
一、硬件资源
在本地运行大模型,需要先保证自己有足够的资源。大模型一般运行在GPU上,这里以GLM-4-9B和Qwen2-7B为例来说明其硬件要求情况。
1.1 GLM-4硬件要求
进入GLM-4的github仓库中Basic Demo,可以看到硬件的要求。
最低硬件要求
如果您希望运行官方提供的最基础代码 (transformers 后端) 您需要:
- Python >= 3.10
- 内存不少于 32 GB
如果您希望运行官方提供的本文件夹的所有代码,您还需要:
- Linux 操作系统 (Debian 系列最佳)
- 大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持
BF16推理的 GPU 设备。(FP16精度无法训练,推理有小概率出现问题)
1.2 Qwen2硬件要求
进入qwen-2-7B,可以看到硬件的要求。
- NVIDIA A100 80GB
- CUDA 11.8
- Pytorch 2.1.2+cu118
- Flash Attention 2.3.3
- Transformers 4.38.2
- AutoGPTQ 0.7.1
- AutoAWQ 0.2.4
1.3 实测配置
官方的测试硬件太高大上,我实际测试时的环境信息:
- OS: Ubuntu 22.04
- Memory:30G
- CUDA Version: 12.1
- GPU:NVIDIA A10 24GB*1
- Python: 3.12.3
- Pytorch:2.3.0
二、运行环境
建议一个独立的项目创建独立的环境。这里从0开始进行环境安装,包含以下几个步骤:
- python环境安装,参考Anaconda环境安装。
- 大模型源码中会提供requirements.txt,包含了运行大模型需要的依赖包,但是pytorch一般会自动安装cpu版本,所以建议手动安装pytorch安装,参考pytorch官网。如果不需要使用vllm部署,那么安装pytorc2.1版本的就好,如果需要使用vllm,则推荐requirements.txt规定的版本。这里我在后面要使用vllm,所以直接使用requirements.txt规定的版本。
二、大模型下载
目前开源大模型,一般会提供源码和权重,所以要使用,需要分别下载。
- 在github中,找到开源模型仓库,git clone下来。我常用的两个模型仓库: 1. 智谱清言 1. 找到对应的大模型仓库,点击code,复制链接
2. 进入想要保存文件的目录,git clone https://github.com/THUDM/GLM-4.git2. 阿里千问 1. 找到对应的大模型仓库,点击code,复制链接
2. 进入想要保存文件的目录,git clone [https://github.com/QwenLM/Qwen2.git](https://github.com/QwenLM/Qwen2.git)
- 模型权重下载,常用的是huggingface和魔搭社区,国内建议用魔搭社区速度很快。 1. huggingface 1. huggingface官网,或者huggingface镜像进入后,输入对应的模型名,点击Use this model,点击transformers.

2. copy相关代码,如果没有缓存,会自动进行下载。

3. 但是由于网络原因,上一步可能下载较慢。那么可以采用另一种方法,点击Files and versions,然后一个点击模型文件里面的下载按钮。
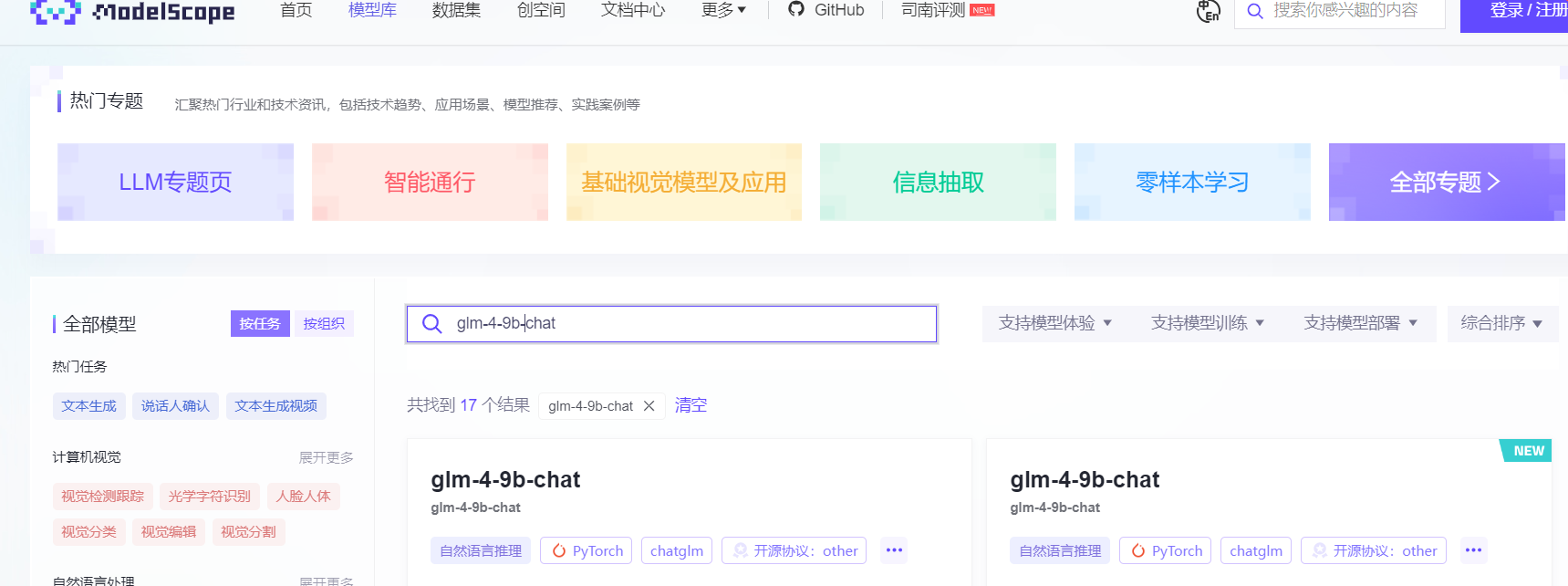
- 魔搭社区 1. 进入魔搭社区官网,点击模型库,然后输入想要现在的模型。
2. 点击模型文件,在右边会出现下载模型,点击它即可。
此时,先安装modelscope库:pip install modelscope,然后再在复制代码进行下载。可以增加一个cache_dir,用来设置下载地址。
#模型下载from modelscope import snapshot_download
model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat')# 设置模型保存目录# model_dir = snapshot_download('ZhipuAI/glm-4-9b-chat',cache_dir='./')
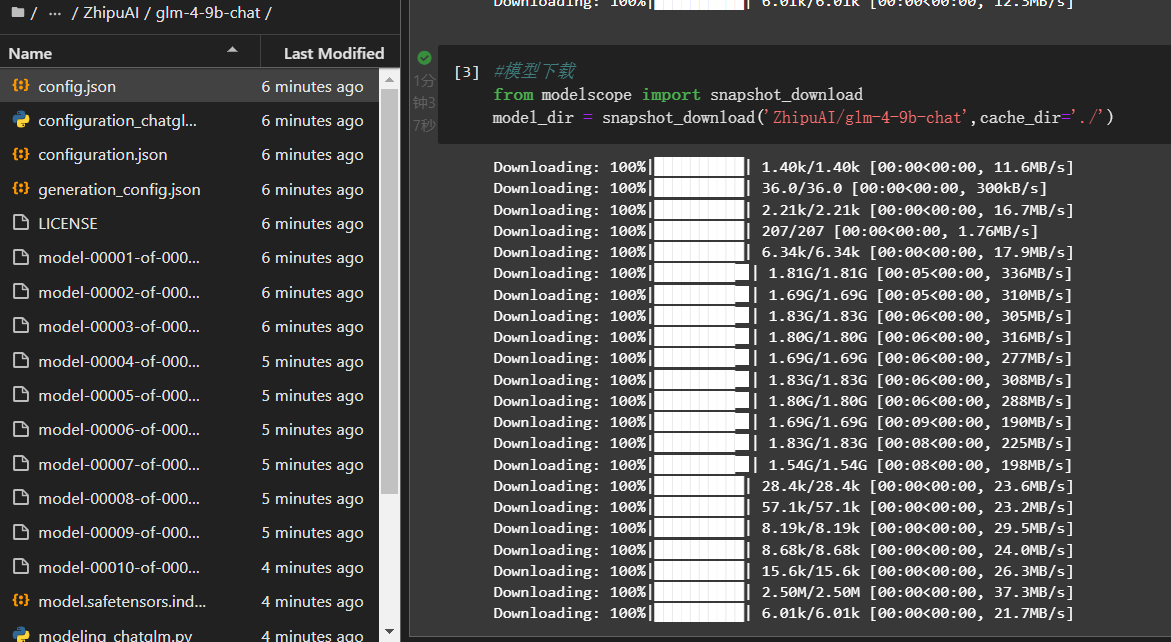
模型下载速度还是很快的。
三、glm-4-9b-chat部署
本地部署大模型,常用的方式有:
- 利用HuggingFace的transformers部署
- 利用vllm部署
- 利用ollama部署
3.1 transformers直接部署
Hugging Face是一家成立于2016年的人工智能公司,专注于开源模型库的研发。 该公司不仅提供了一个平台,让用户可以找到用于各种任务(如文本、图像、音频、视频处理)的预训练模型和数据集,还提供了相关的类库和工具,以简化AI项目的研发流程。Hugging Face通过其Transformers库和Hugging Face社区,为开发者提供了从模型训练到部署的全流程支持。这些工具包括模型版本控制、数据集共享、模型微调等,使得用户可以轻松地学习和应用最新的AI技术,同时与他人进行协作,共同推动人工智能的发展。
3.1.1 依赖包安装
依赖包安装:
- 进入源码GLM4的basic_demo中,将requirements.txt的torch和torchvision去掉
- 安装依赖包:pip install -r requirements.txt
3.1.2 部署模型自带demo
3.1.2.1 直接使用transformers库
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device ="cuda"# 将THUDM/glm-4-9b-chat修改为本地权重实际路径,我这里是'/mnt/workspace/models/ZhipuAI/glm-4-9b-chat'# model和tokenizer都要改
tokenizer = AutoTokenizer.from_pretrained('/mnt/workspace/models/ZhipuAI/glm-4-9b-chat', trust_remote_code=True)
query ="你好"
inputs = tokenizer.apply_chat_template([{"role":"user","content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained('/mnt/workspace/models/ZhipuAI/glm-4-9b-chat',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).to(device).eval()#do_sample:根据预测的概率分布随机选择下一个token,而不是简单地选择概率最高的token。这有助于增加生成文本的多样性和创造性。#top_k :当do_sample为True时,top_k参数变得重要。它指定了在采样过程中考虑的预测概率最高的token的数量#max_length:这个参数控制着生成文本的总长度,包括输入文本的长度,生成的文本达到这个长度,生成过程就会停止。
gen_kwargs ={"max_length":2500,"do_sample":True,"top_k":1}with torch.no_grad():
outputs = model.generate(**inputs,**gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]print(tokenizer.decode(outputs[0], skip_special_tokens=True))

