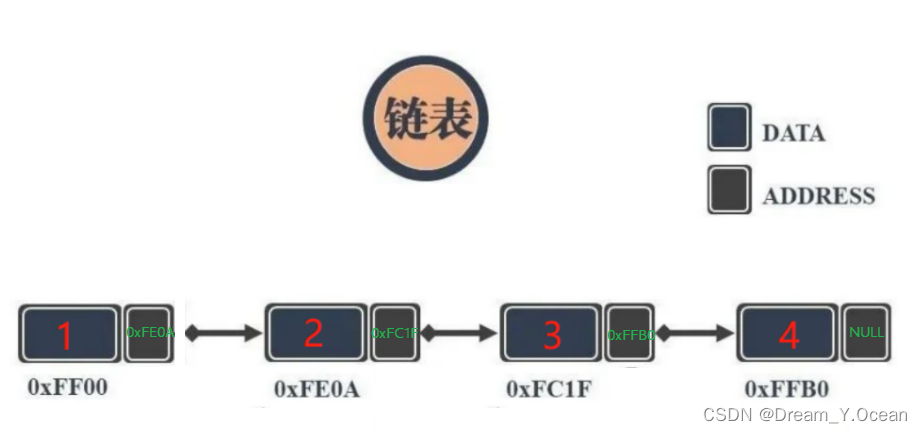
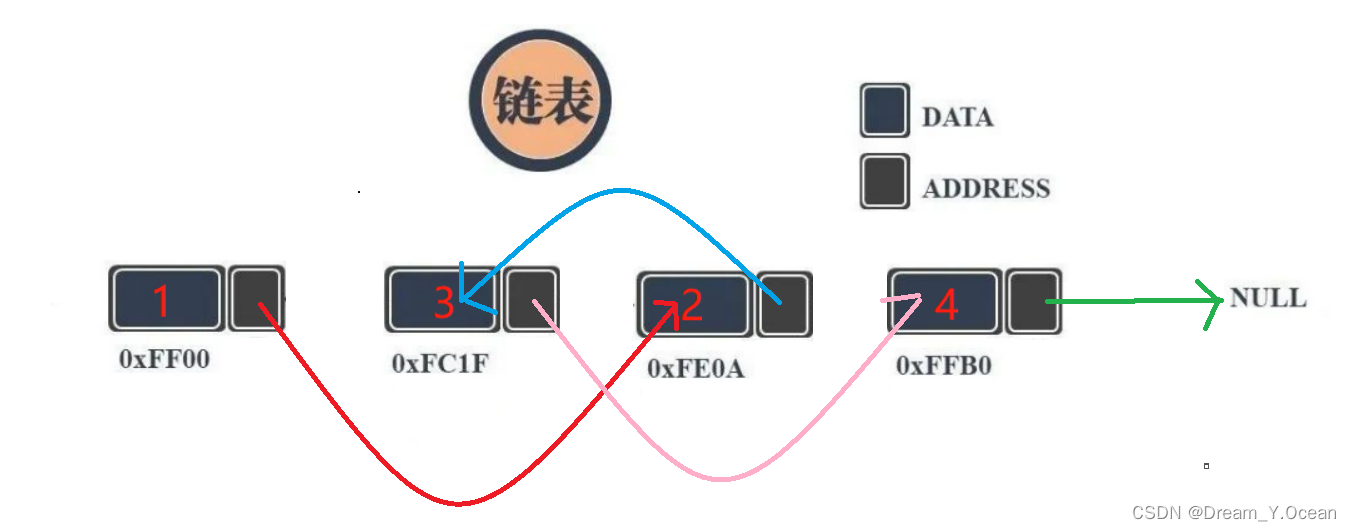
💡综上我们可知:
- 1️⃣链表实际上是由不同的结点
链接而成的【结点是由结构体类型来创建而成的】 - 2️⃣
结点是由数据域【存放数据】和指针域【存放下一个结点的地址】所组成的 - 3️⃣
结点一般是在堆上申请空间的【申请的空间的地址在堆区上是随机分配的,即空间的地址是随机的,这也是为什么每个结点的地址不一定连续】
➡️简单来说:
链表
的元素之间的访问并不像
顺序表
可以通过
下标
进行随机访问
而是通过访问每个结点的
指针域
【指针域内存储了下一个结点的空间地址】,即通过访问下一个结点的地址,去找到下一个结点
所以,链表就是由一个个结点的
指针域
里的地址
链接
起来的,其中元素之间的空间地址并不连续,所以不能像
顺序表
进行
下标访问
这也是为什么链表的
逻辑结构
与
物理结构
不同
【但我们实现的时候只需要依靠
逻辑结构
去实现即可】
✨有了以上对
链表
的概念后,我们便可以实现它啦~
🥐Ⅱ.实现
💡结点: 我们所创建的
结点
都是从
堆区
上申请空间的
➡️简单来说: 使用
动态开辟
在堆区上开辟一个
结点
的空间
Tips: 关于
动态开辟不熟悉的同学可以跳转去🔍【C语言】动态内存管理 [进阶篇_ 复习专用]查看呀
typedefint SLTDataType;typedefstructSlistNode{
SLTDataType data;structSlistNode* next;}SLTNode;
👉由上述我们可知:
结点本质是
结构体类型
,结构体内包含了
数据域
与
后驱指针域
SLTDataType* data用来存储数据struct SlistNode* next;是用来指向下一个结点的地址,达到结点之间链接的目的
✨综上:
- 链表可以根据存储的数据多少实现随时创建结点【动态开辟】进行链接,不会存在空间的浪费
- 所以下面我们实现
链表的接口
❗此处我们实现的是基础的
单向不带头不循环链表
🍞三.链表插口实现
对于数据结构的接口实现,一般围绕
增、
删、
查、
改的内容
💡如下的实现围绕此原码进行:
typedefint SLTDataType;typedefstructSlistNode{
