
1.研究背景与意义
随着人工智能技术的不断发展,深度学习已经成为计算机视觉领域的重要研究方向之一。在图像识别领域,卷积神经网络(Convolutional Neural Networks,CNN)已经取得了显著的成果。然而,传统的卷积神经网络在花卉信息识别方面仍然存在一些挑战,如花卉种类较多、花卉外观差异较大等问题。因此,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究意义。
首先,花卉是自然界中的重要组成部分,具有丰富的物种和品种。花卉的种类繁多,外观差异大,对于一般人来说,很难准确地识别花卉的种类和特征。而基于深度学习和改进卷积神经网络的花卉信息识别系统可以通过学习大量的花卉图像数据,自动识别花卉的种类和特征,为花卉爱好者、园艺师和植物学家提供准确的花卉信息。
其次,花卉信息识别系统对于花卉市场和花卉产业的发展具有重要的推动作用。随着人们对于生活品质的要求不断提高,花卉市场呈现出快速增长的趋势。然而,花卉市场的发展受到花卉信息的限制,人们往往需要依靠专业人士或者花卉书籍来识别花卉的种类和特征。基于深度学习和改进卷积神经网络的花卉信息识别系统可以提供快速、准确的花卉信息,帮助消费者更好地了解和选择花卉,促进花卉市场的发展。
此外,基于深度学习和改进卷积神经网络的花卉信息识别系统还可以为生态环境保护和植物研究提供支持。在生态环境保护方面,花卉是生态系统中的重要组成部分,通过识别花卉的种类和特征,可以更好地了解和保护生态环境。在植物研究方面,花卉是植物学研究的重要对象,通过识别花卉的种类和特征,可以更好地研究植物的生长、繁殖和适应环境的能力。
综上所述,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究背景和意义。通过该系统,可以实现花卉种类和特征的自动识别,为花卉爱好者、园艺师和植物学家提供准确的花卉信息;促进花卉市场的发展,提高消费者对花卉的了解和选择能力;支持生态环境保护和植物研究,促进生态环境的保护和植物学研究的进展。因此,基于深度学习和改进卷积神经网络的花卉信息识别系统具有重要的研究价值和应用前景。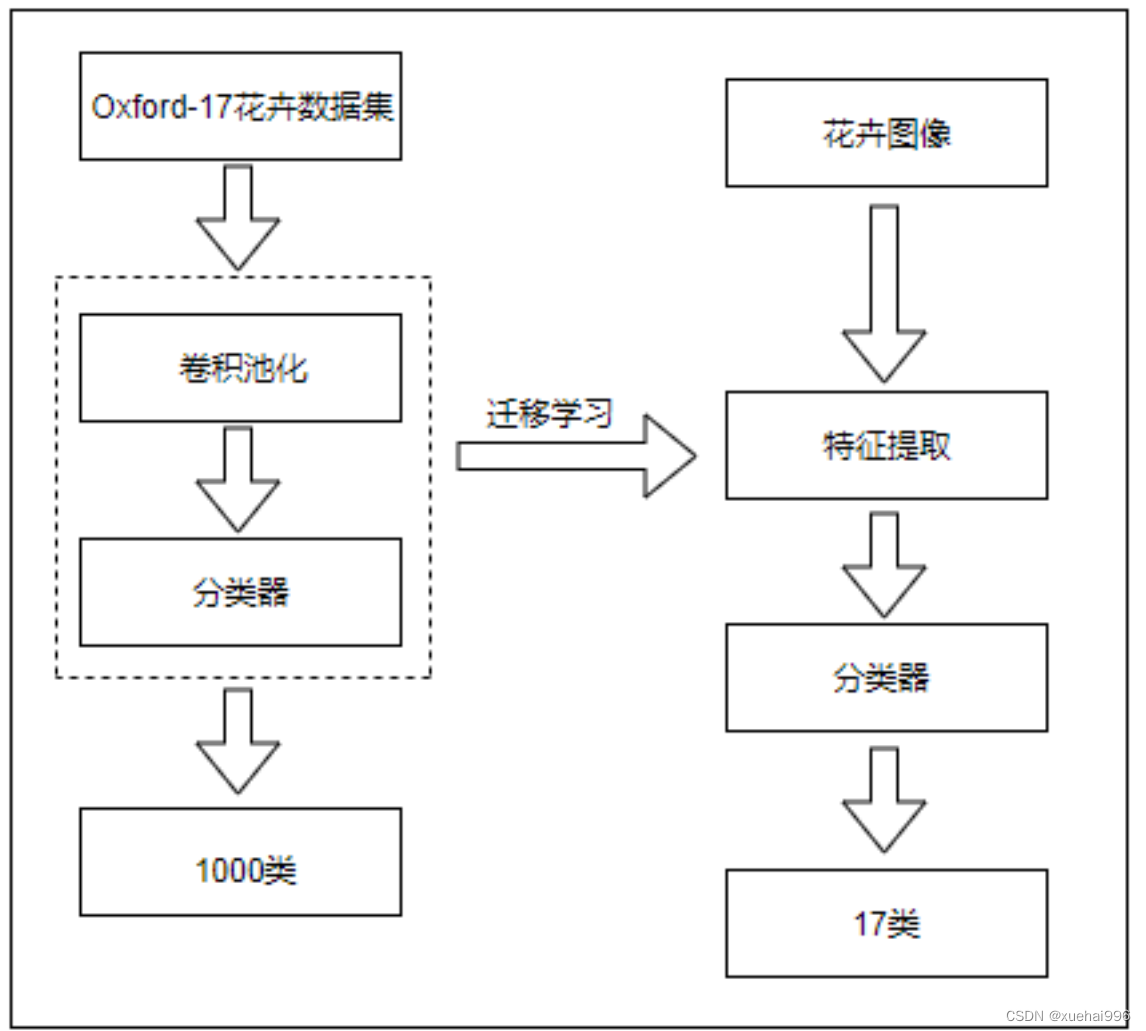
2.图片演示



3.视频演示
基于深度学习和改进卷积神经网络的花卉信息识别系统_哔哩哔哩_bilibili
4.算法流程图
花卉种类识别功能实现的主要途径是利用计算机对样本进行分类。通过对样本的精准分类达到得出图像识别结果的目的。经典的花卉识别设计如图所示,这几个过程相互关联而又有明显区别。
卷积神经网络
卷积神经网络是受到生物学启发的深度学习经典的多层前馈神经网络结构。是一种在图像分类中广泛使用的机器学习算法。
CNN 的灵感来自我们人类实际看到并识别物体的方式。这是基于一种方法,即我们眼睛中的神经元细胞只接收到整个对象的一小部分,而这些小块(称为接受场)被组合在一起以形成整个对象。
与其他的人工视觉算法不一样的是CNN可以处理特定任务的多个阶段的不变特征。卷积神经网络使用的并不像经典的人工神经网络那样的全连接层,而是通过采取局部连接和权值共享的方法,来使训练的参数量减少,降低模型的训练复杂度。
CNN在图像分类和其他识别任务方面已经使传统技术的识别效果得到显著的改善。由于在过去的几年中卷积网络的快速发展,对象分类和目标检测能力取得喜人的成绩。
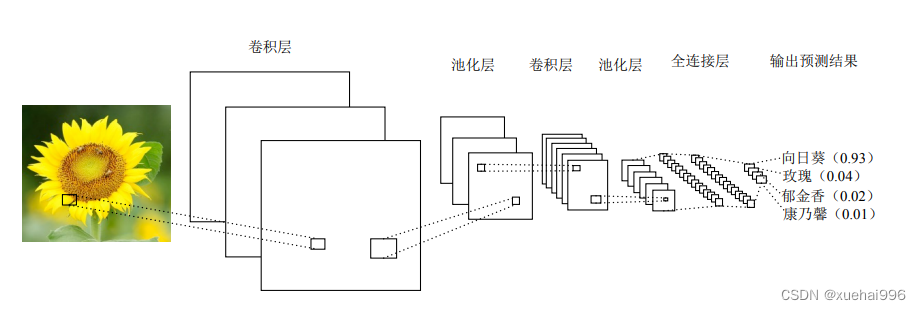
典型的CNN含有多个卷积层和池化层,并具有全连接层以产生任务的最终结果。在图像分类中,最后一层的每个单元表示分类概率。
下图为一个经典卷积神经网络结构。
残差网络(ResNet)
ResNet是功能最强大的深度神经网络之一,在ILSVRC 2015分类挑战中获得了惊人的性能结果。ResNet在其他识别任务上取得了出色的泛化性能,并在ILSVRC和COCO 2015竞赛中获得了ImageNet检测,ImageNet定位,COCO检测和COCO分割方面的第一名。
ResNet 体系结构有很多变体,即相同的概念,但层数不同。有 ResNet-18,ResNet-34,ResNet-50 ,ResNet-101,ResNet-110,ResNet-152,ResNet-164,ResNet-1202。带有两个或多个数字的 ResNet名称仅表示具有一定数量的神经网络层的ResNet体系结构。
深度残差网络提出了捷径连接(shorcut connections,SR) ,利用跳过连接或快捷方式跳过某些层来实现此目的,在保证网络之间数据畅通的前提下,避免了由于梯度损失引起的拟合不足的问题,加深了网络层次,有效地改善了模型的表示性。典型的ResNet模型是通过包含非线性(ReLU)和介于两者之间的批量归一化的双层或三层跳过实现的。
残差学习
残差在数理统计领域中是指实际观察值与估计值之间的差。如果回归模型正确的话,通常也可以将残差看作误差的观测值。
在神经网络中,假设H(x)代表输入样本x后多层神经网络的相应输出。根据神经网络理论,H(x)可以适合任何函数。假设输入输出维度相同。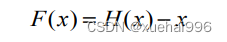
如图所示: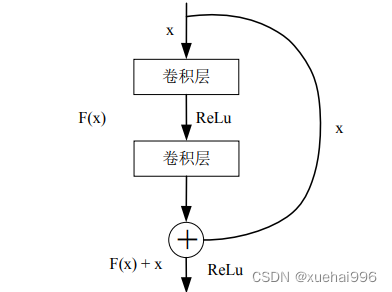
ResNet是一种由残差块组成的架构类型。它是一堆规则层的堆叠,例如卷积和批处理,其输入不仅流经权重层,还流过捷径连接。最后,将两条路径相加。Resnet使我们有机会添加更多的网络层,建议的标准层数为18、34、50、101 和152。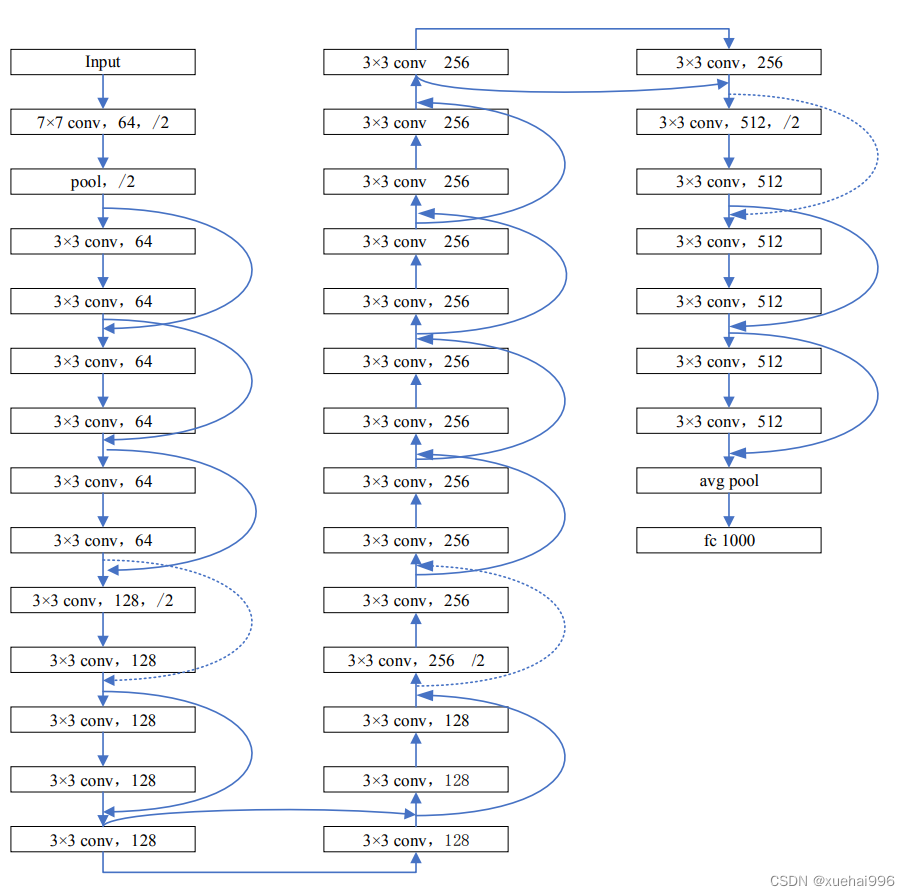
细粒度图像分类(Fine-Grained Categorization),是近年来深度学习里较热门的研究课题。它参考粗粒度的类别划分,在其基础上追求更加细致的子类划分,它类别精度更加细致,类间差异更加细微,往往只能以微小的局部差异才能进行类别区分[4。细粒度图像分类还受到一些因素的困扰,例如光照和背景干扰等。因此,它是一项非常具有挑战性的研究任务。近年来,随着深度学习的发展,专家们开始尝试将各种深度学习的相关技术应用于细粒度图像分类。由于从深度卷积神经网络中提取的特征拥有强大的描述力,更能代表代表物体的本质,他们将深度卷积神经网络应用于细粒度图像分类,再结合一些新型特征算法,这将会极大提高细粒度图像分类的准确度。
花卉图像分类属于细粒度图像分类,背景复杂,花卉部分是整个分类任务中重点关注区域,卷积神经网络对于花卉部分颜色、形状等重要因素的学习来实现花卉图像分类识别。可是现实情况中,有的图像花卉部分占据很大部分,有的图像花卉部分在整幅图像中只占据很小一部分,不相关部分背景的复杂干扰,还有茎和叶的干扰,这些都极大的增加了花卉图像分类任务的难度。为了解决这个困扰,可在卷积神经网络中添加注意力机制,抑制复杂背景的干扰。
添加注意力机制的花卉图像分类识别模型结构
由前一章可知,在众多卷积神经网络模型中,通过实验证明VGG-16对于花卉图像分类识别效果好,所以本节将在VGG-16上添加注意力机制,改善花卉图像背景干扰分类识别的问题。
首先花卉图像分类识别模型基于卷积神经网络,并在该网络上添加Saumya Jetley等人提出的用于图像分类的端到端可训练注意力模块,模型结构如图所示。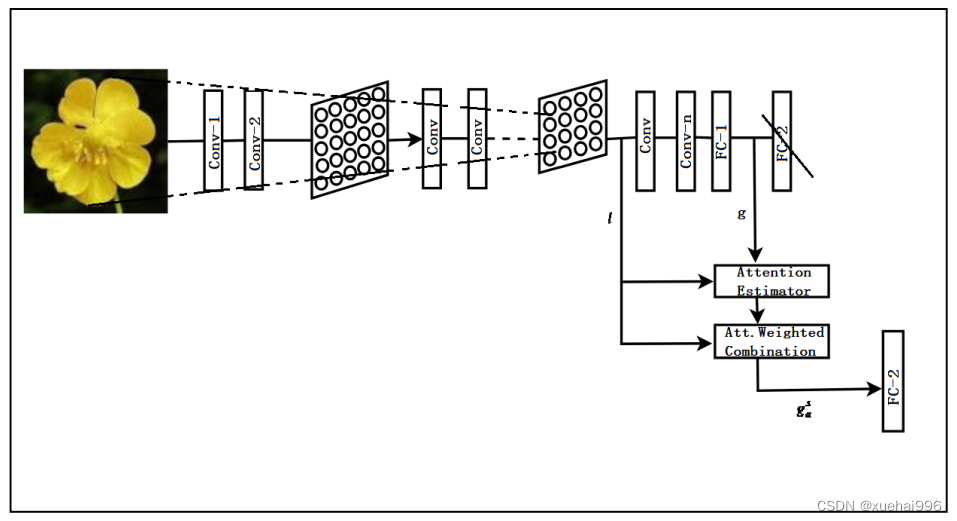
添加注意力机制的花卉图像分类识别结果