可以看到模型加载了10个分片文件,是模型的权重,然后对我们提出的问题,模型给出了对应的答案。
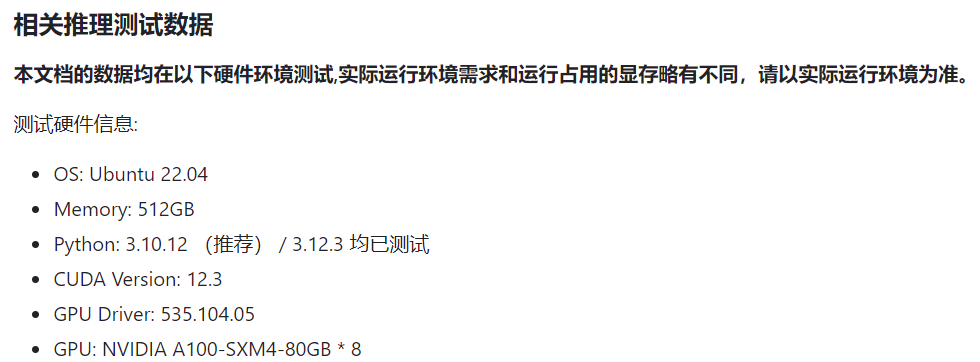
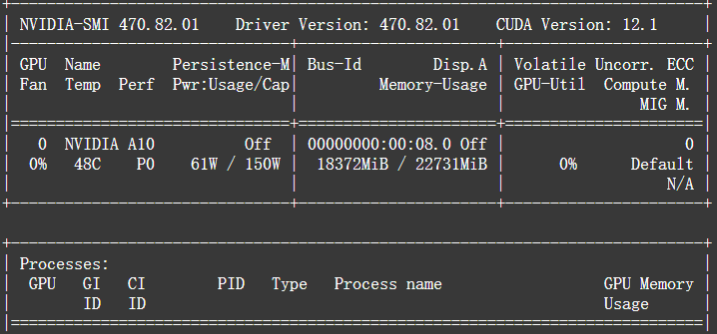
模型占用的显存如下图,数据类型bf16的情况下,用了18G,基本和官方要求给出的一致。
import torch
from transformers import AutoModelForCausalLM,AutoTokenizer
device ="cuda"
model_path ='/mnt/workspace/models/ZhipuAI/glm-4-9b-chat'
query ="请介绍下自己"
messages=[{'role':'user','content':query}]# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map='auto').eval()# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path,trust_remote_code=True)defchat(model,tokenizer,messages):
text = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer([text],return_tensors='pt').to(device)#do_sample:根据预测的概率分布随机选择下一个token,而不是简单地选择概率最高的token。这有助于增加生成文本的多样性和创造性。#top_k :当do_sample为True时,top_k参数变得重要。它指定了在采样过程中考虑的预测概率最高的token的数量#max_length:这个参数控制着生成文本的总长度,包括输入文本的长度,生成的文本达到这个长度,生成过程就会停止。
gen_kwargs ={"max_length":2500,"do_sample":True,"top_k":1}
outputs = model.generate(**model_inputs,**gen_kwargs)# outputs会包含输入的内容,需要去除
outputs = tokenizer.batch_decode(outputs[:,model_inputs['input_ids'].shape[1]:],
skip_special_tokens=True)[0]return outputs
print(chat(model,tokenizer,messages))

3.1.2.2 利用glm-4自带的命令行demo
在glm-4源码的basic_demo目录下,有多个简单的的demo。其中,trans_cli_demo.py是大模型在命令行的简单使用,使用方式如下:
- 进入到basic_demo目录:cd basic_demo
- 修改路径:trans_cli_demo.py中MODEL_PATH路径为权重文件的实际存储路径
- 运行程序:python trans_cli_demo.py

此时出现了如上图所示的界面,在YOU后面输入内容,Enter之后,会得到模型的回复,如下图所示。

3.1.2.3利用glm-4自带的网页demo
在glm-4源码的basic_demo目录下,有多个简单的的demo。其中,trans_web_demo.py是大模型网页端的简单使用,使用方式如下:
- 进入到basic_demo目录:cd basic_demo
- 修改路径:trans_web_demo.py中MODEL_PATH路径为权重文件的实际存储路径
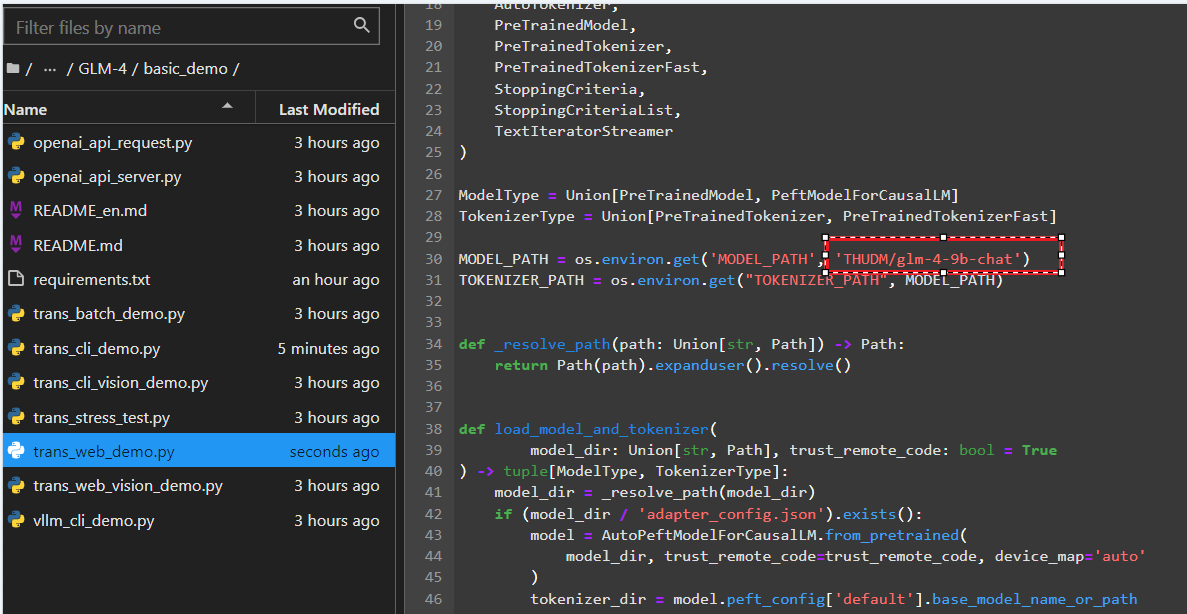
- 运行程序:python trans_web_demo.py