SLTDataType data;structSlistNode* next;}SLTNode;
🥐Ⅰ.创建新结点
1️⃣创建新结点的函数声明:
SLTNode*BuySLTNode(SLTDataType x);
2️⃣创建新结点函数的实现:
SLTNode*BuySLTNode(SLTDataType x){
SLTNode*node =(SLTNode*)malloc(sizeof(SLTNode));
node->data = x;
node->next =NULL;return node;}
🥐Ⅱ.尾插链表
👉简单来说: 对链表进行尾部链接一个新的结点
➡️实现: 通过访问链表走到链表最后一个结点,将此结点的
next
指向新的结点
❗特别注意: 当链表为
NULL
(空表)的时候,尾插即是在头插
✊图例:
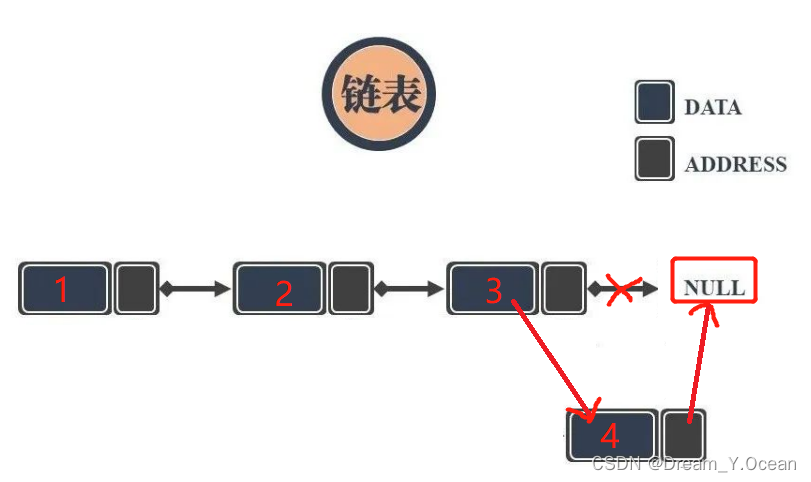
1️⃣尾插的函数声明:
voidSListPushBack(SLTNode** pplist, SLTDataType x)
2️⃣尾插函数的实现:
voidSListPushBack(SLTNode** pplist, SLTDataType x){//创建新结点
SLTNode* newnode =BuySLTNode(x);if(*pplist ==NULL){*pplist = newnode;}else{
SLTNode* tail =*pplist;while(tail->next !=NULL){
tail = tail->next;}//将新结点 链接到 链表上去
tail->next = newnode;}}
🥐Ⅲ.头插链表
👉简单来说: 对链表进行头部链接一个结点
➡️实现: 直接插入到原链表的第一个结点之前
❗特别注意:
- 即使是
NULL(空表),也可以实现头插 - 注意插入顺序,如果顺序反了,会丢失后面结点的地址,找不到后面结点
✊图例:
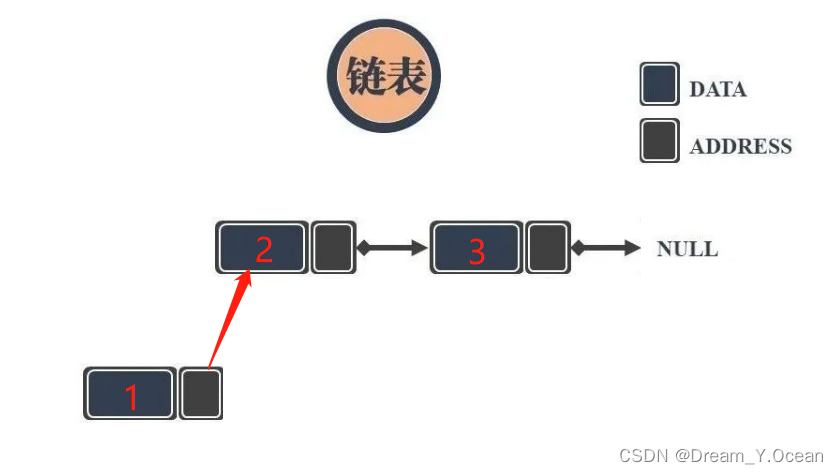
1️⃣头插的函数声明:
voidSListPushFront(SLTNode** pplist, SLTDataType x);
2️⃣头插函数的实现:
voidSListPushFront(SLTNode** pplist, SLTDataType x){//头插并不需要找头 --- 因为一上来就是 头了
