
目录
摘要
防抖技术是一种普遍使用的相机辅助技术,其旨在最大程度减少因摄影中的抖动而造成的照片模糊的现象。介绍防抖技术的分类,并简单介绍镜头防抖、机身防抖和电子防抖的工作原理和发展现状。
关键词:光学防抖;机身防抖;电子防抖
自数码相机诞生以来,人们便由传统胶卷相机时代步入了 数码摄影时代。在过去用传统相机若想要拍摄得到清晰的照片,通常方法是使用三脚架或者尽量用高ISO的胶卷并配合高速快门。而数码相机经过多年的技术发展,数码防抖技术已然 能够实施高效地应对因摄影过程中的晃动而导致的影像不清晰的现象,大大降低了渣图的机率。
主要防抖技术
目前防抖技术主要包括:
(1)光学防抖
是指借助移动式硬件机械结构进行光学补偿的防抖技术, 又可细分为镜头防抖和影像传感器防抖。Nikon的VR(Vibra tion Reduction)减震技术,Cannon的IS(Image Stabilizer)影像稳定系统,Sigma的OS(Optical Stabilizer)光学稳定系统,Pana sonic 的O.I.S.光学防抖,Konica Minolta的AS (Anti-Shake)机身防抖等都归属此类。
(2)电子防抖
采用数码影像技术对拍摄图像进行锐化、降噪等处理的防抖技术。比如Sumsung的ASR防抖。
(3)模式防抖
通过优化调整后的相机拍摄参数来补偿抖动对成像影响的防抖技术。包括Olympus的高ISO(如12800)的高感光度模式,Nikon的BSS最佳拍摄选择器,Sanyo的后期补偿计算式防抖等。
(4)多重防抖
多重防抖是综合了以上多种形式的防抖技术,根据实际拍摄情况选择应用一种或多种防抖技术来确保防抖效果。
(5)物理防抖 指的是云台防抖,就是将防抖技术运用在了多轴云台,比如物理的手持云台、sensor上的微云台
首先在两星级难度的公路行驶过程中,由于行驶速度较快,因此开车时出现了的抖动较为频繁。不过下方视频截图来看,除了荣耀20i出现小幅抖动外,其它几款机型都带来了不错的稳定性,整个画面看上去比较顺滑。
手机防抖对比

乡间小道“急刹车”场景下,出现了剧烈震动,这对于手机的防抖要求更高,那么这几款手机又会有怎样的表现呢?可以看到,几款手机所展现的画面抖动幅度都不尽相同,其中荣耀20i、华为 P30 Pro都有明显的震动。相比之下,iPhone11 Pro Max和OPPO Reno2更能经住“考验”,表现相对好很多。

不过这样的测试还不够,网友又将难度进行了升级,将“战场”转移至石子路斗坡。在频繁、激烈的抖动场景下,依旧是iPhone11 Pro Max和OPPO Reno2带来了比较稳定的拍摄画面,不过两者再进行对比来看,后者的表现会更给力一些。

而在“急转弯”测试中,网友开车时本身车子就晃动得非常剧烈,正是在这样的情况之下,几款测试手机完成了最后的六星级难度测试。从下方的视频截图来看,原本表现比较好的iPhone11 Pro Max拍摄的画面也出现了晃动。比较之下,OPPO Reno2的晃动幅度稍微小一些,画面清晰度、质量等比较不错,整体表现更胜一筹。

OPPO Reno2之所以能够带来比较稳定清晰的拍摄画面,主要是因为OPPO这次为其加入了全新的Ultra Steady视频超级防抖技术,通过结合OIS光学防抖和EIS电子防抖,从硬件和软件层面对画面同时进行优化升级,因此能够拍摄出效果更好的画面。
2 镜头防抖
镜头防抖是技术最成熟、应用最广泛的防抖技术。它由镜头内置的运动感应器(陀螺仪)侦测出镜头位移,微处理器由此信号计算出需要补偿的位移量,并驱动补偿镜片组在指定的方向进行位移补正。镜头防抖的补偿角度范围一般在10°~15°以内,适用于弥补因为摄影者的呼吸、心跳或不自觉的身体晃动 所造成的相机抖动。
镜头防抖也被应用于如手机等集成有摄像头模组的便携式移动终端中,不过此时更多时候移动的不是某个镜片而是整个成像透镜组。它通常是由电磁致动器或电机致动器来驱动,可单轴或多轴运动,包括沿光轴方向的轴向移动、垂直于光轴方向的面向移动、与光轴方向成一夹角的摆动。
以电磁致动器驱动的镜头光学防抖为例,摄像头模组的主要部件包括有成像透镜组和由电磁线圈、电磁铁和磁轭构成的电磁驱动机构。电磁线圈、电磁铁和磁轭一般是对等数量但也可以是不对等数量,它们形成的电磁驱动机构可以是一对或者多对,通常是对称布置在成像透镜组的四周或其下方。通过调 整电磁线圈中电流的大小和方向,产生大小和方向可控的电磁作用力,驱动成像透镜组沿预定方向位移。
在成像过程中,因相机“倾角”抖动对成像的影响要比相机 “平动”抖动大得多。“倾角”抖动对成像的影响及其光学防抖原理如图1所示。
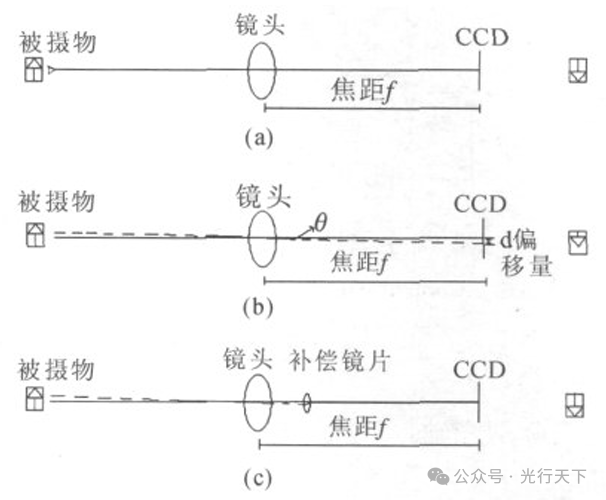
图1.镜头防抖原理图示
图1(a)示意了没有抖动的成像,图1(b)示意了抖动下的成像,容易看出因为“倾角”抖动造成光轴偏转了θ角,成像在CCD上发生了d的偏移量。