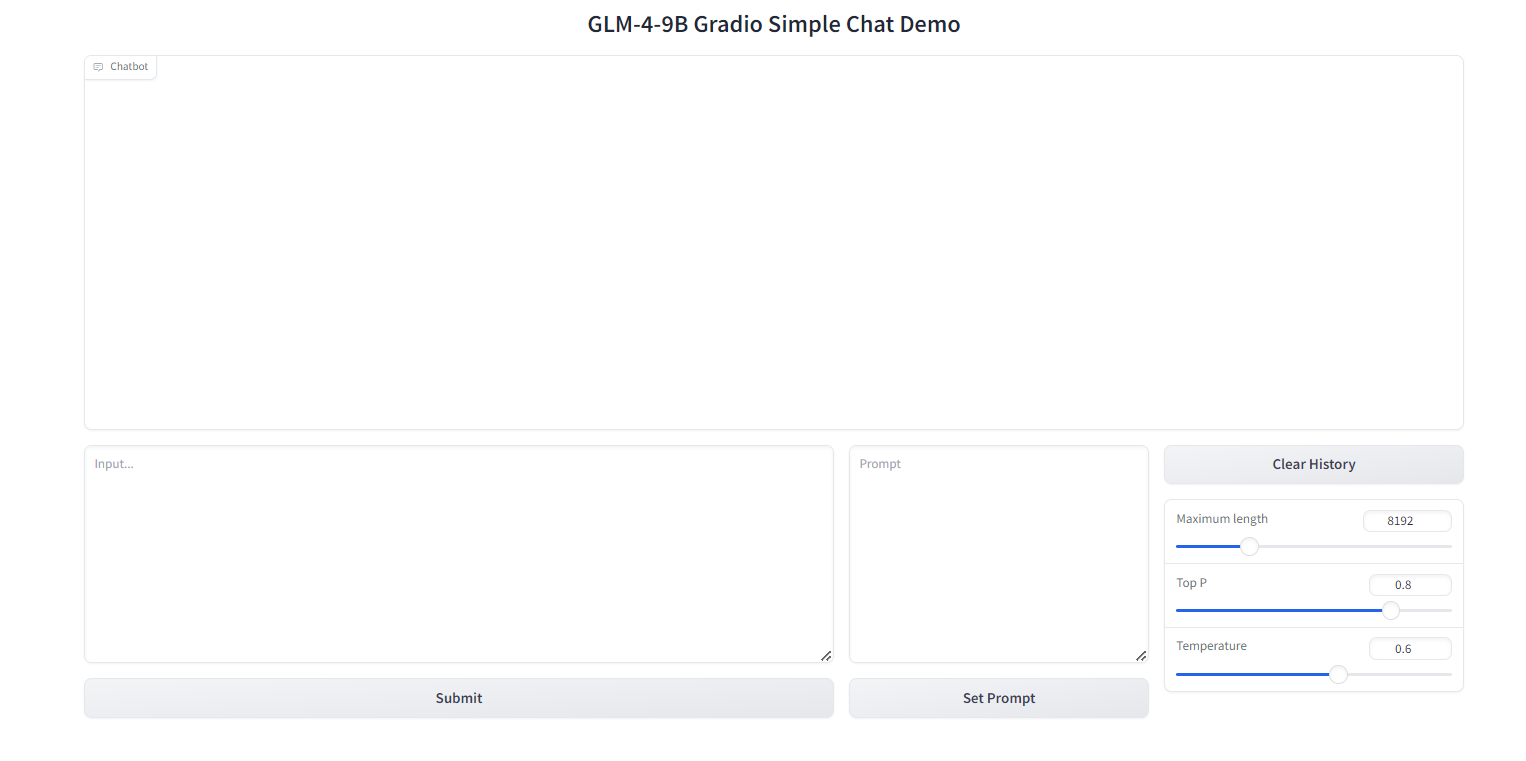
此时出现了如上图所示的界面,点击或复制那个url,就会进入网页端的聊天页面,如下图所示。
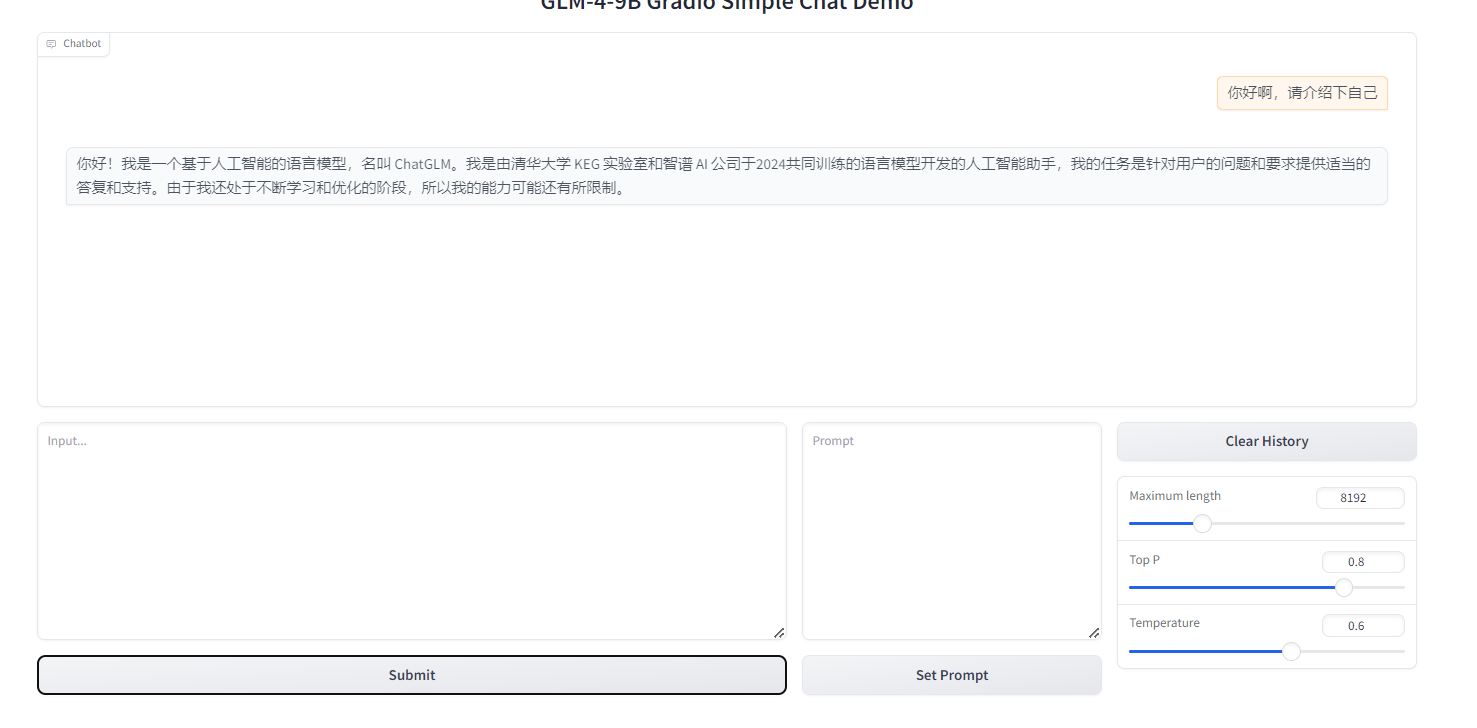
在input中输入聊天内容,可以得到如下的回复。
3.1.2.4 利用glm-4自带的openai风格调用demo
在glm-4源码的basic_demo目录下,有多个简单的的demo。其中,openai_api_server.py是glm-4大模型在关于openai风格调用的简单使用,使用方式如下:
- 进入到basic_demo目录:cd basic_demo
- 修改路径:openai_api_server.py中MODEL_PATH路径为权重文件的实际存储路径
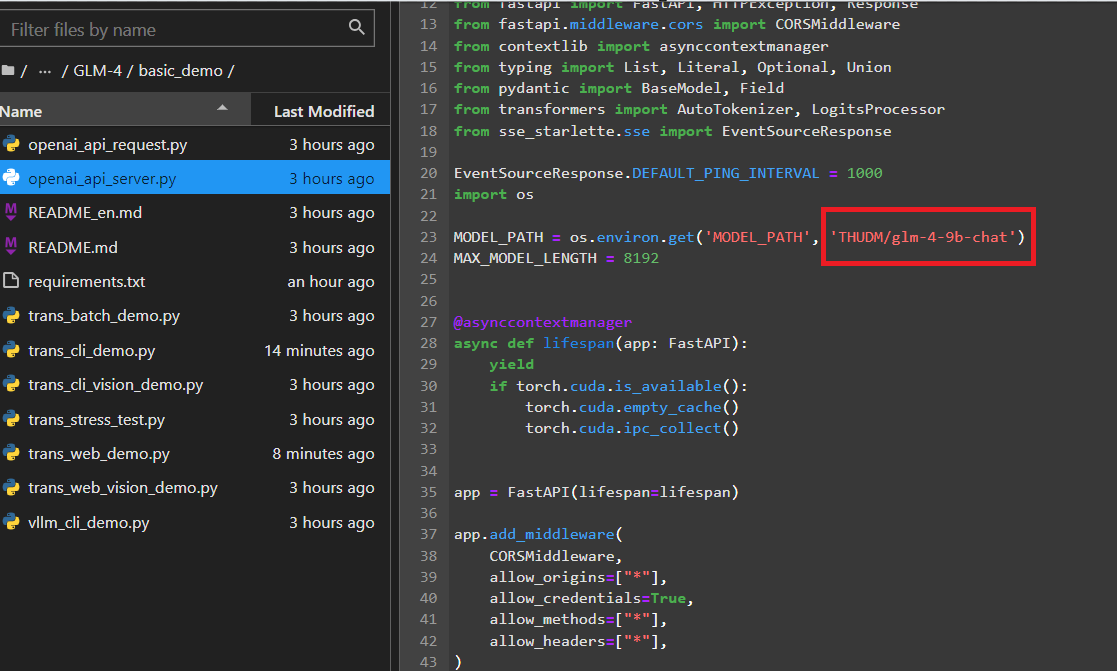
- 运行程序:python openai_api_server.py

会出现如上图所示信息,在openai包中,将base_url和api_key替换掉就可以以openai的api风格调用glm大模型了。
from openai import OpenAI
base_url ="http://127.0.0.1:8000/v1/"
api_key='None'
client = OpenAI(base_url=base_url,api_key=api_key)
messages=[{'role':'user','content':'请介绍下自己'}]
response = client.chat.completions.create(
model='glm-4',
messages=messages
)print(response.choices[0].message.content)

3.2 利用vllm部署
vLLM框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性:
- 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。
- 高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。
- 易用性:vLLM 与 HuggingFace 模型无缝集成,支持多种流行的大型语言模型,简化了模型部署和推理的过程。兼容 OpenAI 的 API 服务器。
- 分布式推理:框架支持在多 GPU 环境中进行分布式推理,通过模型并行策略和高效的数据通信,提升了处理大型模型的能力。
- 开源:vLLM 是开源的,拥有活跃的社区支持,便于开发者贡献和改进,共同推动技术发展。
github地址:https://github.com/vllm-project/vllm
官方文档:https://docs.vllm.ai/en/latest/getting_started/quickstart.html
3.2.1 使用vllm类调用模型
3.2.1.1vllm官方例子改写
改写vllm官方的小例子https://docs.vllm.ai/en/latest/getting_started/examples/offline_inference.html
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)#max_tokens生成的最大长度不超过多少tokens
sampling_params = SamplingParams(temperature=0.95, max_tokens=512)
outputs = llm.generate(prompts=prompt, sampling_params=sampling_params)for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

可以看到,虽然能够生成答案,但是生成的答案不太符合对话,更像是续写。所以接下来改用github上glm-4官方给出的例子。
3.2.1.2 GLM-4官方例子
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt =[{"role":"user","content":"请介绍下自己"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)#generation_config.json中的eos_token_id
stop_token_ids =[151329,151336,151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=512, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)print(outputs[0].outputs[0].text)

可以看出,官方的例子符合人类对话习惯,不再是补齐。
3.2.1.3 GLM-4官方例子扩充-批量处理
每个message都组合成message={‘role’:‘user’,‘conent’,prompt}的格式,然后messages将多个message组合起来。
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
messages=[]for prom in prompt:
message ={'role':'user','content':prom}
messages.append(message)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151329,151336,151338]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)

这种方法只会生成最后一个问题的答案。不可取。
prompt合在一起,输入到messages,即messages=[{‘role’:‘user’,‘conent’,prompt}]的格式
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
messages ={'role':'user','content':prompt}
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151329,151336,151338]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)

可以看到,模型是将几个prompt合在了一起送入模型,同时模型能够一次性给出三个问题的答案。
句子循环输入
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151329,151336,151338]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)for prom in prompt:
messages =[{'role':'user','content':prom}]
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)print(outputs[0].outputs[0].text)
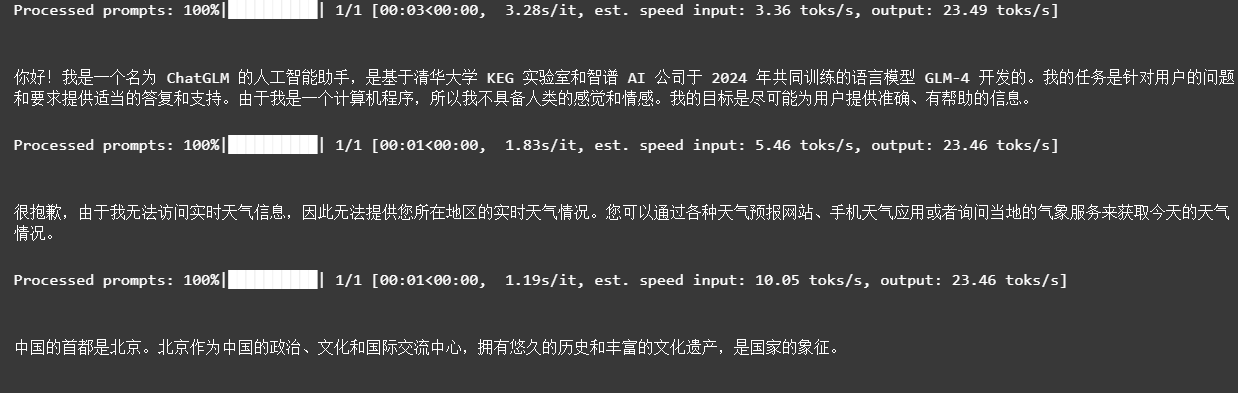
3.2.1 调用vllm的类openai功能
python -m vllm.entrypoints.openai.api_server这个命令是用来启动一个兼容OpenAI API的HTTP服务器,该服务器利用vLLM(virtual Large Language Model)库来提供大规模语言模型的推理服务。
详细的参数见https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html的Named Arguments部分。
#--model需要指定模型路径#--served-model-name指定模型名称,否则调用时就需要输出整个模型的路径#--trust-remote-code,不添加会报错#--max-model-len设定模型最大长度512,否则24G显存的GPU会爆显存。
python -m vllm.entrypoints.openai.api_server \
--model /mnt/workspace/models/ZhipuAI/glm-4-9b-chat \
--served-model-name glm-4 \
--trust-remote-code \
--max-model-len512

等待出现如上图所示的信息后,就可以使用类openai风格的调用方式,来实现对glm-4的访问。
from openai import OpenAI
base_url ="http://0.0.0.0:8000/v1/"
api_key='None'
client = OpenAI(base_url=base_url,api_key=api_key)
messages=[{'role':'user','content':'请介绍下自己'}]
response = client.chat.completions.create(
model='glm-4',
messages=messages
)print(response.choices[0].message.content)

