
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
Spring AI实战全系列链接
- Spring AI实战之一:快速体验(OpenAI)
- SpringAI+Ollama三部曲之一:极速体验
关于ollama
- ollama和LLM(大型语言模型)的关系,类似于docker和镜像,可以在ollama服务中管理和运行各种LLM,下面是ollama命令的参数,与docker管理镜像很类似,可以下载、删除、运行各种LLM
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
简单的说,有了ollama,咱们就可以在本地使用各种大模型了,ollama支持的全量模型在这里:https://ollama.com/library
官方给出的部分模型
ModelParametersSize下载命令Llama 38B4.7GBollama run llama3Llama 370B40GB
ollama run llama3:70bPhi-33.8B2.3GB
ollama run phi3Mistral7B4.1GB
ollama run mistralNeural Chat7B4.1GB
ollama run neural-chatStarling7B4.1GB
ollama run starling-lmCode Llama7B3.8GB
ollama run codellamaLlama 2 Uncensored7B3.8GB
ollama run llama2-uncensoredLLaVA7B4.5GB
ollama run llavaGemma2B1.4GB
ollama run gemma:2bGemma7B4.8GB
ollama run gemma:7bSolar10.7B6.1GB
ollama run solar另外需要注意的是本地内存是否充足,7B参数的模型需要8G内存,13B需要16G内存,33B需要32G内存
关于《SpringAI+Ollama三部曲》系列
- 《SpringAI+Ollama三部曲》是《Spring AI实战》的子系列,特点是专注于使用SpringAI来发挥Ollama的功能,由以下三篇文章构成
- 极速体验:用最简单的操作,在最短时间内体验Java调用Ollama的效果
- 细说开发:说明《极速体验》的功能对应的整个开发过程,把代码的每一步都说得清清楚楚(含前端)
- 延伸扩展:SpringAI为Ollama定制了丰富的功能,以进一步释放Ollama的能力,文章会聚焦这些扩展能力
本篇概览
- 本篇聚焦操作和体验,不涉及开发(后面的文章会有详细的开发过程),力求用最短时间完成本地部署和体验,感受Java版本大模型应用的效果
- 今天要体验的服务,整体部署架构如下
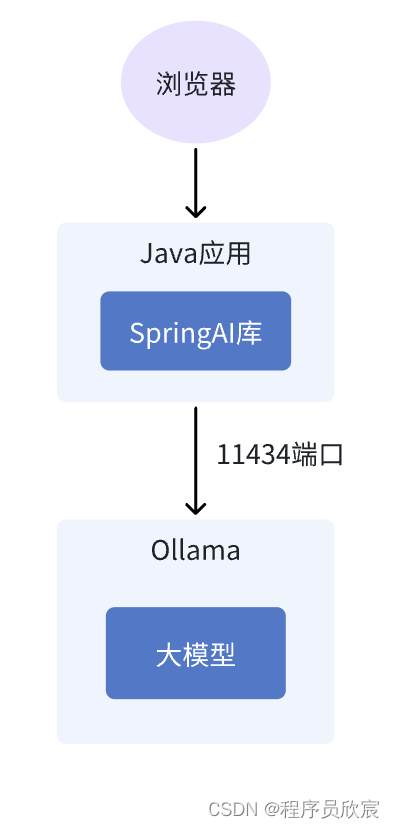
- 最终效果如下
ollama
- 今天要做的所有事情汇总如下,嗯,好像挺简单的
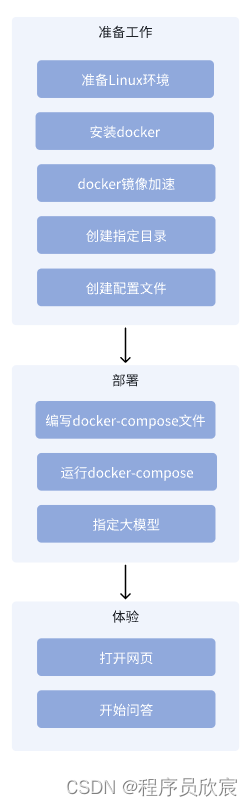
- 接下来咱们开始行动呗,正宗的Java程序员开始参与大模型(应用)相关开发工作了,此刻的我内心是激动的
环境要求
- 完成本篇的实战需要一台Linux操作系统的电脑(虚拟机、WSL2也行),电脑上部署了docker+docker-compose,电脑需要8G内存
确定本篇要用的模型
- Ollama支持的模型有很多,这里打算使用通义千问,官方网页

- 本次实战选择了较小的1.8b版本,您可以根据自己的实际情况在官网选择其他版本
- 稍后会将选好的模型写在配置文件中
准备工作(操作系统和docker)
- 本次实战的两个重要前提条件:
- 操作系统是Linux,我这里用的是Ubuntu 24.04 LTS服务器版