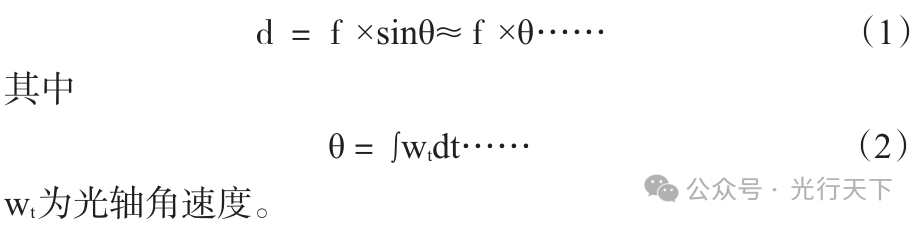
为了减小偏移量d,在镜头光学系统中加入补偿镜片,利用 其光学特性减小光轴偏转角度θ,从而减小偏移量d,其原理图 如图1(c)所示。
光学防抖的控制模型可应用PID控制进行建模。当控制量是恒值时,利用PID算法可以使被控量迅速达到控制量的设定范围内。一般人手持相机时的手抖频率为0~10Hz,基于PID参数建模的控制模型能在极短时间内(小于1/60s)将手抖造成的光轴偏移量减小到预设的位置,从而快速有效地实现光学防抖。
不同厂家的防抖镜头基本原理大同小异,目前多数厂家的防抖镜头可以提升快门速度3~4档,大大提高了出片率。Nikon和Canon的防抖镜头是公认的防抖效果最好,Canon镜头在横向上比Nikon镜头防抖效果略差。
在过去,防抖镜头理论上可以让我们降低2挡快门速度拍摄,随着技术的发展,目前佳能和尼康的防抖镜头已经能保证低于安全快门速度4挡的拍摄,而适马、松下以及腾龙等厂家也都有着自己的镜头防抖系统。Panasonic的防抖镜头有瞬时防抖和全时防抖之分,主要差别在取景和耗电量上。此外还需注意的是,防抖镜头在使用三脚架时不能打开镜头的防抖开关,否则会影响画质。

3 机身防抖
防抖镜头昂贵的价格催生了机身防抖技术。机身防抖(即影像传感器防抖)最早由KonicaMinolta提出,后来Sony收购了KonicaMinolta的相机业务后将其发扬光大并应用于自家的数码单反/无反相机中。影像传感器防抖和镜头防抖在原理和结构上是近似的,只是防抖镜头中动作对象是补偿镜片而在影像传感器防抖中动作对象是影像传感器。其原理是将影像传感器安装在一个可动的运动平台上,根据机身运动感应器反馈的运动信号计算出相应的补偿量,驱动运动平台沿轴向或面向移动进而补偿抖动偏差。目前Ricoh,Pentax,Olympus也拥有了此类技术。
机身防抖比较有代表性的是Pentax开发的SR(OriginalShakeReduction)原始震动减少技术,如图2所示。安装有影像传感器的影像传感器安装板被夹在两块设有电磁驱动机构的磁力板中间,影像传感器安装板能够被电磁力快速沿垂直于光轴方向的平面内快速移动。Pentax的SR防抖效果相当于2.5~4级的快门速度差。需要提醒的是,在使用三脚架拍摄时要关闭SR功能。
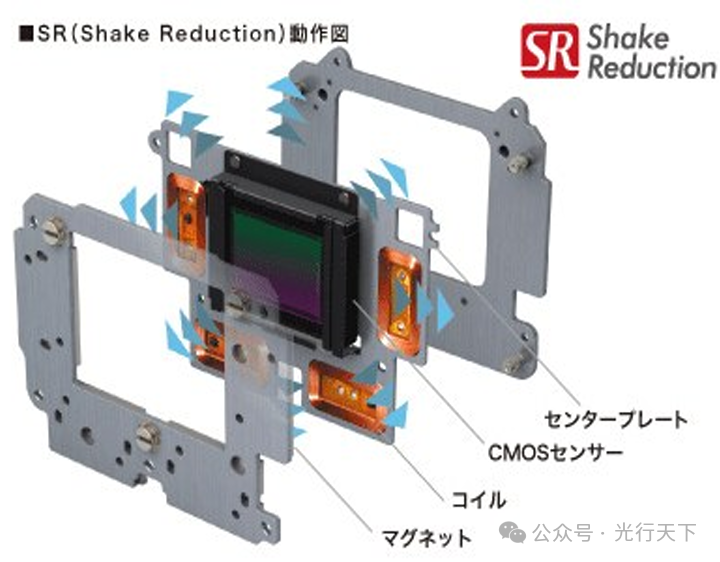
图2.Pentax SR防抖系统
影像传感器防抖也属于光学防抖,它相比防抖镜头来说成本更低,而且也能提供不比镜片移动式防抖差的防抖效果。而且因为防抖机构安装在机身内部,理论上连接不带有防抖功能的镜头也能实现防抖效果,故其兼容性更佳。影像传感器防抖的缺点是在实时取景时无法预览防抖效果,另外要注意的是,如果相机机身已有防抖功能,搭载防抖镜头使用时需要匹配,否则可能会因为两套防抖系统不相协调而造成工作紊乱,反而适得其反。
4 电子防抖
有些便携式数码相机其机身内并无搭载硬件防抖机构,却能在一定程度上修正抖动图像,其实际应用了电子防抖技术,这种防抖技术据说可以让快门速度提高1.5~2档。电子防抖是利用数字图像处理技术对抖动图像进行后期优化从而尽可能地还原出原始清晰图像。另一种是逆向运算法,通过相机内置的运动感应器侦测出相机震动的方向,针对影像传感器的一部分面积进行分析并且通过逆向运算将模糊图像去掉。然而电子防抖在使用上有时反而会使噪点增多或者修图痕迹太过而不能起到真正的防抖作用,究其根本是因为它是对抖动图像的后期补偿,治标不治本,对原始图像的画质有较大影响,而且其防抖效果主要取决于算法的优化程度,算法复杂度较高。电子防抖因其硬件开销小不增加成本,主要应用于消费机DC中。
5 小结
本文对相机的主要防抖技术和工作原理进行了介绍,防抖相关的各个部份只举了少量实例,无法全面涵盖更详细的防抖技术。防抖的根本思想是在摄影中使相机尽可能地稳定,减小晃动。为了更好的拍摄画面质量,相机的防抖研究正在不断地突破着现有技术,向着更高清晰度发展。
本文来自网络文档,仅为传播技术知识之用,若有不妥,敬请告之。

某拇指相机技术分析:
防抖 技术的产品需求文档与研发方案
1.基础介绍
某GO3拇指相机产品与防抖技术关系概述本产品是一款基于6轴IMU(惯性测量单元)防抖技术的图像稳定装置,旨在为消费级影像爱好者和专业摄影师在户外拍摄、运动摄影等使用场景下提供更加稳定的拍摄环境,以实现高质量的图像和视频录制。
2. 功能需求
2.1 功能背景
由于在用户在使用相机时,手持或挂载在身上,会产生中低频率以及中高振幅的抖动,这样拍摄的画面很可能出现运动拖影以及边缘虚化,录制的视频会产生较大抖动,使得视频观感较差,这对用户体验较差,通过对用户与市场调研,受众普遍对防抖效果较优异的产品与更高的购买意愿和更享受的使用体验。