由于Oxford-17 flower花卉数据集样本不多,花卉之间的细小差异难以体现,所以选用数据集Oxford-102 flower进行注意力机制在细粒度图像分类的性能实验。实验采用pycharm平台,以Tensorflow为框架,语言为python3.7,硬件平台采用配置为至强E5八核处理器3.6GHZ和16GB内存的工作站。
基于残差网络并添加注意力机制的花卉图像分类识别具体模型结构如图所示。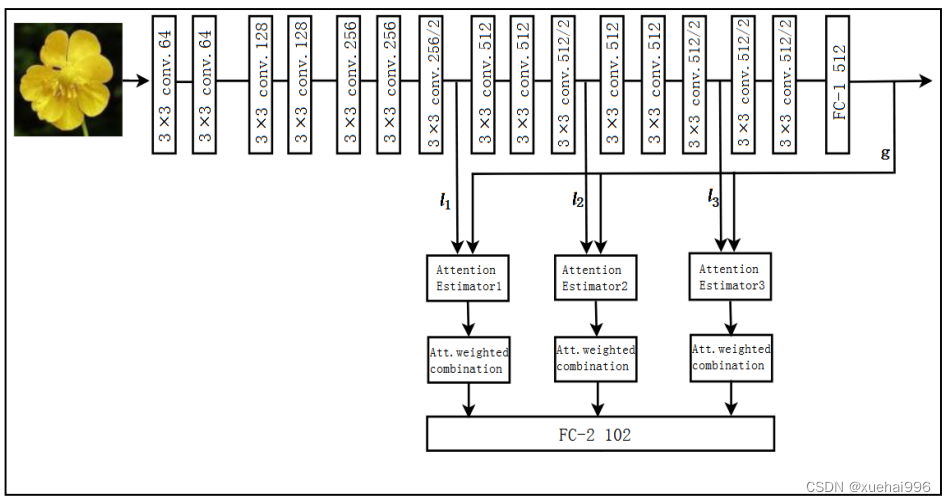
实验中,在残差网络的基础上添加注意力机制,选用调取部分中间卷积层Conv3_3、Conv4_3和Conv5_3的局部特征和全连接层FC-1的全局特征进行特征融合,构建注意力特征作为最后的分类特征,并与全连接层FC-2进行级联,实现对花卉图像的分类识别。
基于VGG-16网络并引用注意力机制得到的注意力模型效果如图所示。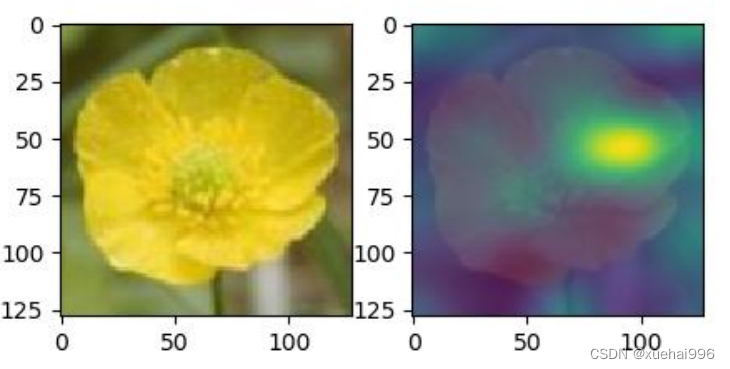
从上图中可以发现注意力机制抑制背景等无用相关信息,选择花卉作为感兴趣点,能提取更多有用的信息,有助于实现花卉的准确分类。
5.核心代码讲解
5.1 fit.py
封装为类的代码如下:
classModelTrainer:def__init__(self, model, loss_fn, optimizer, train_dl, test_dl, exp_lr_scheduler):
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
self.train_dl = train_dl
self.test_dl = test_dl
self.exp_lr_scheduler = exp_lr_scheduler
deffit(self, epoch):
correct =0
total =0
running_loss =0
self.model.train()for x, y in tqdm(self.train_dl):if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = self.model(x)
loss = self.loss_fn(y_pred, y)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct +=(y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
self.exp_lr_scheduler.step()
epoch_loss = running_loss /len(self.train_dl.dataset)
epoch_acc = correct / total
test_correct =0
test_total =0
test_running_loss =0
self.model.eval()with torch.no_grad():for x, y in tqdm(self.test_dl):if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = self.model(x)
loss = self.loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct +=(y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss /len(self.test_dl.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,'loss: ',round(epoch_loss,3),'accuracy:',round(epoch_acc,3),'test_loss: ',round(epoch_test_loss,3),'test_accuracy:',round(epoch_test_acc,3))return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
该程序文件名为fit.py,主要功能是定义了一个fit函数,用于训练模型并返回损失和准确率的变化。
fit函数的输入参数包括epoch(当前训练的轮数)、model(模型)、loss_fn(损失函数)、optim(优化器)、train_dl(训练数据集)、test_dl(测试数据集)和exp_lr_scheduler(学习率调整器)。
在fit函数中,首先初始化了一些变量,包括正确预测的数量correct、总样本数量total和累计损失running_loss。
然后,将模型设置为训练模式,通过迭代训练数据集train_dl,将输入数据x传入模型得到预测结果y_pred,计算预测结果与真实标签之间的损失loss,将优化器的梯度清零,进行反向传播和参数更新。同时,使用torch.no_grad()上下文管理器计算训练集的准确率和累计损失。
接下来,使用学习率调整器exp_lr_scheduler调整学习率,并计算训练集的平均损失epoch_loss和准确率epoch_acc。
然后,初始化测试集的正确预测数量test_correct、总样本数量test_total和累计损失test_running_loss。
将模型设置为评估模式,通过迭代测试数据集test_dl,将输入数据x传入模型得到预测结果y_pred,计算预测结果与真实标签之间的损失loss,并计算测试集的准确率和累计损失。
最后,打印出当前轮数epoch、训练集的平均损失epoch_loss和准确率epoch_acc,以及测试集的平均损失epoch_test_loss和准确率epoch_test_acc。
最后,返回训练集的平均损失、准确率和测试集的平均损失、准确率。
5.2 test.py
classNet(nn.Module):def__init__(self):super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64,64,1),
RestNetBasicBlock(64,64,1))
self.ca = ChannelAttention(64)
self.sa = SpatialAttention()
self.layer2 = nn.Sequential(RestNetDownBlock(64,128,[2,1]),
RestNetBasicBlock(128,128,1))
self.layer3 = nn.Sequential(RestNetDownBlock(128,256,[2,1]),
RestNetBasicBlock(256,256,1))
self.layer4 = nn.Sequential(RestNetDownBlock(256,512,[2,1]),
RestNetBasicBlock(512,512,1))
self.spp = SPP()
self.conv2 = nn.Conv2d(2048,512, kernel_size=1)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc = nn.Linear(512,18)defforward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.ca(out)* out
out = self.sa(out)* out
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.spp(out)
