
图像超分辨率(SR)是一种低层次的计算机视觉问题,其目标是从低分辨率观测中恢复出高分辨率图像。近年来,基于深度卷积神经网络(CNN)的SR方法取得了显著的成功,CNN模型的性能不断增长。近年来,一些方法开始将注意机制集成到SR模型中,如频道注意和空间注意。注意力机制的引入通过增强静态cnn的表示能力,极大地提高了这些网络的性能。
现有研究表明,注意机制在高绩效超划分模型中非常重要。但是很少有研究真正讨论“注意力为什么起作用以及它是如何起作用的”。
今天要介绍的论文试图量化和可视化静态注意力机制,并表明并非所有的注意模块都是有益的。[1]为高精度SR图像提出了注意网络(attention network, A2N)中的注意力。具体来说,A2N由非注意力分支和耦合注意力分支组成。
[1]提出dropout模块(ADM)为两个分支生成动态权值,用于抑制不重要的参数。这使得注意力模块可以更多地关注有益的例子而不受其他惩罚,因此可以通过少量的附加参数来增加注意力模型的容量。
动机
给定输入特征,注意力机制将预测热点图。例如,通道注意将生成1D注意力地图;空间注意力将生成2D注意力地图;频道——空间注意力将生成3D注意力地图。自然而然地,我们问了两个问题:
- 图像的每个部分的注意力因素是高还是低?
- 注意力机制是否总是有利于SR模式?
为了回答上面提到的第一个问题,[1]使用了10个注意模块组成的网络,每个模块都使用了通道和空间注意层,所以每个像素都有一个独立的系数。

注意力热点图:由于空间有限,我们选择了几个具有代表性的块,每一栏分别表示第一、第三、第六、第十注意块。第一行:平均输入特征图。第二行:平均输出特征图。第三行:平均注意力地图。对于前两行,特征中的白色区域表示零值,红色区域表示正值,蓝色区域表示负值。对于注意图(第三行),颜色越亮表示系数越高。来源[1]
上图为某些特征与注意图的视觉效果,上表为注意图与高通滤波的相关系数。虽然这种测量方法不能准确测量注意反应,但其目的是量化不同层次之间的相对高通相关性。

每个注意块的注意图与相应特征图的高通滤波器输出特征之间的相关系数。
从上图和上表中可以看出,不同层次学习到的注意力差异很大。例如,模块1和模块10的反应是完全相反的,即低水平注意模块倾向于低频模式,高水平注意模块倾向于高频模式,中间注意模块的反应是混合的。
基于以上发现,[1]提出尽量减少注意力的使用,同时尽量减少附加参数的数量。一个直观的想法是:只将注意力层放在性能关键层中。然而,上述分析并不是衡量注意层有效性的有效解决方案。
为了定量衡量注意层的有效性,[1]提出了注意dropout框架。他们通过关闭特定的注意层进行了一系列的对比实验,结果如下表所示。
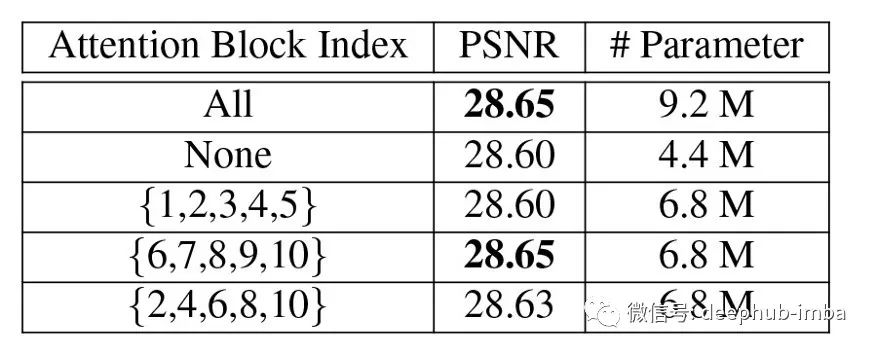
从上表可以看出,模块的深度对注意模块的插入位置影响很大。该结果进一步验证了在整个网络中均匀设置注意力是一种次优解决方案。
方法
一种固定的注意力层方案(如RCAN、PANet)被用来同时激活所有的与图像内容无关注意力地图。以上实验表明,注意层的有效性会随着位置的变化而变化。这启发了[1]构造一个非注意短连接分支和一个注意分支,并将它们与动态权重混合在一起。
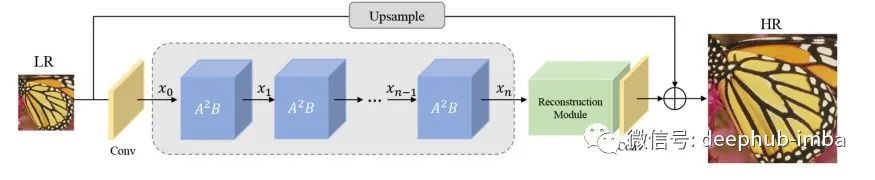
如图所示,网络架构由三部分组成:
- 浅层的特征提取
- 注意块深度特征提取中的注意力
- 图像重建模块。
输入和输出图像分别表示为ILR和ISR。
在浅层特征提取模块中使用单一的卷积层。然后他们就可以阐明
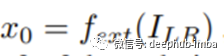
其中fext(·)是内核大小为3×3的卷积层,从输入LR图像ILR中提取浅层特征,x0是提取的特征图。他们利用A2B构造了一个链子网络作为深度特征提取器。
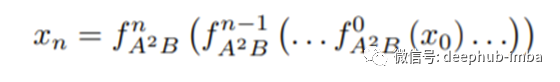
其中,fA2B(·)表示我们在注意块中的建议。A2B将无注意力的分支和注意力分支结合起来并动态调整权重。
在深度特征提取后,通过重构模块对深度特征xn进行升级。在重构模块中,首先使用最近邻插值进行上采样,然后在两个卷积层之间使用一个简化的通道-空间注意层。
他们受到动态内核的启发,提出了一个可学习的ADM来自动丢弃一些不重要的注意力特性,并平衡注意力分支到非注意力分支。具体来说,每个ADM都采用加权方法来控制注意力分支和非注意力分支的动态加权贡献。