2.2 技术背景与技术选型
在防抖技术发展中,简要经过了数字防抖、IMU防抖、机械防抖、光学防抖、AI+防抖等方案,根据多帧图像并估计关键点,实现关键特征点的配准与抖动偏移估计,再使用仿射变换等技术矫正图像以及裁切或补黑边,如GME 6DOF 数字防抖,这样的方式由于在运动时,特征配准不齐且存在数据扰动,画面可能会拖拽感,防抖效果不佳等问题;IMU防抖的成本相对较低,效果较好,但可能需要缜密的防抖算法逻辑并结合较多的姿态估计、pid、纠偏等参数调试,并且通常需要裁切20%以上的画面来切除因图像矫正带来的黑边;机械防抖即通过外置云台或在相机中搭载微型云台实现的,即在sensor外,在相机挂载的云台上内置imu来实现防抖,这就相较于前面所说的sensor imu防抖有更早的优势,防止早期semsor卷帘曝光与物体运动带来的果冻效应与高速运动的画面模糊;光学防抖目前在手机的高端产品上应用,成本较高,需要在sensor外实现一套伺服防抖电机系统,在拇指大的sensor边上搭载xy两轴的运动电机(3轴可能会影响焦点等),电机根据imu数据与姿态估计和纠偏算法,来控制sensor的运动来实现防抖,这种方式高精密,效果接近机械防抖,且占地空间很小;AI+防抖是指纯AI深度学习防抖:使用高维特征来学习多帧间的光流配准,并结合纠偏网络来矫正图像,这样的方式端到端,可惜的是目前效果很有限,且算力需要很大,分辨率越大,计算难度越大,所以一般是使用AI来完成姿态估计或纠偏等部分,其余部分会结合imu数据共同实现。于是本需求分析中以6轴imu防抖为重点技术方案,来实现稳定可靠高效的防抖效果。以下面向算法研发等团队提供技术方案参考。

2.3 技术方案
技术方案中,我们首先通过硬件调研与选型,选择出几款高精度的imu,如icm-40608、icm-42670、icm20608等陀螺仪芯片,这几款的imu有以下优势:性价比高,量程较大,零偏误差较小,imu的精度较高,温度偏移较小,比较适合运动相机;接着会安排硬件同事根据规格书进行imu 与pcb设计和焊接,请注意电路与磁场对imu的干扰,如有必要,可以通过隔断桥梁阻隔干扰信号;然后需要imu驱动同事按照规格书和供应商提供的驱动配置,驱动成功imu,并在主板中加载外围驱动,并设置好陀螺仪电路低通滤波、陀螺仪采样频率以及与主板的时间同步,并在imu通讯正常后,联合算法同事初步在静止场景通过仿真软件测试imu数据波形是否正常且未受电路等影响。然后做相机标定获取相机的内外参数和畸变系数以及相机坐标系旋转矩阵,完成在线与离线零飘、温漂标定与参数记忆和在线标定更新功能。
算法同事根据陀螺仪四元树数据或旋转姿态数据和相机参数,并根据多帧间数据滤波,如在各轴数据中应用低通滤波,免除高频噪声等影响,并使用基于协方差矩阵的卡尔曼滤波递归估计姿态、使用互补滤波来融合不同传感器的数据,如加速度计和地磁计和陀螺仪数据,从加速度计等数据计算相机倾角、从陀螺仪积分角速度得到角度,计算出姿态和偏移,应用于图像中;在流媒体节点的vpss前(即做完大部分isp后),将数据以流水线逐行纠偏方式快速的完成图像防抖的纠偏,然后根据用户选定的分辨率裁切图像输出;其中sensor分辨率为12MP,高于防抖后的输出2.7K视频分辨率,根据防抖的姿态估计,使用流水线逐行进行逆变换或仿射变换来矫正图像,裁切掉黑边以及用户选定分辨率以外的图像;
根据用户选择的输出分辨率(供自由分辨率),新建或启用vpss的新group,将防抖后的图进行输出或做其他osd等处理,之后将图像进行venc输出。我们将在GO3中搭载固定尺寸、自由尺寸的防抖模式,并且可以提供用户选择防抖效果与强度为:极致防抖、高级防抖、中级防抖等模式,并提供用户实时防抖和后期软件防抖模式。在用户的使用过程中,我们整个防抖算法在硬件数据、软件算法等维度实时监测相机姿态和运动,进行实时调整以保持画面稳定,达到产品的防抖需求。由于防抖算法的imu防抖是开发一个需要长期调优的过程,不过算法的初版、硬件初步定板,这个阶段的开发周期不会太长,当第一个周期完成后,将得到一款初步拥有初级防抖效果的版本,其次再根据防抖效果进行进一步调优。优化高振幅和高振频的防抖效果:这需要选购精密的振动台,并反复将算法与参数在选定的振动台上进行3轴实验与调优,在极致防抖模式下,我们可能需要做更多防抖裁切,在高振幅下还需要另一套滤波器等参数来进行防抖,而非初级防抖模式中,应对大抖动会选择减弱防抖强度来减弱画面拖拽感。
防抖算法防抖技术有着与业界常规防抖相比显著的亮点,在GO3 相机中,可供裁切的像素更多,但由于广角相机的畸变较大,除了需要更高精度的畸变标定外,防抖团队也有着算法上更多的大像素防抖适配逻辑,甚至可以使用亚像素防抖或补像素防抖的方式来实现不裁切更多像素实现优异的防抖效果。其余的防抖亮点还有优异的跟手性,通过防抖算法防抖算法,智能区分用户抖动与用户主动移动,智能调节防抖效果和强度;防抖算法还通过每一帧的IMU数据,可以估计出曝光每一行在扫描时的运动情况,然后对图像进行反向校正。这种方法需要防抖算法缜密的计算,在卷帘曝光带来的果冻效应问题中非常有效。防抖算法智能适配了不同的防抖场景,从低频到高频,从低振幅到高振幅都有优异的防抖效果,这使得用户在手握摄影、跑步、骑行、滑雪等各种抖动场景都能稳如泰山。