SLTNode* newnode =BuySLTNode(x);
newnode->next =*pplist;*pplist = newnode;}
🥐Ⅳ.尾删链表
👉简单来说: 对链表进行删除最后一个结点
➡️实现: 遍历到链表到最后一个结点,并将其结点释放,且将倒数第二个结点的
next
置为
NULL
❗特别注意: 有三种情况需要特别分析
- ①链表为
NULL(空链表) - ②链表只有一个结点的情况
- ③此处需要应
二级指针接收,否则会产生野指针的问题
✊图例:
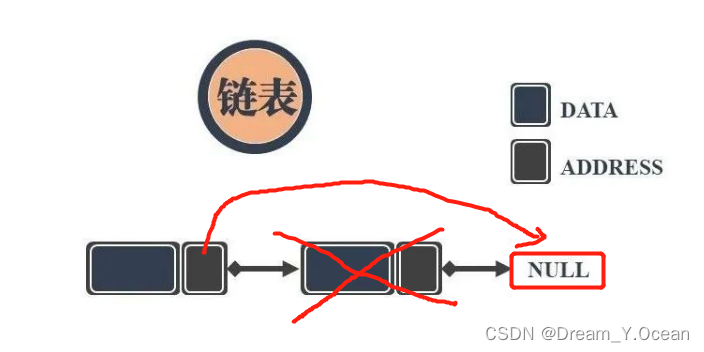
❤️什么时候用二级指针接收,什么时候用一级指针接收的问题我们留到最后面再细细讨论
✨此处我们先记住结论: 凡是需要修改头指针所指向的位置的时候,就需要传头指针的地址上来【即需要用
二级指针
接收】
1️⃣尾删的函数声明:
voidSListPopBack(SLTNode** pplist);
2️⃣尾删函数的实现:
voidSListPopBack(SLTNode** pplist){//先找尾
SLTNode* tail =*pplist;
SLTNode* prev =NULL;//1.链表为NULLif(*pplist ==NULL){return;}//2.只有一个结点的情况elseif((*pplist)->next ==NULL){free(*pplist);*pplist =NULL;}else{while(tail->next !=NULL){
prev = tail;
tail = tail->next;}free(tail);
tail =NULL;
prev->next =NULL;}}
🥐Ⅴ.头删链表
👉简单来说: 对链表进行删除第一个结点
➡️实现: 记住链表的第二个结点,然后释放头结点,让第二个结点当新的头结点
❗特别注意: 有三种情况需要特别分析
- ①链表为
NULL(空链表) - ②链表只有一个结点的情况
- ③此处需要应
二级指针接收,否则会产生野指针的问题
✊图例:
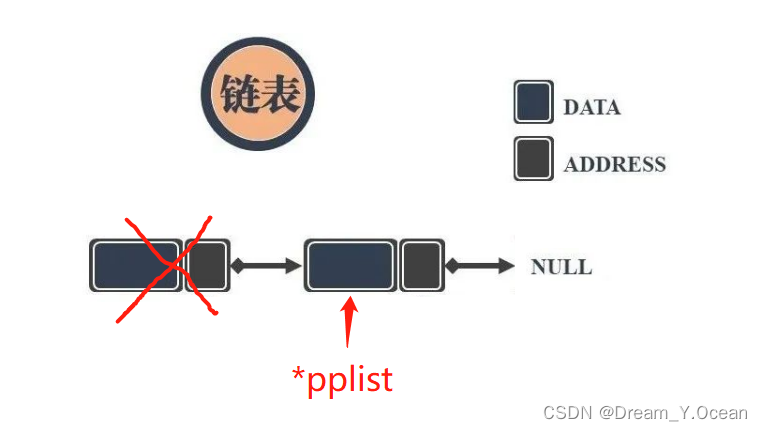
1️⃣头删的函数声明:
voidSListPopFront(SLTNode** pplist);
2️⃣头删函数的实现:
voidSListPopFront(SLTNode** pplist){if(*pplist ==NULL){return;}else{
SLTNode* next =(*pplist)->next;free(*pplist);*pplist = next;}}
🥐Ⅵ.查找链表结点
👉简单来说: 对链表进行查找所需的结点
➡️实现: 遍历链表表一一比较查找是否有我们想要的结点
- 没有,则返回
NULL - 有,则返回当前结点的
地址
1️⃣查找链表结点的函数声明:
SLTNode*SListFind(SLTNode*plist, SLTDataType x);
2️⃣查找链表结点函数的实现:
SLTNode*SListFind(SLTNode*plist, SLTDataType x){
SLTNode*cur = plist;while(cur){if(cur->next == x){return cur;}
cur = cur->next;}returnNULL;}
🥐Ⅶ.对某结点后插
👉简单来说: 对链表的某个结点后进行插入
➡️实现: 类似于尾插的步骤
❗特别注意:
- 需要判断要被后插的这个位置的结点是否存在
- 注意插入顺序,如果顺序反了,会丢失后面结点的地址,找不到后面结点
✊图例:
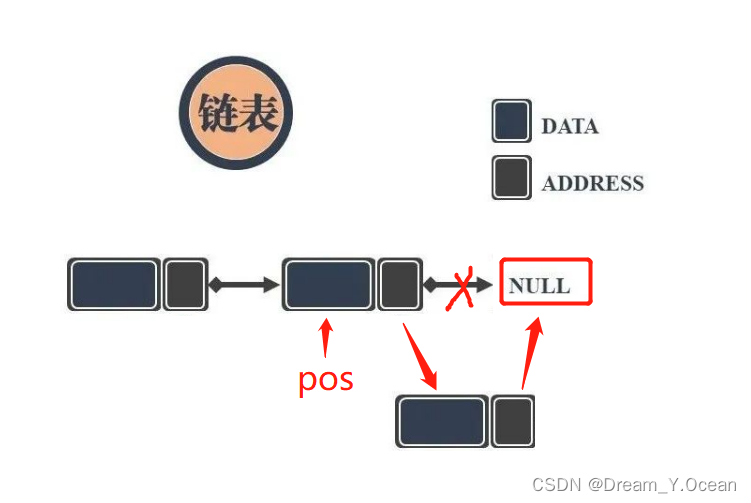
1️⃣对某结点后插的函数声明:
voidSListInsertAfter(SLTNode* pos, SLTDataType x);
2️⃣对某结点后插函数的实现:
voidSListInsertAfter(SLTNode* pos, SLTDataType x){assert(pos);
SLTNode* newnode =BuySLTNode(x);
newnode->next = pos->next;
pos->next = newnode;}
🥐Ⅷ.对某结点前插
👉简单来说: 对链表的某个结点前进行插入
➡️实现: 类似于头插的步骤
❗特别注意:
- 需要判断要被后插的这个位置的结点是否存在
- 此处有可能为对链表进行
头插的情况,我们便可以复用头插接口
✊图例:
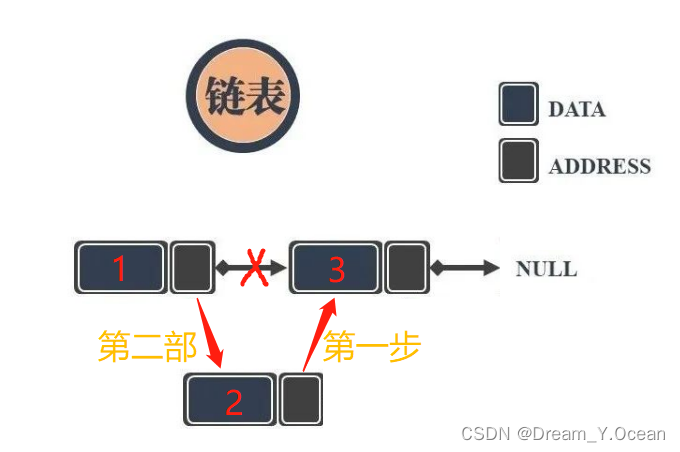
1️⃣对某结点前插的函数声明:
voidSListInsert(SLTNode** pplist,SLTNode* pos, SLTDataType x);