out = self.conv2(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0],-1)
out = self.fc(out)return out
classFlowerClassifier:def__init__(self, model_path):
self.model = Net()
self.model.load_state_dict(torch.load(model_path))
self.transform = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])])defclassify(self, image_path):
pil_img = Image.open(image_path)
img_tensor = self.transform(pil_img)
img_tensor_batch = torch.unsqueeze(img_tensor, dim=0)
pred = self.model(img_tensor_batch)
pred = torch.argmax(pred).detach().numpy()
classes =['夏枯草','射干','曼陀罗','桔梗','波斯婆婆纳','牛蒡','狗尾草','瞿麦','芍药','苍耳','苘麻','蒲公英','藿香','蛇莓','金银花','鸡蛋花','鸭跖草','龙葵']return classes[pred]
这个程序文件名为test.py,主要功能是使用训练好的模型对输入的图像进行分类预测。程序导入了一些必要的库,如numpy、pandas、torch等。然后定义了一些模型的组件,如ResNet的基本块、下采样块、SPP模块、通道注意力模块和空间注意力模块。接着定义了一个包含上述组件的完整的神经网络模型Net。模型的权重通过加载已保存的模型文件model.pth进行恢复。最后,程序通过读取一张图像,并将其转换为模型所需的输入格式,然后使用模型进行预测,并根据预测结果输出对应的植物名称。
5.3 train.py
classDataPreprocessor:def__init__(self, base_dir, specises):
self.base_dir = base_dir
self.specises = specises
defcreate_dataset(self):
train_dir = os.path.join(self.base_dir,'train')
test_dir = os.path.join(self.base_dir,'test')for train_or_test in['train','test']:for spec in self.specises:
os.mkdir(os.path.join(self.base_dir, train_or_test, spec))
image_dir ='data'for i, img inenumerate(os.listdir(image_dir)):for spec in self.specises:if spec in img:
s = os.path.join(image_dir, img)if(i%5==0):
d = os.path.join(self.base_dir,'test', spec, img)else:
d = os.path.join(self.base_dir,'train', spec, img)
shutil.copy(s, d)for train_or_test in['train','test']:for spec in self.specises:print(train_or_test, spec,len(os.listdir(os.path.join(self.base_dir, train_or_test, spec))))classNet(nn.Module):def__init__(self):super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = nn.Sequential(RestNetBasicBlock(64,64,1),
RestNetBasicBlock(64,64,1))
self.ca = ChannelAttention(64)
self.sa = SpatialAttention()
self.layer2 = nn.Sequential(RestNetDownBlock(64,128,[2,1]),
RestNetBasicBlock(128,128,1))
self.layer3 = nn.Sequential(RestNetDownBlock(128,256,[2,1]),
RestNetBasicBlock(256,256,1))
self.layer4 = nn.Sequential(RestNetDownBlock(256,512,[2,1]),
RestNetBasicBlock(512,512,1))
self.spp = SPP()
self.conv2 = nn.Conv2d(2048,512, kernel_size=1)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc = nn.Linear(512,18)defforward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.ca(out)* out
out = self.sa(out)* out
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.spp(out)
out = self.conv2(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0],-1)
out = self.fc(out)return out
classModelTrainer:def__init__(self, model, train_dl, test_dl, optimizer, loss_fn, exp_lr_scheduler):
self.model = model
self.train_dl = train_dl
self.test_dl = test_dl
self.optimizer = optimizer
self.loss_fn = loss_fn
self.exp_lr_scheduler = exp_lr_scheduler
deffit(self, epochs):
train_loss =[]
test_loss =[]
train_acc =[]
test_acc =[]for epoch inrange(epochs):
epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc = self.train(epoch)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(test_epoch_loss)
test_acc.append(test_epoch_acc)return train_loss, train_acc, test_loss, test_acc
deftrain(self, epoch):
self.model.train()
running_loss =0.0