- docker和docker-compose已经部署好,我这里docker版本是26.1.2
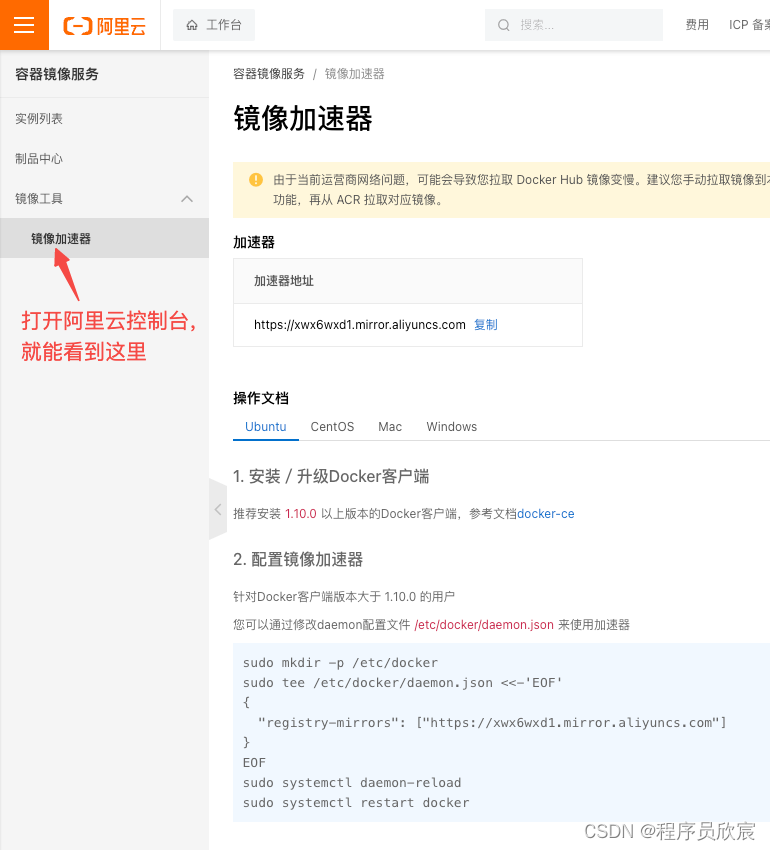
- 由于docker镜像较大,所以请提前准备好docker镜像加速,方法很多,我这里用的是阿里云的,如下图
- 前面介绍Ollama时提到过官方对内存的要求,所以这里请确保本次实战的电脑配置不要过低,我这边运行的模型是通义千问的1.8b,总消耗如下
✗ free-g
total used free shared buff/cache available
Mem: 313210627
Swap: 707
准备工作(保存文件的目录)
- 在电脑上准备两个干净目录,用来保存docker容器中的数据,这样即便是容器被销毁了数据也会被保留(例如模型文件),等到再次启动容器时这些文件可以继续使用
- 第一个是用来保存ollama的文件,我这里是/home/will/data/ollama
- 第二个是用来保存ollama webui的文件,我这里是/home/will/data/webui
- 这两个目录会配置到稍后的docker-compose.yml文件中,您要注意同步修改
准备工作(SpringBoot应用的配置文件application.properties)
- 准备好SpringBoot应用的配置文件application.properties,这样便于各种个性化设置
- 我这边在/home/will/temp/202405/15目录准备好配置文件,内容如下
spring.ai.ollama.base-url=http://ollama:11434
spring.ai.ollama.chat.options.model=qwen:1.8b
spring.ai.ollama.chat.options.temperature=0.7