3.3 利用ollama部署
Ollama 是一个开源项目,旨在简化和加速大语言模型(LLMs)的部署和推理过程。Ollama 提供了一个轻量级的服务框架,使得用户可以轻松地将各种语言模型转化为可调用的API服务,从而便于集成到不同的应用程序中。Ollama 支持多种模型格式,包括 Hugging Face 的 Transformers,以及 ONNX 和 ggml 等格式。
主要特点
- 易用性: Ollama 提供了一个简单的命令行界面,用户只需几行命令即可启动模型服务,无需深入理解底层的模型细节或复杂的部署流程。
- 高性能: Ollama 利用了高效的推理算法和优化过的模型加载方式,可以在不牺牲性能的前提下支持大型语言模型的实时推理。
- 模型多样化: Ollama 支持多种语言模型,包括但不限于 LLaMA、Falcon、StableLM 和 GPT-J 等,这为用户提供了广泛的选择范围。
- 多平台兼容性: Ollama 可以在多种操作系统上运行,包括 Linux 和 macOS,并且能够利用 CPU 或 GPU 进行加速。
- API友好: Ollama 提供了一个RESTful API接口,允许开发者通过HTTP请求调用模型,进行文本生成、问答等任务。
ollama官网:https://ollama.com/library
ollama的github:https://github.com/ollama/ollama
3.3.1 部署流程
3.3.1.1 ollama下载与启动
在下载ollama前,先配置下环境,加速下载,windows下,在hosts文件,在linux下,在/etc/hosts下,添加如下信息加速下载(可能会失效):
# github 注意下面的IP地址和域名之间有一个空格
140.82.114.3 github.com
199.232.69.194 github.global.ssl.fastly.net
185.199.108.153 assets-cdn.github.com
185.199.109.153 assets-cdn.github.com
185.199.110.153 assets-cdn.github.com
185.199.111.153 assets-cdn.github.com
- linux下载ollama: curl -fsSL https://ollama.com/install.sh | sh 1. 这行命令的目的是从https://ollama.com/读取 install.sh 脚本,再立即通过 sh执行该脚本,在安装过程中会包含以下几个主要的操作: 1. 检查当前服务器的基础环境;2. 下载Ollama二进制文件;3. 配置系统服务,包括创建用户和用户组,并添加Ollama配置信息;4. 启动Ollama服务。
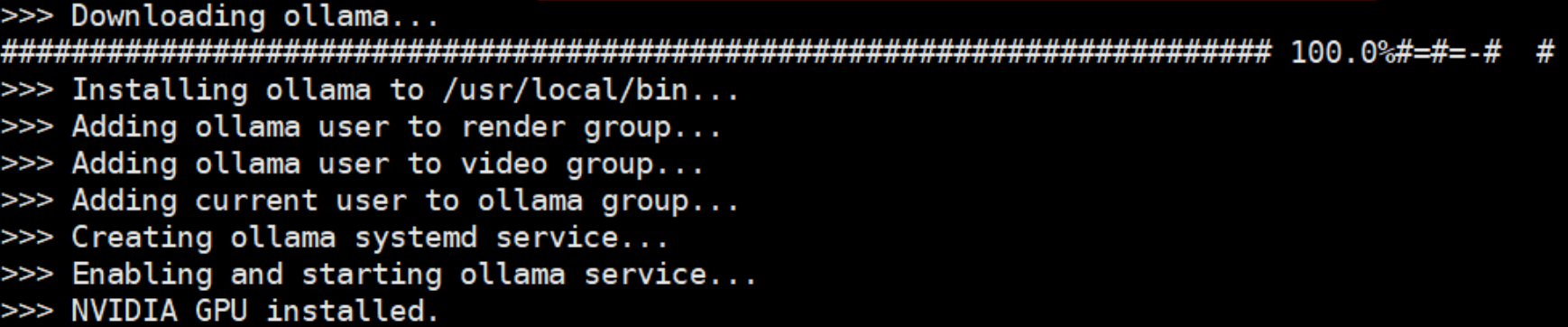
可以看到默认安装路径是/usr/local/bin
2. 检查ollama运行状态:systemctl status ollama
3. 可以通过输入ollama查看命令
- 如果主机已关闭,那么重新启动ollama: ollama serve
- 配置开机启动:sudo systemctl enable ollama
3.3.1.2 模型下载与使用
- 模型搜索:在点击Models,进入模型选项页
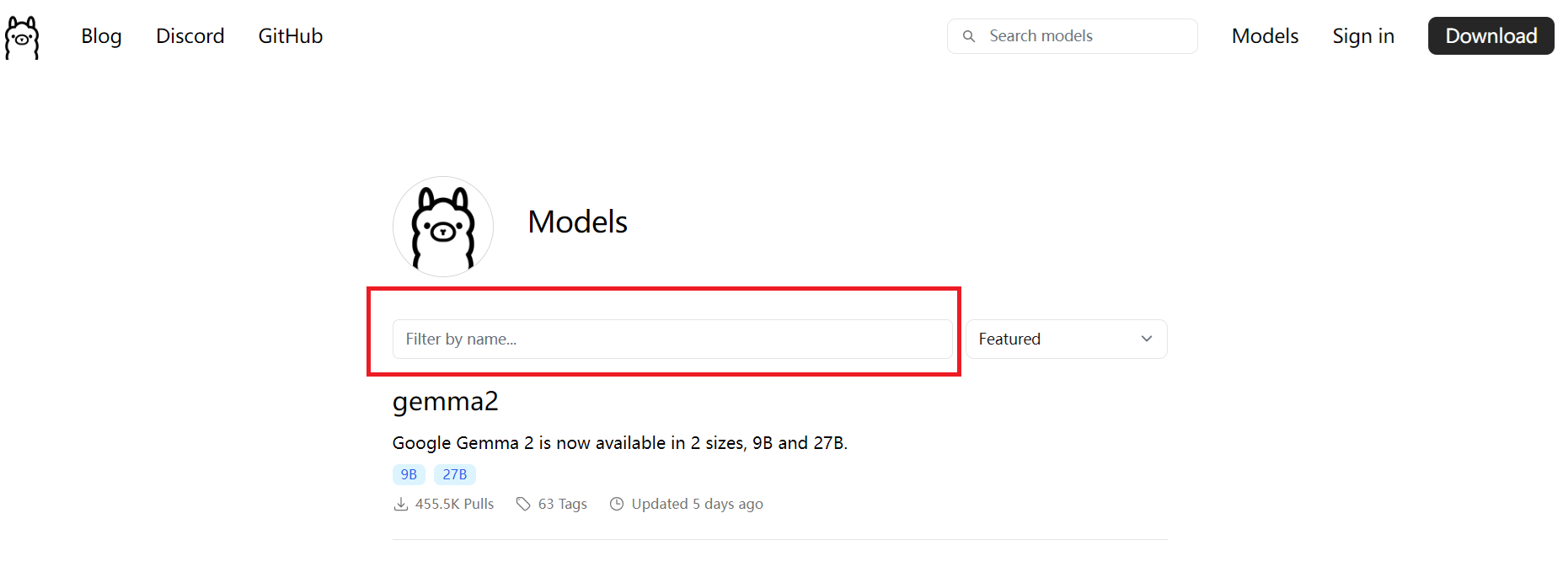
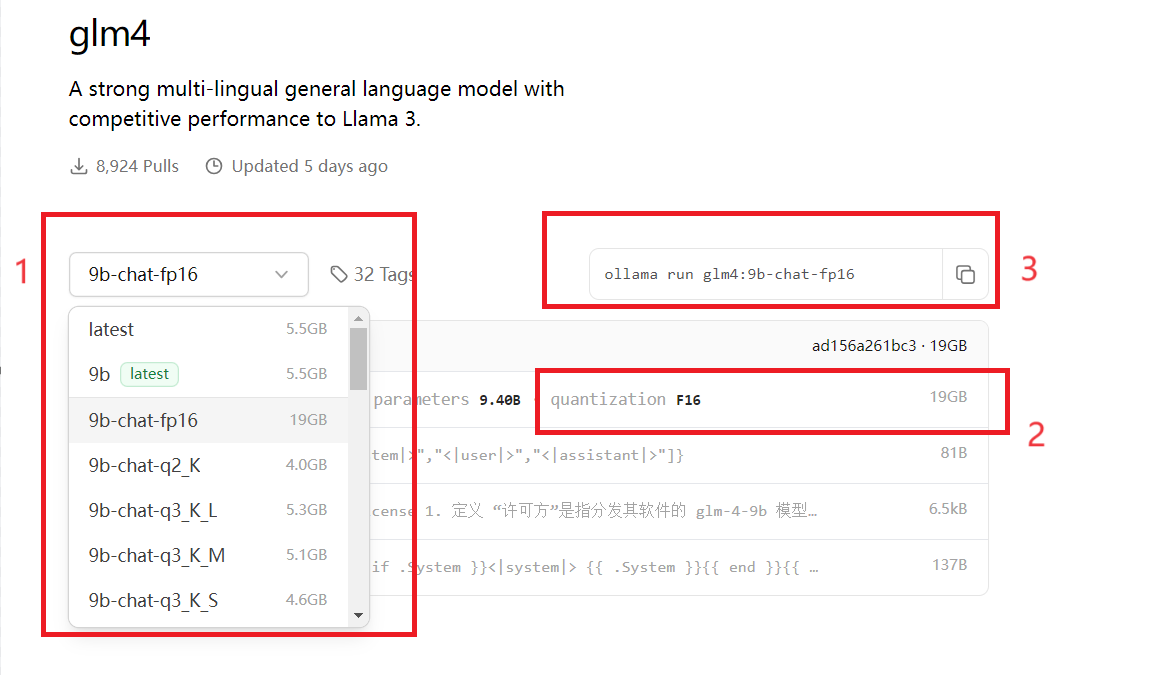
- 模型下载在搜索栏输入模型,如glm4。点击进入glm4页面。注意,模型一般有很多选项,可以通过下拉菜单(下图序号1)选择对应的模型,会显示模型相关的信息,如模型大小、量化信息(下图序号2)等,选择好模型后,在在右上角会出现模型的运行命令(下图序号3),复制该命令ollama run glm4:9b-chat-fp16到命令行运行,此时会自动从ollama拉取对应模型拉取完毕后直接进入模型,拉取速度还是很快的。ollama下载的模型,相对路径为.ollama/models,默认路径为/home/用户名/.ollama/models。当然也可以ollama pull glm4:9b-chat-fp16,那么就只拉取模型。
3. 启动模型:
- 首次运行时,模型会先下载对应的模型,下载完毕后,进入到模型。

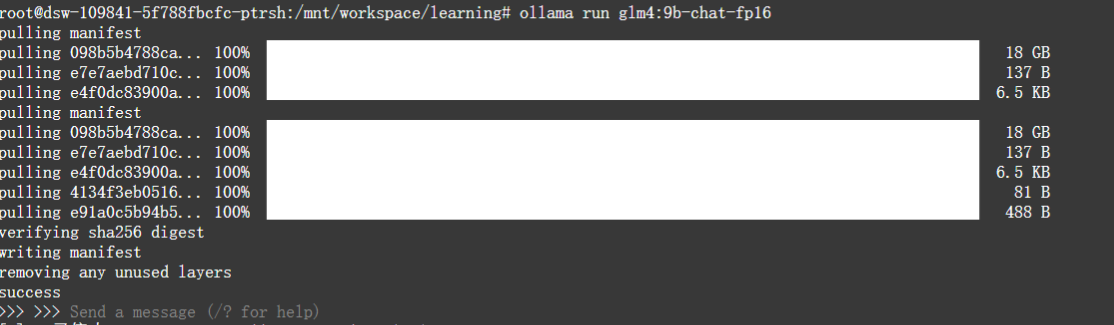
此时可以在命令行输入对话内容。
输入/?可以查看一些帮助信息。
2. 非首次运行时,模型会直接进入到模型