running_corrects =0for inputs, labels in self.train_dl:
inputs = inputs.to(device)
labels = labels.to(device)
self.optimizer.zero_grad()
outputs = self.model(inputs)
_, preds = torch.max(outputs,1)
loss = self.loss_fn(outputs, labels)
loss.backward()
self.optimizer.step()
running_loss += loss.item()* inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss /len(self.train_dl.dataset)
epoch_acc = running_corrects.double()/len(self.train_dl.dataset)
test_epoch_loss, test_epoch_acc = self.test()print('Epoch: {} Train Loss: {:.4f} Train Acc: {:.4f} Test Loss: {:.4f} Test Acc: {:.4f}'.format(
epoch, epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc))return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc
deftest(self):
self.model.eval()
running_loss =0.0
running_corrects =0for inputs, labels in self.test_dl:
inputs = inputs.to(device)
labels = labels.to(device)with torch.no_grad():
outputs = self.model(inputs)
_, preds = torch.max(outputs,1)
loss = self.loss_fn(outputs, labels)
running_loss += loss.item()* inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
test_epoch_loss = running_loss /len(self.test_dl.dataset)
test_epoch_acc = running_corrects.double()/len(self.test_dl.dataset)return test_epoch_loss, test_epoch_acc
该程序文件名为train.py,主要功能如下:
- 导入所需的库和模块。
- 定义了一个数据增强函数augment,用于对图像进行随机水平翻转、随机裁剪、随机旋转、随机缩放、随机调整亮度和对比度等操作。
- 定义了数据集的路径和分类标签。
- 将原始数据集按照一定比例划分为训练集和测试集,并将图像按照类别保存到对应的文件夹中。
- 对数据集进行预处理,包括图像的大小调整、转换为张量、归一化等操作。
- 创建训练集和测试集的数据加载器。
- 定义了一个RestNetBasicBlock类和一个RestNetDownBlock类,用于构建ResNet的基本块。
- 定义了一个SPP类,用于构建Spatial Pyramid Pooling层。
- 定义了一个ChannelAttention类和一个SpatialAttention类,用于构建通道注意力和空间注意力机制。
- 定义了一个Net类,用于构建整个模型,包括卷积层、残差块、注意力机制、SPP层、全连接层等。
- 创建了一个Net模型的实例,并将其移动到GPU上(如果可用)。
- 定义了优化器、损失函数和学习率衰减策略。
- 进行模型的训练和测试,并记录训练和测试的损失和准确率。
- 绘制训练和测试的损失和准确率曲线。
- 保存训练好的模型。
5.4 ui.py
classRestNetBasicBlock(nn.Module):def__init__(self, in_channels, out_channels, stride):super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)defforward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)return F.relu(x + output)classRestNetDownBlock(nn.Module):def__init__(self, in_channels, out_channels, stride):super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels))defforward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)return F.relu(extra_x + out)classSPP(nn.Module):def__init__(self):super(SPP, self).__init__()
self.pool1 = nn.MaxPool2d(kernel_size=5,stride=1,padding=5//2)
self.pool2 = nn.MaxPool2d(kernel_size=7, stride=1, padding=7//2)
self.pool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13//2)defforward(self,x):
x1 = self.pool1(x)
x2 = self.pool2(x)
x3 = self.pool3(x)return torch.cat([x,x1,x2,x3],dim=1)classChannelAttention(nn.Module):def__init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes //16,1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes //16, in_planes,1, bias=False)
self.sigmoid = nn.Sigmoid()defforward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)classSpatialAttention(nn.Module):def__init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in(3,7),'kernel size must be 3 or 7'
padding =3if kernel_size ==7else1
self.conv1 = nn.Conv2d(2,1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()defforward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)return self.sigmoid(x)......