2.4 可行性落地链路
当GO 3 拇指相机搭载了防抖算法防抖技术后,产品拥有了防抖能力,接下来需要做生产链路的搭建和规范化,简要有以下工作要做:首先需要生产团队根据规范焊接imu等硬件,并根据仿真软件来检查imu波动是否在250dps,加速度计偏差是否在300mg下,确认好零偏,然后每款相机imu在工作温度做温漂标定与校准工作,确保设备在-20°-60°的工作范围内的imu数据准确与稳定(当系统团队做好缺省参数或在线温漂记忆与离线温漂与加载等逻辑后可以不需要生产团队对每颗出厂imu都初始化校准);
应用防抖算法并使用仿真软件进行检查每颗相机的防抖效果,对有小部分异常的相机反馈给项目经理。将IMU防抖技术从设计到落地到实际产品,需要进行硬件设计与开发、软件开发、算法开发、生产制造等工作。其中包括选择合适的传感器和相机模块、设计电路和接口、编写驱动程序和应用软件、设计防抖算法、优化算法性能和功耗、校准传感器、进行系统调试与验证等。最后,进行产品原型设计与测试、大规模生产准备、质量控制,以及市场推广与售后支持等环节。我们除了GO3还拥有多款成功的产品,同时还拥有优异的算法、产品、研发、生产、销售等团队,我们针对以上的技术与链路有专家宏观把控风险和技术指导,有优秀的算法工程师来实现和调优,对以上链路的开发可信性较高。
2.5 竞品调研与市场分析
本章节我们将针对flowstate技术和GO3相机进行友商竞品调研与市场分析;主要从产品定义、功能定义与使用、防抖效果与场景定义、市场反馈与体验测试等来反馈给研发团队,共同优化一版又一版的产品与算法。以下为初步调研:iPhone 14 Pro Max等高端机型配备了先进的Sensor-Shift OIS技术,提供极其稳定的视频和照片拍摄能力。三星Galaxy S23 Ultra使用双OIS系统,对高频和低频抖动都有很好的抑制效果。谷歌Pixel 7系列通过强大的EIS和AI算法,提供卓越的视频防抖效果。华为 P50 Pro采用AIS Pro(即AI稳定系统)结合OIS,特别是在夜景拍摄中表现突出。小米 小米12 Pro配备了新的CyberFocus技术和OIS,能提供稳定的成像质量。GoPro Hero系列(如Hero 11 Black)使用HyperSmooth 4.0技术,这是一种先进的EIS系统,能够在各种运动环境下提供卓越的防抖效果。GoPro还提供了Boost模式,可以在极端运动情况下提供更强的稳定性。DJI Osmo Action 3 配备了一种名为RockSteady的EIS技术,能够在高速运动中提供平稳的视频输出。DJI Action 2 进一步提升了RockSteady 2.0,结合了HorizonSteady水平维持功能,使拍摄更加平滑。Insta360 One R和One X2等产品采用FlowState稳定技术,通过6轴陀螺仪和先进的EIS技术,提供360度全方位的稳定效果。
在后期处理软件中,用户可以进一步优化防抖效果。Sony的FDR-X3000R等运动相机采用B.O.SS(Balanced Optical SteadyShot)技术,这是一种基于镜头组和传感器同步移动的光学防抖技术,效果非常显著用户反馈:GoPro和DJI在运动相机市场的用户反馈均非常积极,特别是在防抖效果方面,GoPro的HyperSmooth和DJI的RockSteady都得到了用户的高度评价。耐用性和适应性:运动相机需要在各种极限环境下使用,防抖效果在这些环境中的表现也至关重要。大多数用户认为GoPro和Insta360的防抖效果最为出色,特别是在快速移动和振动剧烈的场景中。市场份额:GoPro仍然是运动相机市场的领导者,其占据了较大的市场份额。DJI和Insta360紧随其后,尤其是在专业领域和特定应用场景中表现强劲。消费者偏好:消费者在选择运动相机时,防抖效果是一个重要考虑因素。许多专业用户和极限运动爱好者更倾向于选择具有优秀防抖技术的品牌和型号。我们GO3 拇指相机主打的是360°防抖、高分辨率防抖、大振幅抖动防抖、高画质与高帧率输出,以及优质的用户使用体验:智能的防抖,既能防住大振幅抖动,又能智能的在用户移动时不拖拽画面,有优异的跟手性,AI与防抖结合:运动相机防抖技术可能更多地依赖AI算法,通过实时学习和自适应调整,提高防抖效果。
2.6 防抖主客观评价