3.3.1.3 ollama启动大模型API服务
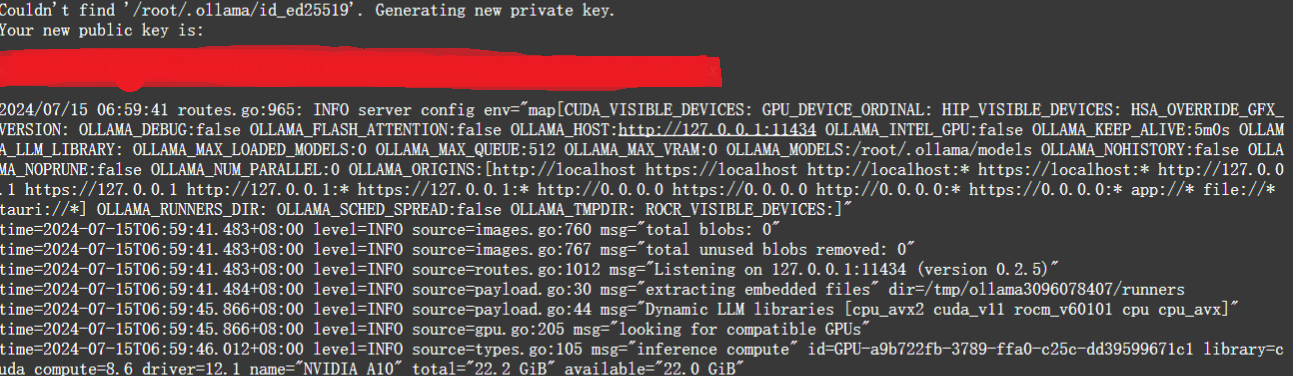
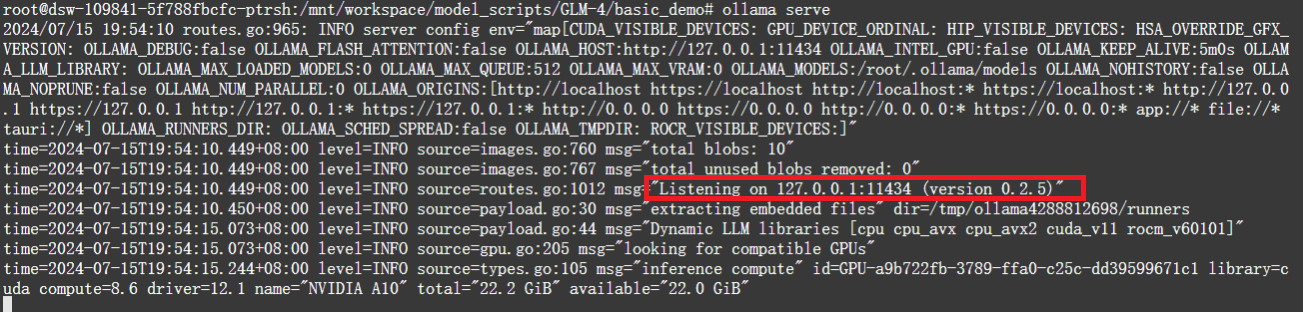
上述利用ollama启动模型的方式,是在命令行中,实际使用时,肯定不会以这种方式运行。实际使用时,常见的两种使用方式是API和网页。Ollama提供了一个REST API,用于运行和管理模型,启动脚本中包含了如下的初始化时,提供了api调用信息如下:
同时,模型的名称是我们启动模型是的名称,如启动命令ollama run glm4:9b-chat-fp16,那么模型的名称就是glm4:9b-chat-fp16,所以模型的类openai的api调用如下。
from openai import OpenAI
base_url ="http://127.0.0.1:11434/v1/"
api_key='None'
client = OpenAI(base_url=base_url,api_key=api_key)
messages=[{'role':'user','content':'请介绍下自己'}]
response = client.chat.completions.create(
model='glm4:9b-chat-fp16',
messages=messages
)print(response.choices[0].message.content)

可以看到,可以正常调用了。另外通过命令lsof -i :11434。使用
lsof命令可以找出哪个进程监听在指定的端口上,输出中的 PID 列显示了进程的 ID,而进程名正是
ollama服务

3.3.1.4 open-webui启动
前面介绍了ollama的API启动方法,这里介绍大模型另一种常用方式:网页端。ollama常用的网页端为open-webui。安装方法如下:
如果没有docker需要先安装:
- 卸载旧版本:sudo apt-get remove docker docker-engine docker.io containerd runc
- 更新软件包索引,并且安装必要的依赖软件,来添加一个新的 HTTPS 软件源: 1. sudo apt update2. sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
- 使用下面的
curl导入源仓库的 GPG key:curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -- 将 Docker APT 软件源添加到你的系统:sudo add-apt-repository “deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable”
- 安装docker:sudo apt install docker-ce docker-ce-cli containerd.io
- 一旦安装完成,Docker 服务将会自动启动。你可以输入下面的命令,验证它:sudo systemctl status docker
由于已经安装了ollama,那么可以直接运行:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
等待拉取镜像,完成后。在host上访问3000端口即可打开Open WebUI页面:
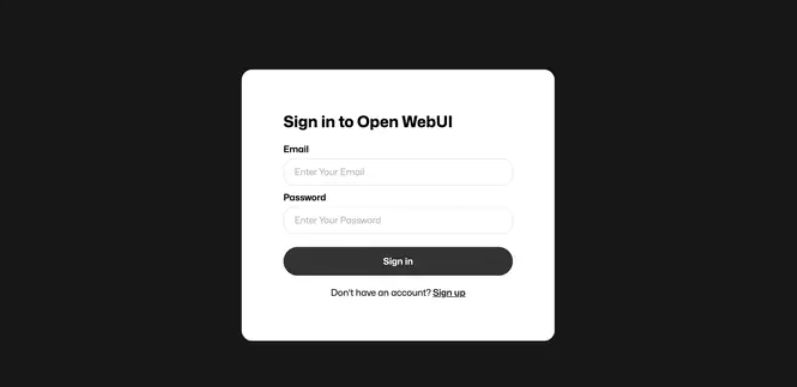
此时第一次进入,需要进行注册,首个注册的用户,将会被Open WebUI认为是admin用户!注册登录后,我们就可以进入首页。
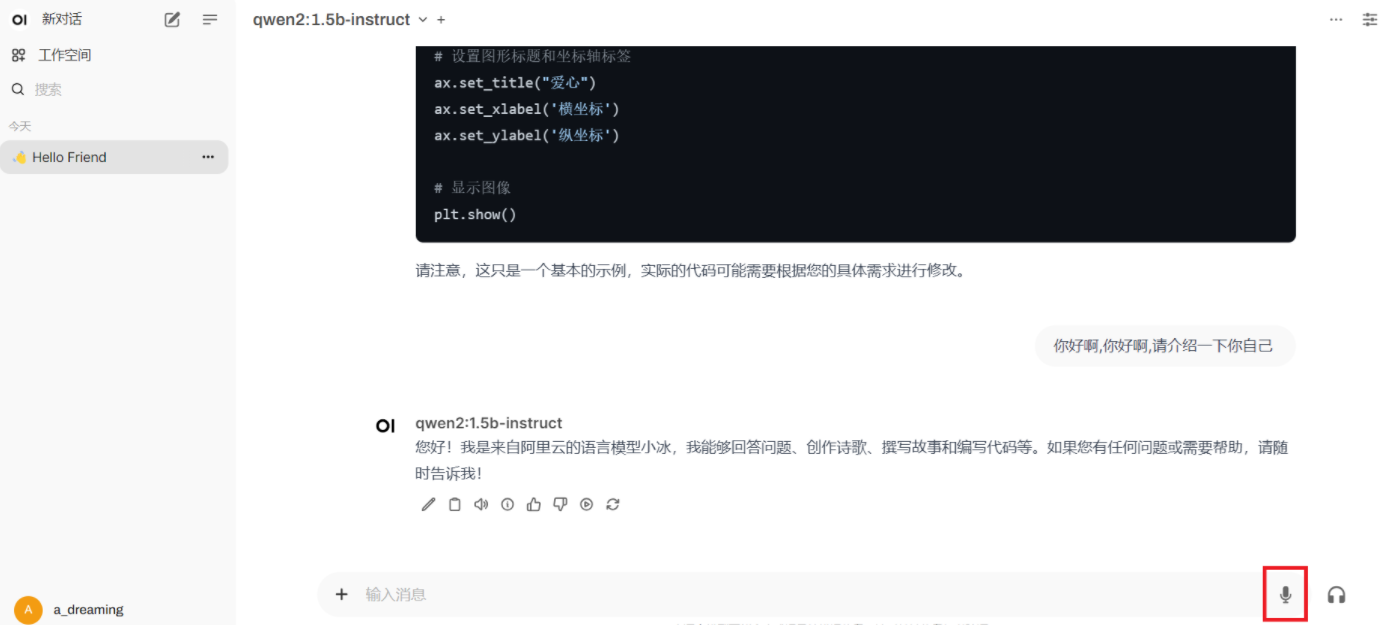
可以看到open-webui网页端与chatgpt有一定的相似度。与大模型交互可以用文字,也可以语音转文字。
除此之外,open-webui还可以同时加载多个模型,当模型的所需的显存不超过物理机实际显存时,模型会一直常驻,那么几个模型会同时工作,同时回答问题。如果超过,那么每次对话时,都会重新逐个加载每个模型,各个模型逐个回答问题。
还可以看到,模型返回的内容下面,都会出现这样的内容,分别表示:编辑、复制、朗读、生成信息、点赞次回答、点踩此回答、继续生成、重新生成。
可以看到open-webui的强大之处。

3.3.1.5 ollama常见设置
使用ollama serve启动ollama时,会使用很多默认参数,
这些参数是什么意思呢,可以输入ollama serve -h,查看到具体信息
- OLLAMA_HOST用来设置IP或端口,默认使用127.0.0.1:11434,只能在本机使用,可以通过对该参数进行设置,可以外网访问。如设置成0.0.0.0:8080。
- OLLAMA_KEEP_ALIVE表示模型在内存中的停留时长,默认为5分钟,可以通过设置这个值,让模型常驻。如设置成24h,表示模型加载到内存中保持24个小时。
- OLLAMA_MODELS 模型路径
- .OLLAMA_NUM_PARALLEL表示模型最大并发请求数量。如果超过最大并发请求,新的请求就会等待旧的请求结束。比如现在设置OLLAMA_NUM_PARALLEL=4,那么最多同时响应4个请求,当第5个请求来了,那么必须等待其中一个结束,才能响应第五个请求。
- OLLAMA_MAX_LOADED_MODELS 设置同时加载的模型数量。