ui.py是一个使用PyQt5库创建的用户界面程序。它还导入了其他一些库,如numpy、pandas、torch等。该程序包括了一些函数和类,用于数据预处理、模型训练和图像分类等任务。其中,augment函数用于数据增强,Net类定义了一个基于ResNet的神经网络模型,det_resnet函数用于加载模型并对输入的图像进行分类。该程序还包括了一些辅助函数和全局变量。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于深度学习和改进卷积神经网络的花卉信息识别系统。它包括了四个主要的程序文件:fit.py、test.py、train.py和ui.py。
fit.py文件定义了一个fit函数,用于训练模型并返回损失和准确率的变化。它通过迭代训练数据集,进行前向传播、损失计算、反向传播和参数更新等操作,同时计算训练集的准确率和累计损失。最后,返回训练集的平均损失、准确率和测试集的平均损失、准确率。
test.py文件用于使用训练好的模型对输入的图像进行分类预测。它加载了已保存的模型文件,定义了一个包含各种组件的神经网络模型,并通过读取图像进行预测,并输出对应的植物名称。
train.py文件用于训练模型。它包括了数据预处理、模型构建、优化器、损失函数和学习率衰减策略的定义。它还定义了一些辅助函数和全局变量,用于数据集划分、数据加载、模型训练和测试等操作。
ui.py文件是一个使用PyQt5库创建的用户界面程序。它包括了一些函数和类,用于数据预处理、模型训练和图像分类等任务。它还导入了其他一些库,如numpy、pandas、torch等。
下面是每个文件的功能整理:
文件名功能fit.py定义了fit函数,用于训练模型并返回损失和准确率的变化。test.py使用训练好的模型对输入的图像进行分类预测。train.py训练模型,包括数据预处理、模型构建、优化器、损失函数和学习率衰减策略的定义。ui.py创建用户界面程序,包括数据预处理、模型训练和图像分类等任务。
7.迁移学习
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。
迁移学习(Transfer Learning)本质简单,它将为原先任务开发的模型再次应用于新任务模型开发29,迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。虽然大多数机器学习算法都是为了解决单个任务而设计的,但促进迁移学习的算法的开发是机器学习社区持续关注的话题。迁移学习就是找到旧问题与目标问题的相似性,将旧领域学习过的模型应用在新领域上。
迁移学习的必要性往往是因为以下几点因素:大数据与少标注的矛盾,虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型,人工进行数据标定又太耗时;大数据与弱计算的矛盾,普通人无法拥有庞大的数据量与计算资源。因此需要借助于模型的
迁移;即使是在同一个任务上也存在普适化模型与个性化需求的矛盾,一个模型也往往难以满足每个人的个性化需求。
迁移学习的发展历史
最早在机器学习领域引用迁移( transfer)这个词的是Lorien Pratt,他于1993年制定了基于可区分性转移(DBT)算法,1997年,机器学习杂志迁移学习发表了专题讨论,到1998年,迁移学习已经成为了比较完整的学习领域,包括多任务学习(multi-task learning),以及对其理论基础的更正式分析。
2005年,Do和 Andrew Ngl30l探讨了在文本分类中应用迁移学习的方法。2007年Mihalkova等学者开发了应用于马尔可夫逻辑网络(Markov Logic Networks)的转移学习算法[31I。同年,Niculescu-Mizil等学者[32l讨论了迁移学习在贝叶斯网络中的应用。2012年Lorien Pratt 和 Sebastian Thrun出版了相关读物,回顾了迁移学习的发展。
在深度学习中,由于神经网络的训练越来越费时,成本越来越高,同时其需要的数据集大小也不是在所有情况下都能满足,因此使用已经训练好的神经网络进行其他任务变得很有必要,迁移学习也变得越来越重要。
迁移学习的研究领域
迁移学习的分类可以按照四个准则进行:按目标域标签分、按学习方法分、按特征分、按形式分。
按目标域标签分,这种分类方式最为直观。类比机器学习,按照目标领域有无标签,迁移学习可以分为以下三个大类:监督迁移学习、半监督迁移学习和无监督迁移学习[831]。显然,少标签或无标签的问题(半监督和无监督迁移学习),是研究的热点和难点。
按学习方法分,按学习方法的分类形式,分为以下四大类:基于样本进行迁移、基于特征进行迁移、基于模型进行迁移和基于关系进行迁移。基于样本的迁移,它权重重用迁移源域和目标域的样本。基于特征的迁移,将进一步转换特征。基于模型的迁移是为了建立参数共享的模型,适用于CNN网络。基于关系的迁移,使用较少,适用于关系类比迁移。
按特征分,如果特征相同,即为同构迁移学习,反之,如果特征不完全相同,那么就是异构迁移学习。
按形式分,迁移学习有两种形式:离线和在线。目前,大部分的迁移学习方法都倾向于离线形式,因为它只需迁移一次。但是这种方式下,算法无法对新加入的数据一次性进行处理和学习,随之模型也无法及时更新。相对的在线方式,它一边加入数据,一边进行及时更新,效率极低。
