
一、B+树的演变历史(从BST树到B+树)
1.BST树---二叉查找树
性质:
- 若其左子树非空,则左子树上所有节点的值都小于根节点的值
- 若其右子树非空,则右子树上所有节点的值都大于根节点的值
- 其左右子树都是一棵二叉查找树
左子树<根<右子树,即二叉查找树的中序遍历是一个递增序列。
如下图就是一个二叉查找树:
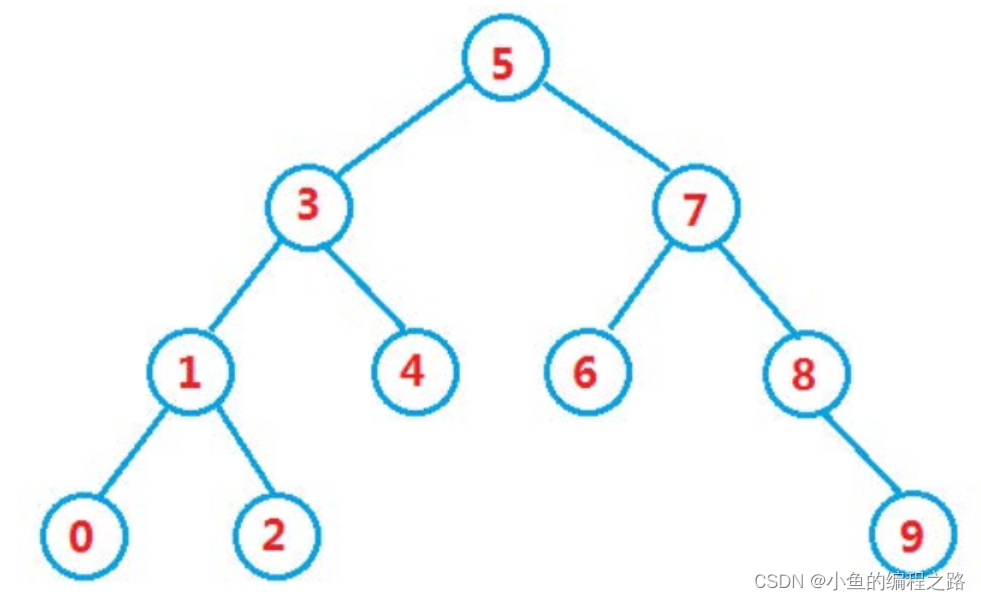
二叉查找树的查询时间复杂度比链表快,链表的查询时间复杂度是O(n),二叉排序树平均是O(logn)。二叉查找树越平衡,越能模拟二分法,所以与二分的思想相似,二叉查找树查询的时间复杂度O(logn)。
缺点:
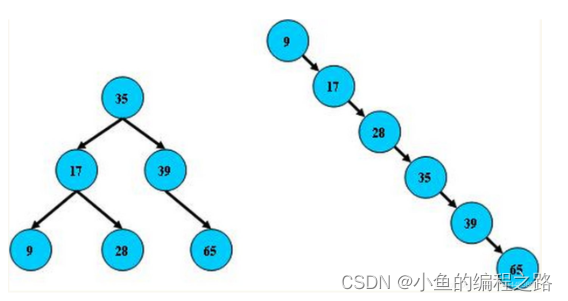
如果插入的结点的值的顺序,是越来越小或者越来越大的,那么BST就会退化为一条链表,那么其查询的时间复杂度就会降为O(n)。如下图所示:
2.AVL树 --- 平衡二叉树
为了解决BST树的缺点,AVL树应运而生。
性质:
- 每棵子树中的左子树和右子树的深度差(平衡因子)的绝对值不能超过1
- 二叉树中每棵子树都要求是平衡二叉树
也就是说,平衡二叉树的前提是它是一棵二叉查找树
平衡二叉树的查找、插入、删除操作在平均和最坏的情况下都是O(logn),这得益于它时刻维护着二叉树的平衡。
平衡因子: 每个结点都有其各自的平衡因子,表示的就是该节点左子树深度减去右子树深度的值称为该结点的平衡因子BF,那么平衡二叉树上的所有节点的平衡因子只能是-1,0,1。只要一棵树中存在平衡因子不是这几个值,则这棵树就是不平衡的,就需要对这棵树进行调整。
AVL树的平衡因子的绝对值不会超过1,正因为如此AVL树的形状肯定不会退化成一条链表的,而是“矮胖”型的树。所以能确保AVL的查找、添加、删除的时间复杂度都是O(logn)。

3.B树 --- 平衡多路查找树
B树和AVL树(平衡二叉树) 的差别就是 B树 属于多叉树,又名平衡多路查找树,即一个结点的查找路径不止左、右两个,而是有多个。数据库索引技术里大量使用者B树和B+树的数据结构。一个结点存储多个值(索引)。
