
文章目录
一、概述
Trino
(前身为
PrestoSQL
)是一款高性能,分布式的SQL查询引擎,可以用于查询各种类型的数据存储,包括
Hive
、
Mysql
、
Elasticsearch
、
Kafka
、
PostgreSQL
等。在使用Trino时,可以通过一些参数来控制查询的行为,例如:
coordinator节点和worker节点的数量: 这两个参数控制了Trino集群中管理查询的节点数量,它们的配合调整可以影响整个集群的查询效率。memory和cpu的分配: 这些参数控制了Trino在查询和计算时使用的内存和CPU数量。可以根据集群的实际硬件情况和查询工作负载来灵活配置。join分布式:控制join关键字的使用。join分布式是一种优化策略,在大规模数据集上运行的查询中处理join操作非常简单。- 指定数据源:可以使用
catalog和schema(数据库)两个关键字指定Trino查询的数据源。 - 分区和bucket表的查询: 分区表是对表进行分区和拆分的一种方式,通过分区表查询只需扫描相应分区,提高了查询效率。bucket表是一种将数据分散在多个桶中的表格,它们可以通过桶数对数据进行分片,并行化查询操作,从而提高查询性能。
Trino官方文档:https://trino.io/docs/current/
关于更多的Presto介绍可以参考我这篇文章:大数据Hadoop之——基于内存型SQL查询引擎Presto(Presto-Trino环境部署)
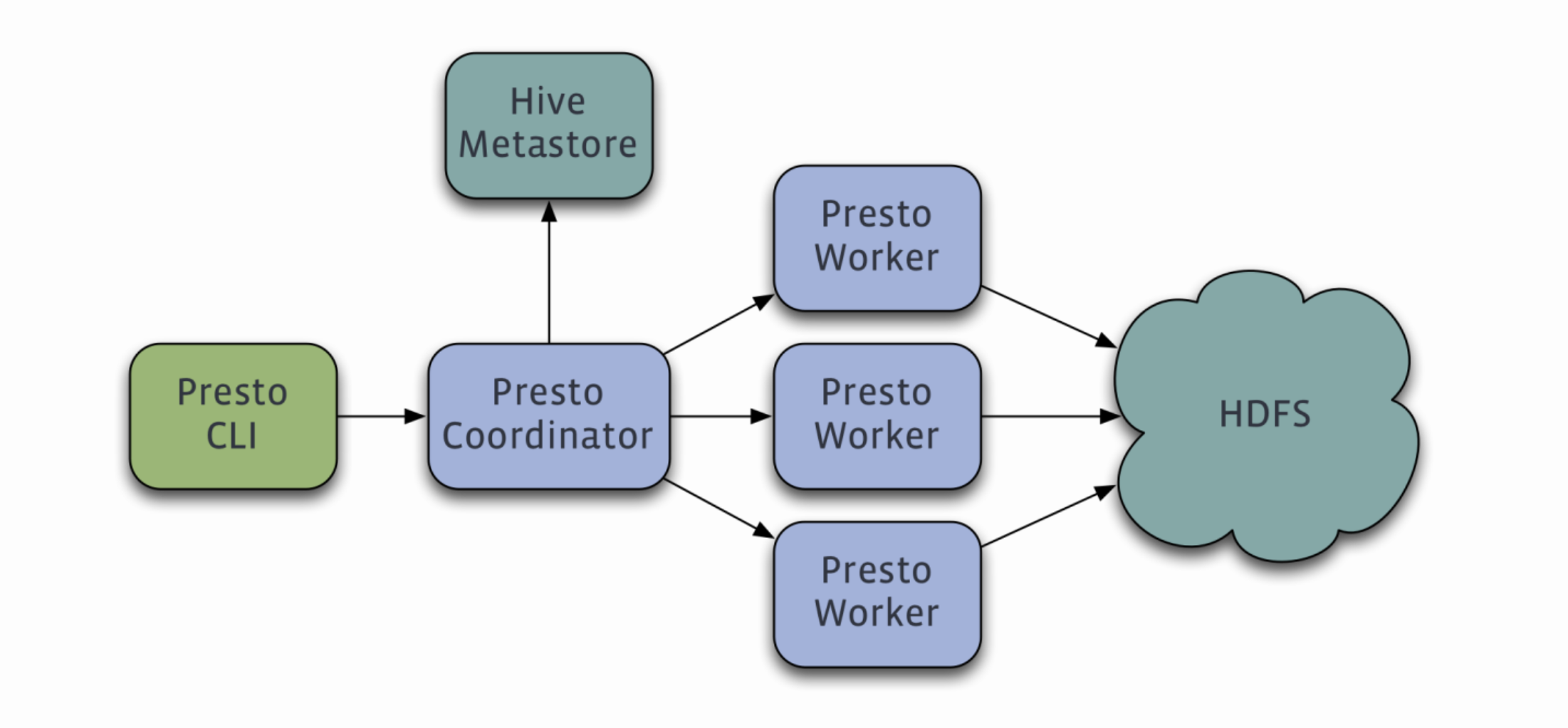
二、Trino coordinator 和 worker 节点作用
1)Trino coordinator 节点作用
在Trino中,coordinator节点是整个集群的管理节点,它的作用包括:
- 查询协调:coordinator节点负责协调所有查询操作,如解析sql语句、生成查询计划、调度和分配查询任务等。它会根据查询的复杂度和数据源的规模来判断查询是否需要被分割和并行执行,以提高查询效率和资源利用率。
- 资源管理:coordinator节点负责管理整个集群的资源,如内存、CPU等。它会根据每个查询的资源需求和集群的可用资源情况来动态调整资源使用情况,以保证集群的稳定性和性能。
- 节点管理:coordinator节点负责管理集群的所有worker节点,包括状态更新、任务分配、心跳检测等。它会监测节点的可用性和状态,并根据集群负载情况来动态调整节点的任务分配和负载平衡策略,以保证整个集群的稳定性和可用性。
- 集群监控:coordinator节点负责监控整个集群的运行状况,包括各个节点的状态、负载情况、查询性能等。它会将这些信息进行汇总和分析,并生成相应的报告和指标,以便管理员进行集群的优化和调整。
- 系统管理:coordinator节点负责管理整个Trino系统,包括配置文件管理、插件管理、安全管理等。它会根据管理员的设定和权限来进行相应的管理和控制,以保证整个系统的稳定性和安全性。
因此,可以看出coordinator节点在Trino集群中起到了至关重要的作用,它是整个集群的大脑和控制中心。为了保证集群的性能和可用性,建议对coordinator节点进行适当的配置和管理,以满足查询复杂度和数据量的需求。
2)Trino worker 节点作用
在Trino中,worker节点是集群中执行任务的节点。它的作用包括:
- 任务执行:worker节点负责执行coordinator分配给它的任务,如数据读取、数据过滤、数据聚合等。它会将数据处理的结果返回给coordinator节点,以便进行下一步的处理和计算。
- 数据存储:worker节点负责存储集群中的数据,包括数据的分片、存储和管理等。它会维护一个数据存储仓库,并根据查询计划和任务分配来读取和处理数据,以提高查询效率和资源利用率。
- 资源管理:worker节点会根据集群的资源限制和任务优先级,动态调整资源的分配和使用情况,以保证集群的稳定性和性能。
- 网络通信:worker节点负责与coordinator节点进行通信,并根据分配的任务来读取和处理数据。它需要保证和coordinator节点的通信畅通,并及时反馈处理结果。
因此,可以看出worker节点在Trino集群中扮演了至关重要的角色,它是整个集群的工作机器和数据存储仓库。为了保证集群的性能和可用性,建议对worker节点进行适当的配置和管理,以满足查询和数据处理的需求。同时,建议用户根据自己的业务需求和数据量来增加或降低worker节点的数量和配置,以达到最佳的资源利用率和查询效率。
三、Trino 参数详细讲解
1)coordinator 节点配置
1、config.properties 配置文件
config.properties是Trino服务器的配置文件,它包含了Trino服务器的各种配置选项,如节点配置、查询优化器配置、内存和CPU配置、集群安全配置等。下面是几个常见的
config.properties
选项:
