
什么是kafka?
分布式事件流平台。希望不仅仅是存储数据,还能够数据存储、数据分析、数据集成等功能。消息队列(把数据从一方发给另一方),消息生产好了但是消费方不一定准备好了(读写不一致),就需要一个中间商来存储信息,kafka就是中间商
架构图如下:
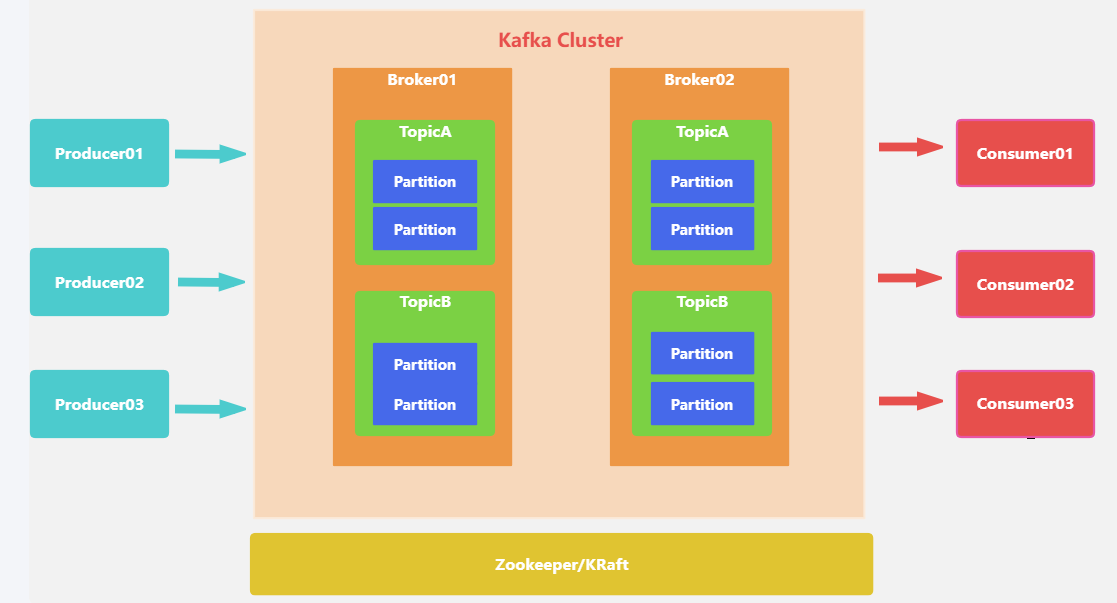
名词解释
名称
解释
Broker
消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
Topic
Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
Producer
消息生产者,向Broker发送消息的客户端
Consumer
消息消费者,从Broker读取消息的客户端
ConsumerGroup
每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息
Partition
物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的
offset
partition中每条消息的唯一编号
①、Producer(生产者)
消息生产者,向broker发送消息,也称为发布者
②、comsumer(消费者)
读取消息的客户端
③、consumer group(消费者组)
一个consumer group由多个consumer组成,消费者组可以消费某个分区中的所有消息,消费的消息不会立马被删除。也称为订阅者
④、Topic(主题)

逻辑上的区分,通过topic将消息进行分类,不同topic会被订阅该topic的消费者消费
特点:topic的一个分区只能被consumer group的一个consumer消费;同一条消息可以被多个消费者组消费,但同一个分区只能被某个消费者组中的一个消费者消费。
问题:topic消息非常多,消息会被保存在log日志文件中,文件过大
解决:分区
⑥、partition(分区)
将一个topic中的消息分区来存储,有序序列,真正存放消息的消息队列
⑦、offset(偏移量)
分区中的每条消息都有唯一的编号,用来唯一标识这一条消息(message)
⑧、Leader、Follower(副本)
每个分区都可以设置自己对应的副本(replication-factor参数),有一个主副本(leader)、多个从副本(follower)
每个副本的职责是什么?
- leader:处理读写请求,负责当前分区的数据读写
- follower:同步数据,保持数据一致性

为什么要设置多副本?
单一职责。leader负责和生产消费者交互,follower负责副本拷贝,副本是为了保证消息存储安全性,当其中一个leader挂掉,则会从follower中选举出新的leader,提高了容灾能力,但是副本也会占用存储空间
⑨、ISR(副本集)

动态集合,保存正在同步的副本集,是与leader同步的副本。如果某个副本不能正常同步数据或落后的数据比较多,会从副本集中把节点中剔除,当追赶上来了在重新加入。kafka默认的follower副本能够落后leader副本的最长时间间隔是10S
参数设置:replica.lag.time.max.ms
kafka工作流程?
生产者生产好消息之后调用send()方法发送到broker端,broker将收到的消息存储的对应topic中的patition中,而broker中的消息实际上是存储在了commit-log文件中,消费者监听定时循环拉取消息