以上参数,可以临时使用,也可以写入配置文件。
- 临时使用:命令 ollama serve 。这里的命令就是上面介绍的那些命令。如OLLAMA_HOST=0.0.0.0:18889 OLLAMA_KEEP_ALIVE=24h OLLAMA_NUM_PARALLEL=2 ollama serve 表示设置成所以IP均可访问,端口为18889,模型存活24小时,并发数为2。
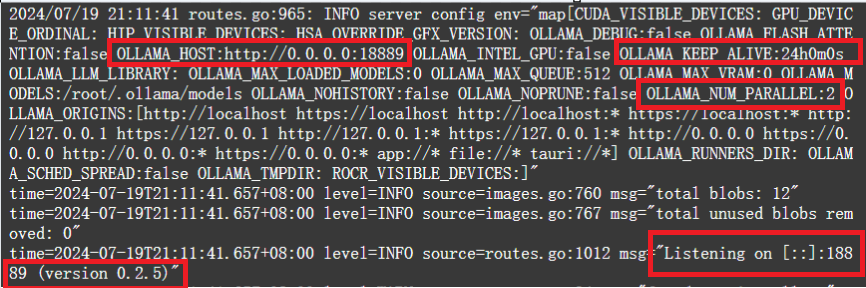
可以看到命令生效了。
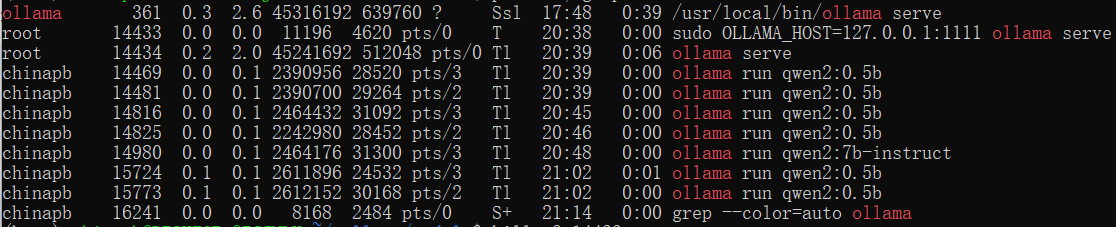
通过 linux的命令:ps aux | grep service_name 查看模型的PID情况,这里是ps aux | grep ollama。
为了演示,之前启动了很多qwen2的小模型。
使用命令 kill -9 $(pgrep ollama)先把所有ollama相关服务全部杀死,重新启动。
2. 永久生效。想要使得配置永久生效,需要写入配置信息到文件。后面再补充该部分。
四、Qwen2-7B-Instruct部署
Qwen2-7B-Instruct的部署和glm-4及其类似。
4.1transformers直接部署
4.1.1 依赖包安装
依赖包安装:
- Qwen2并没有直接给出依赖包的requirements.txt,在Qwen文档中提到需要安装最新版本的
transformers库,或者至少安装4.40.0版本。pip install transformers -U- 由于前期已经安装了glm-4的依赖包,就直接使用,不在继续安装。如果是从头开始,那么在安装完transformers后,可以在运行时,缺少什么包就安装什么包即可。
4.1.2 部署模型自带demo
4.1.2.1 直接使用transformers库
from transformers import AutoModelForCausalLM, AutoTokenizer
device ="cuda"# the device to load the model onto# Now you do not need to add "trust_remote_code=True"# "Qwen/Qwen2-7B-Instruct"修改问本地权重实际路径,我这里是/mnt/workspace/models/qwen/Qwen2-7B-Instruct# model和tokenizer都要改
model = AutoModelForCausalLM.from_pretrained("/mnt/workspace/models/qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/models/qwen/Qwen2-7B-Instruct")# Instead of using model.chat(), we directly use model.generate()# But you need to use tokenizer.apply_chat_template() to format your inputs as shown below
prompt ="Give me a short introduction to large language model."
messages =[{"role":"system","content":"You are a helpful assistant."},{"role":"user","content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)# Directly use generate() and tokenizer.decode() to get the output.# Use `max_new_tokens` to control the maximum output length.
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512)
generated_ids =[
output_ids[len(input_ids):]for input_ids, output_ids inzip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]

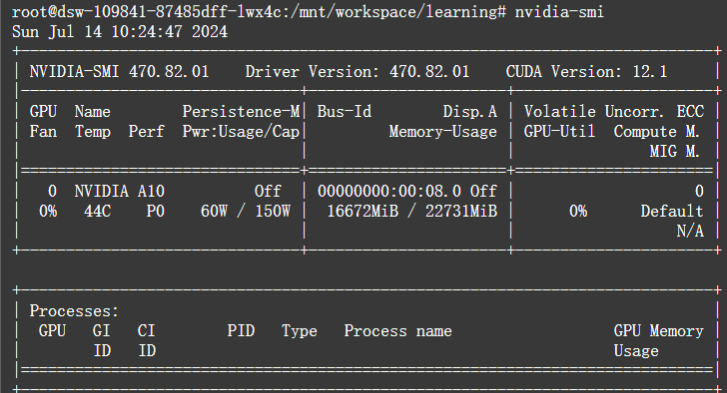
可以看到模型加载了10个分片文件,是模型的权重,然后对我们提出的问题,模型给出了对应的答案。
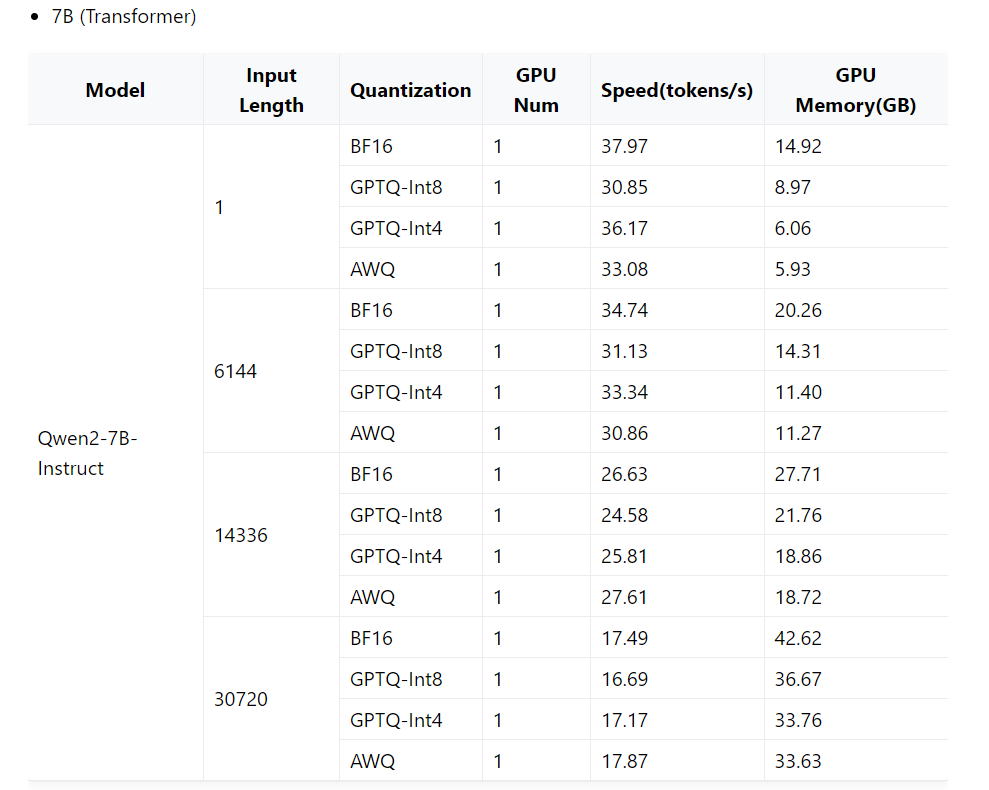
模型占用的显存如下图,数据类型bf16的情况下,用了16G,基本和官方要求给出的一致。
import torch
from transformers import AutoModelForCausalLM,AutoTokenizer
model_path='/mnt/workspace/models/qwen/Qwen2-7B-Instruct'
device='cuda:0'# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_path,
torch_dtype=torch.bfloat16,
device_map='auto').eval()# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
prompt ="请介绍下你自己"
messages =[{"role":"system","content":"You are a helpful assistant."},{"role":"user","content": prompt}]defchat(model,tokenizer,messages):
text = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer([text],return_tensors='pt').to(device)#do_sample:根据预测的概率分布随机选择下一个token,而不是简单地选择概率最高的token。这有助于增加生成文本的多样性和创造性。#top_k :当do_sample为True时,top_k参数变得重要。它指定了在采样过程中考虑的预测概率最高的token的数量#max_new_tokens:这个参数控制着生成文本的总长度,不包括输入文本的长度,生成的文本达到这个长度,生成过程就会停止。
gen_kwargs ={"max_new_tokens":500,"do_sample":True,"top_k":1}#gen_kwargs = {"max_new_tokens": 500, "do_sample": False}# "do_sample": True, "top_k">1时,生成的对话不一定符合要求。
outputs = model.generate(**model_inputs,**gen_kwargs)
outputs = tokenizer.batch_decode(outputs[:,model_inputs['input_ids'].shape[1]:],
skip_special_tokens=True)[0]print(outputs)
chat(model,tokenizer,messages)

4.1.2.2 利用qwen2自带的命令行demo
在qwen2源码的examples/demo目录下,有多个简单的的demo。其中,cli_demo.py是大模型在命令行的简单使用,使用方式如下:
- 进入到basic_demo目录:cd examples/demo
- 修改路径:cli_demo.py中DEFAULT_CKPT_PATH路径为权重文件的实际存储路径
- 运行程序:python cli_demo.py

此时出现了如上图所示的界面,在User后面输入内容,Enter之后,会得到模型的回复,如下图所示。

4.1.2.3利用qwen2自带的网页demo
在qwen2源码的examples/demo目录下,有多个简单的的demo。其中,web_demo.py是大模型在命令行的简单使用,使用方式如下:
- 进入到basic_demo目录:cd examples/demo
- 修改路径:web_demo.py中DEFAULT_CKPT_PATH路径为权重文件的实际存储路径
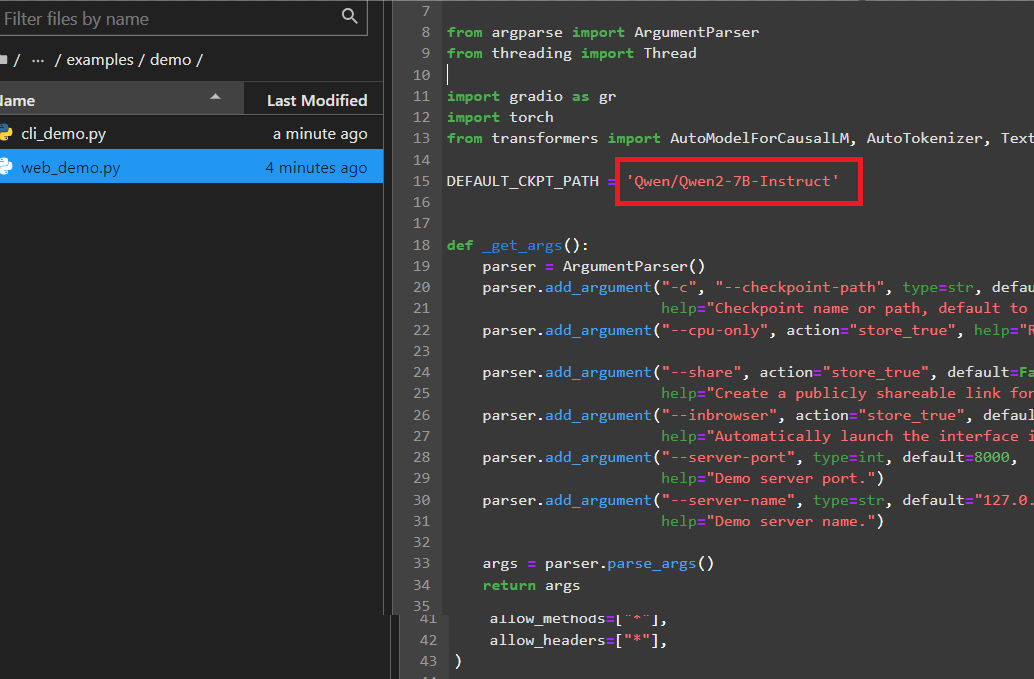
- 运行程序:python web_demo.py