coordinator=true/false:配置当前节点是否为coordinator节点。node-scheduler.include-coordinator:是Trino协调节点(coordinator)的配置参数之一,用于控制调度器是否包括协调节点自身作为可用的执行节点。默认情况下,node-scheduler.include-coordinator的值为true,即协调节点被视为可用的执行节点。task.max-memory-per-node:该参数用于设置每个工作节点上单个任务(task)可使用的最大内存量。它定义了每个任务在工作节点上可以使用的最大内存量。单位可以是字节(B)、千字节(KB)、兆字节(MB)、千兆字节(GB)或太字节(TB)。query.max-memory:这个参数设置了每个查询可使用的最大内存量。它控制着整个查询在所有工作节点上可以使用的总内存量。当查询需要的内存超过这个限制时,Trino将抛出内存不足的错误。query.max-memory-per-node:此参数定义了每个工作节点可使用的最大内存量。它限制了单个查询在单个工作节点上可以使用的最大内存量。当单个任务需要的内存超过此限制时,Trino将启动其他任务以利用其他工作节点上的内存。query.max-total-memory-per-node: 该参数限制了每个工作节点可使用的最大总内存量。它控制着所有正在运行的查询在单个工作节点上可以使用的总内存量。当工作节点上的查询总内存使用超过此限制时,Trino将拒绝新的查询请求。memory.heap-headroom-per-node:用来配置Trino worker节点的Java堆空间余量的选项。它指定了每个worker节点JVM堆中保留的额外内存空间的大小,用于处理临时内存和查询的内存需求。默认情况下,memory.heap-headroom-per-node的值是0。这意味着Trino使用默认的Java Heap内存分配策略来处理内存,并尽可能避免OOM(内存不足)错误。query.max-run-time:配置每个查询的最大运行时间,防止查询太复杂导致资源耗尽。http-server.http.port=8080:配置http服务器的端口号。query.results.max-age=1m:配置查询结果在内存中的最大保存时间,防止浪费内存。query.priority=1:配置查询的优先级,以便coordinator节点调度任务。exchange.client-threads=2:配置worker节点与coordinator节点之间数据交换的线程数量,以提高网络通信效率。plugin.<plugin-name>.<option>=<value>:配置插件选项和值,以扩展Trino的功能和支持新的数据源。
因此,config.properties文件对于Trino服务器的性能和功能都具有重要的作用,建议管理员和用户仔细查阅和配置。同时,可以根据业务需求和系统资源情况来适当调整其中的选项,以达到最佳的性能和效率。
示例配置如下:
##################################### 协调节点配置###################################coordinator=true
##################################### HTTP服务配置###################################
http-server.http.port=8080##################################### 内存配置###################################
query.max-memory=5GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=10GB
##################################### 发现服务配置###################################
discovery-server.enabled=true
discovery.uri=http://localhost:8080
##################################### 插件配置###################################
plugin.myplugin.property=value
##################################### 其他配置#################################### 身份验证配置
http-server.authentication.type=PASSWORD
http-server.authentication.password-user-mapping-file=etc/password-authenticator.properties
# 授权配置
access-control.name=my-access-control
access-control.config-file=etc/access-control.properties
# 元数据存储配置
metadata.store.type=jdbc
metadata.store.jdbc-url=jdbc:postgresql://localhost:5432/trino_metadata
metadata.store.username=trino
metadata.store.password=secret
# 集群配置
discovery-server.enabled=true
discovery.uri=http://localhost:8080
node-scheduler.include-coordinator=true
# 指标和监控配置
metrics.enabled=true
metrics.reporting-interval=1m
metrics.store.type=prometheus
metrics.store.reporters=prometheus
metrics.store.prometheus.uri=http://localhost:9090/metrics
