
一、引言
传统的神经网络,只是在将样本x输入到输入层之前对x进行标准化处理,以降低样本间的差异性。BN是在此基础上,不仅仅只对输入层的输入数据x进行标准化,还对每个隐藏层的输入进行标准化。
我们在图像预处理过程中通常会对图像进行标准化处理,也就是image normalization,使得每张输入图片的数据分布能够统均值为u,方差为h的分布。这样能够加速网络的收敛。但是当一张图片输入到神经网络经过卷积计算之后,这个分布就不会满足刚才经过image normalization操作之后的分布了,可能适应了新的数据分布规律,这个时候将数据接入激活函数中,很可能一些新的数据会落入激活函数的饱和区,导致神经网络训练的梯度消失,如下图所示当feature map的数据为10的时候,就会落入饱和区,影响网络的训练效果。这个时候我们引入Batch Normalization的目的就是使我们卷积以后的feature map满足均值为0,方差为1的分布规律。在接入激活函数就不会发生这样的情况。
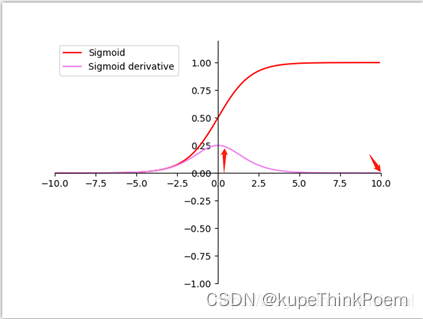
上面只是举例说明, 那在理论上为什么需要对每个隐藏层的输入进行标准化呢?或者说这样做有什么好处呢?这就牵涉到一个Covariate Shift问题。
二、Convariate shift
Convariate shift是BN论文作者提出来的概念,指的是具有不同分布的输入值对深度网络学习的影响。当神经网络的输入值的分布不同时,我们可以理解为输入特征值的scale差异较大,与权重进行矩阵相乘后,会产生一些偏离较大的差异值;而深度学习网络需要通过训练不断更新完善,那么差异值产生的些许变化都会深深影响后层,偏离越大表现越为明显;因此,对于反向传播来说,这些现象都会导致梯度发散,从而需要更多的训练步骤来抵消scale不同带来的影响,也就是说,这种分布不一致将减缓训练速度。
而BN的作用就是将这些输入值进行标准化,降低scale的差异至同一个范围内。这样做的好处在于一方面提高梯度的收敛程度,加快模型的训练速度;另一方面使得每一层可以尽量面对同一特征分布的输入值,减少了变化带来的不确定性,也降低了对后层网络的影响,各层网络变得相对独立,缓解了训练中的梯度消失问题。
三、算法
1、算法公式
一般将bn层放在卷积层(Conv)和激活层(例如Relu)之间。需要对Conv后的每层数据进行归一化。下面的算法是针对某一个层的,每层都采取相应的算法。

2、训练中的BN算法
训练的时候BN层是以每个channel来计算均值和方差,比如是如的是64*32*32*3,3代表channel,当前假如是rgb,64是batchsize。首先在r,g,b上各层上分别求出当前图像所有像素点的均值和方差,然后在batch上求平均,得到该组batch数据的局部数据均值和方差。然后引入bn层中的权重α和偏执β。可学习参数α、β是一个1*channel维度的。
3、测试和推理中的BN算法
测试和推理的时候如果依旧按照bn的公式算当前batch的均值和方差,如果测试图片batch一般为1,那么就大大降低模型的泛化能力,这和训练是要求batch尽可能大的初衷是不一致的。这里借用一句话:某一个样本经过测试时应该有确定的输出,如果在测试时也是用测试数据的means和var,那么样本的输出会随所处batch的不同,而有所差异。即batch的随机性导致了样本测试的不确定性。所以使用固定的在训练中得出的mean和var,在测试和推理的时候使用的均值和方差为训练数据通过指数滑动平均(ExponentialMovingAverage)EMA估算整个训练数据集的样本均值和方差的全局值。
四、BN算法在网络中的作用
BN算法像卷积层,池化层、激活层一样也输入一层,BN层添加在激活函数前,对激活函数的输入进行归一化,这样解决了输入数据发生偏移和增大的影响。
1、优点
(1)可以增加训练速度,防止过拟合:如果没有归一化,每一层训练后的数据分布都不同,网络需要更大的开销去学习新的分布,造成网络模型更加复杂,因此容易发生过拟合,网络收敛也比较慢。
(2)可以避免激活函数进入非线性饱和区,从而造成梯度弥散问题。
(3)不用理会拟合中的droupout、L2正则化项的参数选择,采用BN算法可以省去这两项或者只需要小的L2正则化约束。原因,BN算法后,参数进行了归一化,原本经过激活函数没有太大影响的神经元分布变得明显,经过一个激活函数以后,神经元会自动削弱或者去除一些神经元,就不用再对其进行dropout。另外就是L2正则化,由于每次训练都进行了归一化,就很少发生由于数据分布不同导致的参数变动过大,带来的参数不断增大。
(4)由于因为BN具有提高网络泛化能力的特性,可以减少了你可以移除dropout比例和正则化参数,这样减少繁琐的调参。
(5)可以省LRN局部归一化层。
2、缺点
(1)batch_size较小的时候,效果差
(2)BN 在RNN中效果比较差,RNN的输入是长度是动态的
(3)就是在测试阶段的问题,均值和方差的计算可能与训练集的相差较大
五、论文
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
本文转载自: https://blog.csdn.net/kupe87826/article/details/127351959
版权归原作者 kupeThinkPoem 所有, 如有侵权,请联系我们删除。
版权归原作者 kupeThinkPoem 所有, 如有侵权,请联系我们删除。