
一、引言
在医疗领域,人工智能的应用正逐渐从理论走向实践,其中一项关键任务是从海量的医疗文档中提取有价值的信息。我曾参与的项目,正是这一领域的一次尝试。我们的目标是开发一套系统,能够自动从药品说明书中抽取关键医疗信息,如药物成分、适应症、剂量和可能的副作用等。这一过程不仅需要对自然语言处理技术有深入理解,还需要对医疗知识有准确把握。通过这一项目,我们期望能够为医生和药师提供快速准确的药物信息,从而提高医疗决策的效率和质量。
二、用户案例
在项目初期,我作为项目经理,面对的第一个挑战是如何从海量的药品说明书中快速准确地提取关键信息。这些信息对于医生、药剂师和患者来说至关重要,因为它们涉及到药品的剂量、副作用、相互作用等关键参数。传统的手动阅读和记录方法不仅耗时,而且容易出错。为了解决这个问题,我们决定采用信息抽取技术。
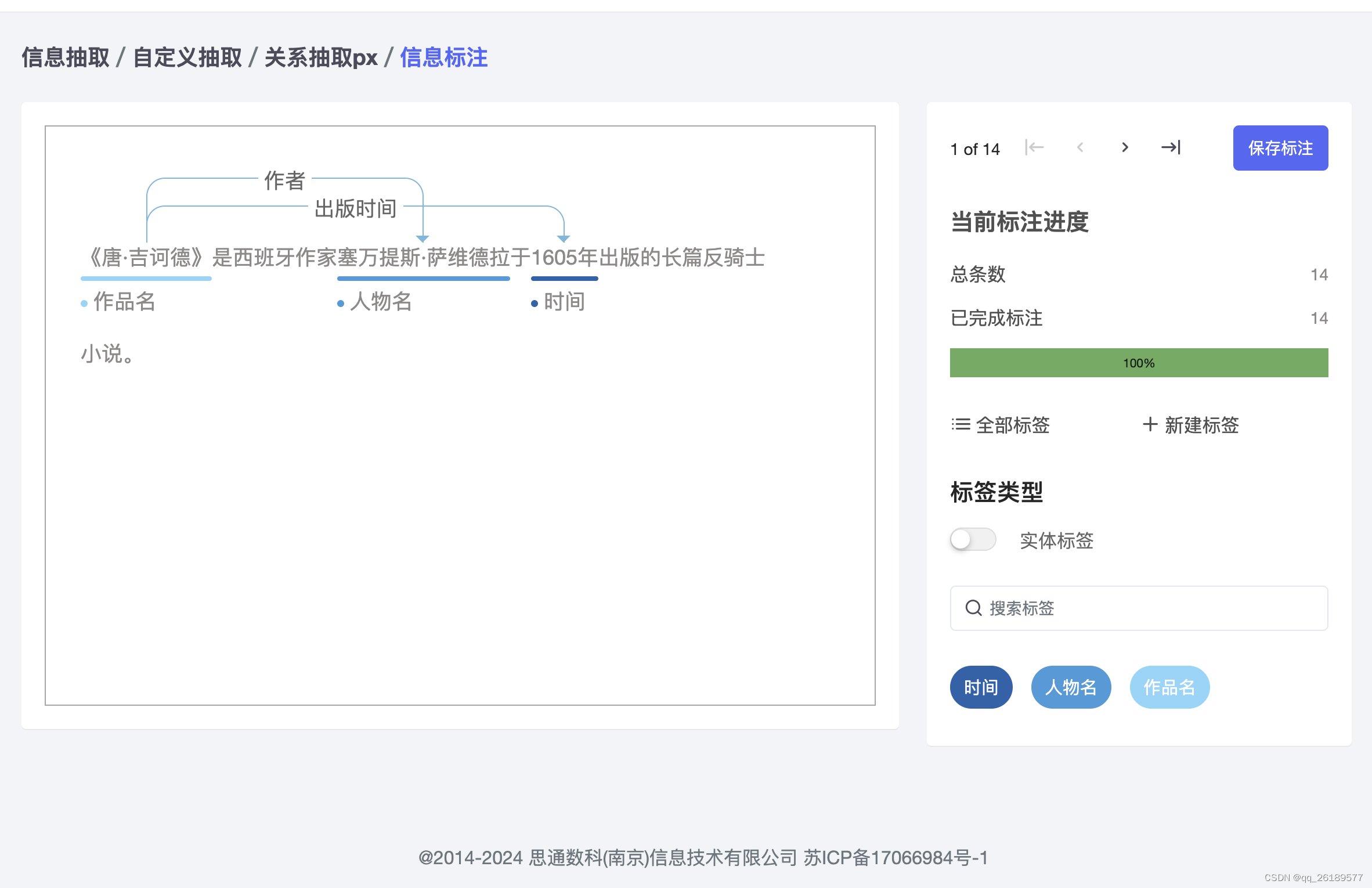
在项目进行中,我们首先利用参数与属性抽取功能,自动识别药品说明书中的数值信息,比如剂量(例如“成人每次服用10毫克”)和时间(例如“每日三次,饭前服用”)。同时,我们还能抽取药品的颜色、形状等属性,这些信息有助于药剂师在配药时快速识别药品。通过自动对应参数和属性之间的关系,我们能够构建出药品的详细档案,极大地提高了工作效率。
我们通过实体抽取技术,识别出说明书中的关键实体,如药品名称、成分、疾病名称等。这些实体的准确识别对于后续的信息整合至关重要。例如,我们能够准确地从说明书中抽取出“阿司匹林”这一药品名称,以及它用于治疗的疾病类型,如“缓解轻度至中度疼痛”。
在项目后期,我们进一步利用关系抽取技术,明确药品与其他实体之间的关系。例如,我们可以识别出“阿司匹林”与“胃溃疡”之间的禁忌关系,这对于医生在开处方时避免不良药物相互作用至关重要。此外,事件抽取技术帮助我们理解药品说明书中描述的临床试验事件,如药品的疗效和副作用发生的时间和条件,这对于药品的安全性评估和患者教育非常有价值。通过这些信息抽取技术的应用,我们不仅提高了信息处理的效率,还确保了信息的准确性和完整性。这对于提升医疗服务质量、保障患者安全以及优化药品管理流程都有着重要的意义。
