
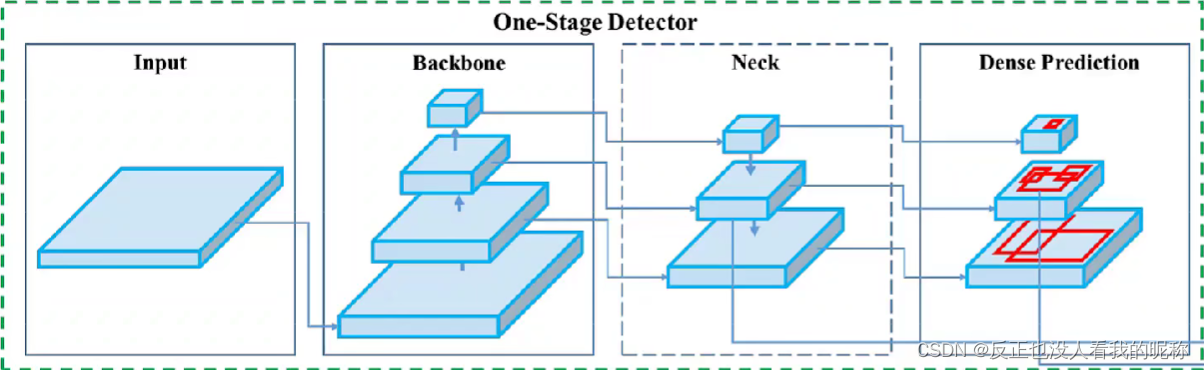
相对于一些早期的检测网络,比如faster-Rcnn来说,网络的架构一般分为,图像输入模块,backbone主干网络,Neck颈部模块,检测头Dense Prediction检测模块。
backbone主干网络一般由:VGG16,Resnet50,ResneXt101,Darknet53等网络构成。
Neck颈部模块一般是一些:FPN,PANet,Bi-FPN等功能块组成,一般实现的功能基础都是上采样。
但是在Yolov5中,作者没有单独给出Neck颈部模块, 而是打包一起放在了头部模块。 Yolov5的主干网络主要是由Focus,BottleneckCSP,SPP功能模块构成。 ** 头部网络**主要是由PANet+Detect(也就是Yolov3/v4的原头部网络)构成。
这里我们先去下载Yolov5的原文件
下载地址:https://github.com/ultralytics/yolov5
可以看到在models文件夹下有一堆.yaml文件,这个就是yolov5的网络架构参数文件,有不同的版本,大体的框架是一样的,这里由yolov5s版本举例。先看代码
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
代码由4部分组成,最上面的控制参数,anchors先验框的配置,backbone主干网络设置,head头部网络设置。
控制参数:
# Parameters
nc: 80 # number of classes 类别数
depth_multiple: 0.33 # model depth multiple 控制模型的深度(BottleneckCSP数)
width_multiple: 0.50 # layer channel multiple 控制conv通道个数 (卷积核数量)
# depth_multiple表示BottleneckCSP模块的层缩放因子,将所有的BottleneckCSP模块的Bottleneck乘上该参数得到最终的个数
# width_multiple表示卷积通道的缩放因子,就是将配置里面的backbone和head部分有关conv通道设置,全部乘以该系数
# 通过这两个参数就可以实现不同复杂度的模型设计。
anchors先验框的配置:
anchors:
- [10,13, 16,30, 33,23] # P3/8 8倍下采样的层面 [宽度,高度]