防抖的评价分为主客观评价,同时在客观评价的过程中,由于友商的防抖功能保密,所以我们需要基于通用防抖评价指标进行客观评价,同时也可以在震动台同步测试。 客观评价。对硬件评价有:零偏误差±0.5°/s,零偏稳定性3°/h, 灵敏度误差 max 3%,温漂0.0005%°C,噪声密度0.0028%sHZ,噪声0.028%s-rms加速度计误差200mg
下面给个demo ,python帧差法数字防抖,后续AI防抖和imu防抖,再继续提供给大家,感谢三连关注收藏,即将更新更多AI、AI计算摄影、AI isp和成像算法;

源码实现运动防抖
我们将采用基于帧差的方法来实现视频去抖动。基本思路是对视频的连续帧进行比较,找出相邻帧之间的差异,并将这些差异用于平滑化画面。
步骤:
- 读取视频文件;
- 逐帧处理视频,计算相邻帧之间的差异;
- 将差异应用于原始帧,以实现去抖动效果;
- 输出处理后的视频。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import
cv2
def
stabilize_video(input_file, output_file):
# 打开视频文件
cap
=
cv2.VideoCapture(input_file)
# 获取视频帧率和尺寸
fps
=
int
(cap.get(cv2.CAP_PROP_FPS))
width
=
int
(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height
=
int
(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 创建 VideoWriter 对象,用于保存处理后的视频
fourcc
=
cv2.VideoWriter_fourcc(
*
'XVID'
)
out
=
cv2.VideoWriter(output_file, fourcc, fps, (width, height))
# 读取第一帧
ret, prev_frame
=
cap.read()
if
not
ret:
return
# 处理视频帧
while
True
:
ret, frame
=
cap.read()
if
not
ret:
break
# 计算相邻帧之间的差异
diff
=
cv2.absdiff(prev_frame, frame)
# 将差异应用于原始帧,平滑画面
stabilized_frame
=
cv2.subtract(frame, diff)
# 写入输出视频文件
out.write(stabilized_frame)
# 更新上一帧
prev_frame
=
frame
# 释放 VideoCapture 和 VideoWriter 对象
cap.release()
out.release()
cv2.destroyAllWindows()
# 调用函数进行视频去抖动处理
input_file
=
'input_video.mp4'
output_file
=
'stabilized_video.avi'
stabilize_video(input_file, output_file)
性能优化与改进
虽然上述方法可以简单地实现视频去抖动,但是在处理大型视频文件时可能存在一些性能问题。为了改进和优化算法,我们可以考虑以下几点:
- 多帧差分:不仅仅使用相邻帧之间的差异,还可以考虑使用多帧之间的差异来平滑画面。这样可以更好地消除不同帧之间的抖动。
- 运动估计:使用光流算法等方法估计帧与帧之间的运动,然后根据运动信息对帧进行校正。这种方法可以更精确地处理抖动,并且适用于更复杂的场景。
- 并行处理:利用多线程或者并行处理的技术,可以加快视频处理的速度,提高程序的性能。
- 参数调优:调整算法中的参数,如帧差阈值、平滑系数等,可以进一步提高视频去抖动的效果。
代码改进
下面是一个改进后的代码示例,使用多帧差分和运动估计的方法来实现视频去抖动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import
cv2
def
stabilize_video(input_file, output_file):
cap
=
cv2.VideoCapture(input_file)
fps
=
int
(cap.get(cv2.CAP_PROP_FPS))
width
=
int
(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height
=
int
(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
num_frames
=
int
(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc
=