三、技术实现
在文章中,我将展示如何使用信息抽取技术来辅助药师小张的工作。以下是一个简化的伪代码示例,它描述了如何通过API调用来实现药品信息的自动提取。
# 伪代码示例
import requests
# 替换为你自己的secret-id和secret-key
secret_id = 'your-secret-id'
secret_key = 'your-secret-key'
# 定义API请求函数
def call_extraction_api(text, sch, modelID):
url = "https://nlp.stonedt.com/api/extract"
headers = {
'Content-Type': 'application/json',
'secret-id': secret_id,
'secret-key': secret_key
}
payload = {
"text": text,
"sch": sch,
"modelID": modelID
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
# 假设的药品说明书文本
drug_manual_text = "药品名称:阿莫西林胶囊,适应症:用于治疗由敏感细菌引起的各种感染,剂量:成人常用量一次250-500mg,一日3次,副作用:可能引起过敏反应。"
# 定义抽取范围和模型ID(这些值需要根据实际情况获取)
extraction_scheme = "药品名称,适应症,剂量,副作用"
model_id = 123 # 假设的模型ID
# 调用API并处理结果
result = call_extraction_api(drug_manual_text, extraction_scheme, model_id)
# 输出结果
if result['code'] == '200':
print("信息抽取成功!")