一、生产者发送消息流程

参考代码:
package com.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class MyProductor {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//kafka的配置
Properties properties = new Properties();
//kafka服务器地址和端口
properties.put("bootstrap.servers", "localhost:9092");
//Producer的压缩算法使用的是GZIP
//为什么要压缩?
properties.put("compression.type","gzip");
//指定发送消息的key和value的序列化类型
properties.put("key.serializer", "org.apache.kafka.common,serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common,serialization.StringSerializer");
//补充:为什么要序列化/反序列化?
//实例化一个生产者对象,指定发送的主题、key、value、分区号等
KafkaProducer<Object, Object> producer = new KafkaProducer<>(properties);
//发送100条消息
for (int i = 0; i < 100; i++) {
//调用send方法,向kafka发送数据,并返回一个Future对象,通过该对象来获取结果
Future<RecordMetadata> result = producer.send(new ProducerRecord<>("my-topic", Integer.toString(i),
Integer.toString(i)));
RecordMetadata recordMetadata = result.get();
}
//关闭生产者对象
producer.close();
}
}
第一步、生产者配置参数
指定生产消息要达到的kafka服务器地址,压缩方式、序列化方式

①、为什么要进行压缩?
Producer生产的每个消息都经过GZIP压缩,在传输的过程中能够节省网络传输带宽和Broker磁盘占用
②、为什么要进行序列化/反序列化?
数据在网络传输过程中都是以字节流的形式传输的,在生产者发送消息的时候需要将消息先进行序列化
第二步、拦截器
生产者在发送消息前会对请求的消息进行拦截,起到过滤和处理的作用。
我们可以自定义拦截器,拦截器中定义自己需要的逻辑,满足个性化配置。比方说对消息进行加密解密、消息格式转换、消息路由等等
第三步、序列化器
数据在网络传输过程中都是以字节流的形式传输的,在生产者发送消息的时候需要将消息先进行序列化
第四步、分区器
- 如果ProducerRecord对象提供了分区号,使用提供的分区号
- 如果没有提供分区号,提供了key,则使用key序列化后的值的hash值对分区数量取模
- 如果没有提供分区号、key,采用轮询方式分配分区号(默认)

第五步、send()发送消息
通过上面的操作生产者已经知道该往哪个主题、哪个分区发送这条消息了。
第六步、获取发送消息响应
①、如果消息发送成功:broker收到消息之后会返回一个Future类型RecordMetadata对象,可以通过该对象来获取发送的结果,对象中记录了此条消息发送到的topic、partition、offset。
②、消息发送失败:错误消息。在收到错误消息之后会有尝试机制,尝试重新发送消息


但直接使用send(msg)会出现问题,调用之后会立即返回,如果因为网络等外界因素影响导致消息没有发送到broker,出现生产者程序丢失数据问题,只能通过处理返回的Future对象处理才能感知到。
对应的解决方案是我们可以使用send(msg,callbakc)的方式发哦是那个消息并设置回调函数

在发送消息后,会立即调用回调函数来处理发送结果,回调函数中定义了处理逻辑
二、broker收发消息流程
1. 分区机制(主题-分区-消息)
前文中提到生产者发送到broker的消息都是基于topic进行分类的(逻辑上),而topic中的消息是以partition为单位存储的(物理上),每条消息都有自己的offset
①、 分区中的数据存储在哪儿?
每个partition都有一个commit log文件
②、 为什么要分区(好处)存储?
如果commitlog文件很大的话可能导致一台服务器无法承担所有的数据量,机器无法存储,分区之后可以把不同的分区放在不同的机器上,相当于是分布式存储
- 每个消费者并行消费
- 提高可用性,增加若干副本
2. 消息存储
每一个partition都对应了一个commit log文件,日志文件中存储了消息等信息,新到达的消息以追加的方式写入分区的末尾,然后以先入先出的顺序读取。
①、 分区中的消息会一直存储吗?
如果不停的一致向日志文件中写入消息,日志文件大小也是有上限的,所以kafka会定期的清理磁盘,有两种方式:
- 时间:kafka默认保留最近一周的消息(根据配置文中的日志保留时间设置的:log.retention.hours)
- 大小:kakfa在配置文件中配置单个消息的大小为1MB,如果生产者发送的消息超过1MB,不会接收消息
②、follower副本数据什么时候同步更新的?
- 数据传输阶段:Leader副本将消息发送给Follower副本。这个过程中,Leader副本会将消息按照一定的批次大小发送给Follower副本,Follower副本会接收并写入本地日志。一旦Follower副本成功写入消息到本地日志,就会向Leader副本发送确认消息。
- 确认阶段:Leader副本在收到来自所有Follower副本的确认消息后,就会认为消息已经成功复制到所有的副本中。然后向生产者发送成功响应,表示消息已被成功接收和复制。
注意的是,Follower副本的数据同步是异步进行的,即Follower副本不需要等待数据同步完成才返回成功响应。这样可以提高消息的处理速度和吞吐量。但也意味着,在数据同步过程中,Follower副本可能会滞后于Leader副本一段时间,这个时间间隔称为追赶(lag)。Kafka提供了配置参数来控制同步和追赶的速度,以平衡数据的一致性和性能的需求。
三、消费者消费消息流程