迁移学习的应用
迁移学习是机器学习领域的一个重要分支,其应用领域非常广泛,只要满足迁移学习问题情景的应用,就都能使用迁移学习的方式,像计算机视觉、文本分类、行为识别、医疗健康等[35]。
(1)计算机视觉
在计算机视觉中,迁移学习的应用场景较多,比如图片的分类和哈希等。现实情况下,照片拍摄没有具体的标准衡量,拍摄角度和光照等因素常常引起同一类图片的很大差异,甚至会改变物体特征分布。因此,在计算机视觉中,常常需要利用迁移学习的方式的同时还需构建跨领域的鲁棒分类器,这对于视觉分析是非常重要的。
(2)文本分类
由于在文本分类中,文本数据掺杂着情感等各种角度,而且各种领域的文本分类标准也不一样,从而给文本分类带来了很大的难度。比如当进行文本分类时,在图书评论训练的分类器,不能直接拿来用于音频文本分类。面对这种难点,需要用到迁移学习知识。
(3)时间序列
时间序列数据常常被称为行为数据,常常用来进行行为识别(Activity Recognition)任务。而行为识别的数据来源主要是用户身体上携带的传感器,通过传感器得到的一些列数据,比如血压、温度等来进行行为识别。但是随着环境、位置和设备的不同,这些都可能改变时间序列数据的分布,进而影响行为识别的正常分析。为了解决这些问题的干扰,通常也需要进行迁移学习。
(4)医疗健康
虽然医疗健康领域越来越重要,但是还存在研究的难点,即无法获取足够有效的医疗数据。此时,将迁移学习运用到医疗健康领域中可以解决这一难题。比如最近,相关医疗杂志报道了张康教授团队的重磅研究成果:基于深度学习技术的眼病和肺炎的AI诊断系统,它运用了迁移学习的方式,其准确性很高[35]。显然,在医疗健康领域,迁移学习可以有效帮助解决医疗数据获取的问题。
卷积神经网络中的迁移学习
当我们训练一个新任务时,由于考虑到训练时间的限制和训练样本不允许占太多储存空间,一般不会重新开始进行训练。因此我们的迁移学习通常处于以下两种情况:
1:把预训练的CNN模型当作特征提取器:
将某个CNN模型经ImageNet数据库预训练后得到任务新模型,由于新模型适应的是新任务,其最后一层全连接层特征输出常常要去掉(因为最后一层的输出是1000个类别的概率,不适用需要解决的问题),然后将剩下的全部网络结构作为一个特征提取器[3],只需最后连接一个分类器就可以完成新任务。
2:微调网络( finetune model )
经ImageNet数据库预训练后得到的新模型一般不会直接用作分类器,还需让新模型去适应训练数据,提高它的新任务分类性能,因此还需要在网络训练过程中不断更新权重。若本身任务的数据库较小,为了防止过拟合,需要对网络的前几层固定参数(不更新权重),而只更新网络结构的后面几层[8]。这是因为网络的前几层得到的局部特征比较基础浅显,改变不大。但是网络层数越靠后,提取的特征越全面,就越接近于最后的分类特征,在分类的过程中,哪怕忽略细微特征,都能改变整个图像分类的结果。因此微调网络是迁移学习非常重要的步骤。
8.注意力机制
在日常生活中,我们通过视觉、听觉、触觉等方式收到很多感官输入。但是我们的大脑可以有序攻击这些外部信息时还坚持工作,是因为人类大脑可以有意或无意地从大量输入信息中选择小部分的有用信息专注处理,而忽略其他信息,这种能力称为注意力。注意力可以反应在外部的刺激(听觉、视觉、味觉等)或内部意识(思考、回忆等)上。人类视觉机制对图像进行全局扫描,得到需要关注的重点区域,并对这一区域投入较多视觉资源,来获取细节信息,抑制无用信息[3]。伴随着人类长期进化,视觉注意力进一步形成和完善,它可促进人类脑部的思考发育。
注意力机制的发展
注意力机制的诞生,最开始是应用于机器翻译中,帮助记住文章中较长的源句。它建立了一个上下文向量与整个源句之间的快捷方式,而不只是通过编码器最后一步的隐层状态来生成上下文向量。有了注意力机制,源序列和目标序列的依赖关系再也不需要二者之间的相对距离了!有了机器翻译领域上巨大的进展,注意力机制在包括计算机视觉在内的其它领域也都随之有了广泛的应用,研究者们也相继探索出各种不同的注意力机制模型以适用于不同的应用场合。
随着注意力机制的不断成熟,专家们将其应用于图像处理方面也越来越熟练。2007年,李毅泉阐述并对注意力模型等相关理论知识进行研究,提出基于注意力的显著区域提取技术[40);2011年,马秀丽提出基于数字图像处理的水果表面品质检测方法,对于水果表面缺陷采用注意力选择的方法,更接近人对水果表面缺陷的判定;2013年,张建兴提出了一种新的基于注意力的目标识别算法,并将该算法运用到移动机器人研究平台,满足移动机器人在未知环境中实时避障的要求;凭借着与人脑注意力机制的高度模仿,注意力机制将越来越多的应用于科技发展当中。
基于注意力机制的图像处理
近年来,注意力模型不断发展,已在目标识别、图像描述生成、图像质量评估等领域被广泛使用。对于图像分类任务来说,特征提取是最重要的,但是特征提取涉及到很多信息的处理问题。由于海量的信息难以进行及时处理,有时还会面临信息处理的不完全性和错误性,这都会导致提取的特征不能满足图像的正确分类,所以面对这种难题,可以在模型中添加注意力机制进行网络学习,相当于给图像处理任务过程中的特征提取设置一个准确方向,避免其他无关或无用的信息对整个分类任务的干扰。
