
还是学习啊 勿怪勿怪 给自己好保存而已哦

论文地址:https://arxiv.org/pdf/2104.11892.pdf
whaosoft aiot http://143ai.com
此分享中调查了基于深度学习的目标检测器的最新发展。还提供了检测中使用的基准数据集和评估指标的简明概述,以及检测任务中使用的一些突出的主干架构。它还涵盖了边缘设备上使用的当代轻量级分类模型。最后,我们比较了这些架构在多个指标上的性能。
背景
- 问题陈述
目标检测是物体分类的自然延伸,其目的只是识别图像中的物体。目标检测的目标是检测预定义类的所有实例,并通过轴对齐框在图像中提供其粗略定位。检测器应该能够识别目标类的所有实例并在其周围绘制边界框。它通常被视为一个有监督的学习问题。现代目标检测模型可以访问大量标记图像进行训练,并在各种规范基准上进行评估。

- 目标检测的主要挑战
计算机视觉在过去十年中取得了长足的进步,但仍有一些重大挑战需要克服。网络在现实生活应用中面临的一些关键挑战包括:

• 类内变化:同一目标的实例之间的类内变化在本质上是相对常见的。这种变化可能是由于各种原因造成的,例如遮挡、照明、姿势、视点等。这些不受约束的外部可能会对目标外观产生巨大影响。预计目标可能具有非刚性变形或旋转、缩放或模糊。一些物体可能有不显眼的环境,使提取变得困难。
• 类别数量:可用于分类的目标类别的绝对数量使其成为一个难以解决的问题。它还需要更多高质量的标签数据,这很难获得。使用更少的示例来训练检测器是一个开放的研究问题。
• 效率:当今的模型需要大量计算资源来生成准确的检测结果。随着移动和边缘设备的普及,高效的物体检测器对于计算机视觉领域的进一步发展至关重要。
数据集和评估指标