此时出现了如上图所示的界面,点击或复制那个url,就会进入网页端的聊天页面,如下图所示。
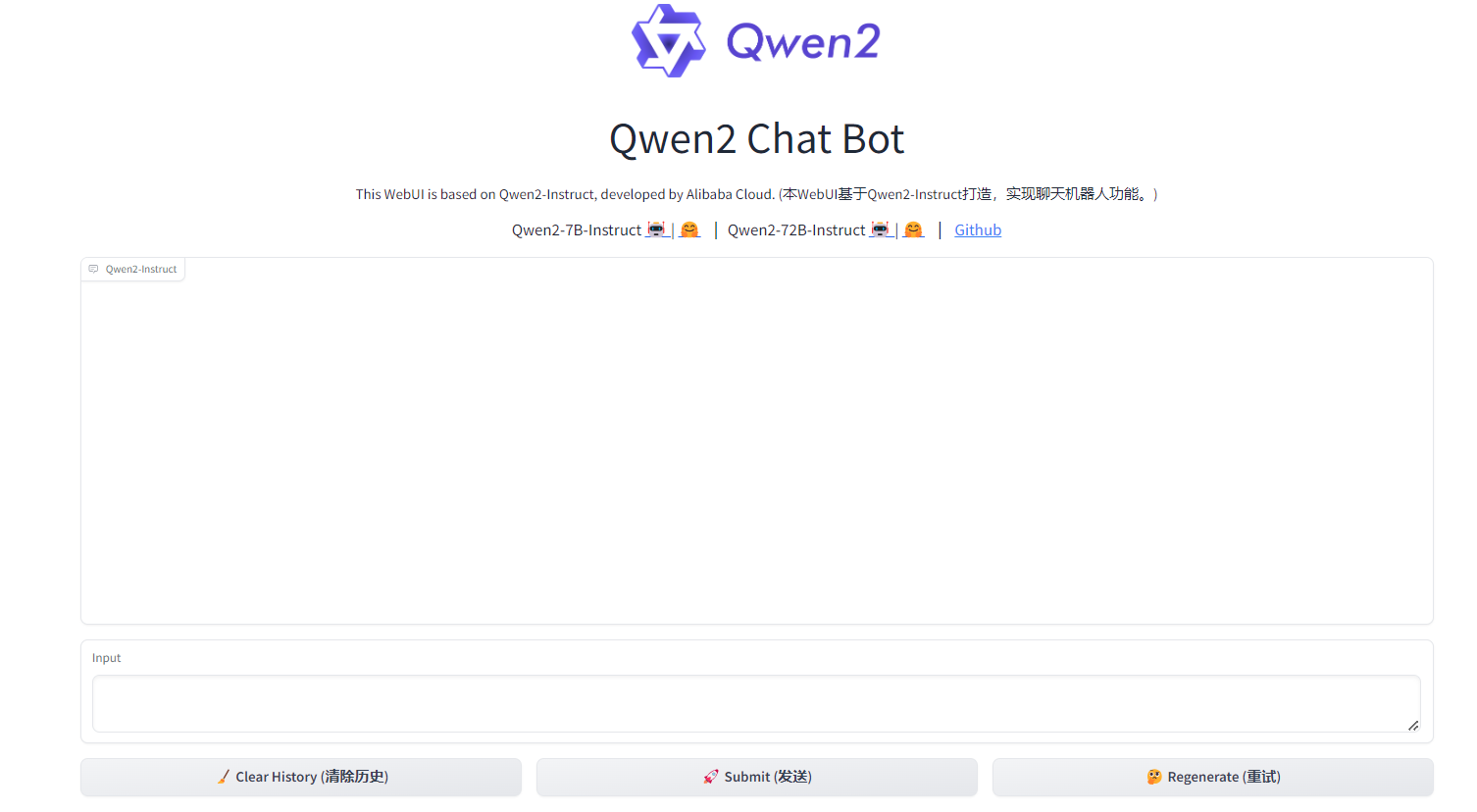
在input中输入聊天内容,点击Submit,可以得到如下的回复。
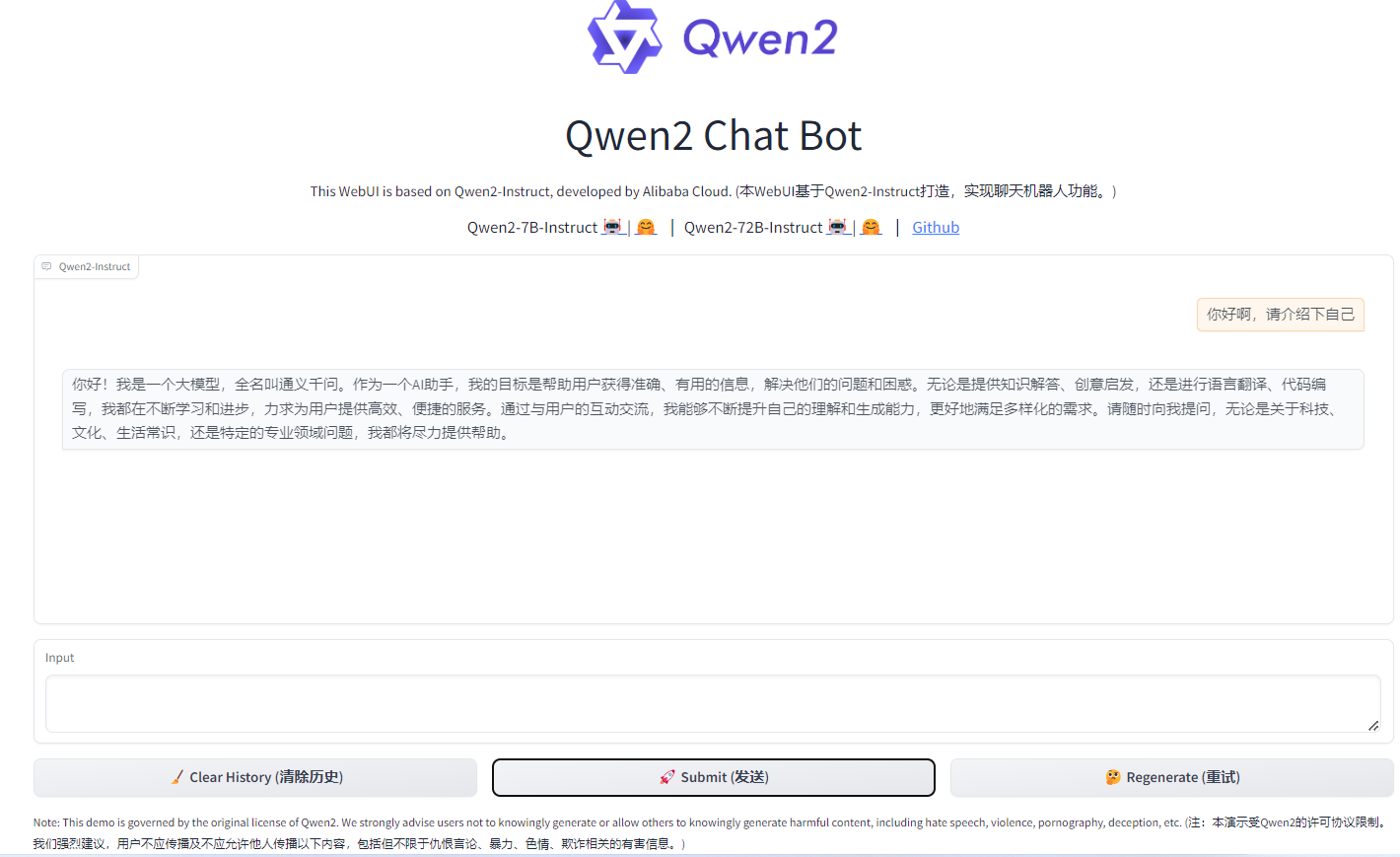
在后台同样可以看到刚刚的聊天内容。

4.2利用vllm部署
4.2.1 使用vllm类调用模型
4.2.1.1vllm官方例子改写
同glm-4的调用一样,同样改写vllm官方的小例子https://docs.vllm.ai/en/latest/getting_started/examples/offline_inference.html
qwen2的加载与使用会比较慢,要耐心等待。
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/ZhipuAI/glm-4-9b-chat"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)#max_tokens生成的最大长度不超过多少tokens
sampling_params = SamplingParams(temperature=0.95, max_tokens=512)
outputs = llm.generate(prompts=prompt, sampling_params=sampling_params)for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

可以看到,虽然能够生成答案,但是生成的答案不太符合对话,更像是续写。所以接下来仿照glm-4官方给出的例子。
4.2.1.2 qwen2借鉴GLM-4官方例子
qwen2可以完全借鉴GLM-4官方例子,只需要修改模型地址为qwen2的模型地址,stop_token_ids改为qwen2的generation_config.json中的eos_token_id
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/qwen/Qwen2-7B-Instruct"
prompt =[{"role":"user","content":"请介绍下自己"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)
stop_token_ids =[151645,151643]
sampling_params = SamplingParams(temperature=0.95, max_tokens=512, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)print(outputs[0].outputs[0].text)

可以看出,官方的例子符合人类对话习惯,不再是补齐。
4.2.1.3 qwen2借鉴GLM-4官方例子扩充-批量处理
每个message都组合成message={‘role’:‘user’,‘conent’,prompt}的格式,然后messages将多个message组合起来。
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/qwen/Qwen2-7B-Instruct"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
messages=[]for prom in prompt:
message ={'role':'user','content':prom}
messages.append(message)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151645,151643]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)

这种方法只会生成最后一个问题的答案。不可取。
prompt合在一起,输入到messages,即messages=[{‘role’:‘user’,‘conent’,prompt}]的格式
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/qwen/Qwen2-7B-Instruct"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
messages ={'role':'user','content':prompt}
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151645,151643]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)