注意力机制常与图像处理进行结合,解决背景干扰问题。如图2-5所示的注意力机制原理图,只要输入图像,就可以该图像得出与每个物体类别的相似概率值。
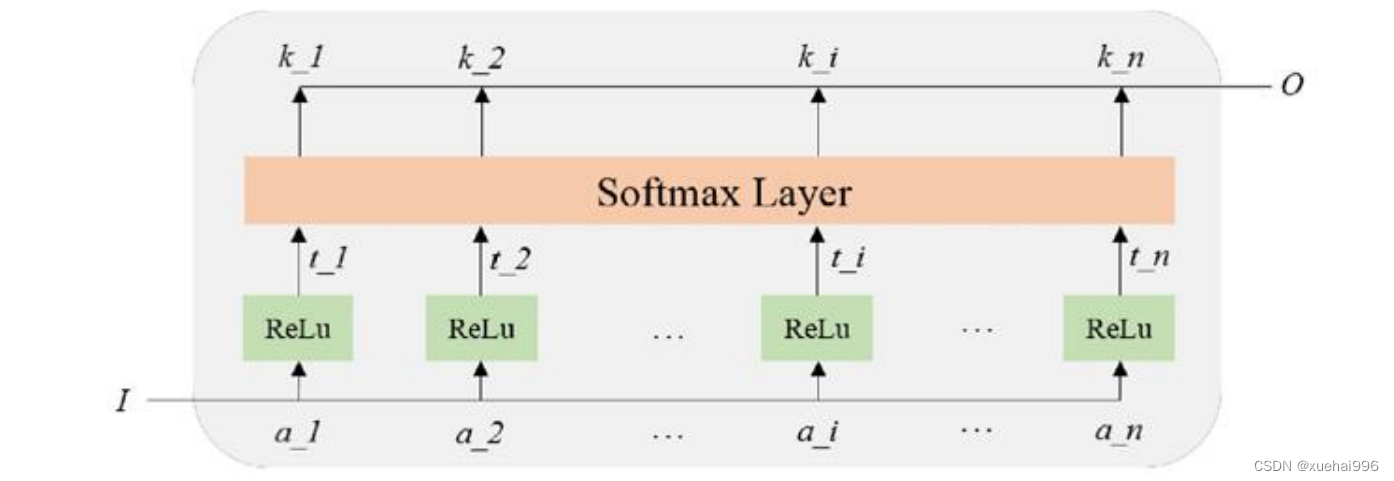
上图中,先输入图像I,其中,a_1,a_2,""a_i,a_n是对整个系统图像中的n个区域的具体描述;接着经过Relu函数激活计算t_1,t_2,…,t_i,t_n,然后Softmax层计算变量关联度,最后相似概率输出。输出0是注意力模型的返回值,返回参数的权重值,这里的权重由每一个a_i相对于输入I的相关性决定,权重进行算术平均后可以得到这张图像与每个物体类别的相关概率值,这对后续图像分类有很大帮助,可以避免背景带来的干扰性。
通道注意力模块
通道注意力是关注哪个通道上的特征是有意义的,输入feature map是H x W x C,先分别进行一个全局平均池化和全局最大池化得到两个1 x 1 x C的feature map , 然后将这两个feature map分别送入两层的全连接神经网络,对于这两个feature map,这个两层的全连接神经网络是共享参数的,然后,再将得到的两个feature map相加,然后再通过Sigmoid函数得到0~1之间的权重系数,然后权重系数再与输入feature map相乘,得到最终输出feature map。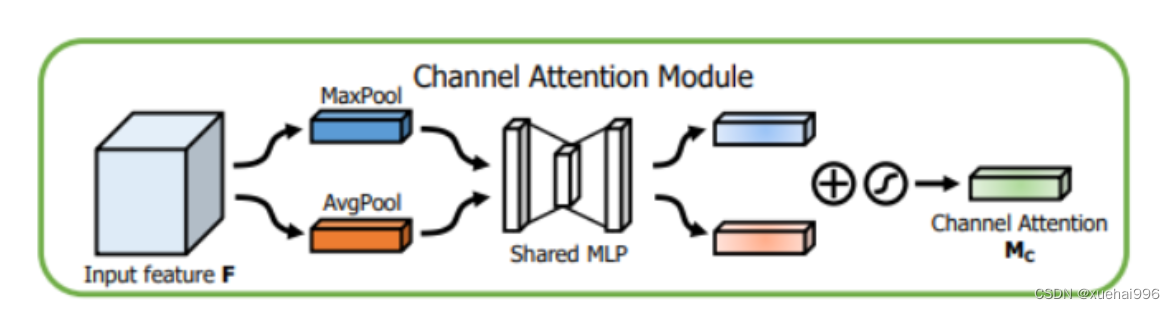
空间注意力模块
输入feature map为 H x W x C,分别进行一个通道维度的最大池化和平均池化得到两个H x W x 1的feature map,然后将这两个feature map在通道维度拼接起来,现在feature map H x W x 2,然后再经过一个卷积层,降为1个通道,卷积核采用7x7,同时保持H W 不变,输出feature map为H x W x 1,然后再通过Sigmoid函数生成空间权重系数,然后再与输入feature map相乘得到最终feature map。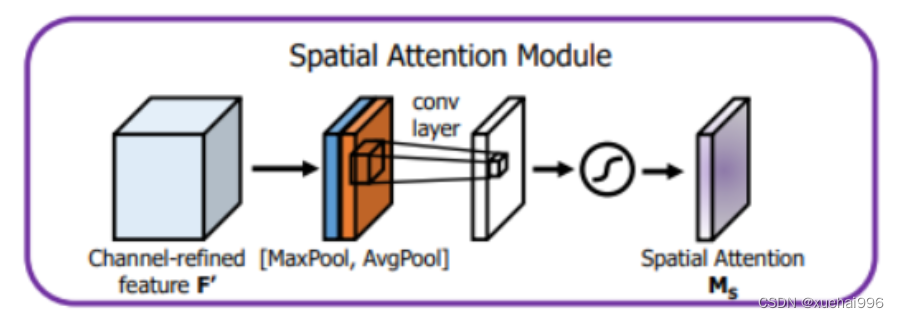
两种注意力机制代码实现
classchannelAttention(nn.Module):def__init__(self , in_planes , ration =16):super(channelAttention, self).__init__()'''
AdaptiveAvgPool2d():自适应平均池化
不需要自己设置kernelsize stride等
只需给出输出尺寸即可
'''
self.avg_pool = nn.AdaptiveAvgPool2d(1)# 通道数不变,H*W变为1*1
self.max_pool = nn.AdaptiveMaxPool2d(1)#
self.fc1 = nn.Conv2d(in_planes , in_planes //16,1, bias =False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes//16, in_planes ,1, bias =False)
self.sigmoid = nn.Sigmoid()defforward(self , x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))#print(avg_out.shape)#两层神经网络共享
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))print(avg_out.shape)print(max_out.shape)
out = avg_out + max_out
print(out.shape)return self.sigmoid(out)''''
空间注意力模块
先分别进行一个通道维度的最大池化和平均池化得到两个H x W x 1,
然后两个描述拼接在一起,然后经过一个7*7的卷积层,激活函数为sigmoid,得到权重Ms
'''classspatialAttention(nn.Module):def__init__(self , kernel_size =7):super(spatialAttention, self).__init__()assert kernel_size in(3,7)," kernel size must be 3 or 7"
padding =3if kernel_size ==7else1# avg 和 max 两个描述,叠加 共两个通道。
self.conv1 = nn.Conv2d(2,1, kernel_size , padding = padding , bias =False)#保持卷积前后H、W不变
self.sigmoid = nn.Sigmoid()defforward(self , x):# egg:input: 1 , 3 * 2 * 2 avg_out :