如上图所示,注意dropout模块通过使用其块的相同输入特征作为两个独立分支来生成权重。
在形式上,我们有:
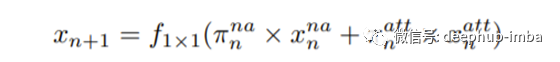
其中x^{na}_ n为非注意力分支的输出,x^{att}_ n为注意力分支的输出。F_ {1×1}(·)提供1×1核卷积。π^{na}和π^{att}分别为非注意力分支和注意力分支的权值,由网络根据输入特征计算π^{na}和π^{att},而不是人为设置的两个固定值。为了计算动态权值,我们有:
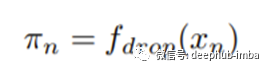
其中f_drop(·)是注意力丢弃模块。
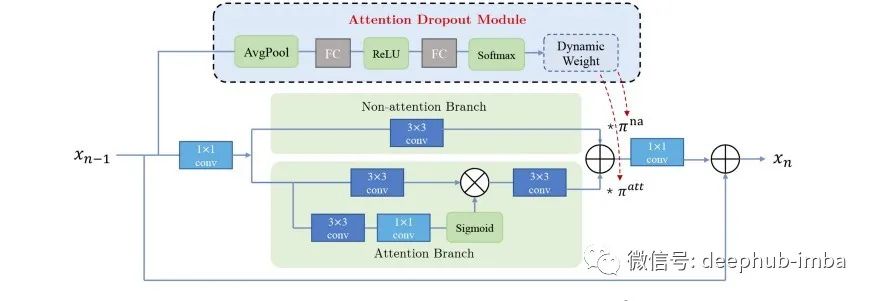
注意力丢弃模块可以在上面的图中详细查看。它首先使用全局平均池化压缩输入xn−1。连接层由两个完全连接的层组成,使用ReLU激活。它们使用全局池化来增加接受域,这使得注意力退出模块能够从整个图像中捕获特征。
结论
实验结果表明,该模型与目前最先进的轻量级网络相比,具有更好的权衡性能。局部归因图的实验也证明注意(A2)结构中的注意可以从更广泛的范围内提取特征。
论文
1.Haoyu Chen, Jinjin Gu, Zhi Zhang.Attention in Attention Network for Image Super-Resolution,arXiv:2104.09497
本文作者:Nabil MADALI