spring.main.web-application-type=reactive
- 注意:本篇使用的模型是qwen:1.8b,如果您要用其他模型,请在这里修改好
- 至此,准备完毕,进入部署阶段
部署工作(编写docker-compose文件)
- 新增名为docker-compose.yml的文件,内容如下
version:'3.8'services:ollama:image: ollama/ollama:latest
ports:- 11434:11434volumes:- /home/will/data/ollama:/root/.ollama
container_name: ollama
pull_policy: if_not_present
tty:truerestart: always
networks:- ollama-docker
open-webui:image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
pull_policy: if_not_present
volumes:- /home/will/data/webui:/app/backend/data
depends_on:- ollama
ports:- 13000:8080environment:-'OLLAMA_BASE_URL=http://ollama:11434'-'WEBUI_SECRET_KEY=123456'-'HF_ENDPOINT=https://hf-mirror.com'extra_hosts:- host.docker.internal:host-gateway
restart: unless-stopped
networks:- ollama-docker
java-app:image: bolingcavalry/ollam-tutorial:0.0.1-SNAPSHOT
volumes:- /home/will/temp/202405/15/application.properties:/app/application.properties
container_name: java-app
pull_policy: if_not_present
depends_on:- ollama
ports:- 18080:8080restart: always
networks:- ollama-docker
networks:ollama-docker:external:false
- 上面的内容中,前两个volumes的配置对应的是准备工作中新建的两个目录,第三个volumes对应的是刚才新建的application.properties,请按照您的实际情况进行修改
部署(运行docker-compose)
- 进入docker-compose.yml文件所在目录,执行以下命令就完成了部署和启动
docker-compose up -d
- 本次启动会用到电脑的这三个端口:11434、13000、18080,如果这些端口有的已被使用就会导致启动失败,请在docker-compose.yml上就行修改,改为没有占用就行,然后执行以下命令(先停掉再启动)
docker-compose down
docker-compose up -d
- 启动期间,下载docker镜像时因为文件较大,需耐心等待(再次提醒,请配置好docker镜像加速)
- 启动成功后,控制台显示如下
[+] Building 0.0s (0/0)[+] Running 4/4
✔ Network files_ollama-docker Created 0.1s
✔ Container ollama Started 0.2s
✔ Container java-app Started 0.4s
✔ Container open-webui Started