2、jvm.config 配置文件
Trino协调节点(coordinator)的JVM配置文件是
jvm.config
。它位于Trino安装目录的 etc 文件夹中。
jvm.config
文件用于配置协调节点的Java虚拟机(JVM)参数,以控制内存、垃圾回收、线程等方面的行为。
一些常用的JVM参数及其含义:
-server
:启用服务器模式,优化性能。
-Xmx8G
:设置Java堆的最大内存为8GB。最好是配置小于32G。
-XX:+UseG1GC
:启用G1垃圾收集器。
-XX:InitialRAMPercentage
:是一个Java虚拟机(JVM)参数,用于设置初始堆内存的百分比。它指定了初始堆内存大小相对于可用系统内存的比例。默认值为
64
,表示JVM将会使用可用系统内存的
64%
。
`-XX:InitialRAMPercentage` 该参数通常与`-Xmx`(最大堆内存)参数一起使用,以确保在应用程序启动时分配足够的初始堆内存。
-XX:InitialRAMPercentage 和 -Xmx 都是用于配置Java虚拟机(JVM)的堆内存参数。下面是一个示例配置和相应的换算示例:
-XX:InitialRAMPercentage=25
-Xmx8G
假设可用系统内存为16GB(Gigabytes),我们将根据配置计算初始堆内存和最大堆内存的大小。
首先,我们使用 -XX:InitialRAMPercentage 参数来计算初始堆内存的大小:
初始堆内存大小 = 可用系统内存 * (InitialRAMPercentage / 100)
初始堆内存大小 = 16GB * (25 / 100)= 4GB
接下来,我们使用 -Xmx 参数来指定最大堆内存的大小,这里设置为8GB。
因此,根据以上配置和换算示例,初始堆内存将为4GB,最大堆内存将为8GB。
请注意,确保根据实际系统内存大小和应用程序的内存需求进行适当的调整。对于初始堆内存和最大堆内存,建议根据应用程序的性能需求进行合理配置,以确保充分利用系统资源并避免内存不足或浪费的情况。
此外,-XX:InitialRAMPercentage 和 -Xmx 参数的可用性和行为可能因JVM的版本和厂商而有所不同。请参考所使用JVM的文档以获取准确的信息。
-XX:MaxRAMPercentage:是一个JVM参数,用于指定JVM使用系统内存的最大百分比。这个参数可以被用于Trino和其他Java应用程序。它的默认值为64,表示JVM将最大使用可用系统内存的64%。例如,如果系统有16GB内存可用,则默认情况下JVM将使用10.24GB内存。-XX:MaxRAMPercentage:是一个JVM参数,用于控制G1垃圾收集器中堆区域的大小。G1垃圾收集器是Java SE 9及更高版本中使用的一种高效的垃圾收集器,可以用于Trino和其他Java应用程序。堆区域是G1垃圾收集器中内存分配的最小单位。这个参数的默认值是**堆大小除以2048**,最小值是1MB,最大值是32MB。这意味着如果堆大小是8GB,则每个堆区域的默认大小是4MB。-XX:+ExplicitGCInvokesConcurrent:是一个JVM参数,用于启用显式垃圾回收调用时并发处理的垃圾收集器。在此模式下,会在发出垃圾回收调用时,同时运行一个并发垃圾收集器,以优化程序的性能。-XX:+ExitOnOutOfMemoryError:是一个JVM参数,用于在发生OutOfMemoryError错误时自动退出JVM。OutOfMemoryError指的是Java程序中无法分配足够的内存的情况。默认情况下,JVM在发生OutOfMemoryError时不会终止。如果您使用这个参数,则JVM将在发生OutOfMemoryError时立即退出,从而防止程序继续运行并进一步损坏数据或系统。-XX:-OmitStackTraceInFastThrow:是一个JVM参数,用于在Java程序中启用错误堆栈跟踪提示。通常,当Java程序中发生异常或错误时,系统会生成一个堆栈跟踪提示来告诉您程序执行过程中出现了哪些错误。默认情况下,当程序中的代码中发生快速失败时,JVM会省略异常堆栈跟踪提示,以提高程序的性能。这意味着,当程序出现错误时,您可能无法轻松地DEBUG并查找到底发生了什么错误。-XX:ReservedCodeCacheSize:是一个JVM参数,用于设置JIT编译器代码缓存的最大大小。默认情况下,JIT编译器会将编译过的代码存放在代码缓存中,以加速程序的后续执行。然而,如果缓存大小不够,JIT编译器可能会不得不丢弃部分编译过的代码,这会导致程序性能下降。-XX:PerMethodRecompilationCutoff:是一个Java虚拟机(JVM)的参数,用于设置方法重新编译的阈值。它指定了一个方法在执行多少次之后需要重新编译。该参数的值通常是一个正整数,默认值为15000。-XX:PerBytecodeRecompilationCutoff:是一个Java虚拟机(JVM)的参数,用于设置字节码重新编译的阈值。它指定了一个方法的字节码在执行多少次之后需要重新编译。该参数的值通常是一个正整数,默认值为10000。-Djdk.attach.allowAttachSelf是一个Java系统属性,用于允许Java进程自己附加到自己。该属性通常用于启用Java程序自我监视和调试的功能。默认情况下,此属性被设置为"false",禁止Java进程附加到自身。要允许Java进程附加到自身,需要将该属性设置为"true"。-Djdk.nio.maxCachedBufferSize:是一个Java系统属性,用于设置NIO缓冲区的最大缓存大小。NIO(New I/O)是Java提供的一种高性能I/O操作方式。