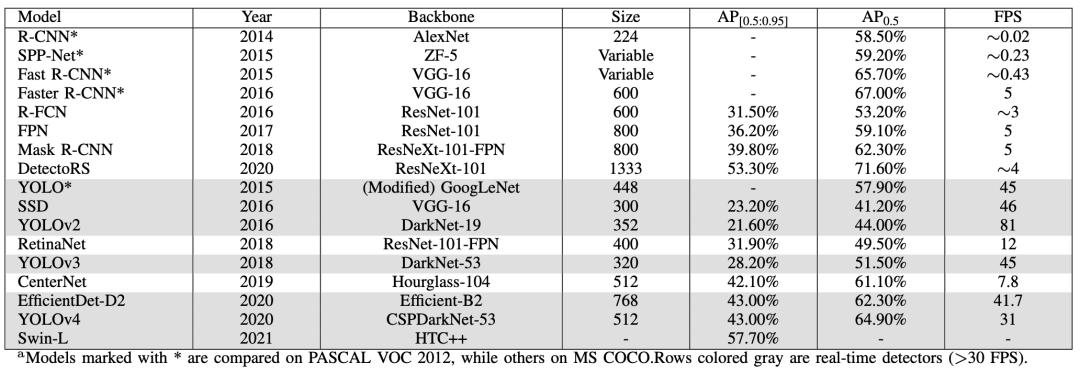
目标检测器使用多个标准来衡量检测器的性能,即每秒帧数 (FPS)、精度和召回率。然而,平均精度(mAP)是最常见的评估指标。精度来自于联合交集(IoU),它是GT实况与预测边界框之间的重叠面积与联合面积的比值。设置阈值以确定检测是否正确。如果IoU大于阈值,则将其分类为True Positive,而IoU低于阈值则将其分类为False Positive。如果模型未能检测到地面实况中存在的对象,则称为假阴性。精度衡量正确预测的百分比,而召回衡量关于基本事实的正确预测。
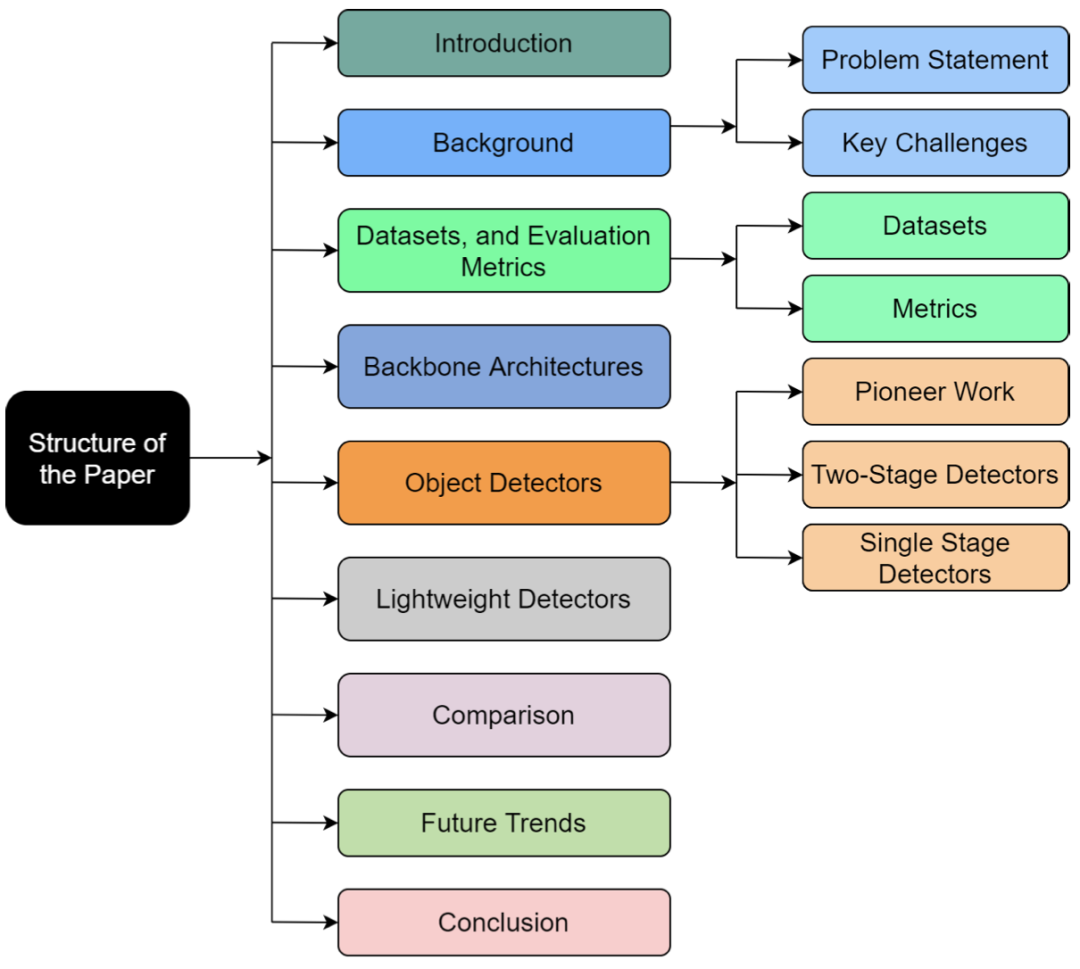
常见主干网络
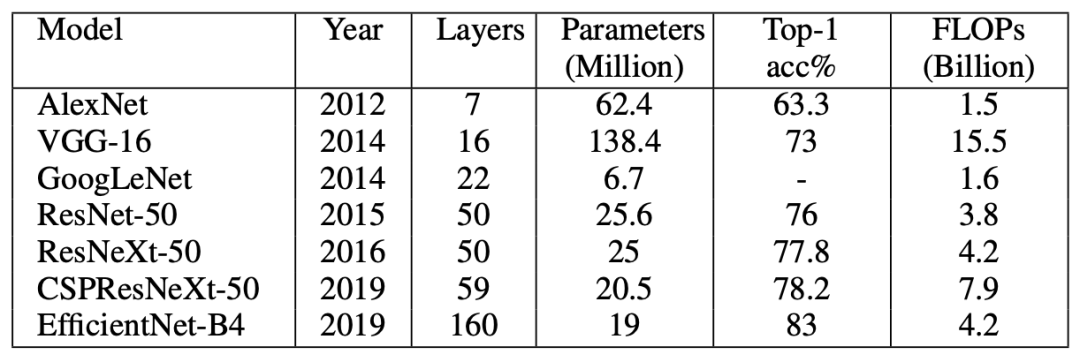
常见目标检测框架
我们根据两种类型的检测器(两级和单级检测器)划分了这篇评论。然而,我们也讨论了开创性的工作,我们简要检查了一些传统的物体检测器。具有生成区域建议的单独模块的网络称为两阶段检测器。这些模型在第一阶段尝试在图像中找到任意数量的对象建议,然后在第二阶段对它们进行分类和定位。由于这些系统有两个独立的步骤,它们通常需要更长的时间来生成候选,具有复杂的架构并且缺乏全局上下文。
单级检测器使用密集采样在一次过程中对目标进行分类和定位。他们使用各种比例和纵横比的预定义框/关键点来定位目标。它在实时性能和更简单的设计方面超越了两级检测器。