- 配置消费者客户端参数
- 创建消费者实例并指定订阅的主题
- 拉取消息并消费
- 提交消费offset
参考代码:
package com.example;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class Consumer {
public static void main(String[] args) {
Properties properties = new Properties();
//要连接的kafka服务器
properties.put("bootstrap.servers", "localhost:9092");
//标识当前消费者所属的小组
properties.put("group.id", "test");
//---------位移提交(自动提交)----------
//为true,自动定期地向服务器提交偏移量(offset)
properties.put("enable.auto.commit", "true");
//自动提交offset的间隔,默认是5000ms(5s)
properties.put("auto.commit.interval.ms", "1000");
//每隔固定实践消费者就会把poll获取到的最大偏移量进行自动提交
//出现的问题:如果刚提交了offset,还没到5s,2s的时候就发生了均衡,导致分区会重新划分,此时offset是不准确的
//key和value反序列化
properties.put("key.serializer", "org.apache.kafka.common,serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common,serialization.StringSerializer");
KafkaConsumer<Object, Object> consumer = new KafkaConsumer<>(properties);
//指定consumer消费的主题(订阅多个)
consumer.subscribe(Arrays.asList("my-topic", "bar"));
//轮询向服务器定时请求数据
while (true) {
//拉取数据
ConsumerRecords<Object, Object> records = consumer.poll(100);
for (ConsumerRecord<Object, Object> record : records) {
//同步提交:提交当前轮询的最大offset
consumer.commitSync();
//如果失败还会进行重试
//优点:提交成功准确率上升;缺点:降低程序吞吐量
System.out.printf("offset=%d,key=%s,value=%s%n", record.offset(), record.key(), record.value());
//异步提交并定义回调
//优点:提高程序吞吐量(不需要等待请求响应,程序可以继续往下执行)
//缺点:当提交失败的时候不会自动重试;
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets,
Exception exception) {
if (exception != null) {
System.out.println("错误处理");
offsets.forEach((x, y) -> System.out.printf(
"topic = %s,partition = %d, offset = %s \n", x.topic(), x.partition(), y.offset()));
}
}
});
}
}
}
}
第一步、配置消费者客户端参数
配置要消费消息的kafka服务器、消费者所在的消费组、offset是自动提交还是手动提交

enable.auto.commit和auto.commit.interval.ms参数为是否自动提交参数
- enable.auto.commit=true:自动定期地向服务器提交偏移量(offset)
- auto.commit.interval.ms:动提交offset的间隔,默认是5000ms(5s)
逻辑:每隔固定实践消费者就会把poll获取到的最大偏移量进行自动提交
出现的问题:如果刚提交了offset,还没到5s,2s的时候就发生了均衡,导致分区会重新划分,此时offset是不准确的,所以我们也可以配置手动提交的方式,具体的手动提交方式在下面第四步会讲到
第二步、创建消费者实例并指定订阅的主题
调用subscribe()方法可以订阅多个主题