该属性指定了NIO缓冲区在缓存中的最大大小。默认情况下,该属性未设置,使用JVM内部的默认值。可以通过设置该属性为一个正整数值来限制NIO缓冲区的最大缓存大小,以控制内存的使用。默认值取决于 Java 运行时环境的版本。在Java 8 及之前的版本中,默认值为-1,表示不限制 NIO 缓冲区的最大缓存大小。而在Java 9 及以后的版本中,默认值为0,表示禁用 NIO 缓冲区的缓存,即不进行缓存。-XX:+UnlockDiagnosticVMOptions:是一个 Java 虚拟机(JVM)选项,用于解锁诊断性 VM 选项。默认情况下,JVM 中的某些诊断功能是被禁用的,通过使用该选项,可以解锁并启用这些诊断功能。这个选项通常用于开发和调试目的。-XX:+UseAESCTRIntrinsics:是一个 Java 虚拟机(JVM)选项,用于启用AES-CTR加密算法的硬件优化。当该选项被启用时,JVM会尝试使用CPU的AES指令集来执行AES-CTR操作,以提高加密和解密的性能。-XX:-G1UsePreventiveGC:是一个 Java 虚拟机(JVM)选项,用于禁用G1垃圾收集器的预防性垃圾回收(Preventive GC)机制。预防性垃圾回收是 G1 垃圾收集器的一项特性,旨在在堆内存使用率较低时主动触发垃圾回收,以避免堆内存达到极限。
这个选项通常用于开发和
以下是一个示例的
jvm.config
配置文件:
-server
-Xmx2G
-XX:InitialRAMPercentage=20
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
# Disable Preventive GC for performance reasons (JDK-8293861)
-XX:-G1UsePreventiveGC
请注意,具体的配置取决于您的硬件资源、工作负载和性能需求。您可以根据您的具体情况来调整和优化JVM参数。
3、log.properties 配置文件
# 设置日志级别,有四个级别:DEBUG, INFO, WARN and ERROR
io.trino=INFO
4、node.properties 配置文件
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=production
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的,不填则是随机的。
node.id=trino-coordinator
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/apache/trino/data
2)worker 节点配置
1、config.properties 配置文件
以下是一个Trino工作节点的配置文件示例config.properties,用于配置工作节点的基本设置,包括通信、内存、线程池以及插件等。
coordinator=false
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=10GB
query.max-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://<your-coordinator-node-hostname>:8080
exchange.http-client.keep-alive-interval=5m
exchange.http-client.idle-timeout=10m
task.concurrency=16
task.writer-count=4
jvm.configured-initial-ram-percent=80
memory.heap-headroom-per-node=1GB
以下是示例配置文件中的各项设置的含义:
coordinator=false:设置当前节点为工作节点而非协调器节点。node-scheduler.include-coordinator=false:用于决定协调器节点是否应该纳入查询计算资源的调度范围。当该参数设置为true时,协调器节点可以作为一个普通的计算节点来执行查询,从而帮助处理计算负载。当设置false,这将确保协调器节点不会执行查询,从而避免了性能瓶颈问题,一般是设置false,禁用协调节点又充当worker节点使用。http-server.http.port=8080:HTTP服务器监听的端口号,用于接收REST API请求。query.max-memory=10GB:单个查询可用的最大内存数量。
- query.max-memory-per-node=2GB
:单个工作节点可用于执行查询的最大内存数量。
discovery-server.enabled=true:启用节点发现服务器,用于协调 Trino 群集中的各个节点。discovery.uri=http://<your-coordinator-node-hostname>:8080:发现服务器节点的URL。exchange.http-client.keep-alive-interval=5m:控制通信时,HTTP客户端保持活动状态的时间。exchange.http-client.idle-timeout=10m:当HTTP客户端处于空闲状态时,客户端关闭连接之前保持空闲的时间量。task.concurrency=16:在工作节点上同时执行的最大任务数。task.writer-count=4:在工作节点上同时写入数据的最大任务数。jvm.configured-initial-ram-percent=80:JVM初始堆大小作为RAM百分比的设置。memory.heap-headroom-per-node=1GB:为Trino查询准备的每个节点之外的堆剩余空间。