2️⃣对某结点前插函数的实现:
voidSListInsert(SLTNode** pplist,SLTNode* pos, SLTDataType x){assert(pos);
SLTNode* newnode =BuySLTNode(x);if(pos ==*pplist)//此时相当于头插{SListPushFront(pplist, SLTDataType x);}else{
SLTNode* prev =NULL;
SLTNode* cur =*pplist;while(cur != pos){
prev = cur;
cur = cur->next;}
prev->next = newnode;
newnode->next = pos;}}
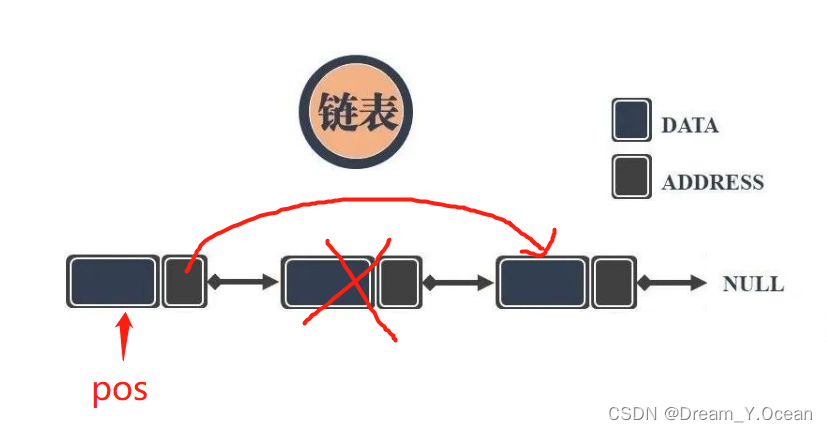
🥐Ⅸ.对某节点后删
👉简单来说: 对链表的某个结点进行后删
➡️实现: 记住这个结点和要删除的结点的
next
,然后进行后删除释放即可
❗特别注意:
- 对某结点进行后删,但不能对
最后一个结点进行后删 - 需要判断要被后删的这个位置的结点是否存在
✊图例:
1️⃣对某节点后删的函数声明:
voidSListEraseAfter(SLTNode*pos);
2️⃣对某节点后删函数的实现:
voidSListEraseAfter(SLTNode*pos){assert(pos);if(pos->next ==NULL){return;}else{
pos->next = pos->next->next;free(pos->next);}}
💡我们一般不实现
某位置前删
的接口,因为对于单链表来说没必要,此功能我们放到
带头循环双向链表
中提及
🥐Ⅹ.打印链表
👉简单来说: 对链表逐个遍历打印
➡️实现: 遍历链表一一打印即可
1️⃣打印链表的函数声明:
voidSListPrint(SLTNode* plist);
2️⃣打印链表函数的实现:
voidSListPrint(SLTNode* plist){
SLTNode* cur = plist;while(cur !=NULL){printf("%d ", cur->data);
cur = cur->next;}printf("\n");}
🥐Ⅺ.销毁链表