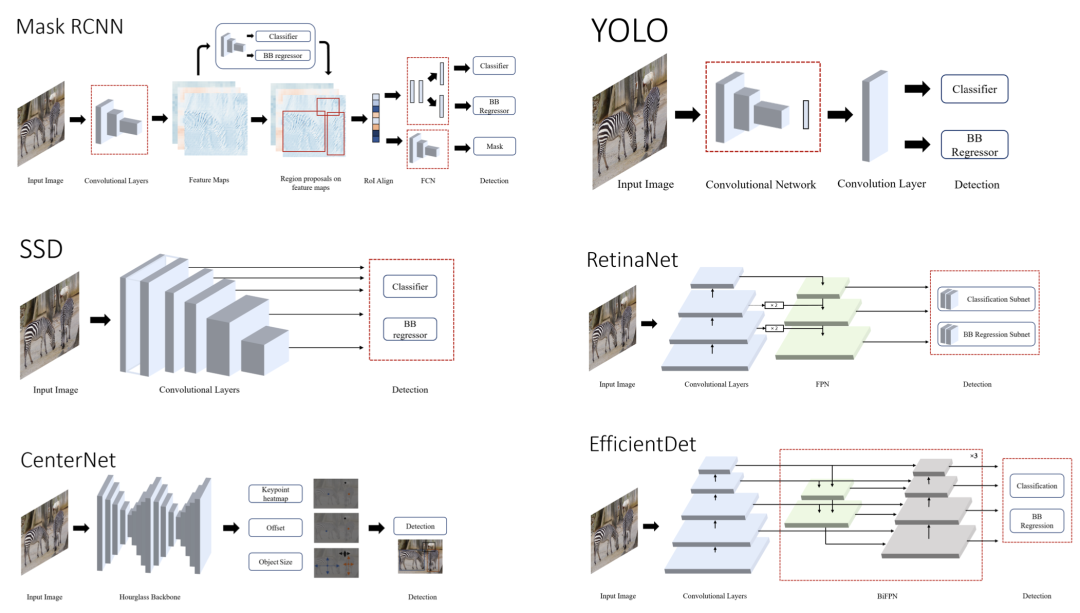
轻量级网络
近年来形成了一个新的研究分支,旨在为物联网 (IoT) 部署中常见的资源受限环境设计小型高效网络。这种趋势也渗透到了强大的物体检测器的设计中。可以看出,尽管大量目标检测器实现了出色的准确性并实时执行推理,但这些模型中的大多数都需要过多的计算资源,因此无法部署在边缘设备上。
过去,许多不同的方法都显示出令人兴奋的结果。利用高效组件和压缩技术,如修剪、量化、hashing等,提高了深度学习模型的效率。使用经过训练的大型网络来训练较小的模型,称为蒸馏,也显示出有趣的结果。然而,在本节中,我们将探讨一些用于在边缘设备上实现高性能的高效神经网络设计的突出示例。
版权归原作者 tt姐 所有, 如有侵权,请联系我们删除。