请注意,这只是一个示例配置,您可以根据您自己的需求进行修改。有关更多配置参数和详细信息,请参阅官方文档:https://trino.io/docs/current/installation/deployment.html。
2、jvm.config 配置文件
下面是一个Trino工作节点的
jvm.config
示例配置文件,它包含了一些常用的JVM参数,可以帮助你优化Trino的性能和内存利用率:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=16M
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:ErrorFile=/var/log/trino/hs_err_pid%p.log
-Djava.library.path=/usr/lib/hadoop/lib/native
-Djdk.attach.allowAttachSelf=true
这里是每个参数的含义:
-server: 使用JVM的服务模式,通常是用于长时间运行的应用程序。-Xmx16G: 设置JVM可用的最大堆内存为16GB。-XX:+UseG1GC: 启用G1垃圾回收器。-XX:G1HeapRegionSize=16M: 设置G1 GC的堆区域大小为16MB。-XX:+HeapDumpOnOutOfMemoryError: 在内存溢出时生成堆内存转储文件。-XX:OnOutOfMemoryError=kill -9 %p: 在内存溢出时强制杀死Trino进程。-XX:ErrorFile=/var/log/trino/hs_err_pid%p.log: 将JVM错误信息输出到指定的错误文件中。-XX:+ExplicitGCInvokesConcurrent: 启用显式垃圾回收操作。-Djava.library.path=/usr/lib/hadoop/lib/native: 指定Hadoop本机库的路径。-Djdk.attach.allowAttachSelf=true: 允许JVM附加到它自己的进程,有助于诊断和调试。
这只是一个基础配置文件,用户可以根据各自的需求和系统资源状况进行微调。同时需要注意的是,在配置JVM参数时,一定要谨慎,了解每个参数的含义和影响,并进行适当的测试和调优,以确保系统的稳定性和性能。
3、log.properties 配置文件
# 设置日志级别,有四个级别:DEBUG, INFO, WARN and ERROR
io.trino=INFO
4、node.properties 配置文件
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=production
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的,不填则是随机的。
node.id=trino-worker-1
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/apache/trino/data
四、环境准备
如已经有环境了,可以忽略,如想快熟部署Presto(Trino)环境可参考我这篇文章:【大数据】通过 docker-compose 快速部署 Presto(Trino)保姆级教程
dockerexec -it trino-coordinator bash# --catalog:数据源 --schema:数据库${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
五、Trino 中的 数据源(catalog)
在Trino中,catalog是一种用于管理数据连接和数据源的概念。一个catalog可以代表一个数据库、一个hive实例、或者其他支持的数据源。Trino可以通过启用不同的catalog来连接和查询不同的数据源,这样你就可以使用一个Trino集群查询多个数据源中的数据,而不需要使用不同的工具和语言进行查询。
Trino中支持的catalog包括:
系统catalog:包括system、memory、information_schema和metadata,用于管理和查询Trino系统和运行时信息。
- Hive catalog:用于连接处理Hive数据。
- Mysql catalog:用于连接在Trino中,catalog是一种用于管理数据连接和数据源的概念。一个catalog可以代表一个数据库、一个hive实例、或者其他支持的数据源。Trino可以通过启用不同的catalog来连接和查询不同的数据源,这样你就可以使用一个Trino集群查询多个数据源中的数据,而不需要使用不同的工具和语言进行查询。
Trino中支持的catalog包括:
- **系统
catalog**:包括system、memory、information_schema和metadata,用于管理和查询Trino系统和运行时信息。 Mysql catalog:用于连接Mysql数据源。Hive catalog:用于连接处理Hive数据。Kafka catalog:用于连接处理Kafka消息数据。Elasticsearch catalog:用于连接处理Elasticsearch数据。Jdbc catalog:用于连接处理关系型数据库。Cassandra catalog:用于连接处理Cassandra NoSQL数据库。