cv2.VideoWriter_fourcc(
*
'XVID'
)
out
=
cv2.VideoWriter(output_file, fourcc, fps, (width, height))
prev_frame
=
None
for
_
in
range
(num_frames):
ret, frame
=
cap.read()
if
not
ret:
break
if
prev_frame
is
None
:
prev_frame
=
frame
continue
# 多帧差分
diff
=
cv2.absdiff(prev_frame, frame)
# 运动估计
flow
=
cv2.calcOpticalFlowFarneback(prev_frame, frame,
None
,
0.5
,
3
,
15
,
3
,
5
,
1.2
,
0
)
flow
=
flow.astype(
'int32'
)
flow
=
-
flow
stabilized_frame
=
cv2.remap(frame, flow[:,:,
0
], flow[:,:,
1
], cv2.INTER_LINEAR)
out.write(stabilized_frame)
prev_frame
=
frame
cap.release()
out.release()
cv2.destroyAllWindows()
input_file
=
'input_video.mp4'
output_file
=
'stabilized_video.avi'
stabilize_video(input_file, output_file)
进一步改进与应用
除了以上提到的改进方法外,还有一些其他的技术和思路可以进一步提高视频去抖动的效果和应用:
- 深度学习方法:利用深度学习模型,如卷积神经网络(CNN)或循环神经网络(RNN),对视频进行学习和预测,从而实现更加精细的视频去抖动效果。
- 自适应参数调整:根据视频的内容和特点,动态调整算法中的参数,以适应不同场景下的视频去抖动需求。
- 实时处理:将视频去抖动算法应用于实时视频流中,例如实时监控系统或视频通话应用中,提高用户体验。
- 结合其他技术:将视频去抖动与其他视频处理技术相结合,如视频稳定、视频降噪等,以进一步提高视频质量。
- 应用于特定场景:针对特定应用场景,如运动摄影、无人机航拍等,优化和定制视频去抖动算法,以满足特定需求。
深度学习方法示例
下面是一个简单的示例,演示如何利用深度学习模型(这里使用的是预训练的深度学习模型)来实现视频去抖动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import
cv2
import
numpy as np
from
tensorflow.keras.applications
import
VGG16
def
stabilize_video_deep_learning(input_file, output_file):
# 加载预训练的VGG16模型
model
=
VGG16(weights
=
'imagenet'
, include_top
=
False
)
cap
=
cv2.VideoCapture(input_file)
fps
=
int
(cap.get(cv2.CAP_PROP_FPS))
width
=
int
(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height
=
int
(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
num_frames
=
int
(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc
=
cv2.VideoWriter_fourcc(
*
'XVID'
)
out
=
cv2.VideoWriter(output_file, fourcc, fps, (width, height))
prev_frame
=
None
for
_
in
range
(num_frames):
ret, frame
=
cap.read()
if
not
ret:
break
if
prev_frame
is
None
:
prev_frame
=
frame
continue
# 利用VGG16模型提取特征
prev_features
=
model.predict(np.expand_dims(prev_frame, axis
=
0
))
curr_features
=
model.predict(np.expand_dims(frame, axis
=
0
))
# 计算特征差异
diff
=
np.