第三步、拉取消息并消费
通过poll()方法设置定时拉取消息的时间间隔,消费者会循环的从kafka服务器拉取消息

第四步、提交消费offset
前文中提到我们可以通过收到的方式提交offset,而手动提交又分为了两种,同步提交和异步提交。下面我直接上代码观看更直观
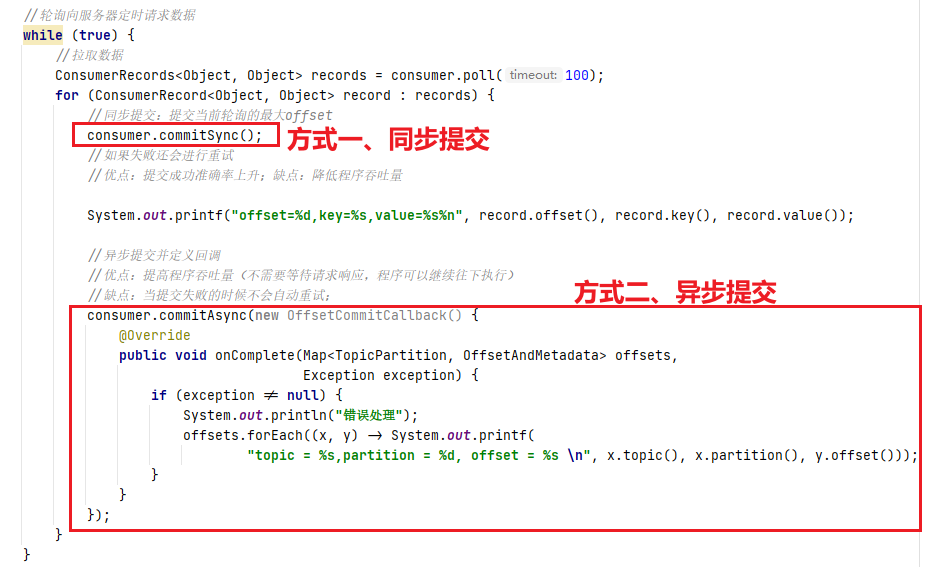
①、同步提交:如果失败还会进行重试,保证了提交成功准确率上升,但缺点是降低程序吞吐量,会发生阻塞
consumer.commitSync();
②、异步提交并回调:提高程序吞吐量(不需要等待请求响应,程序可以继续往下执行),不会阻塞,但缺点是当提交失败的时候不会自动重试;
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets,Exception exception) {
if (exception != null) {
System.out.println("错误处理");
offsets.forEach((x, y) -> System.out.printf(
"topic = %s,partition = %d, offset = %s \n", x.topic(), x.partition(), y.offset()));
}
}
});
Kafka如何保证消息可靠性的?
如何保证消息不丢失?ack机制
topic中的partition收到生产者发送的消息后,broker会向生产者发送一个ack确认,如果收到则继续发送,没收到则重新发送。
- acks=0:不等待broker返回ack接着执行下面逻辑。如果broker还没接收到消息就返回,此时broker宕机那么数据会丢失
- acks=1(默认):消息被leader副本接收到之后才算被成功发送。如果follower同步成功之前leader发生了故障,那么数据会丢失
- acks=all:所有ISR列表的副本全部收到消息后,生产者收到broker的响应才算成功。
发生重复消费的场景有哪些?
- 消费者提交位移失败:当消费者消费消息后,如果在提交消费位移之前发生错误或故障,可能导致消费者无法正确提交位移。在恢复后,消费者重新启动时,可能会从之前已经消费过的位置开始消费消息,导致消息的重复消费。
- 消费者重复启动:如果消费者在处理消息过程中发生故障或重启,可能会导致消费者重新从上一次位移处开始消费消息。这样可能会导致之前已经消费过的消息被重复消费。
- 重平衡(Rebalance):当消费者组中的消费者发生变化(例如增加或减少消费者),或者消费者订阅的主题发生变化时,会触发消费者组的重平衡操作。在重平衡期间,消费者可能会被重新分配到其他分区,导致消息的重新消费。
- 消息重复发送:在某些情况下,生产者可能会由于网络问题或其他原因导致消息发送失败,然后重新发送相同的消息。这样可能会导致消息在Kafka中出现多次,导致重复消费。
如何保证消息不被重复消费的?
- 使用消费者组(Consumer Group):将消费者组中的消费者分配到不同的分区进行消费,确保每个分区只被一个消费者消费。这样可以避免重复消费问题。
- 使用自动提交位移:在消费者消费消息时,可以选择使用自动提交位移的方式。这样消费者会在消费消息后自动提交位移,确保消费者在重启或发生故障后能够从正确的位置继续消费。
- 使用唯一的消费者ID:为每个消费者分配一个唯一的消费者ID,这样可以避免消费者重复启动或重复加入消费者组的情况。
- 设计幂等的消费逻辑:在消费者的业务逻辑中,可以设计幂等的处理逻辑,确保相同的消息被消费多次时不会产生副作用。
如何保证消息顺序消费的?
- 分区顺序:Kafka中的主题(topic)被分为多个分区(partition),每个分区内的消息是有序的。当消息被写入到某个分区时,Kafka会保证该分区内的消息顺序。因此,如果一个主题只有一个分区,那么消费者将按照消息的写入顺序进行消费。
- 消费者组:在一个消费者组(Consumer Group)中,每个消费者只会消费其中一个分区的消息。这样可以保证每个分区内的消息被单个消费者按照顺序消费。如果一个主题有多个分区,并且消费者组中的消费者数大于分区数,Kafka会将多个消费者均匀地分配到不同的分区进行消费。
- 顺序保证:在同一个分区内,Kafka会保证消息的顺序。即使有多个消费者消费同一个分区,Kafka也会保证每个消费者按照顺序消费该分区的消息。
需要注意的是,Kafka只能保证在单个分区内的消息顺序。如果一个主题有多个分区,那么多个分区之间的消息顺序无法保证。消费者可能会并行消费多个分区,并且不同分区的消息到达消费者的顺序可能会不同。
版权归原作者 吃豆子的恐龙 所有, 如有侵权,请联系我们删除。