B树的阶数:M阶表示 一个B树的结最多有多少个查找路径(即这个结点有多少个子节点)。M=M路,M=2是二叉树,M=3则是三叉树。
一棵M阶B树有以下特点:
- 每个结点的值(索引) 都是按递增次序排列存放的,并遵循左小右大原则。
- 根结点的子节点个数为 [2,M]。
- 除根结点以外的非叶子结点 的子节点个数为[ Math.ceil(M/2),M],其中Math.ceil() 为向上取整。
- 每个非叶子结点的值(索引) 个数 = **子节点个数 -1 **。最小为 **Math.ceil(M/2)-1 **最大为 **M-1 **个。
- B树的所有叶子结点都位于同一层。
下图就是一个B树:
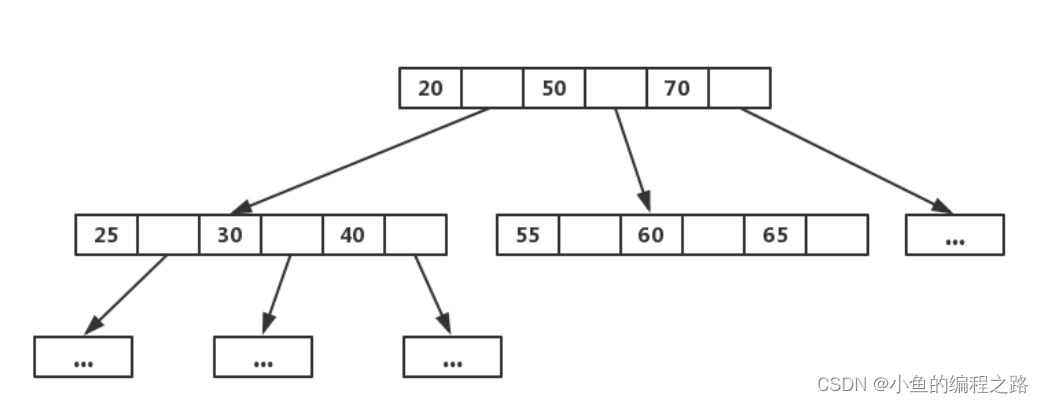
B树的查找结点过程 :
在上图中若搜索 key 为 25 节点的 data,首先在根节点进行二分查找(因为 keys 有序,二分最快),判断 key 25 小于 key 50,所以定位到最左侧的节点,此时进行一次磁盘 IO,将该节点从磁盘读入内存,接着继续进行上述过程,直到找到该 key 为止。
4.B+树
B+树是基于B树的基础提出的。
性质:
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2;
- 根节点的子节点个数可以不超过 m/2,这是一个例外;
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表;
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找;
- 一般情况,根节点会被存储在内存中,其他节点存储在磁盘中。
对于相同个数的数据构建 m 叉树索引,m 叉树中的 m 越大,那树的高度就越小,那 m 叉树中的 m 是不是越大越好呢?到底多大才最合适呢?
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次会读一页的数据。如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。我们该如何解决这个问题呢?
