
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com
BP神经网络的训练算法基本都涉及到梯度公式,
本文提供三层BP神经网络的梯度公式和推导过程
一. 推导目标
BP神经网络的梯度推导是个复杂活,
在推导之前 ,本节先把推导目标清晰化
**1.1 梯度公式目标 **
训练算法很多,但各种训练算法一般都需要用到各个待求参数(w,b)在损失函数中的梯度,
因此求出w,b在损失函数中的梯度就成为了BP神经网络必不可少的一环,
求梯度公式,即求以下误差函数E对各个w,b的偏导:
代表网络对第m个样本第k个输出的预测值,w,b就隐含在
中
1.2 本文梯度公式目标
虽然梯度只是简单地求E对w,b的偏导,但E中包含网络的表达式f(x),就变得非常庞大,
求偏导就成了极度艰巨晦涩的苦力活,对多层结构通式的梯度推导稍为抽象,
本文不妨以最常用的三层结构作为具体例子入手,求出三层结构的梯度公式
即:输入层-隐层-输出层 (隐层传递函数为tansig,输出层传递函数为purelin)
虽然只是三层的BP神经网络,
但梯度公式的推导,仍然不仅是一个体力活,还是一个细致活,
且让我们细细一步一步慢慢来
二. 网络表达式梳理
在损失函数E中包括了网络表达式,在求梯度之前,
先将表达式的梳理清晰,有助于后面的推导
2.1 梳理三层BP神经网络的网络表达式
网络表达式的参考形式
隐层传递函数为tansig,输出层传递函数为purelin的三层BP神经网络,有形如下式的数学表达式
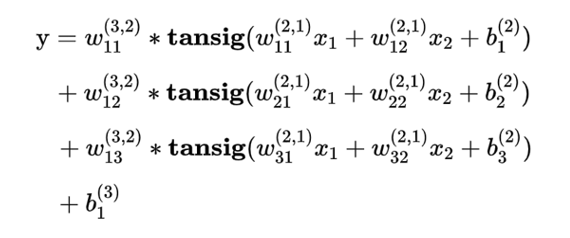
网络表达式的通用矩阵形式
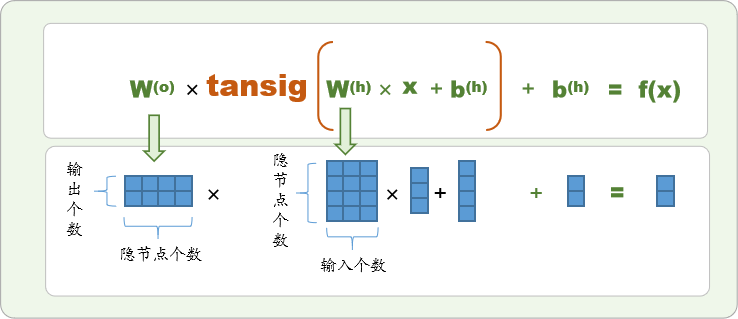
写成通用的矩阵形式为
这里的
为矩阵,
和
为向量,
上标(o)和(h)分别代表输出层(out)和隐层(hide),
例如,2输入,4隐节点,2输出的BP神经网络可以图解如下:
三. 三层BP神经网络梯度推导过程
本节我们具体推导误差函数对每一个待求参数w,b的梯度
3.1 简化推导目标
由于E的表达式较为复杂,
不妨先将问题转化为"求单样本梯度"来简化推导表达式
对于任何一个需要求偏导的待求参数w,都有:
即损失函数的梯度,等于单个样本的损失函数的梯度之和(E对b的梯度也如此),
因此,我们先推导单个样本的梯度,最后再对单样本梯度求和即可。
现在问题简化为求
3.2 输出层权重的梯度推导
输出层权重梯度推导
输出层的权重为"输出个数*隐节点个数"的矩阵,现推导任意一个权重wji (即连接第i个隐层与第j个输出的权重)的单样本梯度
如下:
事实上,只有第j个输出
是关于
的函数,也即对于其它输出
因此,上式即等于
继续求导
是第j个输出的误差,简记为
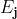
是第j个隐节点的激活值,简记为
(A即Active)
上式即可写为
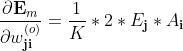
**上述是单样本的梯度,
整体样本的梯度则应记为 **M,K为样本个数、输出个数
是第m个样本第j个输出的误差
是第m个样本第i个隐节点的激活值
3.3 输出层阈值的梯度推导
输出层阈值梯度推导
对于阈值
(第j个输出节点的阈值)的推导与权重梯度的推导是类似的,
只是上述标蓝部分应改为
简记为
**上述是单样本的梯度,
整体样本的梯度则应记为 **
M,K为样本个数、输出个数
3.4隐层权重的梯度推导****
隐层的权重为"隐节点个数*输入个数"的矩阵,
现推导任意一个权重
(即连接第i个输入与第j个隐节点的权重)的单样本梯度
如下:
只有第j个tansig是关于
继续求导
又由
所以上式为:
简写为
上述是单样本的梯度,对整体样本则有:
M,KM,K为样本个数、输出个数
是第m个样本第k个输出的误差
是第m个样本第i个输入
3.5 隐层阈值的梯度推导
隐层阈值梯度推导
对于阈值b_\textbf{j}^{(h)} (第j个隐节点的阈值)的推导与隐层权重梯度的推导是类似的,只是蓝色部分应改为
又由
所以上式为:
简写为
上述是单样本的梯度,对整体样本则有:
M,K为样本个数、输出个数
四. 推导结果总结
4.1 三层BP神经网络梯度公式
输出层梯度公式
输出层权重梯度:
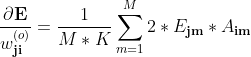
输出层阈值梯度:
** **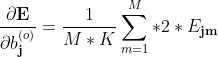
隐层梯度公式
隐层权重梯度:
隐层阈值梯度:
** **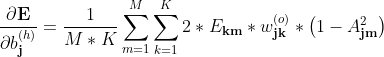
✍️符号说明
M,K为样本个数、输出个数
** 相关文章**
《BP神经网络梯度推导》
《BP神经网络提取的数学表达式》
《一个BP的完整建模流程》
版权归原作者 老饼讲解-BP神经网络 所有, 如有侵权,请联系我们删除。