abs
(prev_features
-
curr_features)
# 根据特征差异对帧进行校正
stabilized_frame
=
cv2.subtract(frame, diff)
out.write(stabilized_frame)
prev_frame
=
frame
cap.release()
out.release()
cv2.destroyAllWindows()
input_file
=
'input_video.mp4'
output_file
=
'stabilized_video_dl.avi'
stabilize_video_deep_learning(input_file, output_file)
实时处理与应用示例
在某些场景下,需要对实时生成的视频进行即时的去抖动处理,比如视频通话或实时监控系统。下面是一个简单的示例,演示如何利用多线程技术实现实时视频去抖动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
import
cv2
import
numpy as np
import
threading
class
VideoStabilizer:
def
__init__(
self
, input_file, output_file):
self
.cap
=
cv2.VideoCapture(input_file)
self
.fps
=
int
(
self
.cap.get(cv2.CAP_PROP_FPS))
self
.width
=
int
(
self
.cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self
.height
=
int
(
self
.cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self
.out
=
cv2.VideoWriter(output_file, cv2.VideoWriter_fourcc(
*
'XVID'
),
self
.fps, (
self
.width,
self
.height))
self
.prev_frame
=
None
self
.lock
=
threading.Lock()
def
stabilize_frame(
self
, frame):
if
self
.prev_frame
is
None
:
self
.prev_frame
=
frame
return
frame
# 多帧差分
diff
=
cv2.absdiff(
self
.prev_frame, frame)
# 运动估计
flow
=
cv2.calcOpticalFlowFarneback(
self
.prev_frame, frame,
None
,
0.5
,
3
,
15
,
3
,
5
,
1.2
,
0
)
flow
=
flow.astype(
'int32'
)
flow
=
-
flow
stabilized_frame
=
cv2.remap(frame, flow[:,:,
0
], flow[:,:,
1
], cv2.INTER_LINEAR)
self
.prev_frame
=
frame
return
stabilized_frame
def
process_video(
self
):
while
True
:
ret, frame
=
self
.cap.read()
if
not
ret:
break
stabilized_frame
=
self
.stabilize_frame(frame)
with
self
.lock:
self
.out.write(stabilized_frame)
def
start(
self
):
video_thread
=
threading.Thread(target
=
self
.process_video)
video_thread.start()
video_thread.join()
self
.cap.release()
self
.out.release()
cv2.destroyAllWindows()
input_file
=
'input_video.mp4'
output_file
=
'realtime_stabilized_video.avi'
stabilizer
=
VideoStabilizer(input_file, output_file)
stabilizer.start()
在这个示例中,我们创建了一个 VideoStabilizer 类,它负责从输入视频中读取帧,并在多线程中实时进行视频去抖动处理。每个帧都会通过 stabilize_frame 方法来进行处理,然后写入输出视频文件。使用多线程技术可以确保视频处理不会阻塞主线程,从而实现实时处理的效果。
除了实时处理之外,我们还可以将视频去抖动技术应用于特定的场景和应用中。
运动摄影
在运动摄影中,如自行车运动、滑雪等,摄像机通常会受到振动和晃动的影响,导致视频画面不稳定。通过应用视频去抖动技术,可以改善视频的观感,使得观众能够更清晰地观察到运动者的动作和技巧。
无人机航拍
无人机航拍视频通常受到风力和飞行姿态变化的影响,导致画面抖动。通过视频去抖动技术,可以提高航拍视频的质量,使得画面更加平稳、清晰,从而提升用户体验。
摄像头防抖设备
一些摄像头防抖设备也可以使用视频去抖动技术来实现。这些设备通常会通过传感器或者陀螺仪来检测和补偿设备的晃动和振动,从而实现视频的稳定输出。
另一个值得关注的方面是应用视频去抖动技术的挑战和限制。
计算资源需求
一些视频去抖动算法需要大量的计算资源,特别是针对高分辨率或高帧率的视频。这可能导致处理速度慢或者需要高性能的硬件设备。
复杂场景处理
在复杂的场景中,如背景变化剧烈、运动速度快的情况下,传统的视频去抖动算法可能效果不佳。这可能需要更复杂的算法或者结合其他技术来解决。
参数调整和优化
视频去抖动算法通常具有许多参数需要调整和优化,以适应不同的视频场景和质量要求。这需要耗费大量的时间和精力进行参数调试和优化。
下面是一个使用深度学习模型进行视频去抖动的代码案例。我们将使用预训练的深度学习模型来学习视频帧之间的运动,并根据学习到的信息对视频进行稳定处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import
cv2
import
numpy as np
from
tensorflow.keras.applications
import
VGG16
def
stabilize_video_deep_learning(input_file, output_file):
# 加载预训练的VGG16模型
model
=
VGG16(weights
=
'imagenet'
, include_top
=
False
)
cap
=
cv2.VideoCapture(input_file)
fps
=
int
(cap.get(cv2.CAP_PROP_FPS))
width
=
int
(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height
=
int
(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
num_frames
=
int
(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc
=
cv2.VideoWriter_fourcc(
*
'XVID'
)
out
=
cv2.VideoWriter(output_file, fourcc, fps, (width, height))
prev_frame
=
None
for
_
in
range
(num_frames):
ret, frame
=
cap.read()
if
not
ret:
break
if
prev_frame
is
None
:
prev_frame
=
frame
continue
# 利用VGG16模型提取特征
prev_features
=
model.predict(np.expand_dims(prev_frame, axis
=
0
))
curr_features
=
model.predict(np.expand_dims(frame, axis
=
0
))
# 计算特征差异
diff
=
np.