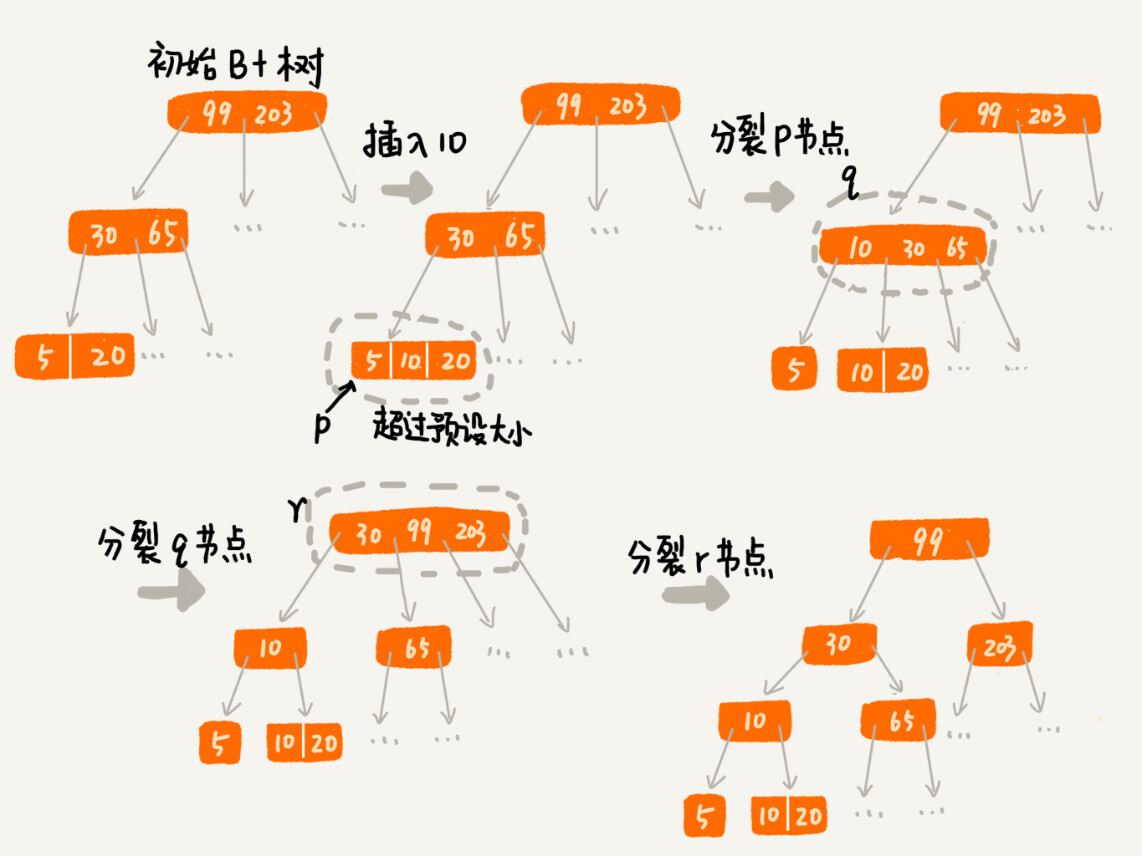
实际上,处理思路并不复杂。我们只需要将这个节点分裂成两个节点。但是,节点分裂之后,其上层父节点的子节点个数就有可能超过 m 个。不过这也没关系,我们可以用同样的方法,将父节点也分裂成两个节点。这种级联反应会从下往上,一直影响到根节点。这个分裂过程,你可以结合着下面这个图一块看,会更容易理解(图中的 B+ 树是一个三叉树。我们限定叶子节点中,数据的个数超过 2 个就分裂节点;非叶子节点中,子节点的个数超过 3 个就分裂节点)。
正是因为要时刻保证 B+ 树索引是一个 m 叉树,所以,索引的存在会导致数据库写入的速度降低。实际上,不光写入数据会变慢,删除数据也会变慢。
因为我们在删除某个数据的时候,也要对应地更新索引节点。这个处理思路有点类似跳表中删除数据的处理思路。频繁的数据删除,就会导致某些节点中,子节点的个数变得非常少,长此以往,如果每个节点的子节点都比较少,势必会影响索引的效率。
所以我们可以设置一个阈值。在 B+ 树中,这个阈值等于 m/2。如果某个节点的子节点个数小于 m/2,我们就将它跟相邻的兄弟节点合并。不过,合并之后节点的子节点个数有可能会超过 m。针对这种情况,我们可以借助插入数据时候的处理方法,再分裂节点。
下图中的 B+ 树是一个五叉树。我们限定叶子节点中,数据的个数少于 2 个就合并节点;非叶子节点中,子节点的个数少于 3 个就合并节点。

而在B+ 树中,将叶子节点串起来的链表是双链表,每个节点都会记住头尾的指针,方便修改,新增,删除;另外一点也是大家写的倒序排列单链表无法实现,单链表只存放的后驱指针所以正向排序是支持的,逆向排序不支持,所以不能是单链表。
接下来我们来看一下B+树的应用场景:
二、B+树应用场景
B+树主要用在磁盘文件组织、数据索引和数据库索引。
(1) B+tree的磁盘读写代价更低
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
(2)B+tree的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
(3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
版权归原作者 小鱼的编程之路 所有, 如有侵权,请联系我们删除。