for entity in result['result'][0]:
for item in entity.values():
print(f"实体: {entity}, 内容: {item['text']}, 起始位置: {item['start']}, 结束位置: {item['end']}, 准确率: {item['probability']:.2f}")
else:
print(f"信息抽取失败,错误代码: {result['code']}, 错误信息: {result['msg']}")
# 示例输出
# 实体: 药品名称, 内容: 阿莫西林胶囊, 起始位置: 6, 结束位置: 16, 准确率: 0.99
# 实体: 适应症, 内容: 用于治疗由敏感细菌引起的各种感染, 起始位置: 22, 结束位置: 56, 准确率: 0.95
# 实体: 剂量, 内容: 成人常用量一次250-500mg,一日3次, 起始位置: 62, 结束位置: 92, 准确率: 0.90
# 实体: 副作用, 内容: 可能引起过敏反应, 起始位置: 98, 结束位置: 116, 准确率: 0.85
在上述伪代码中,我们首先定义了一个名为 `call_extraction_api` 的函数,它负责发送POST请求到信息抽取API,并返回JSON格式的响应。然后,我们构造了一个假设的药品说明书文本,并定义了抽取范围和模型ID。调用API后,我们检查返回的 `code` 是否为 `200`,如果是,表示抽取成功,我们遍历结果并打印出每个实体的信息。如果抽取失败,我们打印出错误信息。
这个伪代码示例展示了如何将信息抽取技术应用于实际场景,帮助药师小张快速获取药品的关键信息。通过这种方式,我们能够提高工作效率,减少人为错误,确保药品信息的准确性。
四、项目总结
本项目的核心成果在于实现了药品信息的高效自动化处理,极大地提升了医疗文档处理的效率。通过集成先进的自然语言处理技术,我们为药师小张等医疗专业人员提供了一个强大的工具,使得他们能够在短时间内准确地获取关键医疗信息。这不仅优化了药品管理流程,还显著提高了医疗服务的响应速度和质量。此外,自动化的信息抽取减少了人为因素导致的误差,从而为患者提供了更加安全的用药环境。从经济效益角度来看,项目实施后,医院在药品库存管理上的成本得到了有效控制,同时也提高了整体的运营效率。这些成果不仅为医院带来了直接的效益,也为整个医疗行业在信息管理方面树立了新的标杆。
五、开源项目(可本地化部署,永久免费)
思通数科的多模态AI能力引擎平台是一个企业级解决方案,它结合了自然语言处理、图像识别和语音识别技术,帮助客户自动化处理和分析文本、音视频和图像数据。该平台支持本地化部署,提供自动结构化数据、文档比对、内容审核等功能,旨在提高效率、降低成本,并支持企业构建详细的内容画像。用户可以通过在线接口体验产品,或通过提供的教程视频和文档进行本地部署。平台鼓励社区参与,欢迎用户和开发者提出建议和贡献。成功部署后,用户可以通过默认的登录凭证访问系统。
多模态AI能力引擎平台https://gitee.com/stonedtx/free-nlp-api
思通数科(StoneDT)专注于自然语言处理(NLP)技术,提供多模态AI工具集和解决方案,支持文本、音视频和图像处理。我们的AI能力引擎平台支持本地化部署,旨在自动化处理大量文本数据,提高效率,降低成本。平台功能包括自动结构化数据、文档比对、内容审核、信息抽取等。我们服务于金融、政府和大型企业,拥有多项技术专利,核心团队来自知名企业。客户包括国家邮政总局、国家电网等。我们积累了丰富的算法模型和数据标签,提供灵活的数据分析解决方案,以卓越的数据技术为客户创造价值。公司以客户为中心,构建了以业务场景为核心的服务体系,实现创新业务增长。技术成果广泛应用于政府、金融等领域。
本文转载自: https://blog.csdn.net/qq_26189577/article/details/136261753
版权归原作者 qq_26189577 所有, 如有侵权,请联系我们删除。
版权归原作者 qq_26189577 所有, 如有侵权,请联系我们删除。