abs
(prev_features
-
curr_features)
# 根据特征差异对帧进行校正
stabilized_frame
=
cv2.subtract(frame, diff)
out.write(stabilized_frame)
prev_frame
=
frame
cap.release()
out.release()
cv2.destroyAllWindows()
input_file
=
'input_video.mp4'
output_file
=
'stabilized_video_dl.avi'
stabilize_video_deep_learning(input_file, output_file)
在这个示例中,我们使用了预训练的 VGG16 模型来提取视频帧的特征,并计算帧与帧之间的特征差异。然后,根据特征差异对帧进行校正,从而实现视频的稳定处理。这种基于深度学习的方法可以更准确地处理视频去抖动,并适用于各种不同的场景和应用需求。
实时处理需求
在某些应用中,需要对实时生成的视频进行即时的去抖动处理。这对计算资源和算法效率提出了更高的要求,需要针对实时处理进行专门的优化和改进。
误差累积
一些视频去抖动算法可能会引入误差累积的问题,特别是在长时间的视频处理过程中。这可能会导致最终的稳定效果不佳或者画面出现畸变。
了解这些挑战和限制可以帮助我们更好地选择合适的视频去抖动算法和方法,并在实际应用中做出适当的调整和优化,以达到最佳的效果。
针对这些挑战和限制,我们可以采取一些策略和方法来应对:
并行和分布式处理
利用多线程、多进程或者分布式计算技术,可以加速视频去抖动算法的处理速度,提高计算效率。这样可以更快地处理大规模的视频数据,同时减少处理时间和资源消耗。
算法优化和改进
持续优化和改进视频去抖动算法,针对不同的场景和应用需求进行适当的调整和改进。例如,结合深度学习技术、增加自适应参数调整、优化运动估计算法等,以提高算法的准确性和效率。
实时处理优化
针对实时处理需求,对算法进行专门的优化和改进,以保证实时性和响应性。可以采用流式处理技术、缓冲区管理、实时调整参数等方法,以满足实时处理的要求。
下面是一个基于 OpenCV 库的简单视频去抖动的代码案例,使用了帧差法来处理视频中的抖动:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import
cv2
def
stabilize_video(input_file, output_file):
cap
=
cv2.VideoCapture(input_file)
fps
=
int
(cap.get(cv2.CAP_PROP_FPS))
width
=
int
(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height
=
int
(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 创建 VideoWriter 对象,用于保存处理后的视频
fourcc
=
cv2.VideoWriter_fourcc(
*
'XVID'
)
out
=
cv2.VideoWriter(output_file, fourcc, fps, (width, height))
# 读取第一帧
ret, prev_frame
=
cap.read()
if
not
ret:
return
# 处理视频帧
while
True
:
ret, frame
=
cap.read()
if
not
ret:
break
# 计算相邻帧之间的差异
diff
=
cv2.absdiff(prev_frame, frame)
# 将差异应用于原始帧,平滑画面
stabilized_frame
=
cv2.subtract(frame, diff)
# 写入输出视频文件
out.write(stabilized_frame)
# 更新上一帧
prev_frame
=
frame
# 释放 VideoCapture 和 VideoWriter 对象
cap.release()
out.release()
cv2.destroyAllWindows()
# 调用函数进行视频去抖动处理
input_file
=
'input_video.mp4'
output_file
=
'stabilized_video.avi'
stabilize_video(input_file, output_file)
在这个示例中,我们使用了 OpenCV 库来读取视频文件,并逐帧处理视频,通过计算相邻帧之间的差异来进行视频去抖动。最后,将处理后的帧写入输出视频文件中。这个简单的代码示例演示了如何使用 Python 和 OpenCV 库实现视频去抖动的基本方法。
高性能硬件支持
利用高性能的硬件设备,如GPU加速、专用的视频处理芯片等,可以提高视频去抖动算法的处理速度和效率。这样可以更快地处理大规模视频数据,同时减少计算资源的消耗。
实验和评估
进行实验和评估,对不同的视频去抖动算法和方法进行比较和评估,选择最适合特定场景和需求的算法。通过实验和评估,可以找到最佳的算法和参数组合,以达到最佳的效果。
综合利用这些策略和方法,可以更好地应对视频去抖动技术面临的挑战和限制,从而实现更高效、更可靠的视频去抖动处理。

总结
视频去抖动技术在当今数字视频处理领域扮演着重要角色,它可以有效地减少视频中由相机振动或手持拍摄等原因引起的画面抖动,从而提高视频的质量和观赏性。本文介绍了如何利用Python和OpenCV库实现视频去抖动的方法,并提供了多种技术和方法的示例。我们从基本的帧差法到更复杂的运动估计和深度学习方法,介绍了不同的实现思路和应用场景。此外,我们还讨论了视频去抖动技术面临的挑战和限制,并提出了一些应对策略和方法。通过不断优化和改进算法,结合高性能硬件支持和实时处理优化,可以实现更高效、更可靠的视频去抖动处理,满足不同场景和应用的需求。视频去抖动技术的发展和应用将进一步推动数字视频处理技术的发展,为用户提供更优质的视频体验。
给个demo ,python帧差法数字防抖,后续AI防抖和imu防抖,再继续提供给大家,感谢三连关注收藏,即将更新更多AI、AI计算摄影、AI isp和成像算法;关注cv君,一起变强,有任何疑问,可以咨询cv君,私信或微信:zxx15277368495z
版权归原作者 cv君 所有, 如有侵权,请联系我们删除。