👉简单来说: 对链表进行销毁,释放内存空间
➡️实现: 逐一遍历链表结点,然后逐个释放
1️⃣销毁链表的函数声明:
voidSListDestroy(SListNode** pphead)
2️⃣销毁链表函数的实现:
voidSListDestroy(SLTNode** pphead){assert(pphead);
SLTNode* cur =*pphead;while(cur){
SLTNode* next = cur->next;free(cur);
cur = next;}*pphead =NULL;}
🥯Ⅻ.总结
✨综上:就是单向链表接口实现的内容啦~
➡️相信大家对
单链表
有不一样的看法了吧🧡
🍞四.链表的优缺点
🔵优点:
- 可以按需申请内存【不会存在像
顺序表一样的内存浪费】,需要存一个数据,就申请一块内存 - 任意位置都是
O(1)时间内插入、删除数据
🔴缺点:
- 不支持下标的
随机访问【访问的时候,需要从头往后找】
🍞五.一级指针&二级指针接收问题
❓综上,我们看到有些链表接口的形参为
一级指针
接收,有些则是
二级指针
接收,这是为什么呢
➡️如图:
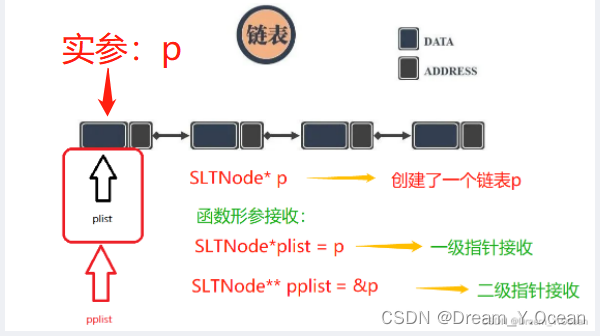
💡此刻,我们便知道:
- 1️⃣如果用
一级指针接收,相当于在接口函数内部创建了一个实参的临时拷贝,即存的依然是地址,后续的结点访问也是通过访问地址正常修改链表- 但唯独头结点p的指向无法被修改,因为即使修改了头结点,也只是对函数的形参plist这个临时头结点的指向进行了修改,但正真的头结点p的指向没有被修改,那下次再传p的话,相当于传的是这个链表的头还处于没有被修改的地址 - 2️⃣如果用
二级指针接收,则相当于把头结点p这个变量的地址传给接口,即pplist = &p,*pplist = p,这样在函数内部对*pplist这个头结点的指向进行修改,真正的头结点p也会跟着修改
✨综上,我们便可以总结出:
- 若接口需要改
头结点指向的时候时,需要传头结点的地址,即用二级指针接收 - 若不需要,则传
头结点,即用一级指针接收即可
🫓总结
综上,我们基本了解了数据结构中的 “链表” 🍭 的知识啦~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
版权归原作者 Dream_Y.Ocean 所有, 如有侵权,请联系我们删除。