除了以上常用的catalog,Trino还支持许多其他的catalog。你可以通过配置文件或者命令行参数来启用或禁用不同的catalog,以便连接和查询不同的数据源。当启用一个catalog时,需要为它配置连接参数和身份凭证等信息。Trino中的catalog提供了一种简便而灵活的方式来管理连接和查询多种数据源,使得数据查询和集成变得更加高效和便利。
官方文档:https://trino.io/docs/current/connector.html
六、Trino 数据类型
官方文档:https://trino.io/docs/current/language/types.html
1)基础数据类型
类型描述示例booleantrue或falsetruetinyint8位有符号整数,最小值− 2^7 ,最大值 2^7-142smallint16位有符号整数,最小值− 2^15 ,最大值 2^15-142integer、int32位有符号整数,最小值− 2^31 ,最大值 2^31-1bigint64位有符号整数,最小值− 2^63 ,最大值 2^63-1real32位浮点数,遵循IEEE 754二进制浮点数运算标准2.71828double64位浮点数,遵循IEEE 754二进制浮点数运算标准2.71828decimal固定精度小数123456.7890varchar、varchar(n)可变长度字符串。字符长度为m(m < n),则分配m个字符“hello world”char、char(n)固定长度字符串。总是分配n个字符,不管字符长度是多少。char表示char(1)“hello world”
- 当字符串cast为
char(n),不足的字符用空格填充,多的字符被截断 - 当插入字符串到类型为
char(n)的列,不足的字符用空格填充,多了就报错 - 当插入字符串到类型为
varchar(n)的列,多了就报错
2)集合数据类型
类型示例arrayarray[‘apples’, ‘oranges’, ‘pears’]mapmap(array[‘a’, ‘b’, ‘c’], array[1, 2, 3])json{‘a’:1, ‘b’:2, ‘c’:3}rowrow(1, 2, 3)
3)日期时间数据类型
官方文档:https://trino.io/docs/current/functions.html
类型描述示例date包含年、月、日的日期2023-05-14time包含时、分、秒、毫秒的时间, 时区可选16:26:08.123 +08:00timestamp包含日期和时间, 时区可选2023-05-14 16:26:08.123 Asia/Shanghaiinterval year to month间隔时间跨度为年、月interval ‘1-2’ year to monthinterval day to second间隔时间跨度为天、时、分、秒、毫秒interval ‘5’ day to second
七、Trino 内置函数
Trino(之前叫Presto)提供了丰富的内置函数,可以满足各种SQL查询的需求。下面对Trino内置函数进行详细说明。
1)数学函数
abs(numeric):返回数值参数的绝对值。ceil(numeric):返回不小于参数的最小整数。floor(numeric):返回不大于参数的最大整数。exp(numeric):返回e的幂次方。log(numeric):返回参数的自然对数。log10(numeric):返回参数的以10为底的对数。sqrt(numeric):返回参数的平方根。power(numeric, numeric):返回第一个参数乘以第二个参数的幂次方。
2)字符串函数
concat(string1, string2, ...): 连接两个或多个字符串。length(str):返回字符串的长度。substring(str, from [, length ]):返回字符串的子串,从指定位置开始(从1开始计算),如果提供长度参数,则截取固定长度。replace(str, pattern, replacement):将字符串中的符合模式的字符串替换成替换字符串。lower(str) / upper(str):将字符串转化成小写/大写。trim([characters from] string):去掉字符串头尾指定的空格或字符。regexp_extract(string, pattern, index):指定模式,并返回特定位置(从1开始计算)的匹配结果。regexp_replace(string, pattern, replacement):将字符串中的符合模式的字符串替换成替换字符串。
3)日期时间函数
date(date_string):将日期字符串转化成日期格式。current_date:返回当前日期。current_time:返回当前时间。current_timestamp:返回当前时间戳。year(date):返回日期的年份。month(date):返回日期的月份。day(date):返回日期的日份。hour(timestamp):返回时间戳的小时部分。minute(timestamp):返回时间戳的分钟部分。second(timestamp):返回时间戳的秒部分。
4)聚合函数
count(*) / count(expression):返回记录数。count(*)表示所有行的行数,一般用于计算表的行数。count(expression)返回expression的不同值的数量。sum(number):返回列数值的总和。avg(numeric):返回数值列的平均值。max(value) / min(value):返回列的最大值/最小值。array_agg(expression):将指定表达式的结果合并为一个数组。
