
前言
yolov5的6.2版本不仅更新了前一篇文章里提到的分类模型,同时也更新了图像分割模型,在官方的教程和用法还没出之前(2022/09/19),我基于官方已经写好的推理脚本进行部分修改,实现了基于图像分割的简单人物抠像。
注:本文所用模型为yolov5s-seg,是已经预训练好的官方模型。
展示效果
话不多说,先来放图!
首先是官方的图像分割推理结果,为了不透露小伙伴信息,这里打上马赛克:
其次是我修改后需要的人物抠像结果:
如何实现
克隆yolov5新版源码解压后(这个就不展开谈了)
1.首先修改yolov5-master\utils下的plots.py:
#plots.pydefmasks(self, masks, colors, im_gpu=None, alpha=1):
这里的alpha值需要修改为1,alpha影响的是mask也就是遮罩层的透明度,默认是0.5,是以下这种效果:

可以看到很明显暗半圈,不符合我们的效果。
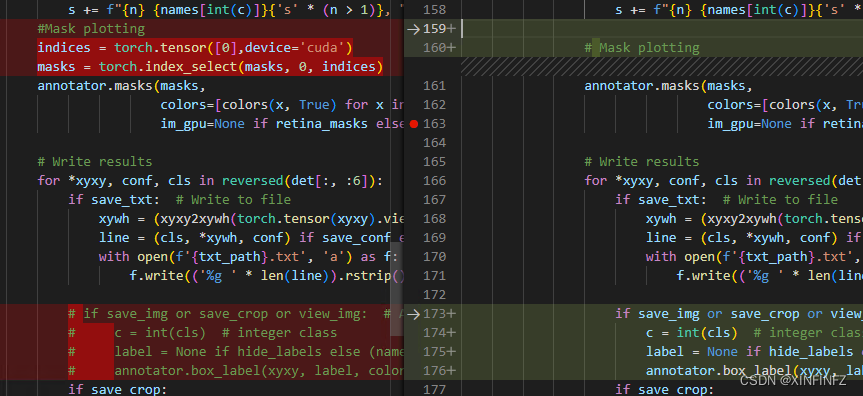
接下来需要修改几行代码,为了清楚,我直接把我修改的和原始文件对比进行截图:

也就是修改成:
masks = masks.unsqueeze(3)# shape(n,h,w,1)
masks_color = masks *(colors * alpha)# shape(n,h,w,3)
inv_alph_masks =(masks * alpha).cumprod(0)# 1-masks*alpha
mcs =(masks_color * inv_alph_masks).sum(0)*2# mask color summand shape(n,h,w,3)
im_gpu = im_gpu.flip(dims=[0])# flip channel
im_gpu = im_gpu.permute(1,2,0).contiguous()# shape(h,w,3)
im_gpu = im_gpu * inv_alph_masks[0]#no mcs
其中我把mcs(也就是着色块)先去掉,然后因为是要去掉背景保留前景,所以需要把1-mask乘alpha改成mask乘alpha,同时为了只取最大的物体,这里inv_alph_masks里的-1(取全部)改成了0(只取第一个物体)。
为了更好地理解,这里分别放出mcs,inv_alph_masks分别是什么效果:

2.修改yolov5-master\segmant\predict.py文件:
上面两行代码的意思是这里取masks里的第一个物体,也就是检测值最大的那个物体,其他我不要了(这个看需求处理),同时要把目标检测框去掉的话只要把下面四行代码注释掉即可。
3.预测:
#D:\yolov5-master-seg\yolov5-master\segment在当前目录下启动命令行
python predict.py --weights yolov5s-seg.pt --source 3014193119028716040.avi --class0
–source后面跟的换成你需要的视频文件或者视频源。
–class 0表示只预测0的分类,这里的分类取自coco数据集,0就是人的意思,所以只会进行人的图像分割。
以下是推理的结果:
Speed:0.4ms pre-process,8.3ms inference,1.0ms NMS per image at shape (1,3,640,640)
Results saved to ..\runs\predict-seg\exp24
用的是rtx4000显卡,速度是非常理想的,此外这里提一句,yolov5s的推理速度就比yolov5n慢了一点点(大约2ms),但是效果要好不少,各位请根据自己的实际情况选择模型。
版权归原作者 XINFINFZ 所有, 如有侵权,请联系我们删除。