可以看到此时会报错。
句子循环输入
from transformers import AutoTokenizer
from vllm import LLM,SamplingParams
# GLM-4-9B-Chat# max_model_len, tp_size = 1000, 4# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size =1000,1
model_name ="/mnt/workspace/models/qwen/Qwen2-7B-Instruct"
prompt=['请介绍下自己','今天天气如何','中国的首都是哪里?']
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,#模型名称或路径
tensor_parallel_size=tp_size,#GPU并行度,与GPU数量相关,1个GPU并行度就设置为1
max_model_len=max_model_len,#模型能处理的最大长度(即输入长度)
trust_remote_code=True,
enforce_eager=True,# GLM-4-9B-Chat 如果遇见 OOM 现象,建议开启下述参数# enable_chunked_prefill=True,# max_num_batched_tokens=8192)# 对应eos_token_id
stop_token_ids =[151645,151643]
sampling_params = SamplingParams(temperature=0.95,max_tokens=1024,stop_token_ids=stop_token_ids)for prom in prompt:
messages =[{'role':'user','content':prom}]
inputs = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
outputs = llm.generate(prompts=inputs,sampling_params=sampling_params)print(outputs[0].outputs[0].text)
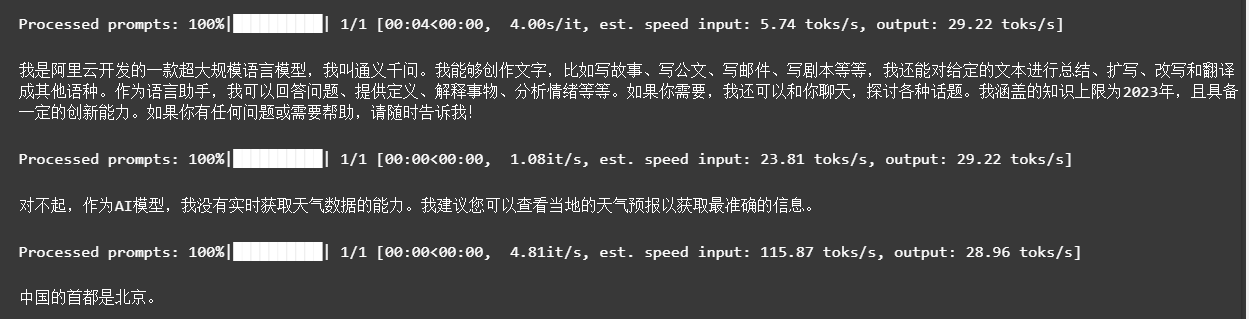
4.2.2 调用vllm的类openai功能
python -m vllm.entrypoints.openai.api_server这个命令是用来启动一个兼容OpenAI API的HTTP服务器,该服务器利用vLLM(virtual Large Language Model)库来提供大规模语言模型的推理服务。
详细的参数见https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html的Named Arguments部分。
#--model需要指定模型路径#--served-model-name指定模型名称,否则调用时就需要输出整个模型的路径#--max-model-len模型最大长度8192,否则报错:ValueError: The model's max seq # len (32768) is larger than the maximum number of tokens that can be # stored in KV cache (18656). Try increasing `gpu_memory_utilization` or # decreasing `max_model_len` when initializing the engine.。# 在这里指定了host和port以及api-key
python -m vllm.entrypoints.openai.api_server \
--model /mnt/workspace/models/qwen/Qwen2-7B-Instruct \
--served-model-name qwen2 \
--host 127.0.0.1 \
--port 2222 \
--api-key test001 \
--max-model-len8192

等待出现如上图所示的信息后,就可以使用类openai风格的调用方式,来实现对qwen2的访问。
from openai import OpenAI
# 改成指定的url和port
base_url ="http://127.0.0.1:2222/v1/"# 改成指定的api-key
api_key='test001'
client = OpenAI(base_url=base_url,api_key=api_key)
messages=[{'role':'user','content':'请介绍下自己'}]
response = client.chat.completions.create(
model='qwen2',#指定了模型名称
messages=messages
)print(response.choices[0].message.content)

4.3利用ollama部署
Ollama 是一个开源项目,旨在简化和加速大语言模型(LLMs)的部署和推理过程。Ollama 提供了一个轻量级的服务框架,使得用户可以轻松地将各种语言模型转化为可调用的API服务,从而便于集成到不同的应用程序中。Ollama 支持多种模型格式,包括 Hugging Face 的 Transformers,以及 ONNX 和 ggml 等格式。
主要特点
- 易用性: Ollama 提供了一个简单的命令行界面,用户只需几行命令即可启动模型服务,无需深入理解底层的模型细节或复杂的部署流程。
- 高性能: Ollama 利用了高效的推理算法和优化过的模型加载方式,可以在不牺牲性能的前提下支持大型语言模型的实时推理。
- 模型多样化: Ollama 支持多种语言模型,包括但不限于 LLaMA、Falcon、StableLM 和 GPT-J 等,这为用户提供了广泛的选择范围。
- 多平台兼容性: Ollama 可以在多种操作系统上运行,包括 Linux 和 macOS,并且能够利用 CPU 或 GPU 进行加速。
- API友好: Ollama 提供了一个RESTful API接口,允许开发者通过HTTP请求调用模型,进行文本生成、问答等任务。
ollama官网:https://ollama.com/library
ollama的github:https://github.com/ollama/ollama
4.3.1 部署流程
4.3.1.1 ollama下载与启动
- linux下载ollama: curl -fsSL https://ollama.com/install.sh | sh 1. 这行命令的目的是从https://ollama.com/读取 install.sh 脚本,再立即通过 sh执行该脚本,在安装过程中会包含以下几个主要的操作: 1. 检查当前服务器的基础环境;2. 下载Ollama二进制文件;3. 配置系统服务,包括创建用户和用户组,并添加Ollama配置信息;4. 启动Ollama服务。
- 检查ollama运行状态:systemctl status ollama
- 可以通过输入ollama查看命令
- 如果主机已关闭,那么重新启动ollama: ollama serve
- 配置开机启动:sudo systemctl enable ollama
4.3.1.2 模型下载与使用
- 模型搜索:在点击Models,进入模型选项页
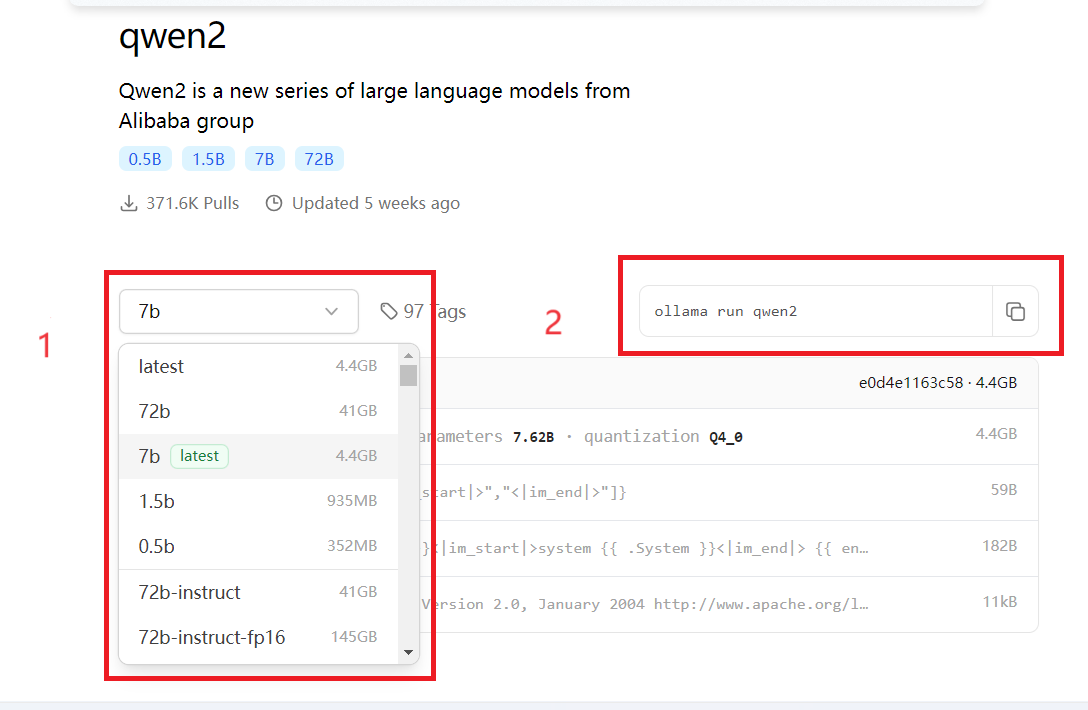
- 模型下载在搜索栏输入模型,如qwen2。点击进入glm4页面。注意,模型一般有很多选项,可以通过下拉菜单(下图序号1)选择对应的模型,会显示模型相关的信息,如模型大小、量化信息(下图序号2)等,选择好模型后,在在右上角会出现模型的运行命令(下图序号3),复制该命令ollama run qwen2:7b-instruct-fp16到命令行运行,此时会自动从ollama拉取对应模型,速度还是很快的。ollama下载的模型,相对路径为.ollama/models
3. 启动模型:
- 首次运行时,模型会先下载对应的模型,下载完毕后,进入到模型。

此时可以在命令行输入对话内容。
输入/?可以查看一些帮助信息。
2. 非首次运行时,模型会直接进入到模型


4.3.1.3 ollama启动大模型API服务
上述利用ollama启动模型的方式,是在命令行中,实际使用时,肯定不会以这种方式运行。实际使用时,常见的两种使用方式是API和网页。Ollama提供了一个REST API,用于运行和管理模型,启动脚本中包含了如下的初始化时,提供了api调用信息如下:
同时,模型的名称是我们启动模型是的名称,如启动命令ollama run glm4:9b-chat-fp16,那么模型的名称就是glm4:9b-chat-fp16,所以模型的类openai的api调用如下。
from openai import OpenAI
base_url ="http://127.0.0.1:11434/v1/"
api_key='None'
client = OpenAI(base_url=base_url,api_key=api_key)
messages=[{'role':'user','content':'请介绍下自己'}]
response = client.chat.completions.create(
model='qwen2:7b-instruct-fp16',
messages=messages
)print(response.choices[0].message.content)

可以看到,可以正常调用了。另外通过命令lsof -i :11434。使用
lsof命令可以找出哪个进程监听在指定的端口上,输出中的 PID 列显示了进程的 ID,而进程名正是
ollama服务
4.3.1.4 启动时设置IP、端口
默认情况下,Ollama 服务只监听本地 IP 地址(127.0.0.1)上的端口 11434。为了使服务可以从外部网络访问,需要编辑
/etc/systemd/system/ollama.service文件,修改
Environment行中的
OLLAMA_HOST参数。/etc/systemd/system/ollama.service
vim /etc/systemd/system/ollama.service
新增如下内容:
Environment="OLLAMA_HOST=0.0.0.0:8899"
# 在Linux系统中,修改了任何服务的配置文件(比如创建新的服务文件或修改现有的服务
# 文件等)后,需要执行这个命令来让`systemd`知道配置已更改并重新读取它们,
# 执行如下命令:
sudo systemctl daemon-reload
sudo systemctl restart ollama
sudo systemctl status ollama
版权归原作者 清水阁散人 所有, 如有侵权,请联系我们删除。