5)逻辑函数
if(condition, true_value, false_value):如果条件为真,返回true_value,否则返回false_value。nullif(expression1, expression2):如果expression1等于expression2,则返回null。coalesce(expression1, expression2, ...):返回参数列表中第一个非空的值。and(x1, x2, ...) / or(x1, x2, ...) / not(x):逻辑运算符,返回相应的逻辑值。
6)类型转换函数
cast(expression AS type):将表达式转化为指定类型。try_cast(expression AS type):尝试将表达式转化为指定类型,如果无法转化,则返回null。to_json(expression):将指定的值序列化为JSON字符串。from_json(jsonString, type):将一个JSON字符串反序列化为指定类型。to_array(map) / to_map(array):将一个map(array)转化为一个数组(map)。
这些内置函数只是Trino中的部分函数,Trino还支持大量其他内置函数,可以参阅Trino的官方文档获得更详细、更全面的信息。
八、Trino 中的 SQL 语法
连接:
# 如不是通过容器部署,自己有环境,可以忽略下来容器登录的步骤dockerexec -it trino-coordinator bash# --catalog:数据源 --schema:数据库${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
官方文档:https://trino.io/docs/current/sql.html
1)数据源语法
一般数据源配置在
${TRINO_HOME}/etc/catalog
目录下
# 查看数据源
show catalogs;
当然也可以通过sql创建,示例如下:
1、配置hive数据源
${TRINO_HOME}/etc/catalog/hive.conf
connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
hive.config.resources='/opt/apache/trino/etc/catalog/core-site.xml,/opt/apache/trino/etc/catalog/hdfs-site.xml'
2、查看catalog
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
SHOW CATALOGS;# 查看当前 catalog
SELECT current_catalog;
2)数据库语法(schemas)
在Trino中,catalog用于访问数据源和外部系统。每个catalog都可以包含一个或多个schema,每个schema包含一组相关的表。你可以在Trino中使用
CREATE SCHEMA
、
DROP SCHEMA
、
RENAME SCHEMA
和
SHOW SCHEMAS
等语句来管理
schema
。
语法:
CREATESCHEMA[IFNOTEXISTS] schema_name
[AUTHORIZATION(user|USERuser| ROLE role )][WITH( property_name = expression [,...])]
以下是一些用于操作catalog schema的示例:
- 创建一个名为schema_test的新schema
#USE 语法,USE catalog.schema # USE schema
USE hive.default;
CREATE SCHEMA IF NOT EXISTS schema_test;# 查看
show schemas;
【注意】如果登录时,没有带–scheme,就必须USE切换scheme,才能使用创建schema。
- 查看scheme
show schemas from hive;
show schemas;
- 删除一个名为my_schema的schema
DROP SCHEMA hive.schema_test;
- 查看当前scheme
# 查看当前catalog
SELECT current_catalog;# 查看scheme
SELECT current_schema;
3)表 DDL 语法
在Trino中,你可以使用CREATE TABLE语句来创建表,使用ALTER TABLE来修改表的结构和元数据,并使用DROP TABLE来删除表。
下面分别介绍一下这几个操作的语法和参数:
1、创建表 - CREATE TABLE
语法:
CREATE TABLE [ IF NOT EXISTS ]
table_name ({ column_name data_type [ NOT NULL ][ COMMENT comment ][ WITH ( property_name = expression [, ...])]| LIKE existing_table_name
[{ INCLUDING | EXCLUDING } PROPERTIES ]}[, ...])[ COMMENT table_comment ][ WITH ( property_name = expression [, ...])]