avg_out = torch.mean(x , dim =1, keepdim =True)#通道维度的平均池化# 注意 torch.max(x ,dim = 1) 返回最大值和所在索引,是两个值 keepdim = True 保持维度不变(求max的这个维度变为1),不然这个维度没有了
max_out ,_ = torch.max(x , dim =1,keepdim=True)#通道维度的最大池化print(avg_out.shape)print(max_out.shape)
x = torch.cat([avg_out , max_out], dim =1)print(x.shape)
x = self.conv1(x)return self.sigmoid(x)
9.数据集和预处理
Oxford-17 flower 花卉数据集
公开数据集Oxford-17 flower花卉数据集包含了17类花卉,每种花卉图像有80张,共计1360张图像,如图2-6所示。这些图像的拍摄视角、尺寸、形态各有差异。
数据预处理
采用经典花卉数据集:Oxford-17 flower,这两个数据集的花卉图片大小不一,形状各异,对花卉种类涵盖较全。为避免图像通过卷积神经网络所产生的维度不一致,需要规范图像输入时大小相同,所以实验采用保持纵横比的图像归一化方法,因而特征能够输入到Softmax层,进行花卉图像分类识别。设定输入图像大小为100 x 100,目标图像纵横比为1。如果存在输入图像纵横比不同于目标纵横比的图像的现象,会出现如图所示的归一化效果,即图像归一化后产生了4幅图像。这种方法一定程度上增加了花卉图像的数量,而且还避免了图像畸形等问题,为后续的图像分类识别奠定了坚实的基础。

经过图像大小归一化后,为了解决图像数据集分布不均衡等问题,采取随机翻转图像以及随机调整色调、饱和度、亮度等操作扩充样本小的类别。这既扩充了数据集,同时又增加网络模型的鲁棒性。
由于两花卉数据集数据量较大,且经过数据集扩充后的数据量加大,所以将两个花卉数据集的数据格式转换为TFRecod格式,可减小内存利用。
模型训练
事实上,初建立卷积神经网络模型时,参数的设置并不是凭空创造,是根据以往的经验进行设置。往往这些参数对于不同的识别任务来说并不都是最优的,从而网络输出的结果与期望值相差很大。这就需要用到反向传播的方法,它先求解正向输出值与实际值的差值,将其作为参数反向输入传播,并利用梯度下降进行权值更新调整[41。实验中对于卷积神经网络模型的训练,采用Softmax损失函数和小批量梯度下降算法。
10.训练结果与分析
注意力机制对于花卉图像分类识别实验来说相当于是显著性区域检测,检测出花卉图像的显著性区域,再进行显著性区域增强,非显著性区域抑制,从而去除掉无用的背景的干扰,但其实对于注意力机制的添加和效果还存在一些问题,为验证如何添加注意力机制对花卉图像分类识别起到更好的效果和注意力机制的添加对花卉图像分类识别准确率的影响力,现分别进行对比实验。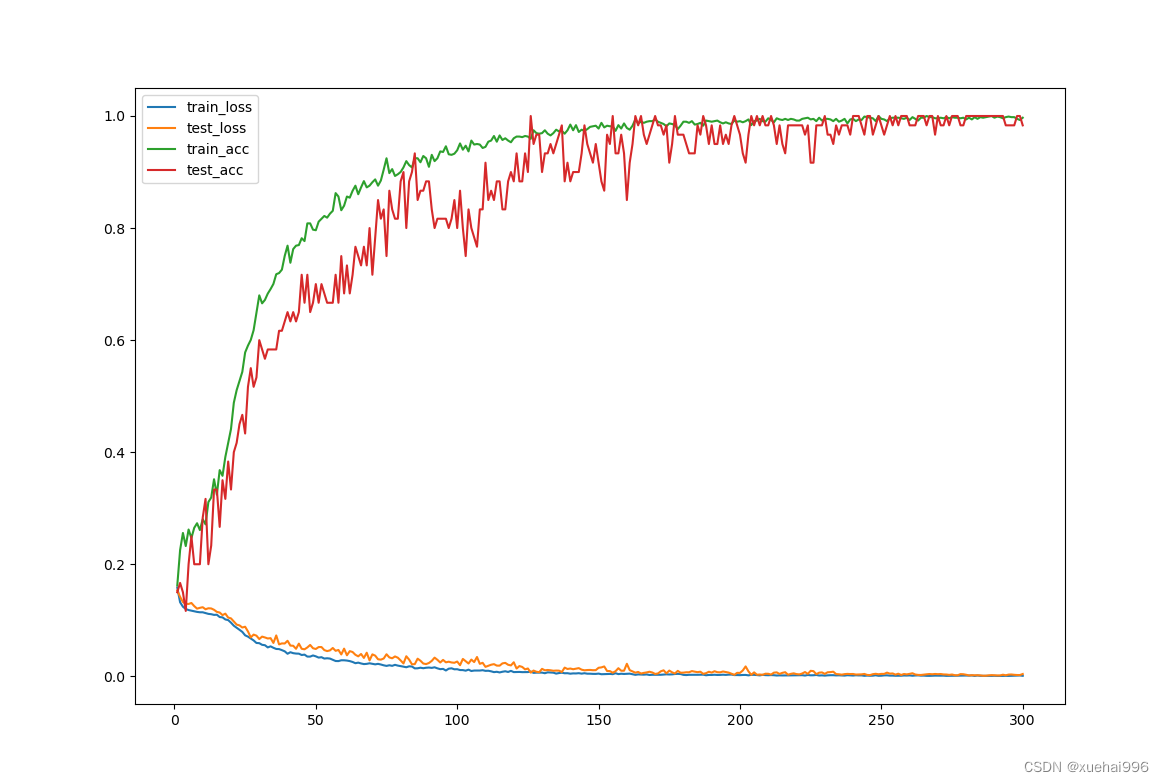
中间卷积层的局部特征的选取
由于注意力机制的形式不同,对于不同的模型也有不同的添加方式,从而对整个图像分类实验效果也存在着较大差异。由于本文采用的是Saumya Jetley等人提出的一种端到端可训练注意力模型,存在争议比较大的是中间卷积层局部特征的选取,一种是经过卷积层还未经过经过池化层的局部特征,另一种是已经经过池化层的局部特征。现针对花卉图像分类识别实验,分别对于两种中间卷积层的局部特征的选取方式进行对比实验,比较出适合并且有效的中间卷积层局部特征的选择方式。
(1)中间卷积层局部特征选取在池化层之前
置于连续的卷积层中间的池化层,常被用于压缩数据和参数的量,降低过拟合风险。局部特征选取在池化层之前,选取的数据还未经过进一步压缩,参数量比较多,此时将局部特征和全局特征进行融合,构建注意力特征,进行对花卉图像分类识别实验。实验基于Oxford-102 flower花卉数据集,当学习率为0.001时,其花卉图像分类识别准确率为82.80%。具体的花卉图像分类识别准确率变化曲线图如图所示。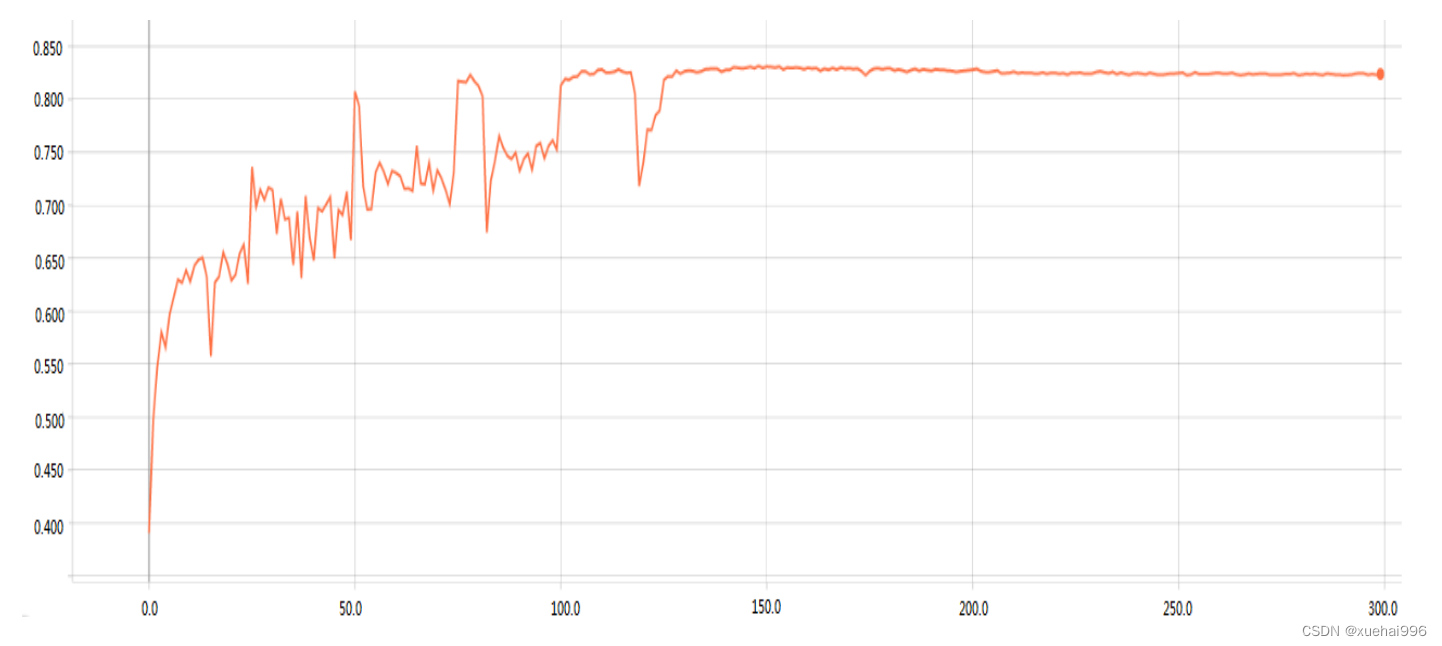
(2)中间卷积层局部特征选取在池化层之后
选取池化层之后的局部特征和全局特征进行融合,此时局部特征数据已经过压缩,参数量较前者少一点,计算量也稍微简单一点,此时将局部特征和全局特征进行融合,构建注意力特征,进行对花卉图像分类识别实验。实验同样基于Oxford-102 flower花卉数据集,当学习率为0.001时,其花卉图像分类识别准确率为83.25%。具体的花卉图像分类识别准确率变化曲线图如图所示。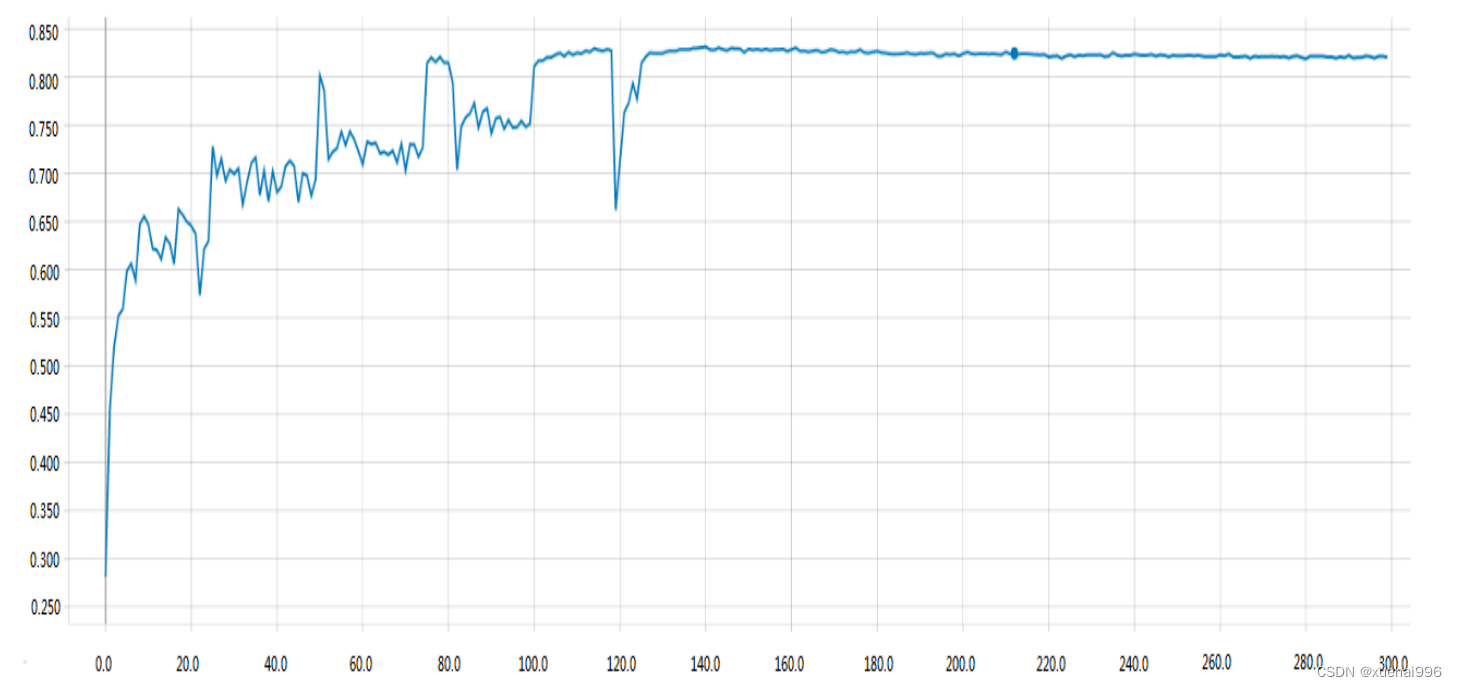
两种选取中间卷积层局部特征的方式对于花卉图像分类识别产生了不同的结果,两者相比来说,注意力机制添加在池化层之后,即中间卷积层选取在池化层之后产生的花卉图像分类识别率比较高,可见池化层的数据压缩但是数据不变性的优点。最终的选取方式为注意力机制添加在池化层之后。
11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于深度学习和改进卷积神经网络的花卉信息识别系统》
版权归原作者 群马视觉 所有, 如有侵权,请联系我们删除。