- 现在服务都启动起来了,但是还不能用,咱们还要把大模型下载下来
部署(指定大模型)
- 登录webui服务,地址是http://192.168.50.134:13000,192.168.50.134是运行docker-compose的电脑IP
- 打开地址,会提示注册或者登录,这里要注册一下
- 注册成功后显示登录成功的页面,如下图
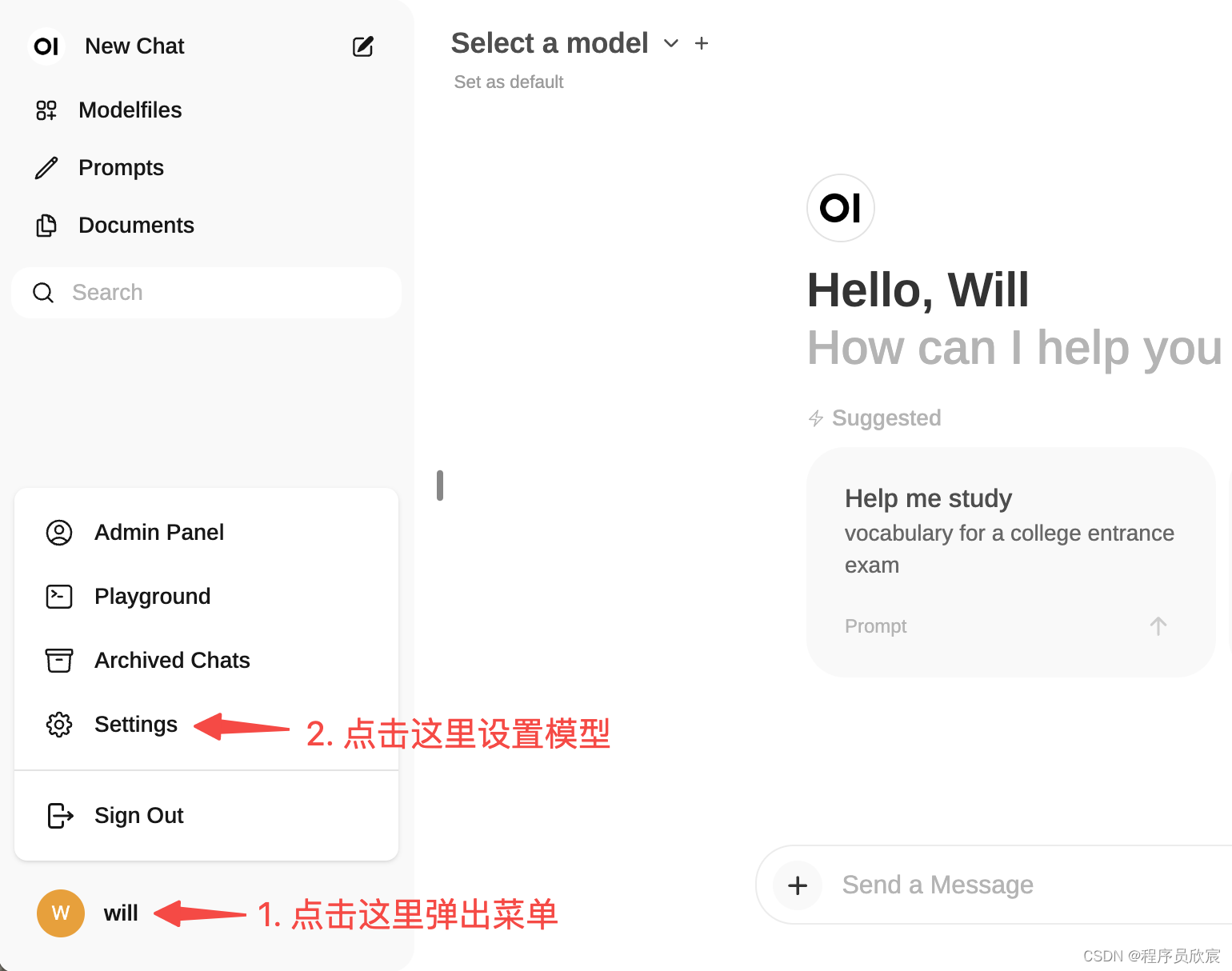
- 现在来下载模型,操作如下
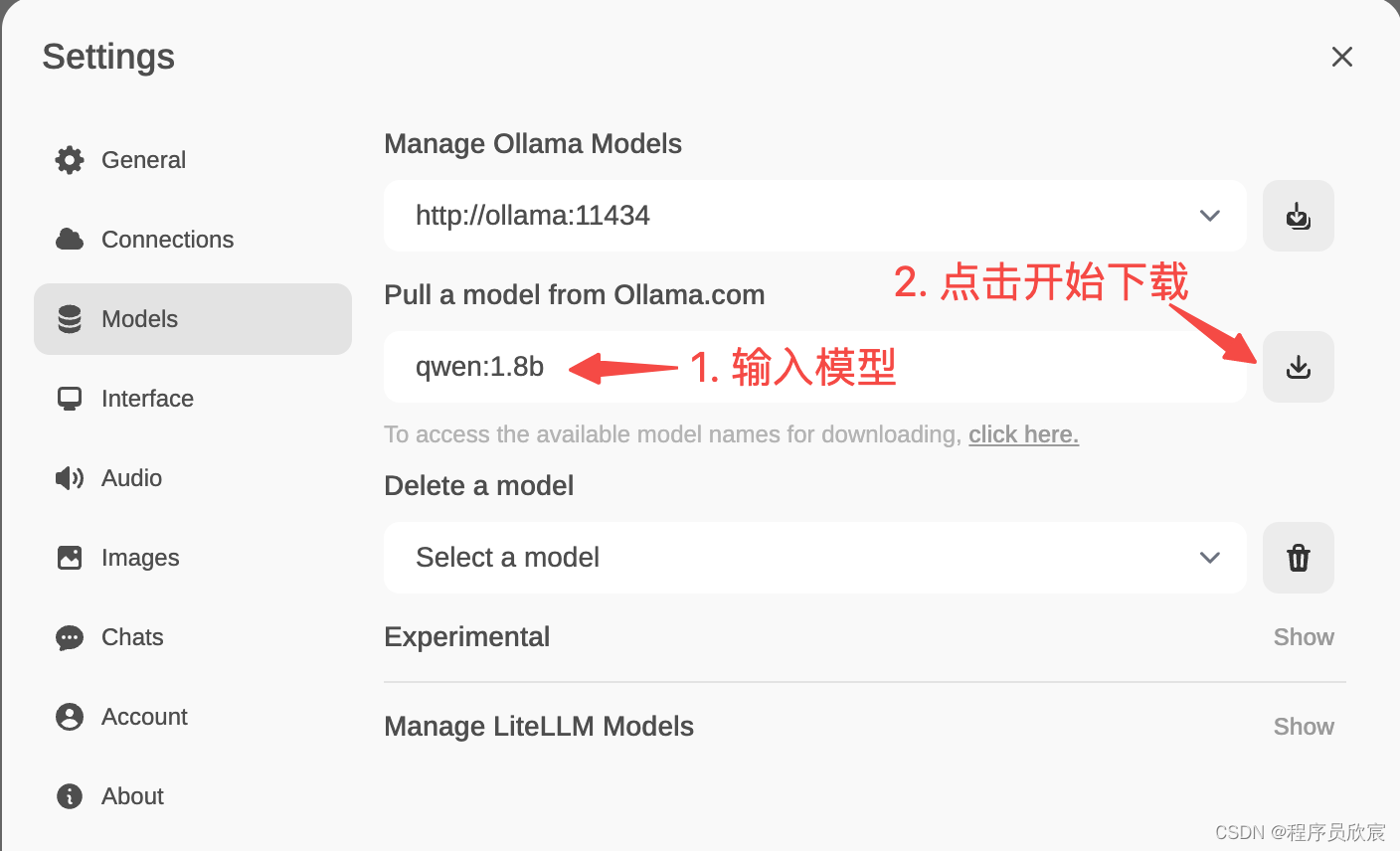
- 输入模型名称然后开始下载
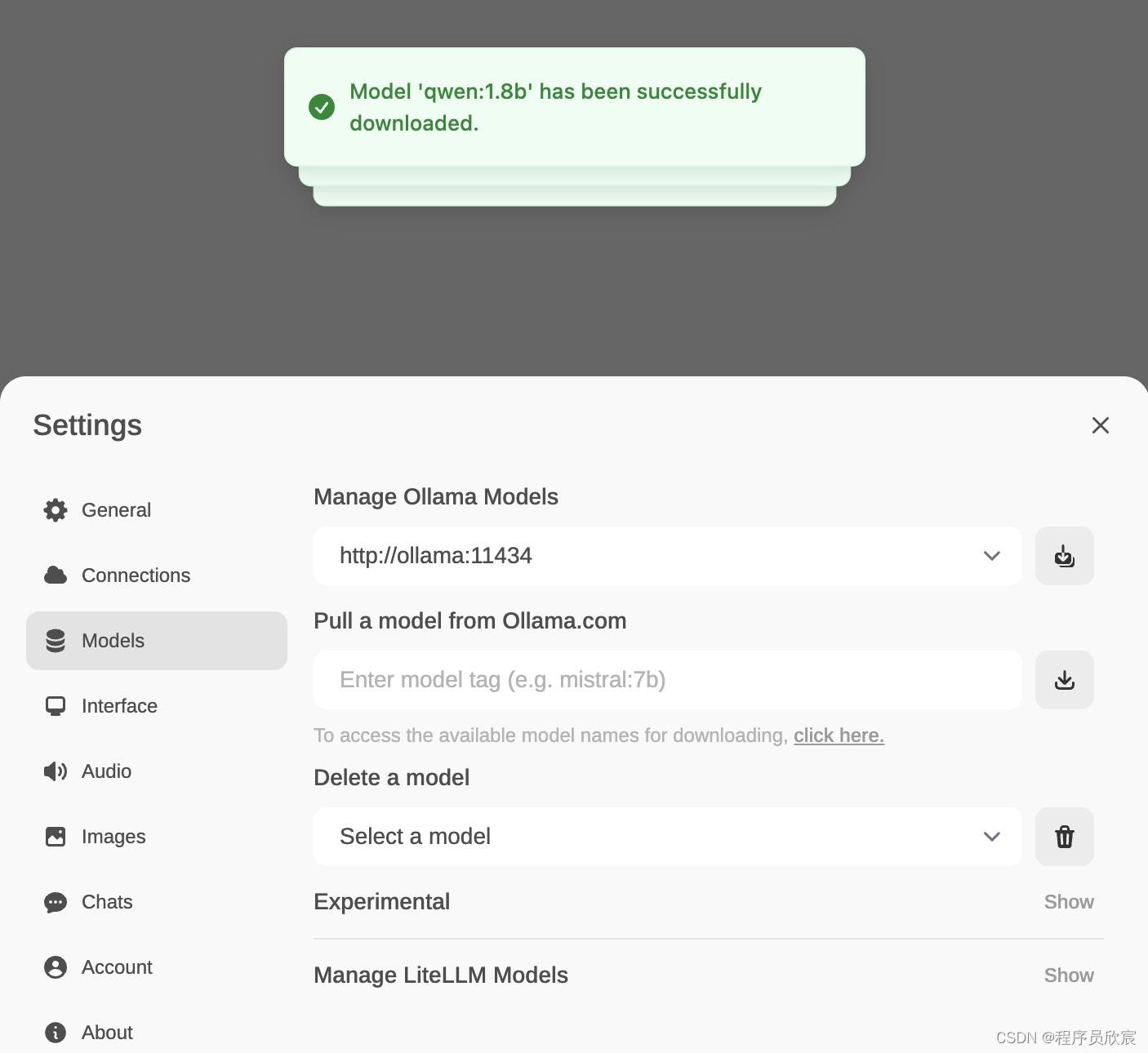
- 模型下载完成后会有如下提示
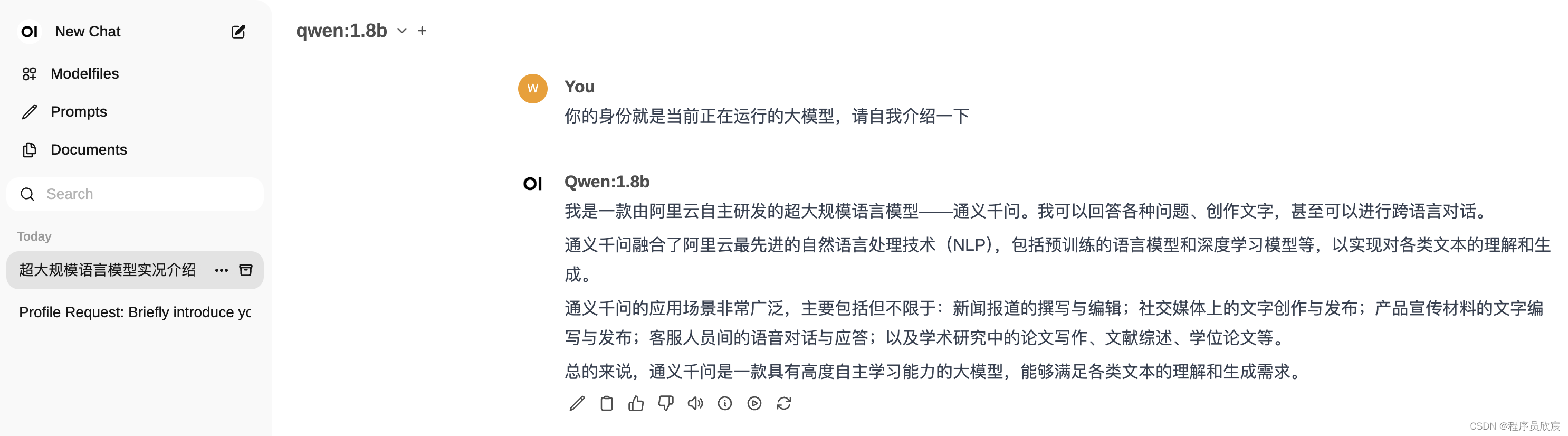
- 可以直接在webui上体验刚下载的模型,尝试了基本的问答,没有问题
- 至此,部署和启动都完成了,可以体验Java应用了
体验
ollama
- 至此,本篇的任务已经完成,一个本地化部署的大模型应用已经就绪,也完成了最基本的体验,过程十分简单(好像也就输入了几行命令,打开浏览器点了几下)
- 简单的背后,其实现是否也简单呢?先剧透一下吧,得益于Spring团队的一致性风格,调用Ollama的过程和操作数据库消息队列这些中间件差不多,几行代码几行配置就够了
- 至于完整的开发过程,就留到下一篇吧,那里会给出所有源码和说明
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列
本文转载自: https://blog.csdn.net/boling_cavalry/article/details/138761438
版权归原作者 程序员欣宸 所有, 如有侵权,请联系我们删除。
版权归原作者 程序员欣宸 所有, 如有侵权,请联系我们删除。