使用
CREATE TABLE
创建一个新的表。下面是一个示例:
CREATE TABLE orders (
orderkey bigint,
orderstatus varchar,
totalprice double,
orderdate date)
WITH (format ='ORC')# 在Trino中,你可以使用 FORMAT 子句指定查询结果输出的格式。Trino支持多种常见格式,包括文本(text)、CSV、JSON、javax.json、Avro、Parquet、ORC、RCFile等。
其中,my_table是你想要创建的表名,后面的括号中列出了表的列和对应的数据类型。在Trino中可以定义多种数据类型,如
integer
、
varchar
、
boolean
等等。更多数据类型可以查看Trino官方文档。
你可以使用CREATE TABLE的参数进行更高级的操作,例如指定分桶
(bucket)
、分区
(partition)
和格式
(format)
,以下是一些常用参数的示例:
CREATE TABLE my_table3 (
column1 int,
column2 varchar(64),
column3 varchar(64),
column4 varchar(64))
WITH (format='ORC',
partitioned_by = ARRAY['column3','column4'],
bucketed_by = ARRAY['column2'],
bucket_count =10);# 注意:partitioned字段必须是表的最后的字段
这个示例中,表使用
ORC
格式存储,按照column3和column4列进行了分区,使用column2列进行了分桶,并设置了10个桶。
2、修改表 - ALTER TABLE
使用
ALTER TABLE
命令修改现有表。下面是一些常见的用法:
- 添加列
ALTERTABLE my_table ADDCOLUMN new_column datatype;
- 修改列
ALTERTABLE my_table ALTERCOLUMN column1 TYPE new_datatype;
- 删除列
ALTERTABLE my_table DROPCOLUMN column1;
- 添加分区
ALTERTABLE my_table ADDPARTITION(column1 ='value1', column2 ='value2');
- 删除分区
ALTER TABLE my_table DROP PARTITION (column1 ='value1', column2 ='value2', ...);
3、删除表 - DROP TABLE
使用DROP TABLE语句删除现有表。下面是一个示例:
DROPTABLE my_table;-- 如报错:io.prestosql.spi.security.AccessDeniedException: Access Denied: Cannot drop table-- 在catalog hive中添加以下两行-- hive.allow-drop-table=true-- hive.allow-rename-table=true
注意:删除一个表将会永久删除该表的全部数据,慎重操作!
4、trino 中的分区分桶
在Trino中,你可以使用分区(partition)和分桶(bucket)来优化查询性能,提高查询速度和效率。
1、分区(partition)
- 分区是指把数据按照一定规则划分成若干部分(比如按照日期、地区、类别等),每个部分就是一个分区。在Trino中,你可以使用
CREATE TABLE语句的partitioned_by子句来创建一个分区表,你可以写入数据到这个表的每个分区。 - 使用分区对于查询过滤条件的列进行过滤非常高效。Trino实际上将所有数据按照分区规则分布到磁盘的不同目录下,当你执行包含了分区过滤的查询时,Trino会自动发现这个过滤条件,并且只读取符合条件的分区数据,这样就可以大大提高查询效率。
以下是一个创建一个按照日期分区的示例:
CREATETABLE my_part_table (
id bigint,
name varchar(64),
event_date date)WITH(
partitioned_by = ARRAY['event_date']);
2、分桶(bucket)
- 分桶是将表中的数据划分成若干个桶(bucket)存储的方式。在Trino中,你可以使用 CREATE TABLE 语句的
bucketed_by和bucket_count子句来创建一个分桶表。在建表时,你需要定义一个或多个bucket列并设置桶的数量,Trino会根据这些设置把表中的数据分配到不同的桶中。
使用分桶后,Trino优化器可以将查询操作分配到不同的节点上并行执行,以实现更快的查询速度。比如,如果你的分桶表中有100个桶,Trino可以把这100个桶分配到100个不同的节点上并行执行查询操作,从而大大提高查询效率。
以下是一个创建分桶的示例:
CREATE TABLE my_bucket_table (id INT,
name VARCHAR,
age INT
)
WITH (
bucket_count =10,
bucketed_by = ARRAY['id']);
CREATE TABLE my_bucket_table_new (id INT,
name VARCHAR,
age INT
)
WITH (
bucket_count =10,
bucketed_by = ARRAY['id']);
4)添加数据
INSERT INTO my_bucket_table (id, name, age) VALUES (1, 'Tom', 20), (2, 'Jerry', 23);
INSERT INTO my_bucket_table_new SELECT * FROM my_bucket_table;
Presto(Trino)配置参数以及 SQL语法讲解就先到这里了,有任何疑问欢迎给我留言,也可关注我的公众号【大数据与云原生技术分享】加群交流或私信咨询问题~
版权归原作者 大数据老司机 所有, 如有侵权,请联系我们删除。