- [30,61, 62,45, 59,119] # P4/16 16倍下采样的层面
- [116,90, 156,198, 373,326] # P5/32 32倍下采样的层面
backbone主干网络设置:
backbone:
# [from, number, module, args]
# from:当前模块输入来自哪一层,-1表示上一层输入
# number:本模块重复次数,1表示只有一个,3表示有3个相同的模块
# conv卷积层 C3:BottleneckCSP SPPF:SPP模块
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 128表示有128个卷积核,3表示3×3的卷积核,2步长为2
[-1, 3, C3, [128]], # 这里的重复次数,要乘上一开始的缩放因子
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
head头部网络设置:
# 作者没有区分neck模块, 所以里面包含了PANet + Detect部分
head:
[[-1, 1, Conv, [512, 1, 1]], # 卷积层
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 上采样
[[-1, 6], 1, Concat, [1]], # cat backbone P4 拼接层
[-1, 3, C3, [512, False]], # 13 这里的重复次数,要乘上一开始的缩放因子
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
这里需要注意的是这两个参数depth_multiple用于控制模型的深度(BottleneckCSP数),width_multiple用于控制conv通道个数 (卷积核数量)。只要牵涉到CSP操作和conv操作的时候就要用该参数,去乘上重复次数,已达到对模型深度的控制。
# yolov5l版本
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# yolov5m版本
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# yolov5n版本
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# yolov5s版本
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# yolov5x版本
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
这里可以看出,官方提供的不同版本的主要区别就是模型深度的不同,不同深度的模型,计算量也不一样,有的多,有的少。对于不同的场景,所需要的模型计算量是不一样的,也不是越深的模型越好,视情况而定,杀鸡焉用牛刀。
Yolov5sYolov5mYolov5LYolov5xdepth_multiple0.330.671.01.33width_multiple0.50.751.01.25BottleneckCSP数(BCSP True)1,3,32,6,63,9,94,12,12BottleneckCSP数(BCSP False)1234Conv卷积核数量32,64,128,256,51248,96,192,384,76864,128,256,512,102480,160,320,640,1280
yolov5网络整体架构流程
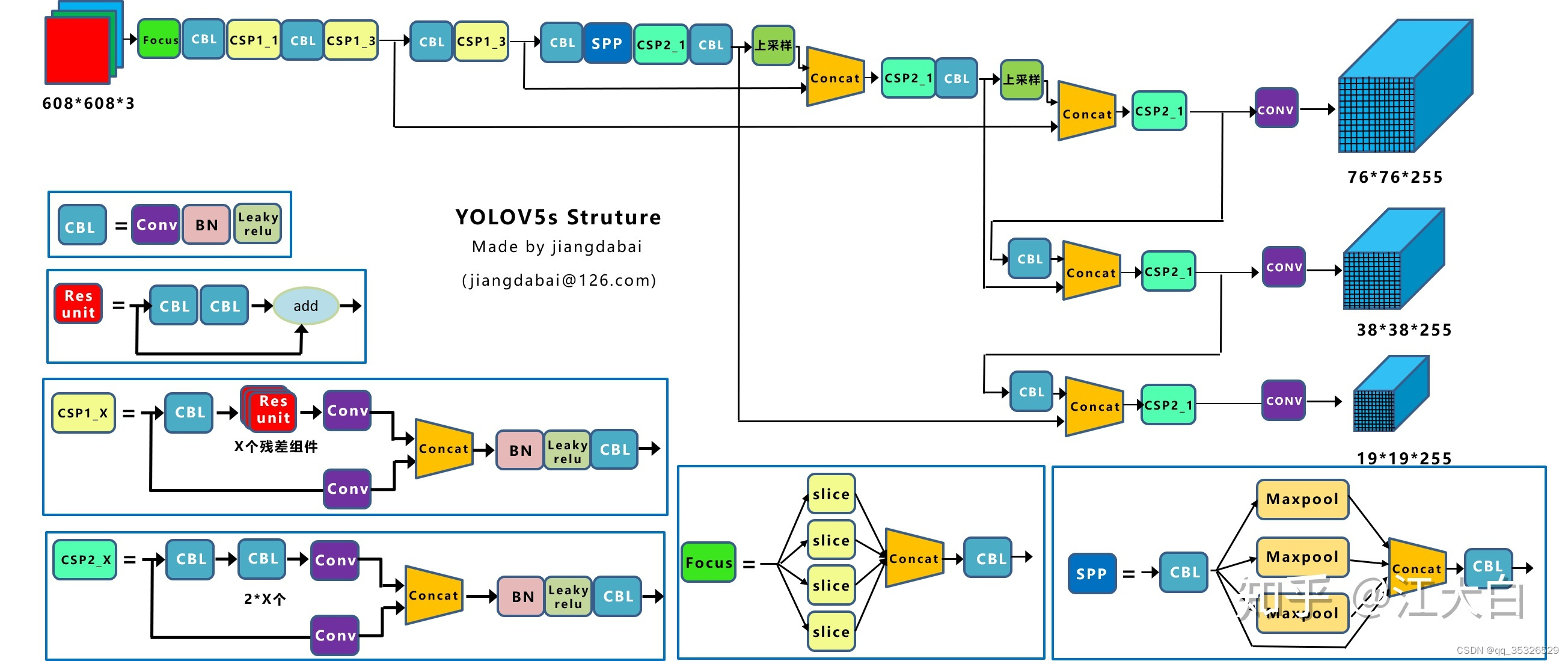
Focus操作
我们可以看到图像最先输入进去之后进行了一个Focus处理。
这个操作就是把数据先切分成4分,每份数据就相当于下采样两倍得到,然后在channel维度进行拼接,然后再进行卷积操作。
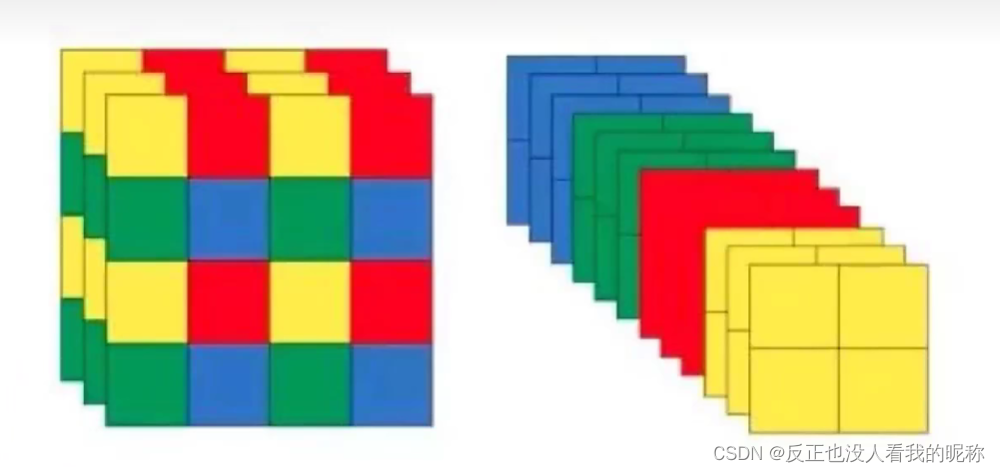
就相当于图像的数据没有什么变动,但是多了4倍的数据量。大大提高了原始数据量。这个原理相当于这个视频。
神奇!一张狗狗照片,裁碎竟变四张_哔哩哔哩_bilibili
将细节更好的显现出来。
SPP空间金字塔池化
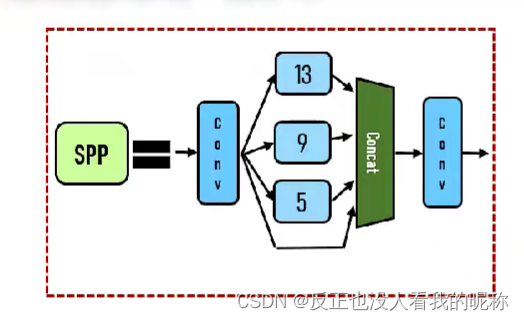
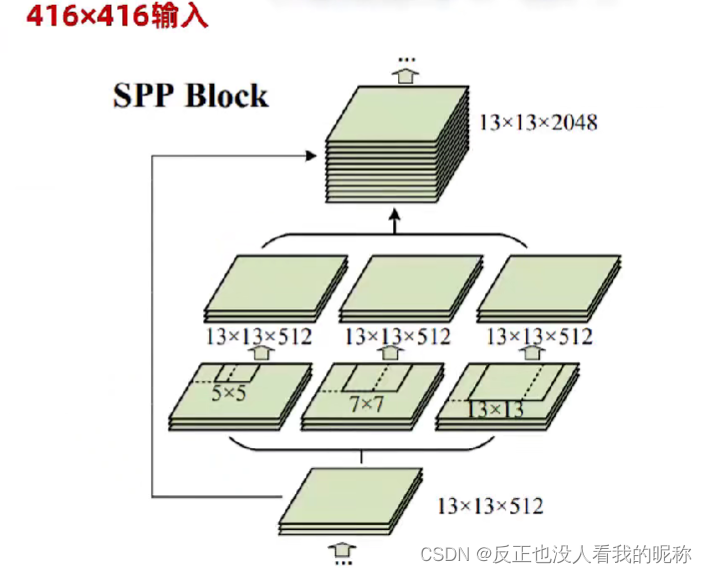
上图非常清晰的表现出,整个池化的过程。但是在第一次卷积的过程中会因为使用的卷积核大小不一样,导致没办法进行张量的拼接。作者直接采用了填充的方式硬生生的拼了上去。
参考:
深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎
【目标检测新手首选】PyTorch从零带你搭建YOLOV5目标检测平台!-人工智能/计算机视觉/深度学习_哔哩哔哩_bilibili
版权归原作者 反正也没人看我的昵称 所有, 如有侵权,请联系我们删除。